文章目录
- 前言
- 堆排序
- TopK问题
- 结语
前言
上篇博客,我们实现了堆。那么堆到底有什么应用情景?今天的内容就是堆的两个应用,堆排序和TopK问题。话不多说,我们这就开始。
堆排序
堆排序,是根据堆的结构而设计出的一种排序算法,其时间复杂度:O(N * logN),空间复杂度:O(1)。
堆排序的前提是需要 构建一个堆,而建堆有两种方法:
向上调整建堆:
上篇博客中,我们实现过 堆的向上调整算法。我们使用向上调整方法建堆时,需要复用堆的两个接口:初始化 和 插入(插入中调用了向上调整)。
通过这种方法,我们可以建堆成功。
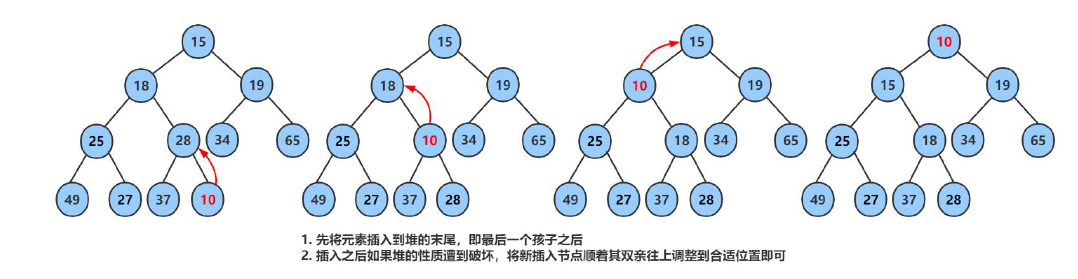
那么它的时间复杂度怎么计算?
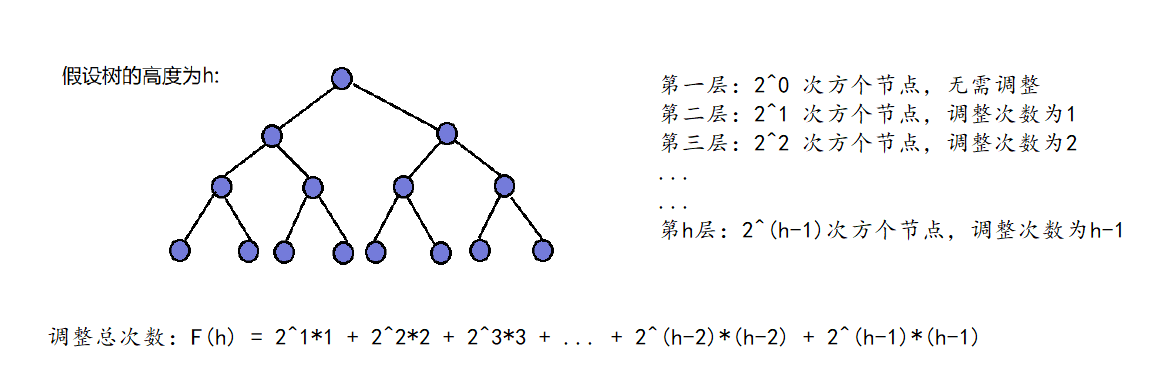
对于 向上调整 来说,除了第一层无需调整,其他层数都需要调整。而 二叉树每层的节点是呈 2 倍递增的。
所以其实 最后一层的节点 比 前 h - 1 层 都多,最后一层的节点数为:2^(h-1) * (h-1),再对其进行处理:2^h * (h-1)/2。
这里的 h 为 高度,我们设 N 为二叉树的总结点数。假设二叉树每一层都是满的,那么每层节点数就呈一个等比数列:20~ 2(h-1)。通过等比数列求和,可以求出二叉树的总结点数为:2^h - 1,那么就可以推导出 h 和 N 之间的关系为:2^h-1 = N.
