微信搜「古时的风筝」,还有更多技术干货
这有朋友聊到他们的系统中要接入全文检索,这让我想起了很久以前为一个很古老的项目添加搜索功能的事儿。
一提到全文检索,我们首先就会想到搜索引擎。也就是用一个词、一段文本搜索出匹配的内容。一般这种技术都有对应的实现方式,ES(ElasticSearch)就是专门干这个的,如果你们的业务中明确需要全文检索,或者简单一点说,需要根据关键词搜索出匹配的内容,那就直接用 ES 就好了。
无论你怎么调研,都不推荐使用 MySQL 实现这种需求,显而易见,MySQL 作为关系型数据库,本身就不适合做搜索这种需求。
但是,奈何,今天我们就要用 MySQL 来做这件事儿。
背景
有一个很古老的业务采集了大量的信息,当然是合法采集了。系统用的人已经不多了,并且在平稳的运行,那就不要动它了就好了嘛。可偏偏为数不多的人非要加一个搜索功能,根据一个关键词来搜索。
这项目直接没接触过,咱也不敢随意改呀,通过和少有的还有了解这个系统的同事沟通,发现有一类角色本来就有搜索功能,只不过这功能基本没法用,从来搜不出内容。现象就是点完搜索按钮,后台接口就一直 pending,不用说了,那肯定是因为数据量太大了,或者某种很傻的原因,比如直接在大数据量、大段文本的字段中使用了 like模糊查询。
经过一番查看,发现这个准备要支持搜索的字段是 text类型的, 字段本身是不参与业务计算的,只是用来展示。而要搜索的内容还不止一个字段,好几个字段,这些字段的内容是什么呢,就是一段描述内容,里面有各种各样的专业名词,每一行记录中这个字段最大长度可能有几十到上千个字不等。
这张表由于数据量较大,并且字段很多,所以进行了分表,根据某个上层类型进行拆分,这样分出来的表,大的有上百万,小的有几十万。业务运算的时候,也是固定类型后,在这个类型下的分表中进行增删改查。
一看代码,果然,一条查询好几个 like,在几十万数据量的表中like好几个字段,不慢才怪,能查出来就是奇迹了。
于是勇敢的在数据库中尝试了一下一条查询的完整 SQL,在10分钟之后,还是果断结束了任务,一条SQL执行10分钟,就算用户能接受,我们自己也接受不了,好不好。
分析并思考解决方案
有需求就要处理,这种搜索的需求很明显就要用 ES 嘛,下载ES,准备本地搭建环境。
开玩笑的,加上 ES 不知道何年何年了,况且这么老的项目,能少动就少动,能不碰就不碰。这个法则,每个程序员都应该掌握。
思考
如果用户想要的不是通过任意关键字检索,而是通过指定一些我们为他预设好的关键词查询,就类似于抽出一些标签,可以按照标签组合搜索,那可以将需要搜索的字段中的内容拿出来分词、归类,抽取出相关的标签。这又是分词、又是分析的,想想也不比直接上 ES 简单。
还好,用户不想要这种的,就要不做限制,直接用关键词搜索。
务实主义
目前的处境是这样的:
1、不要做大的改动,因为项目老旧,并且不熟悉,用的人也不多了;
2、逻辑很明晰,就是模糊查询,但是目前性能极低;
3、直接在 MySQL 层做优化,确实是有办法的,具体效果只能试过之后才知道;
直接的优化手段其实也是非常简单的,MySQL 5.6版本后,MyISAM 和InnoDB 引擎已经全部支持全文索引了。还好,目前使用的数据库在5.6版本之后。
为了演示,我将最小的一张 296,560 表缩小了10倍变成了 2万9千多条,没有做任何处理,直接在一个最长的 text类型的字段上做 like查询,最后的查询时间是 1秒左右,偶尔慢的时候能达到2、3秒。
select * from case_data where case_name like '%侵权责任%';

