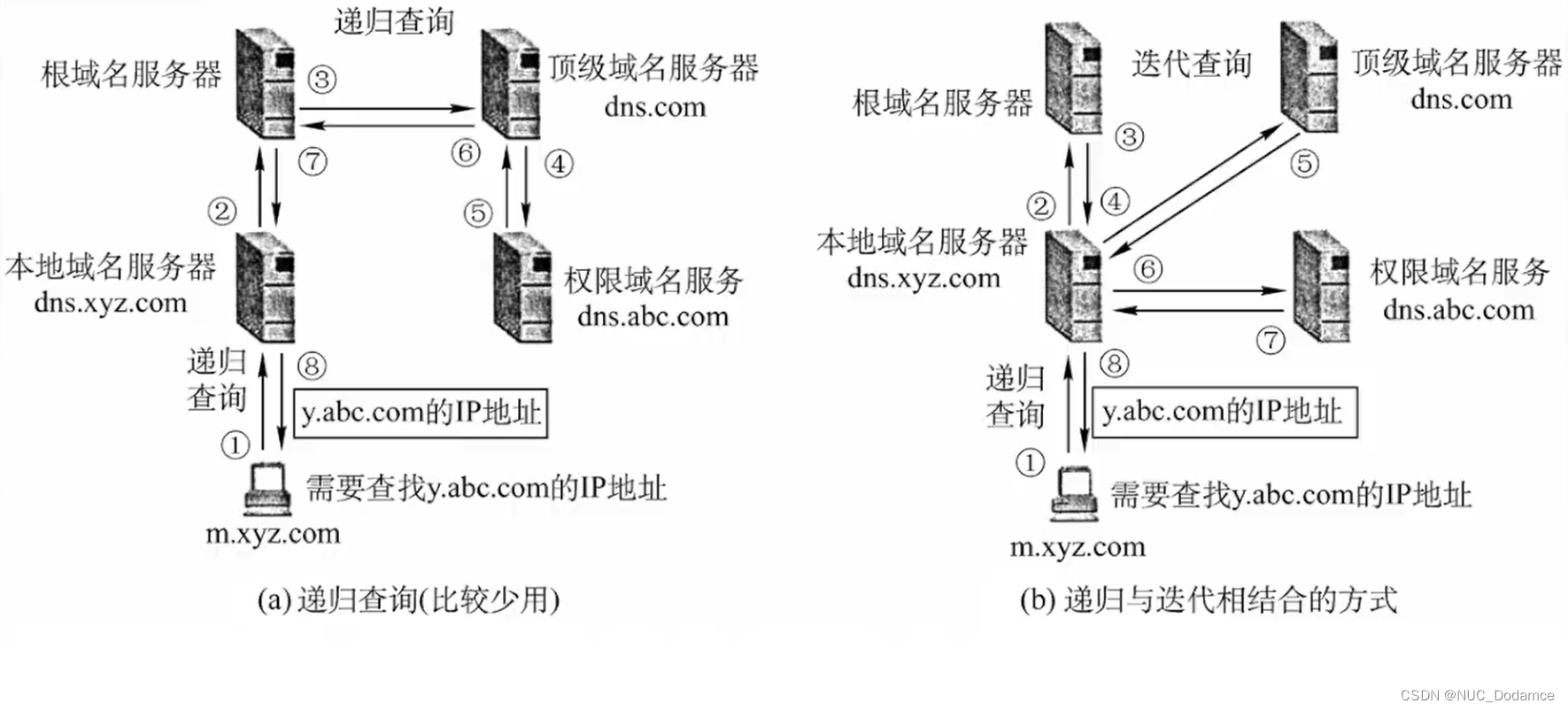
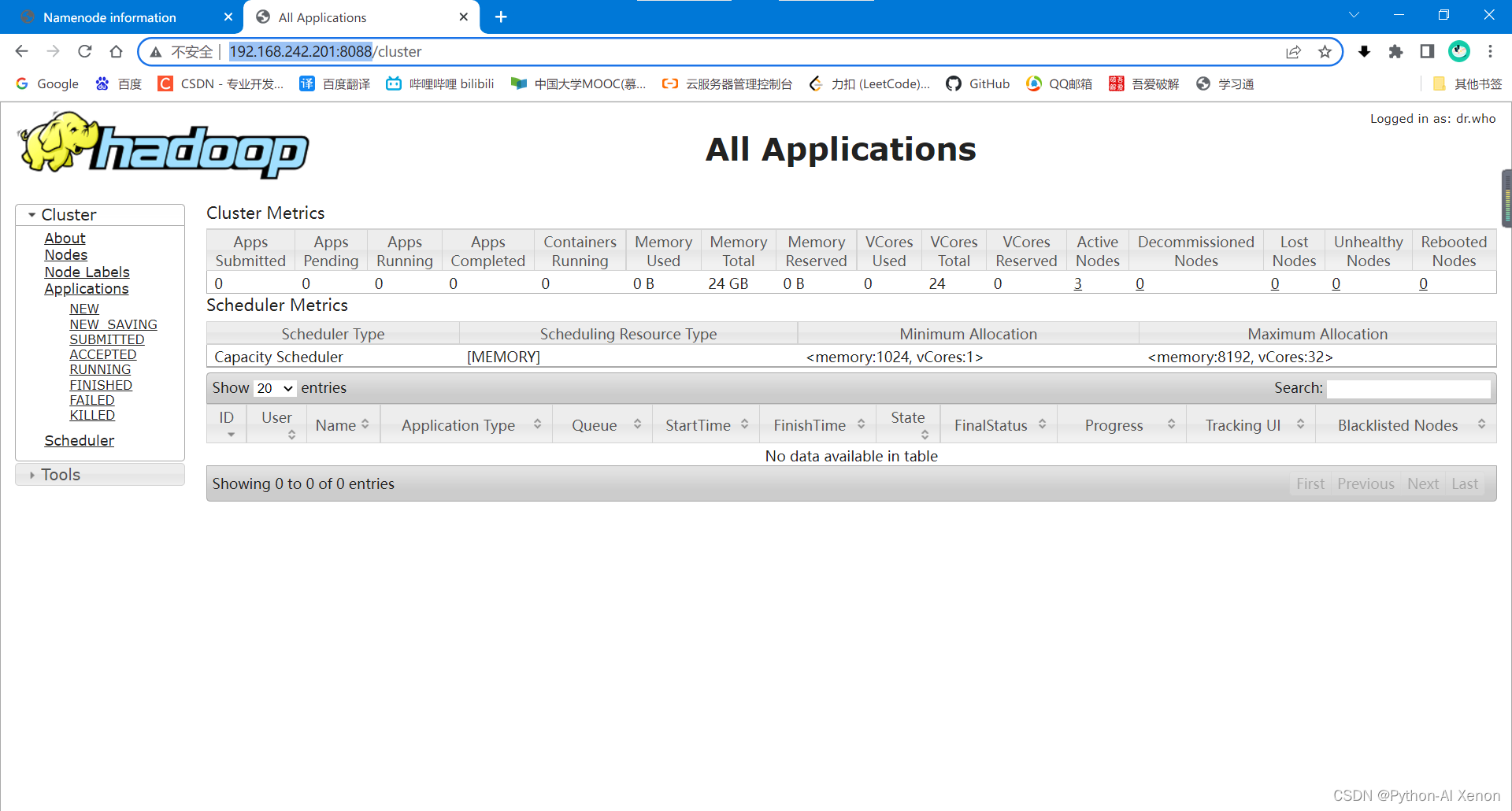
C++11、17、20的内存管理-指针、智能指针和内存池从基础到实战(中)
- 第三章 分配器allocator和new重载
- 1、重载operator的new和delete包括数组
- 如果我们访问的是一个数组
- 2、类成员操作符new重载和放置placement_new
- placement new(放置内存)
- 3、分配器allocator详解c++17_20新特性说明
- 4、自定义allocator演示vector和list分配器
- 现在换成我们自定义的分配器
- 我们再试一个list容器
- 5、未初始化内存复制分析uninitialized_copy
- 6、c++17 20 construct对象构造和销毁
- 第四章 C++指针与面向对象
- 1、限制栈中创建对象和调用delete销毁对象
- 2、类继承和多继承内存地址分析
- 多继承内存分析
- 3、多继承中的二义性和虚基类内存问题分析
- 虚基类、虚继承
- 4、虚函数原理和内存分析
- 5、虚函数表指针直接访问函数的代码实验
- 手动调用虚函数表里面的函数
- 第五章 C++17内存池
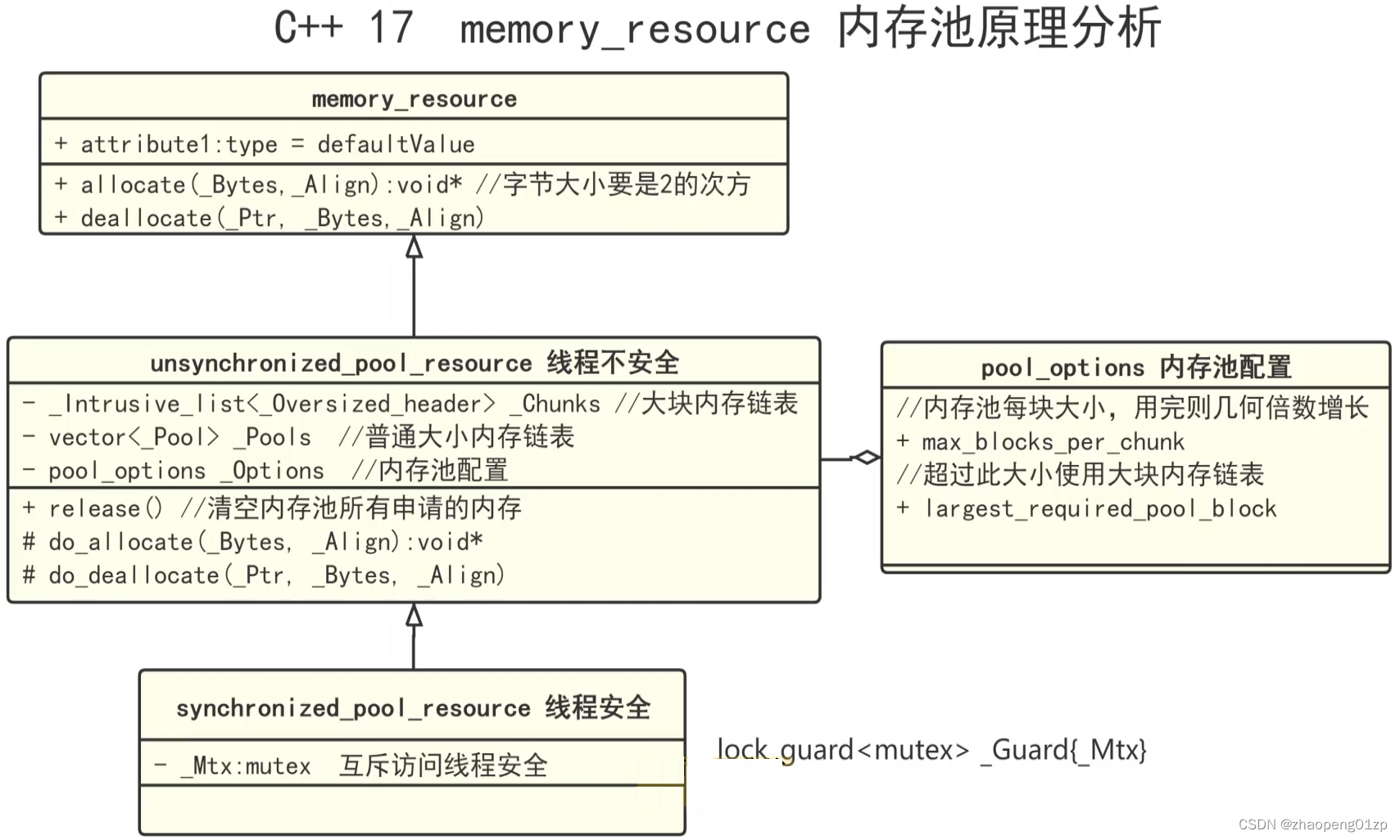
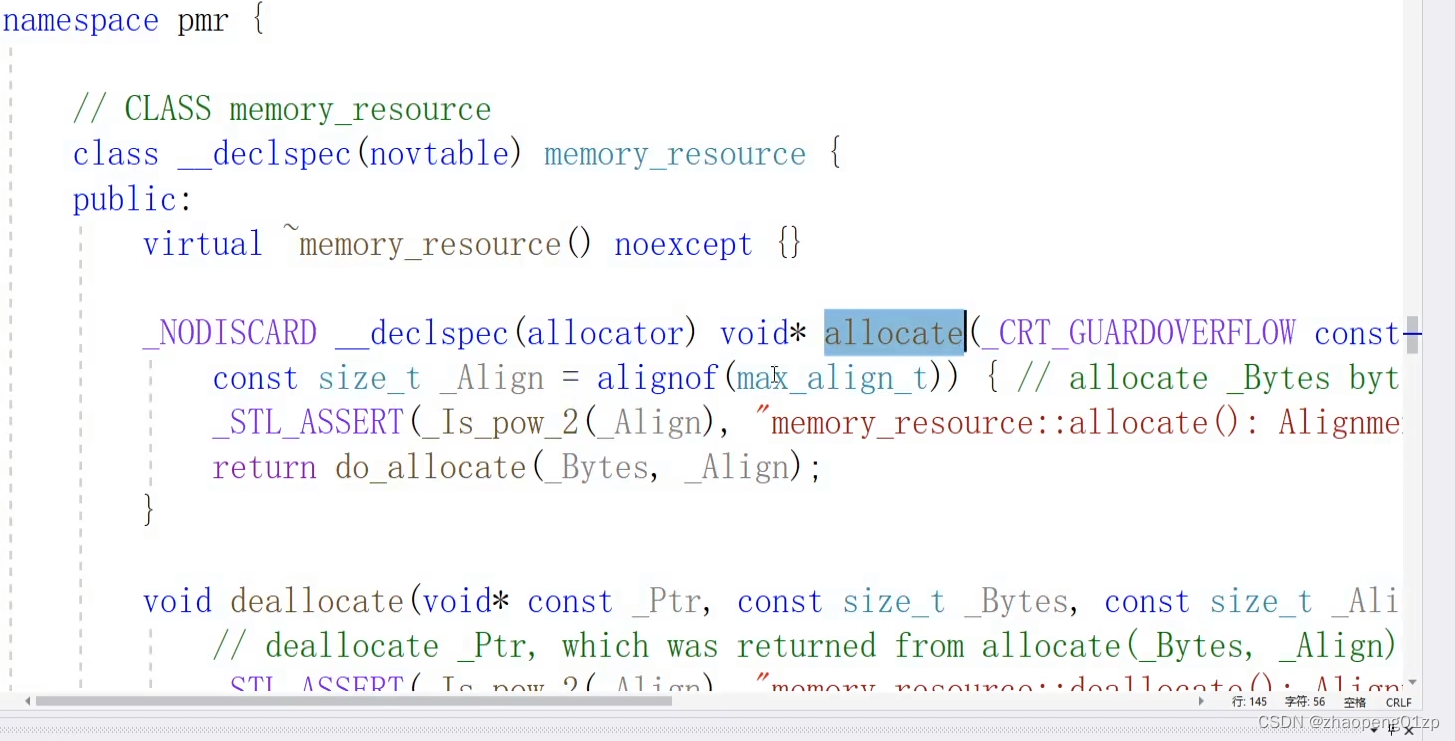
- 1、c++17内存池memory_resource内存池原理
- 2、c++17内存池synchronized空间申请源码分析
- 写代码测试内存池
- 3、c++17内存池空间释放代码分析
第三章 分配器allocator和new重载
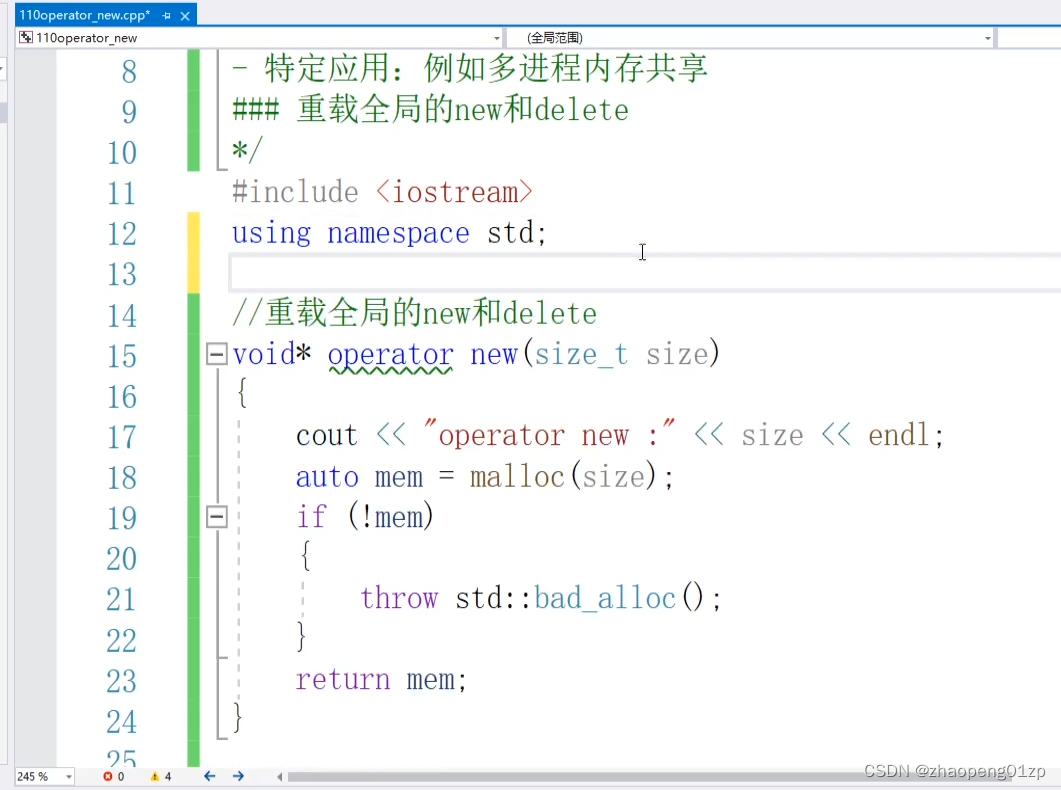
1、重载operator的new和delete包括数组