那么式子 2^h*(h-1)/2,就可以继续转换为:(N+1)(logN-1)/2,省去常数项和除数,就可以推出 向上调整算法的时间复杂度为O(N * logN)。
那么对于向下调整呢?它的时间复杂度是否更优?
向下调整建堆:
首先明确一点,可以使用向上调整或向下调整算法的前提是,数组的结构是一个堆。向上调整算法由于是从0开始构建的,每一次push都保证它是一个堆,这点它不需要考虑。
但是对于向下调整算法来说,给定的数组可能不是一个堆,所以第一步就是将 给定数组 调成一个堆:
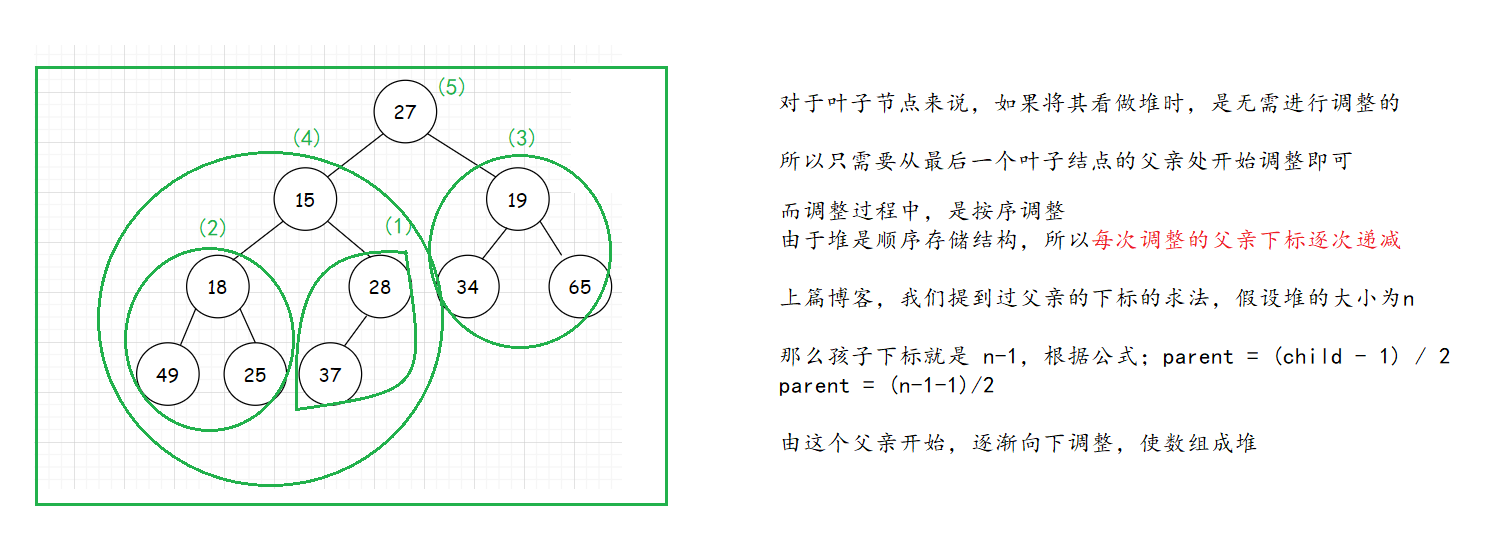
那么建堆的时间复杂度又是多少?这里就又要进行推导:
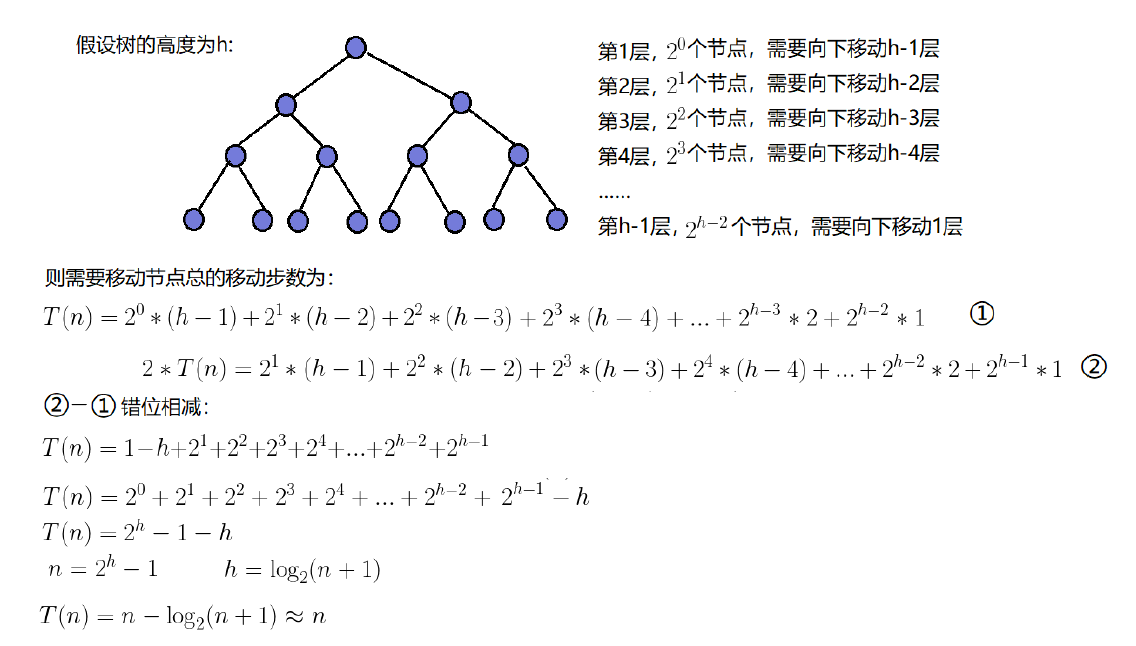
根据推导,我们可以得知 向下调整建堆的时间复杂度为O(N)。
所以就时间复杂度上,明显向下调整建堆的方法更优。
那么接下来,就到了堆排序的第二步,选择排升序还是降序。
我们这里就举 排升序 的例子:
如果要使 堆排序的排序方式为升序,那么我们应该构建 大堆 还是 小堆 ?
先假设我们构建的是一个小堆:

小堆被否决,我们就需要构建大堆:
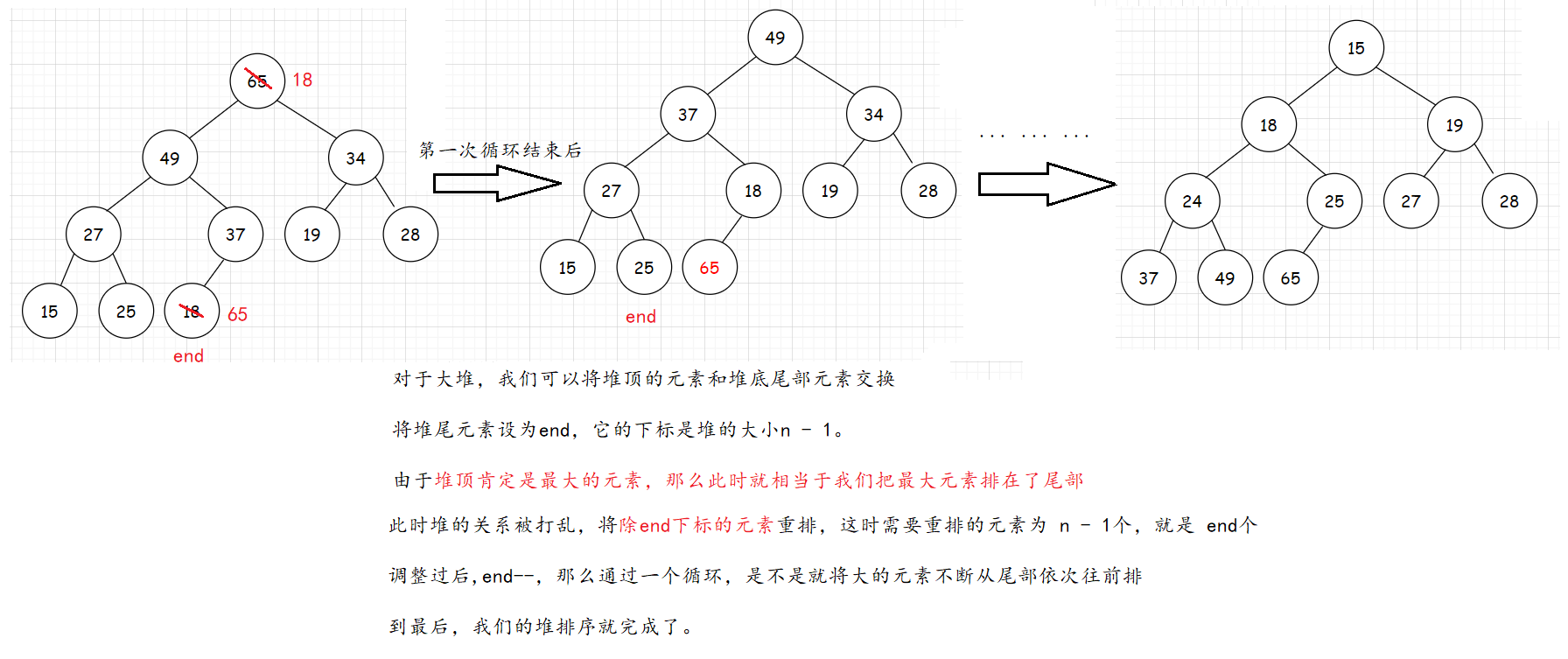
而这里我们构建大堆在向下调整的过程中,每个节点最多向下调整 logN 次。
建堆的时间复杂度为O(N),而排序的过程根据最后一层计算出的时间复杂度为O(N * logN),那么整体的时间复杂度就为N+N*logN,忽略掉N,堆排序的时间复杂度为O(N * logN)
那么堆排序对比冒泡排序、插入排序等时间复杂度为O(N^2)的排序的排序速度有多快呢?
对于 N^2 的如果有100w个值,那么就要跑一万亿次;而对于 N*logN 而言,只需要跑 2000w 次。这就体现出差距了。
建大堆,排升序代码:
// 交换
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 向下调整
void AdjustDown1(int* a, int sz, int parent)
{
int child = 2 * parent + 1;
// 建大堆
while (child < sz)
{
if (child + 1 < sz && a[child + 1] > a[child])
{