用explain分析一下,发现是全表扫描。

这只是查询了将近3万条数据,并且只查询了一个字段,并且没有其他逻辑,真实环境中的逻辑要复杂的多。
全文索引简单原理
MySQL 5.6之后的版本支持对 char、varchar、text 类型的字段创建全文索引。
当添加了全文索引之后,数据库引擎就会对添加索引的列进行语法语义的分析,并对它进行分词,之后对这些分出的短语进行索引,每个短语对应包含它的行的集合。
| 短语 | 包含的行的集合 |
|---|---|
| 合同 | 第1行、第5行、第10行、第n行 |
| 项目管理 | 第2行、第3行、第22行、第1999行、第n+1行 |
| 产品研发 | 第500行、第3899行、第8899行、第n+2行 |
这样当我们搜索某个关键词后,如果正好对应了某个短语,就可以直接命中包含它的行。
有几个参数是控制全文索引的, ft(FullText) 开头的。用下面的命令可以查看。
show variables like '%ft%'
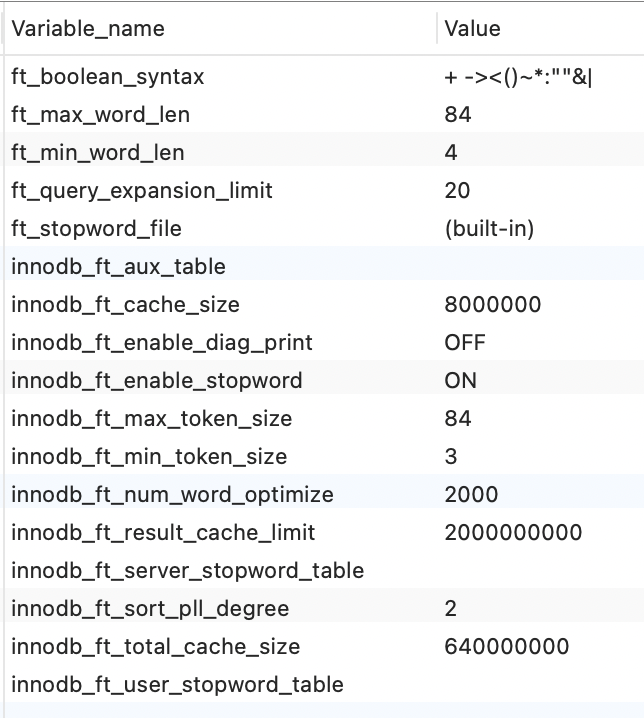
ft_boolean_syntax
表示布尔查询时的可以用的符号,改变IN BOOLEAN MODE的查询字符,一会儿下面会演示用法。
innodb_ft_min_token_size
对与 innodb 引擎,最短的索引字符串,默认值为84,修改后要重建索引
innodb_ft_max_token_size
对与 innodb 引擎,最长的索引字符串,默认值为3,修改后要重建索引
创建全文检索
下面这两种方式都可以对已经存在的表创建全文索引。
CREATE FULLTEXT INDEX <index_name> on tableName(字段名);
ALTER TABLE tableName ADD FULLTEXT <index_name>(字段名);
当然,如果你不想用SQL语句创建,也可以直接使用客户端工具创建。
比如我测试用的这个表叫做 case_data,要支持全文检索的字段叫做 case_name,使用下面的 SQL 创建索引,索引名称为 inde_case_name。
ALTER TABLE case_data ADD FULLTEXT index_case_name(`case_name`);
创建索引的过程比较缓慢,对于大数据量的表更慢,尤其是全文索引,这3万条数据对这一个字段创建索引的过程差不多10秒钟左右,如果是线上正在使用的服务,创建这种耗时索引就要酌情考虑一下什么时机创建比较合适了。
再次查询测试性能
全文索引创建好之后,就可以测试一下效果如何了,执行一下,等着见证奇迹。
select * from case_data where case_name like '%侵权责任%';
咦,怎么不仅没快,反而慢了一点儿。

别慌,姿势不太对。全文索引有专门对应的查询关键字。使用 match和against配合查询,match 表示要匹配的列名称,against 表示要查询的关键词。比如下面这样:
select * from case_data where match(case_name) against('侵权责任');
确实是快了,通过分析可以看出已经开始走全文索引了,扫描的行数已经是常数行了。

但是,一顿操作猛如虎,一看结果啥都没有啊。
因为全文检索是有精度的,是按照分词出来的关键词进行完全匹配的,也就是说当前的分词短语中并不存在侵权责任这个词,但是可能存在人身侵权责任、无故侵权责任人等短语。最简单的办法就是在查询侵权责任这个短语时,也要命中人身侵权责任、无故侵权责任人这两个短语,又类似于模糊查询了。
怎么办呢,这样写就可以了。
select * from case_data where match(case_name) against('*侵权责任*' in boolean mode);
这样再次查询,结果就出来了。为什么会这样呢,前面我们提到一个变量,叫做ft_boolean_syntax,这个变量中的符号就类似于正则表达式里支持的规则符号。
常见的匹配模式有下面这些:
空格:可选的,包含该词的顺序较高
"text":全词匹配查找
text*:通配符查找,*只能放在后面
+text:必须包含,+只能放在词前面
-text:必须不包含,不能单独使用,如`+aaaa-cccc
>text:如果含有该词,提高词的相关性
<text:如果含有该词,降低词的相关性
():条件组,如aaaa+(bbbb cccc)表示必须包含 bbbb 或 cccc
本来就叫全文检索了,结果又整个模糊查找,一点儿也不彻底呀,还有没有别的办法了。
有一个,在5.7版本开始就内置了中文分词插件 ngram,我们将刚才创建的索引删掉,然后重新用 ngram做分词重新建立索引。
ALTER TABLE case_data ADD FULLTEXT index_case_name(`case_name`) WITH PARSER ngram;
等个十几秒中,然后再执行第一次差不到数据的SQL。
select * from case_data where match(case_name) against('侵权责任');
再看查询结果,已经有数据了。
性能提升
我的测试数据只有2万多条,这种少量数据的情况下,性能是看不到提升的。并且还由于创建了索引,增大了存储空间。
但是将数据量提升十倍,到二十多万,会看到性能明显提升了几十倍。我在线上测试了 200万的表,用全文索引的方式0.5秒内能出结果,用 like 的话,喝完一杯茶,发现还在跑着。
因为全文检索本来就是适用于大数据量的场景,所以对于小样本的数据量,直接用 like也查不到哪儿去。
对于大数据量的场景,如果不引入ES等全文检索的中间件的情况下,用全文索引可以说是最快最划算的方式了。
如果对你有帮助,欢迎给个一键三连。
微信搜「古时的风筝」,还有更多技术干货






![[附源码]java毕业设计校园拓展活动管理系统](https://img-blog.csdnimg.cn/1eca652730764a5ab2dd37d0ae1fdbc8.png)





![[附源码]SSM计算机毕业设计基于javaweb电影购票系统JAVA](https://img-blog.csdnimg.cn/450f1d8bbccd45b598185b3384da2e1e.png)