可以看到我们的TestMem类里面没有成员,没有成员的话它new出来一个空间它至少也要占一个字节,也就是说它new出来一个对象,至少分配的是一个字节;
如果给它添加一个int成员:



如果是new一个int类型呢:

如果我们访问的是一个数组
我们申请一个int类型的数组空间,和一个TestMem类型的数组:
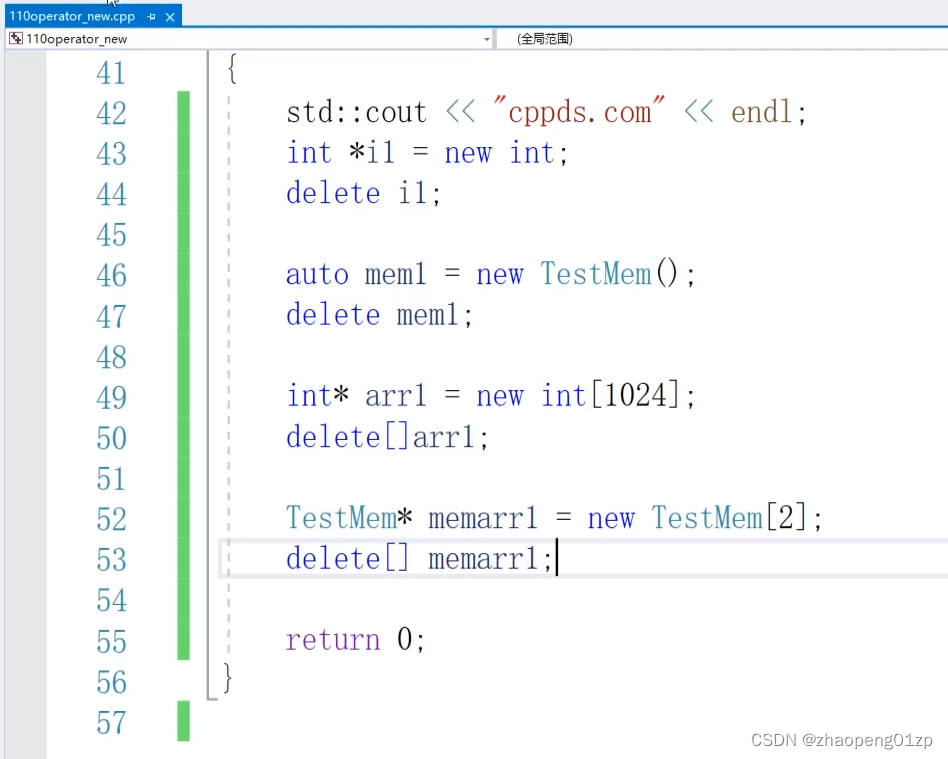