child++;
}
// 判断孩子是否大于父亲
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int sz)
{
// 建堆
for (int i = (sz - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown1(a, sz, i);
}
// 此刻堆已经建好了
// 排升序,已经建了大堆,就需要调整元素
int end = sz - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown1(a, end, 0);
end--;
}
}
void TestHeap1()
{
int array[] = { 27, 15, 19, 18, 28, 34, 65, 49, 25, 37 };
HeapSort(array, sizeof(array) / sizeof(int));
for (int i = 0; i < sizeof(array) / sizeof(int); ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
int main()
{
TestHeap1();
}

TopK问题
TopK问题:即求数据结合中 前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如 csdn的热榜前一百、世界五百强、古代的四大美女等。
对于TopK问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。
比如在N个数中找出最大的 k 个数。最佳的方式就是用堆来解决,而堆又有两种方案:
- 建立一个 N 个数的大堆,pop k 次,依次取堆顶元素,依次得到最大的 k 个数。
- 建立一个 k 个数的小堆,依次遍历数据,数据比堆顶数据大就替换堆顶,再向下调整堆,最后小堆中就是最大的 k 个数。
我们先分析 第一种方案:
对于 N 不大的情况,这种方法是可以的。但是如果 N 是一百亿呢,这时这些数据的大小就是40G,我们买来的电脑内存才16G,那肯定就开不了这么大的堆。
虽然它有着 k * logN 的时间复杂度,且在内存放的下的情况下,空间复杂度更是达到了O(1),但是它因为可能有着内存放不下的风险,所以这个方案被否决了。