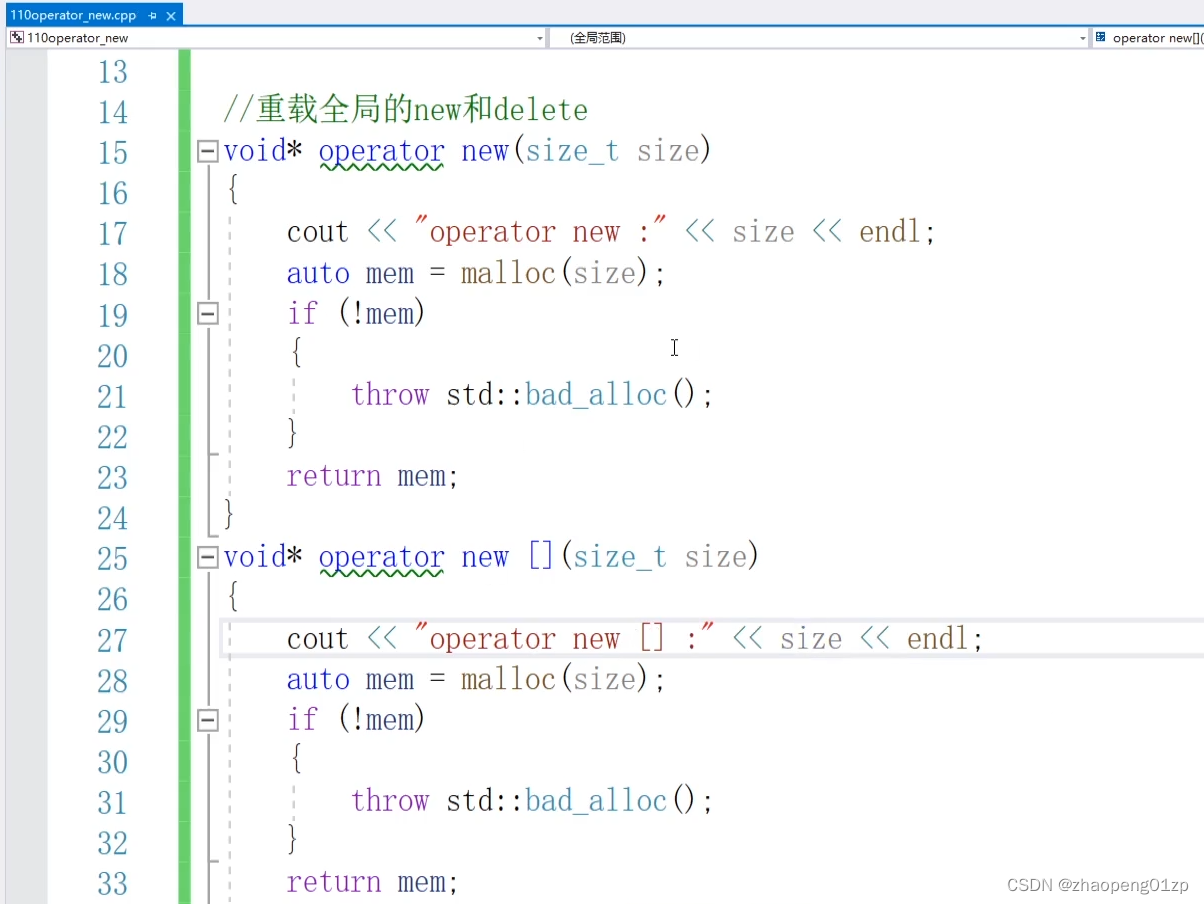
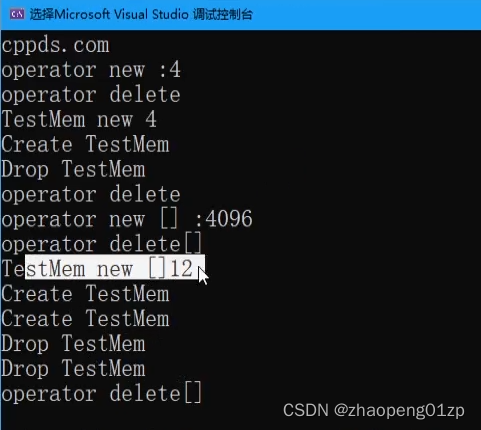
我们把new一个普通的对象和new一个数组的操作符区分开来;
我们重载操作符new访问数组的函数:

我们new函数是在进入构造函数之前先进入的, 因为你得先有空间,才能够做构造,因为构造肯定是在你的内存空间基础之上来做构造的。
我们重载清理的函数:


我们从上图可以看到,进入构造函数,然后进入析构,析构完了之后最后才调用的delete,因为析构的时候其实是还能够访问内存的,所以这时候你不能把空间删掉,基本上是在析构之后调用的delete,也就是说只要进入到我们delete函数,表示这个对象已经析构过了。
2、类成员操作符new重载和放置placement_new
对于大部分项目来说,重载全局的new其实是很危险的,特别是你做了一些特定操作的时候,当然你可以在debug模式重载一下,用来记录所有的内存的申请和分配;
很多情况下,我们只希望是在某一个类的时候,它的new出来的这个过程我们去控制,而针对其他类的内存我们不用去控制。


但是我们发现在操作数组的时候,我们是调用了全局的数组函数,那也就是说我们要把这个数组函数进行重载:
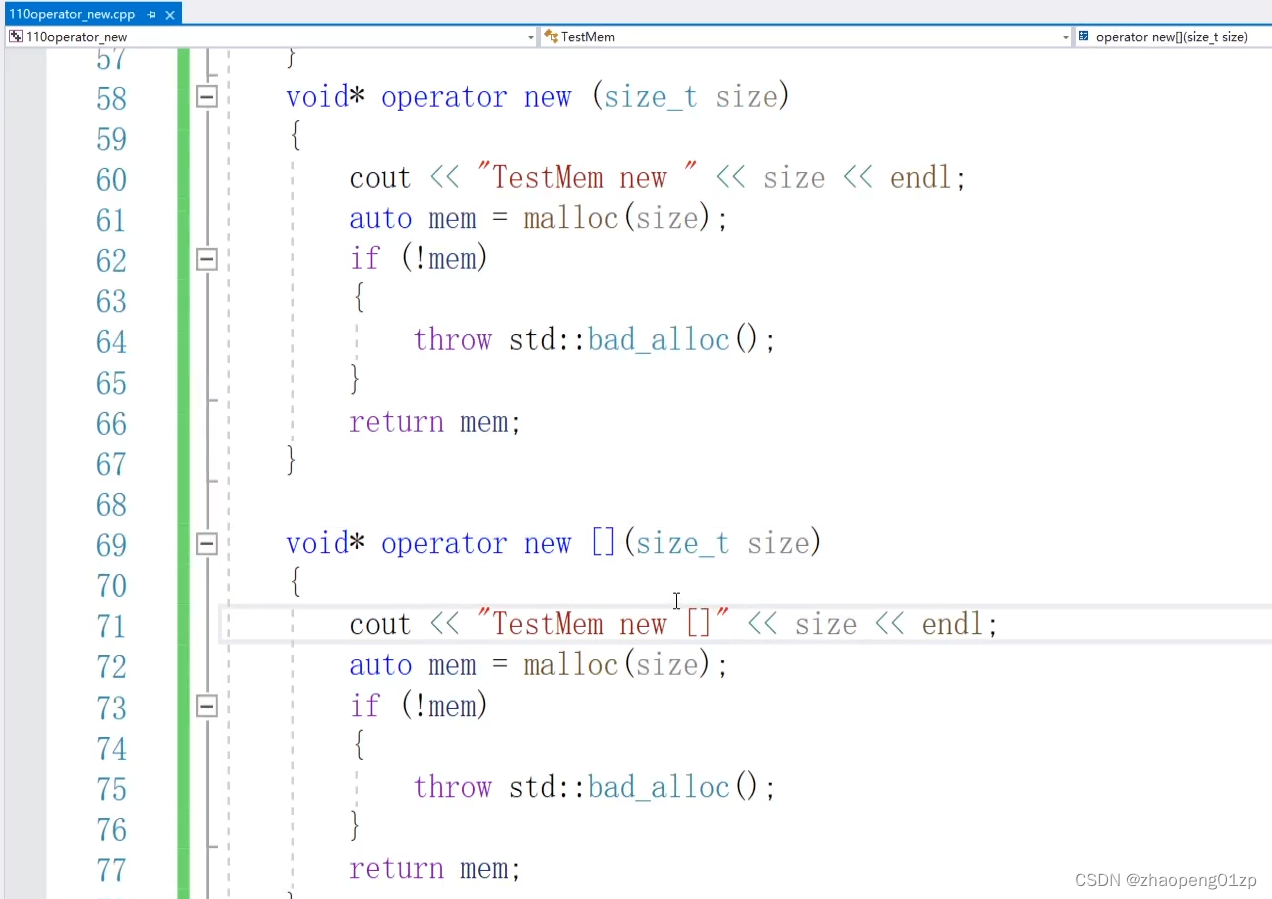
当你调用、生成这个TestMem对象的时候,它优先找我们类当中的成员,找不到的话再去找你重载的new,再找不到的话就去找全局的、本身的new。
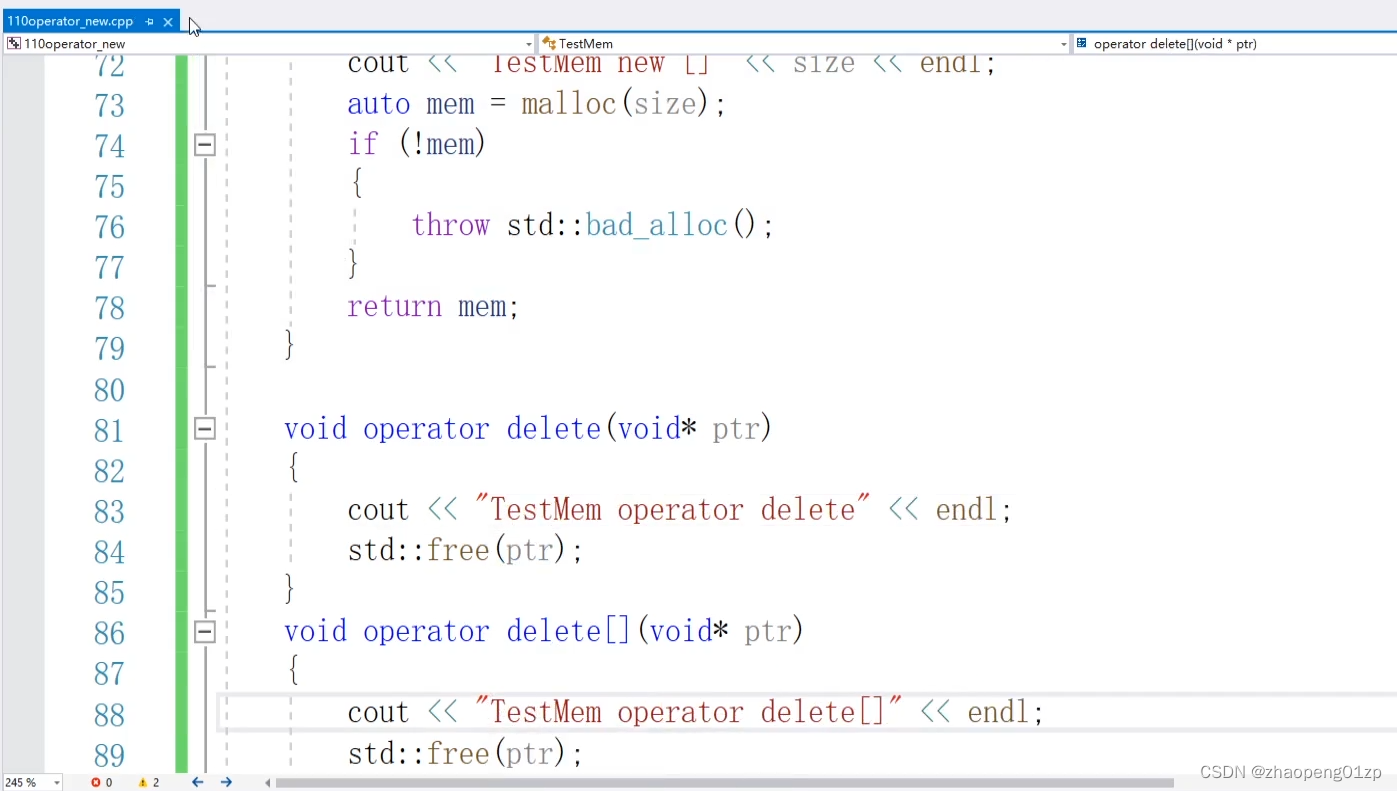
我们把delete和delete[]也在TestMem类当中进行重载:

placement new(放置内存)
在一些特定的需求当中,我们要分配一个对象的时候,我们让它在以后的空间当中创建;
或者是我们把空间的创建和对象的构造给它分割开来,这样可以加快我们的效率;
当然还有一种情况,我们想new出一个在栈当中分配的空间,但是这个方式使用的时候我们要注意的一点,我们这个new调用之后,它生成的空间是不会释放的,也就是说不需要你去释放,因为这个空间你并没有生成,你只是在指定的空间当中做了对象的初始化。
在栈当中分配空间,其实我们就不需要对它进行释放了,注意啊,你准备好的这个空间要大于你待会要放置的空间:
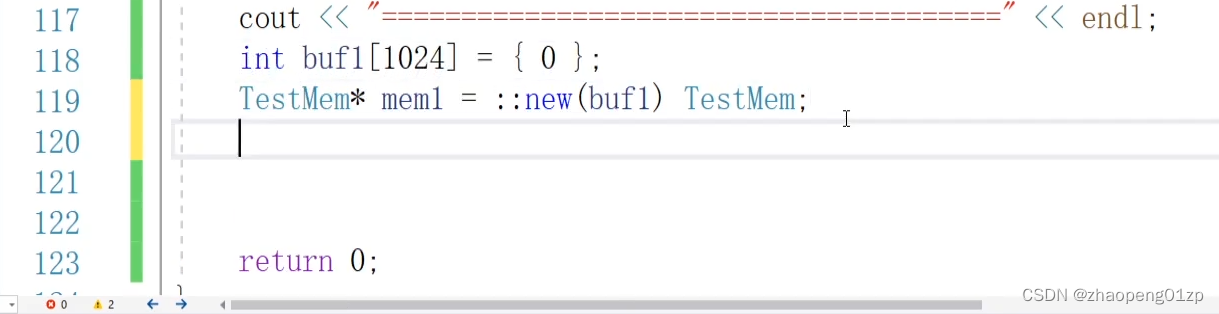
我们创建的这个对象是在原来的buf1的地址当中,我们可以试着把这个地址打印一下:


那这个时候我们能不能清理呢,delete是不能清理mem2的,因为这是在栈中调用的。
那如果说要在堆当中调用呢?

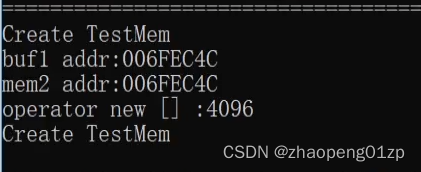
那我们析构该怎么调用呢?
如果我们是在栈中调用的,析构是没法调用的,如果我们delete这个栈当中的空间的话:

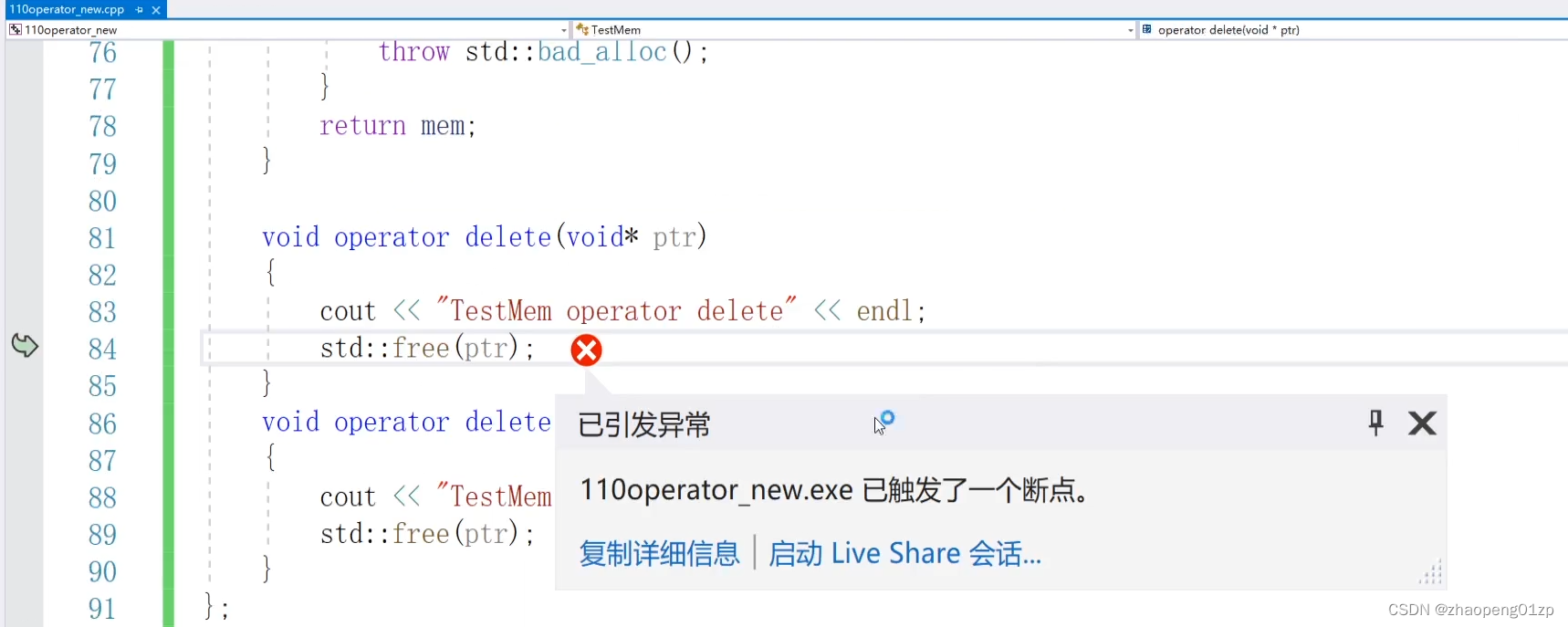
清理栈当中的空间那么程序肯定会当掉的。
我们的析构要自己调用,也就是说析构函数我们自己主动调用:

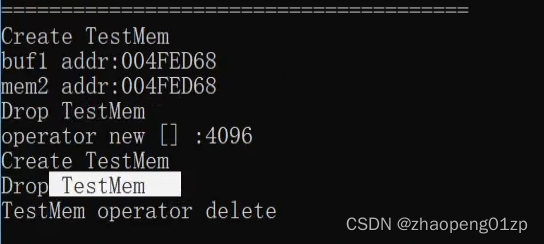
我们也可以对placement new进行重载(对应类当中成员的),只不过会包含两个参数:

也就是说它可以在现有的空间当中来分配我们new的空间,就相当于我们这个空间就不用申请了,但是可以构建它的过程。


3、分配器allocator详解c++17_20新特性说明

我们用标准分配器主要来实现什么呢?
也就是说把对象内存的创建和构造函数的调用给它分割出来,为什么要分割呢?
有时候我们创建对象的时候,在内存分配的时候我们也许一上来分配了1000个对象,但是在业务逻辑当中呢,我们没必要在分配这1000个对象的时候就全部给它们初始化,所谓初始化其实最重点的就是会调用它的构造函数,那我们只有在用到某一个对象的时候,我们内存要提前分配,但是我们再用某一个具体对象的时候再对它进行初始化。
我们刚才讲了,分配器除了把算法和存储细节隔离开之外,它同样可以实现对象内存分配和构造分离;
正常情况我们如果new一个对象出来,它的分配和构造一起做的,有时候我们要把它分开了来做,我们也是通过分配器来实现。



总的来说就是根据你的类型大小,new出来一块size这么大的空间。
我们编译运行看看:

可以看到内部调用的时候,它其实调用的是new函数,它并没有构造,也就是说这一步是不构造对象的。


你可以看到其实的过程,它也没有调用析构函数,所以说在我们使用这个内存分配的时候,就需要我们主动地去控制什么时候调用构造和析构,也就是说析构的调用权也交给了你。
那我们怎么去构造呢?比如说我们拿到了这块空间,那怎么去调用它的构造函数?