那么我们接着看 第二种方案:
内存中可能放不下这些数据,那么就可以放到磁盘中,也就是放到我们的文件中,有了这个前提,我们再开始。
首先,我们分析一下,为什么要建 k 个数的小堆:
我们的目的是选出 最大的 k 个数,大堆堆顶的数据为最大,如果一开始建堆的 k 个数,就包含着 N 个数中最大的数,其他的数不是最大的数之一。那么最大的数据堵在堆顶,其他数据就进不来了。所以一定要建小堆。
当建好堆之后,遍历 N 个数,由于是小堆,那么遍历的数据一旦比堆顶数据大,就把元素放入堆,然后重新调整,再选出堆中最小的数,循环往复,最后堆中就是最大的 k 个数。
我们再分析一下时间复杂度,建小堆的时间复杂度为:O(k),遍历选数的时间复杂度为:O(N - k) * logk。那么总体就是 k + (N - k) * logk,化简一下就为:O(N * logk)。
而空间复杂度由于建了 k 个数的堆,就是O(k)。
这里我们使用随机数 + 文件读写的方式,并且在文件中放入几个大于随机数最大值的数据,检测是否完成选最大的 k 个数的任务:
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown2(int* a, int sz, int parent)
{
int child = 2 * parent + 1;
// 建小堆
while (child < sz)
{
if (child + 1 < sz && a[child + 1] < a[child])
{
child++;
}
// 判断孩子是否小于父亲
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
void TestHeap3()
{
int n, k;
printf("请输入n和k:>");
scanf("%d%d", &n, &k);
srand((unsigned int)time(NULL));
// 写文件
FILE* in = fopen("data.txt", "w");
if (in == NULL)
{
perror("fopen fail");
return;
}
for (int i = 0; i <= n - 5; i++)
{
fprintf(in, "%d\n", rand());
}
// 手动输入大于随机数最大值的值