我们可以看到构造函数就被调用了。


4、自定义allocator演示vector和list分配器

在这里的通用分配器有时候是外部条件传进来的,包括我们也可以去实现一些算法内部提供的分配器,也就是说我们通过外部传递然后来实现分配,这样把整个的空间分配和业务逻辑做这样的一个解耦合。
我们可以看一下现有的vector是怎么做的,然后我们再来看我们怎么去实现这样一个自定义分配器。


因为vector里面存放的是XData,不是指针,我们存的是对象,所以说这个push_back它每次其实会复制一份到它内部的内存。

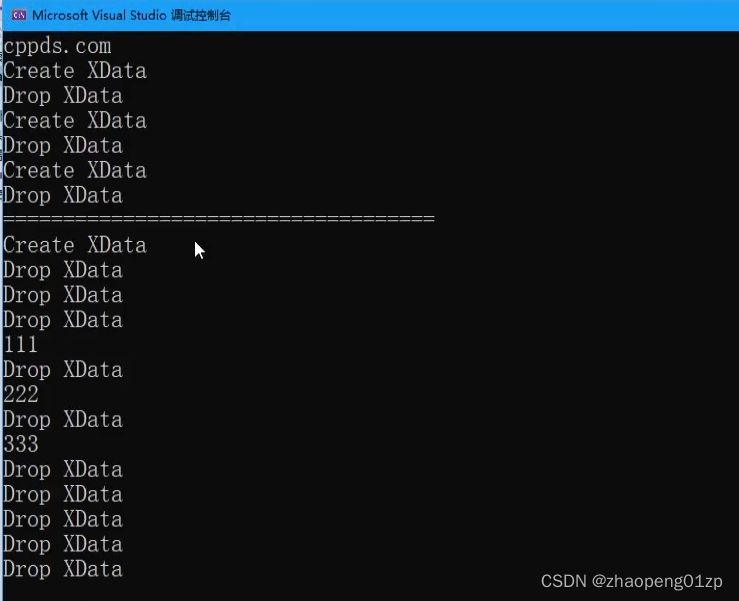
我们可以看到全是Drop,我们为了监控它的复制,给XData添加一个拷贝构造函数:


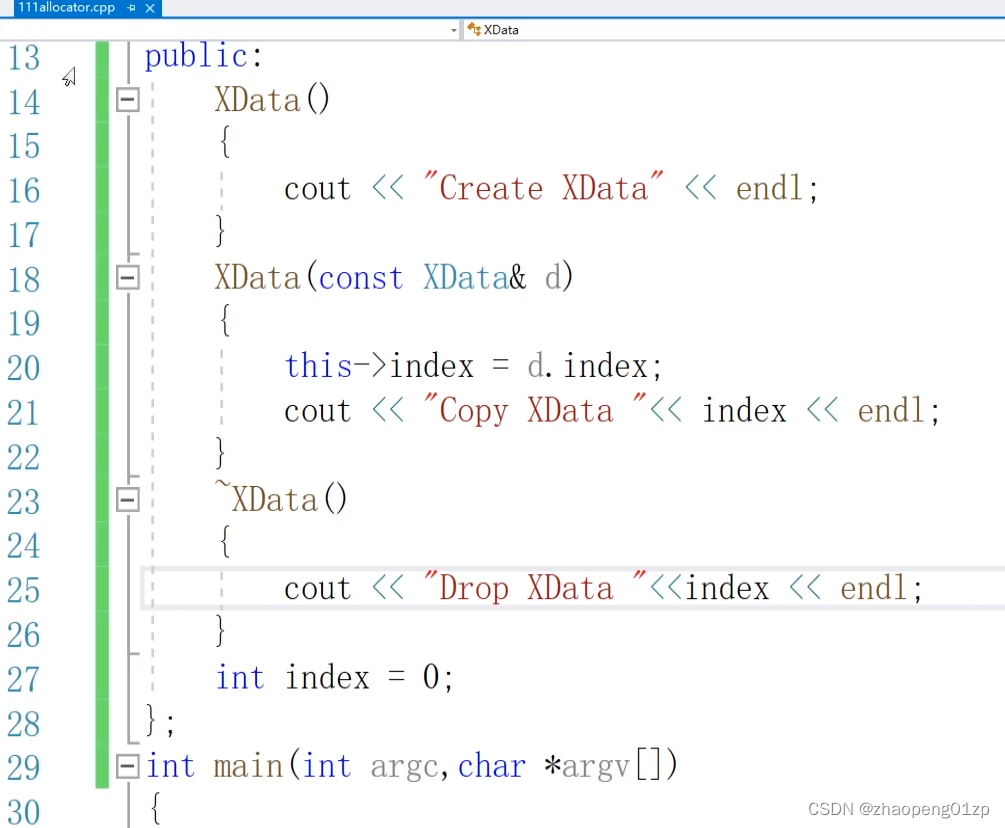
编译出错,拷贝构造函数的参数是要加const的。

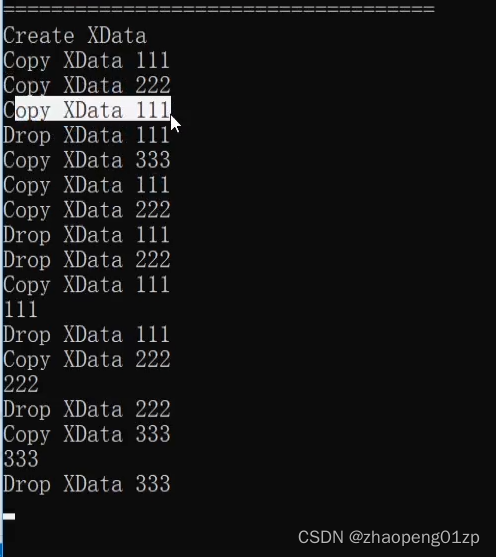
从上图我们可以看到,再次Copy 111的时候,它可能重新划分了一个空间,然后把之前的(第1个XData 111)给释放掉,然后后面继续拷贝;
我们修改for循环里面的代码,把xd换成引用,否则我们在这里面读取的时候又做了一次拷贝,我们换成引用的话减少它的拷贝。
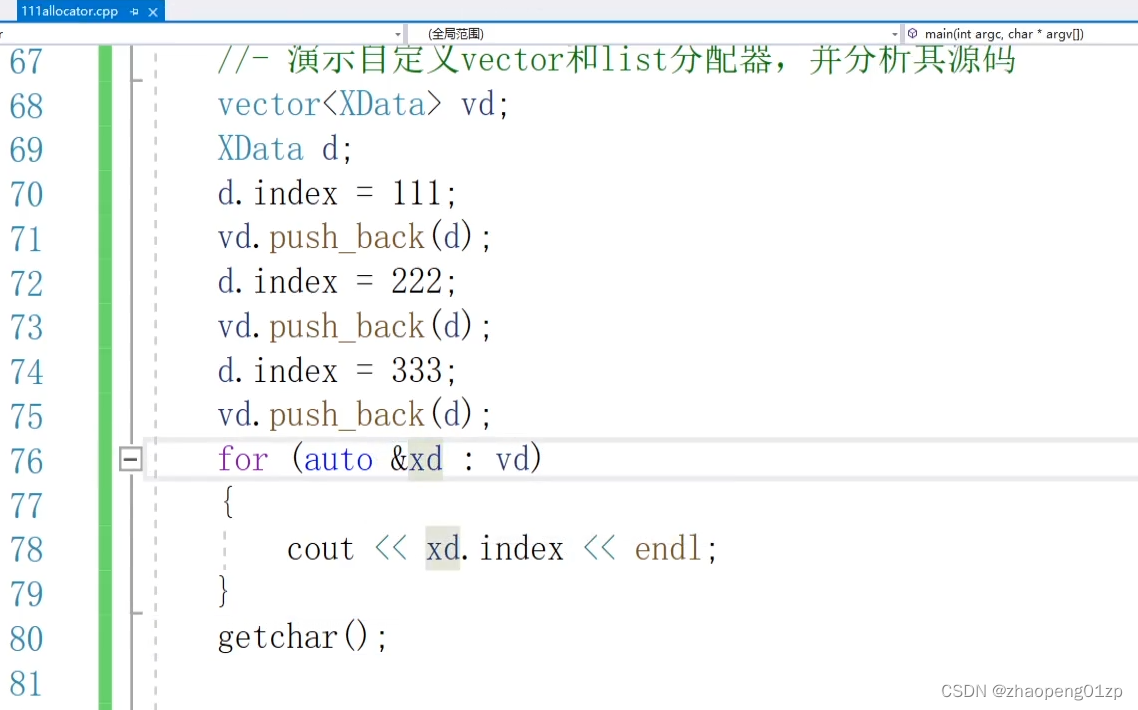
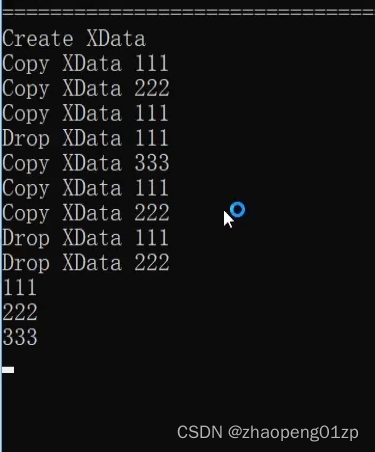
这样输出就清晰一点,其实它做了一次内存的移动,把整个的空间增大之后,要把原来的空间清理掉。
所以说它整个是这样一个过程:
首先,第一次创建的时候,它可能预先分配好空间,当空间不够的时候,它会申请一块更大的空间,然后把前面的空间复制过来,并且把前面空间释放掉,有这样一个过程。