fprintf(in, "%d\n", 66666);
fprintf(in, "%d\n", 77777);
fprintf(in, "%d\n", 88888);
fprintf(in, "%d\n", 99999);
fprintf(in, "%d\n", 55555);
fclose(in);
in = NULL;
// 读文件
FILE* out = fopen("data.txt", "r");
if (out == NULL)
{
perror("fopen fail");
return;
}
// 动态开辟空间
int* minHeap = (int*)malloc(sizeof(int) * k);
if (minHeap == NULL)
{
perror("malloc fail");
return;
}
for (int i = 0; i < k; i++)
{
fscanf(out, "%d", &minHeap[i]);
}
int val = 0;
// 取k个数,建小堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown2(minHeap, k, i);
}
// 开始调整
while (fscanf(out, "%d", &val) != EOF)
{
if (val > minHeap[0])
{
minHeap[0] = val;
AdjustDown2(minHeap, k, 0);
}
}
// 打印minHeap 就是 topK
for (int i = 0; i < k; i++)
{
printf("%d ", minHeap[i]);
}
printf("\n");
fclose(out);
out = NULL;
}
int main()
{
TestHeap3();
}

结语
到这里,本篇博客就到此结束了。可能看到这里,大家可能会有点迷糊。因为今天的两个应用相对于之前是有难度的,里面有很多公式的推导和证明。博主第一遍学习的时候也是迷迷糊糊的,这是正常的,多看几遍,画画图,理解一下,就会好理解很多,而博主很笨都能理解,大家这么优秀也肯定可以理解的哈哈哈。
多写多练才是最重要的!
如果觉得anduin写的还不错的话,还请一键三连!如有错误,还请指正!
我是anduin,一名C语言初学者,我们下期见!