现在换成我们自定义的分配器

我们可以看到vector是有两个模板参数的,第一个参数是容器的类型,第二个参数是allocator,也就是说vector它默认使用了allocator的分配器。
那这时候我们把它换成自定义的allocator分配器,这里面不要涉及继承,因为这是模板函数,所以也不存在继承的概念。
模板函数就是声明跟定义不能分开了,声明跟定义只能在一起:


我们先编译一下看看错误:
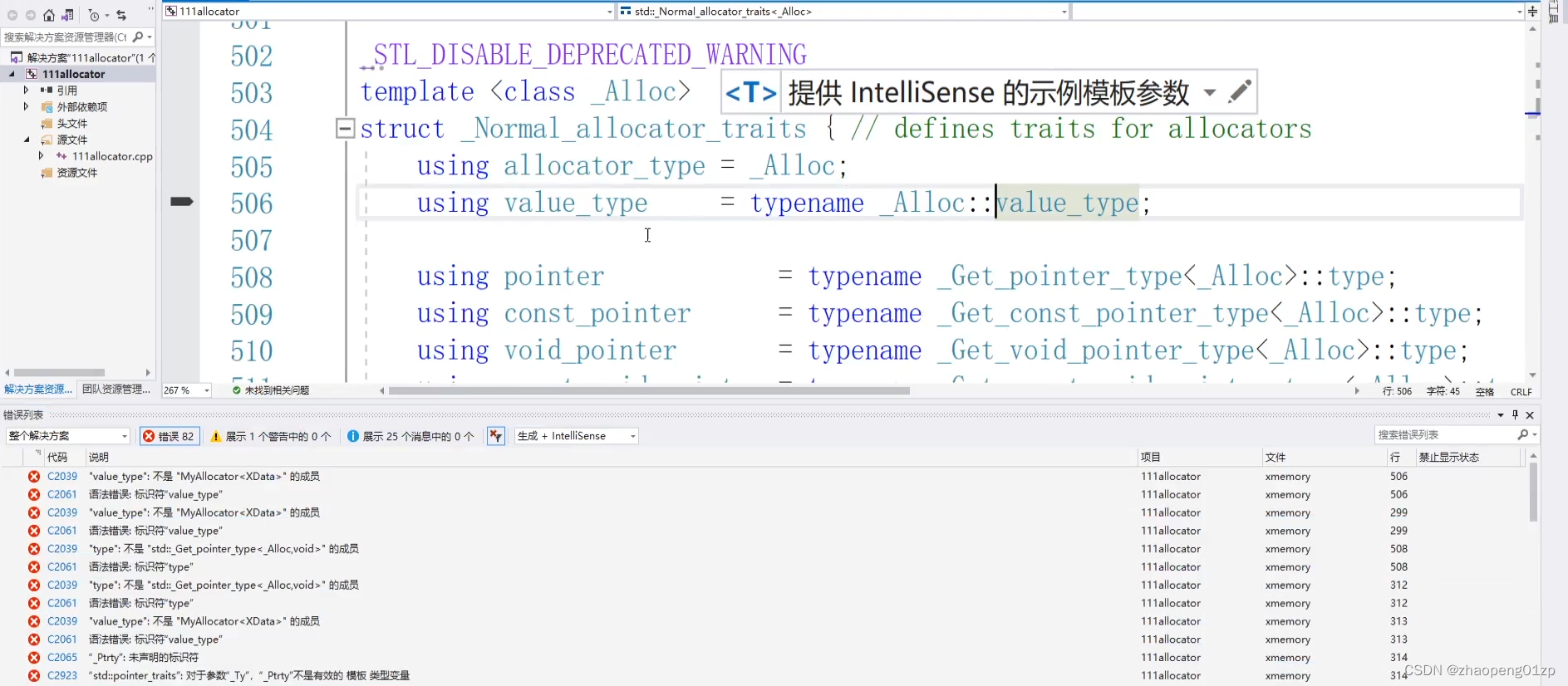
可以看到它有一些特征,它用到了一个叫做value_type,因为它里面的代码会用value_type去做一系列的事情。


这里面的函数名称是固定的,如果你写错名称的话,它的调用会找不到这个函数,也就是说在我们的vector当中它会调用这里面相关的函数,所以名字要正确。
我们编译一下可以看到错误:


因为vector也是一个模板容器,它其实不知道我们这个MyAllocator中的Ty类型,vector去访问的时候它里面自动生成的代码都用的叫value_type,也就是说它会用value_type去作为类型的方式,因为vector本身支持任意的容器进来,所以说它的类型名不固定,那这时候我们就把所有的类型名都给它指定成value_type,它后面的代码都可以用value_type就可以实现我们这样一个隔离分开的功能,所以说这个value_type要加进来。
我们再编译一下:
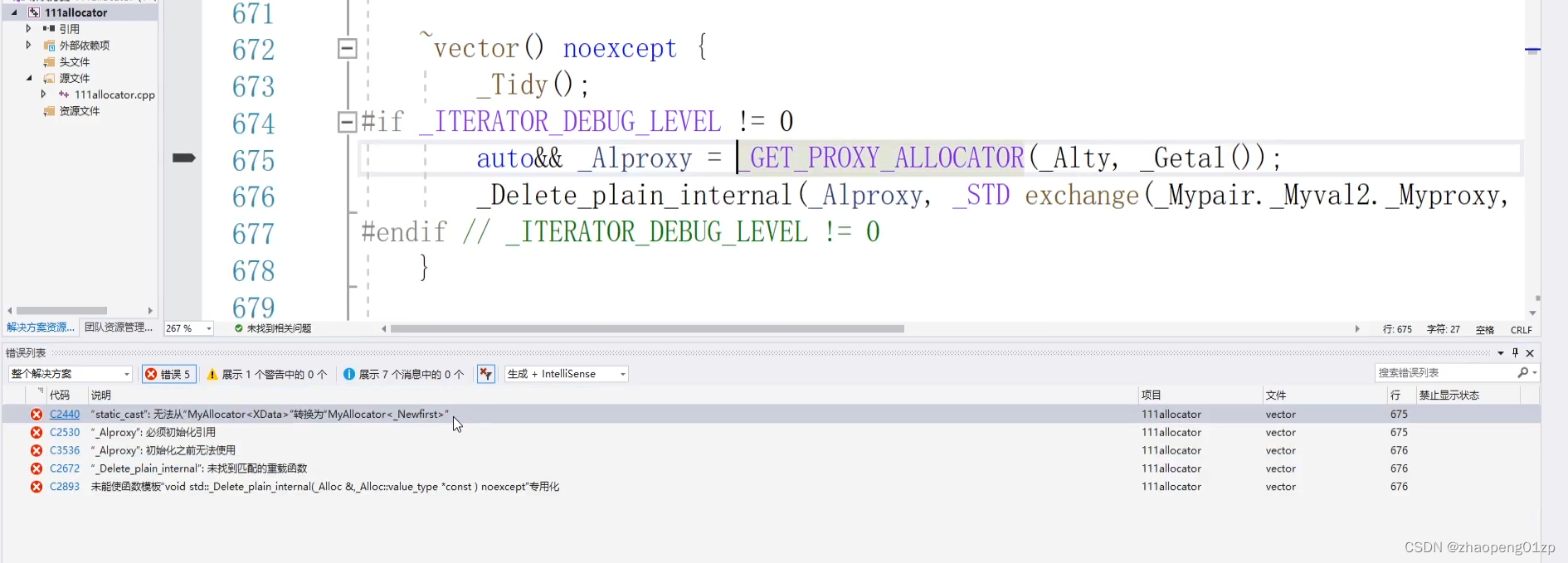
它这个错误是在析构部分。
在它内部的实现要替换成另外一个类型,当然我们这个函数可以什么都不做,因为这里我们用不到,如果说要用到的话,我们还需要再重载另外一个,把当前的分配器指向另外一个分配器,虽然用不到,但是vector内部实现的代码有调用,所以我们得提供它,提供个空的就可以了。
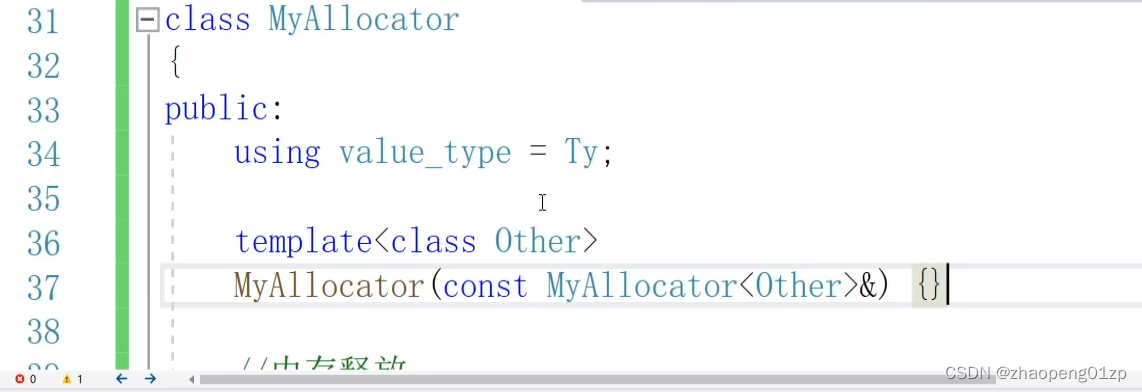

因为我们添加了一个有参数的构造函数,所以需要补充默认的构造函数:



我们给分配和释放添加上输出代码,来监控一下整个过程,它什么时候来跟我们申请的空间:



我们可以看到,第一次申请了一个空间,第二次申请了两个空间的时候,它会把前面的空间复制到我们新的空间当中去;
allocate 3,又做了一次复制,当然了,整个的减少复制过程的流程就需要你自己来做了。
我们每次push_back的时候其实会申请一块新的内存空间,第一次申请1个,第二次申请2个,第三次申请3个,其实这样做的效率是不高的,所以这个优化过程由你自己来写这样一个算法,比方说最大容量放多少,第一次一上来就给它申请1024个,到后面申请的时候直接返回这个空间的地址就可以了,也就是说第二次申请的时候就不需要再给它新的空间,这个根据你的业务逻辑来,这里我们只要把流程给它跑通就可以了。
我们可以把类型打印出来看看:

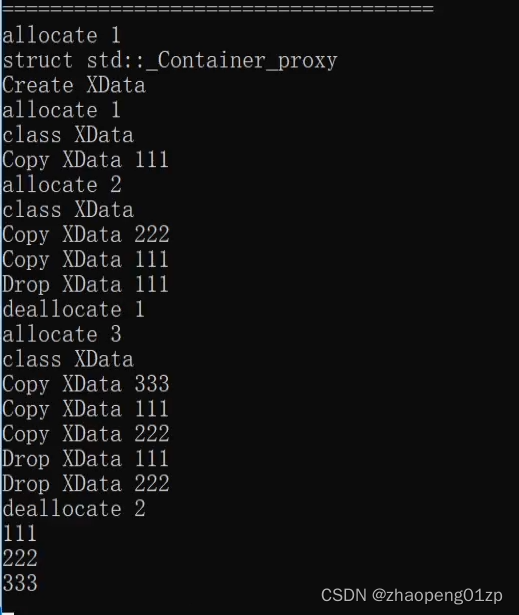
我们可以看到,第一次它先往容器里面加了一个Container_proxy,通过这样一个分配器我们也是可以进一步跟进到容器的代码当中。
我们再试一个list容器

list跟我们上面的vector不同,vector就是一个固定的数组,而list它是一个链表结构,它的类型申请其实是每push一个内容,它都会去申请一块内存。

list每次分配的是1个空间(allocate 1),所以你在做分配器的时候就要考虑到它的这个分配空间。
我们给for循环里面的代码换成引用(因为auto它不会自动推导出引用):


5、未初始化内存复制分析uninitialized_copy

我们把一个对象复制到一块未初始化的内存当中,什么叫未初始化的内存,malloc直接申请的内存就算是,或者是你明明要存放很多的对象,但是你是new出来的一个char的空间,并不是new出来整个对象;比方说你new 1024个XData对象,那这个就是已经初始化过的,所以不需要你去做相应的处理,而我们很多情况下,我们拿到了一组对象,我们希望把它复制到一个我们本地的内存当中去,这是经常涉及到的数据交互。
很多做法怎么做呢?
如果是C语言编码的话,那就memcpy,如果是C++的话,我们可能用std::copy直接把整个内存复制过去就可以了;
那为什么我们有时候会用到uninitialized_copy这样一个未初始化的复制方法呢?
它会调用拷贝构造,它会把对象进行复制。


我们希望把上面的datas复制到我们buf当中,并且确保在这个buf当中存储的对象是经过初始化的,或者是调用过拷贝构造的,那我们一种做法是直接调用memcpy。
但是这种有什么问题呢?

我们可以看到它没有调用拷贝构造,这里面就有问题了,如果我们这个XData里面有指针指向的空间,有个堆空间,那这时候这块空间可能就是无效的了,通过memcpy就做不到拷贝构造,为了解决问题,我们手动来得做一遍复制。
我们再来看看C++的std::copy方式:



我们可以看到,std::copy同样也没有调用我们的拷贝构造函数,也就是说它不是生成一个新的对象,它是做的一个把内存空间整个复制的过程。
那我们如果希望它重新构造呢?

我们把赋值操作符等于符号=进行重载:


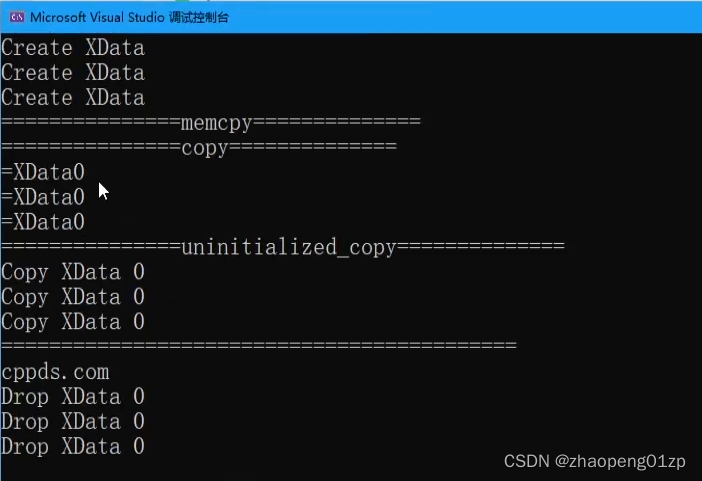
我们uninitialized_copy这种方式是把整个对象做了初始化,并且以传进来的值作为拷贝构造。
6、c++17 20 construct对象构造和销毁
之前我们的构造是调用了C++11开始就支持的allocator_traits里面的方法来获取了对象,在C++17和C++20呢也提供了一个简化的方法来调用构造函数。
为了使用C++17和C++20要设置项目属性、常规、C++语言标准为预览 - 最新C++工作草案中的功能:
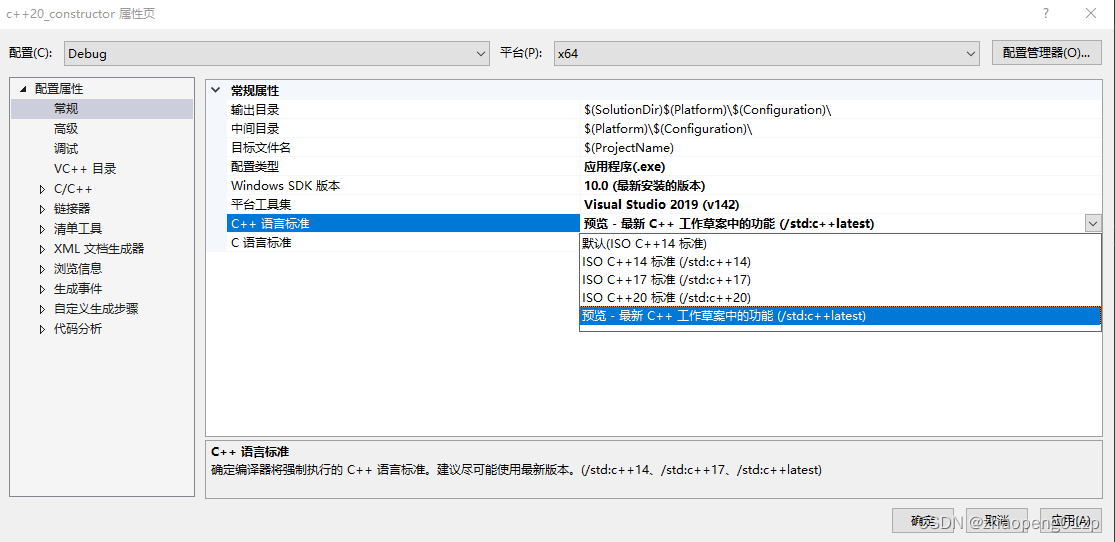
接着我们写代码,分配一块空间,在现有的空间中构造对象:

我们可以看到调用了构造函数,但是退出之后并没有释放这些对象,因为这里面我们是主动调用了构造函数,因为空间是在malloc中申请的,所以最后的话我们要free把空间释放了,当然用free释放的话,是不会调用对象的析构函数的:


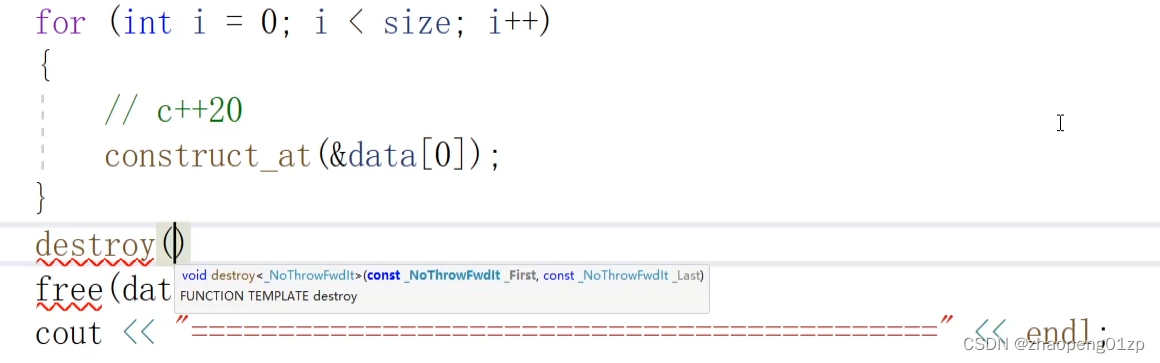
我们可以看到C++20的destroy的两个参数是像迭代器一样的指针,表示开始指针位置和结束指针位置:

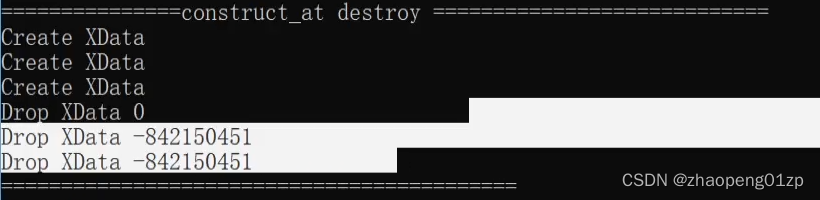
上图这是由于我们在for循环中构造对象的时候下标错了,应改为:

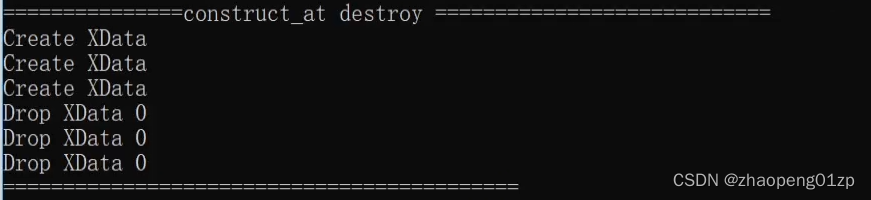
这样的话就完成了构造和析构,当然我们在构造的过程中可以把值进行修改。
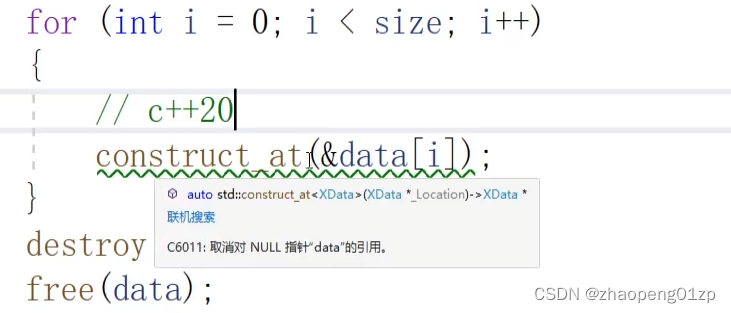
我们看到上图绿色波浪线提示异常:data有可能为NULL,所以我们修改代码对data做个判断来排除异常:

第四章 C++指针与面向对象
1、限制栈中创建对象和调用delete销毁对象
本节课我们来讲一下指针与面向对象的关系,也就是说我们通过指针去操作类当中的成员,包括虚函数它的空间分配情况,我们重点就是指针操作内存,我们看一下在类当中它的内存情况。
我们先来做第一个示例,我们限制在栈当中创建对象,并限制你用delete来销毁对象。
我们为什么要做这样一个限制呢?
你可能会看到很多的工厂方法当中,它会要求你必须用它的接口来创建对象,这也是在设计模式当中经常会用到的,包括单件模式我们也会用到限制栈中创建对象,因为栈中创建的空间很多你是具有不确定性的,就是当你限制用户的时候,就是怎么让使用你代码的人不去在栈中创建对象,怎么达到这个目的呢,你可以写在文档当中、写在说明当中,但是这样的做法大部分人是不看文档的,他先用、先跑起来就不管到底是怎么跑起来的;
所以我们这时候对他做一个限制的话,那我们要在语法层面就让他过不了,也就是说如果他在栈中创建对象,我让他编译不过,那我们怎么通过代码来实现让他不能在栈中创建对象,也就是说只能在堆中创建对象,当然了,我们也限制他在堆当中创建对象必须通过我们的接口来进行调用。
其实这里面我们不是限制堆或者栈,而是说我限制你自己创建对象,必须经过我的接口,这样的话我们在接口当中就可以做统一的处理。
主要做哪些处理呢?
比如说我们是做组合的设计模式,把多个对象拼在一起,增加一些属性,这样的话我们可以做出很多的特性,而不去跟我们具体的类的构造函数相关,因为在构造函数当中我们肯定不能做太多事情,就是在外部来达到这样的目的;
当然了,因为涉及到我们待会会做protected,可能会涉及到友元,那么我们这边尽量简化在当前类当中去创建对象。
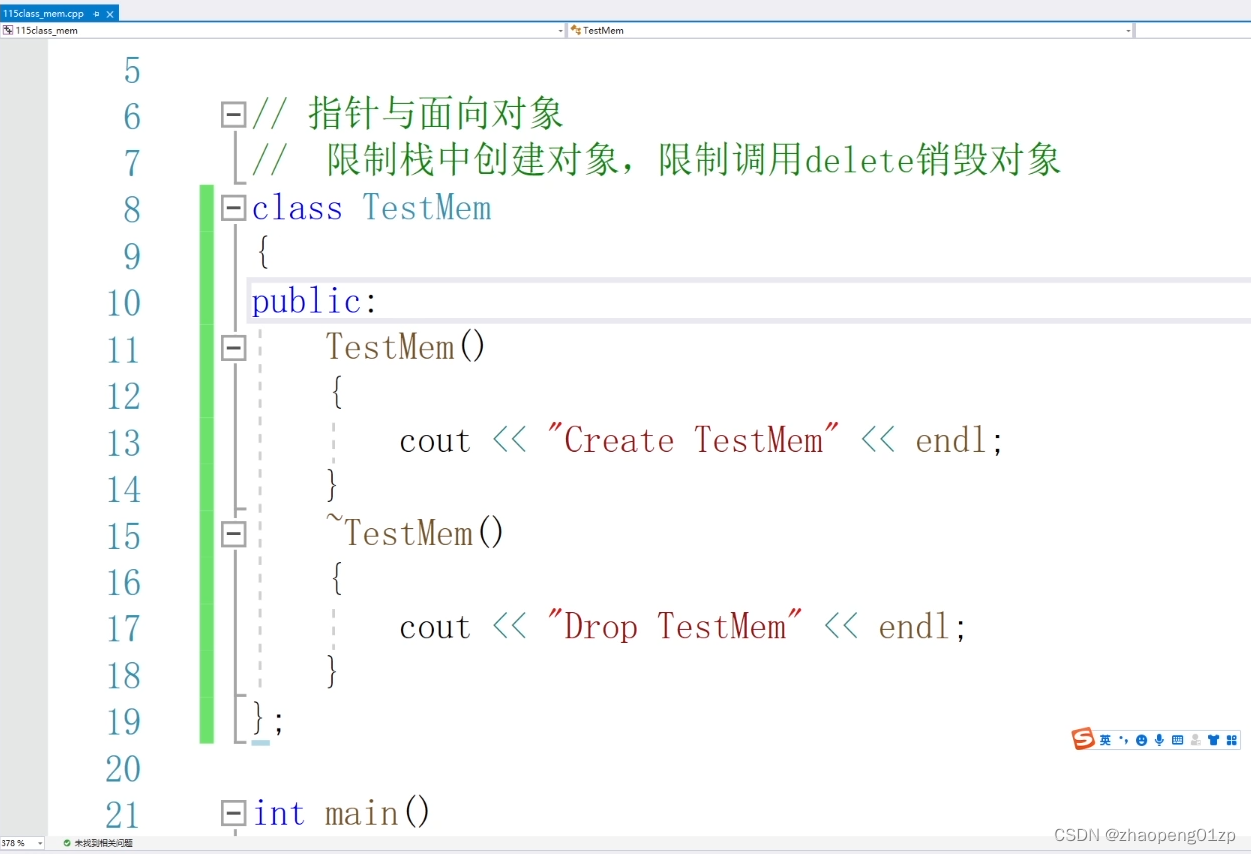

现在默认肯定是编译正确通过的,如果说我们想要限制它,不允许像上图选中那样做,一旦这样做就让它编译出错。
把构造函数做成protected或者私有的:
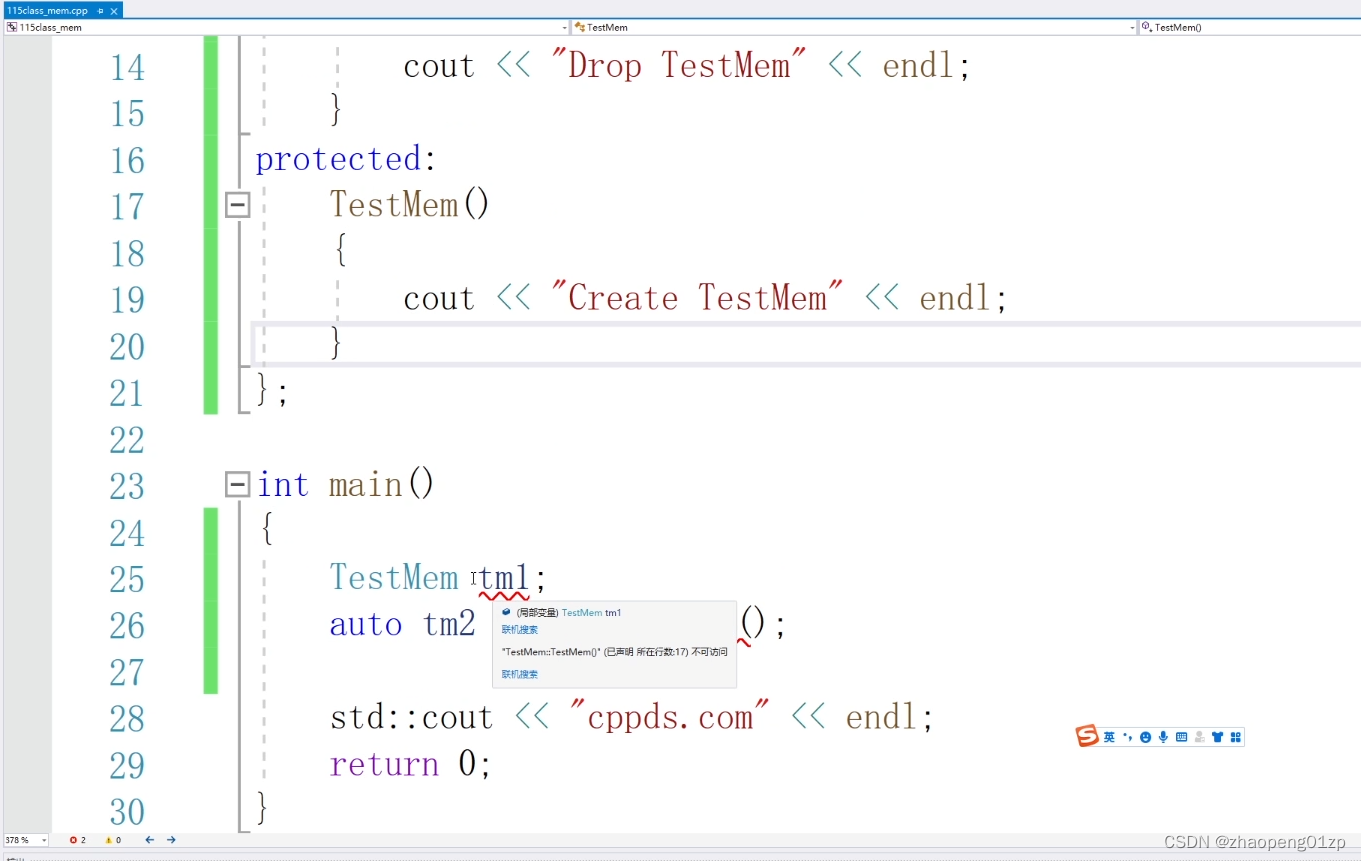
一旦把构造函数放到protected当中,你在外部调用、生成这个对象的时候,因为生成对象的时候是要调用构造的,而构造函数是protected的,只能是它的派生类或者友元才能访问,所以这时候在外部就不能访问。
那它怎么创建对象呢?就要通过我们提供的接口来创建了。
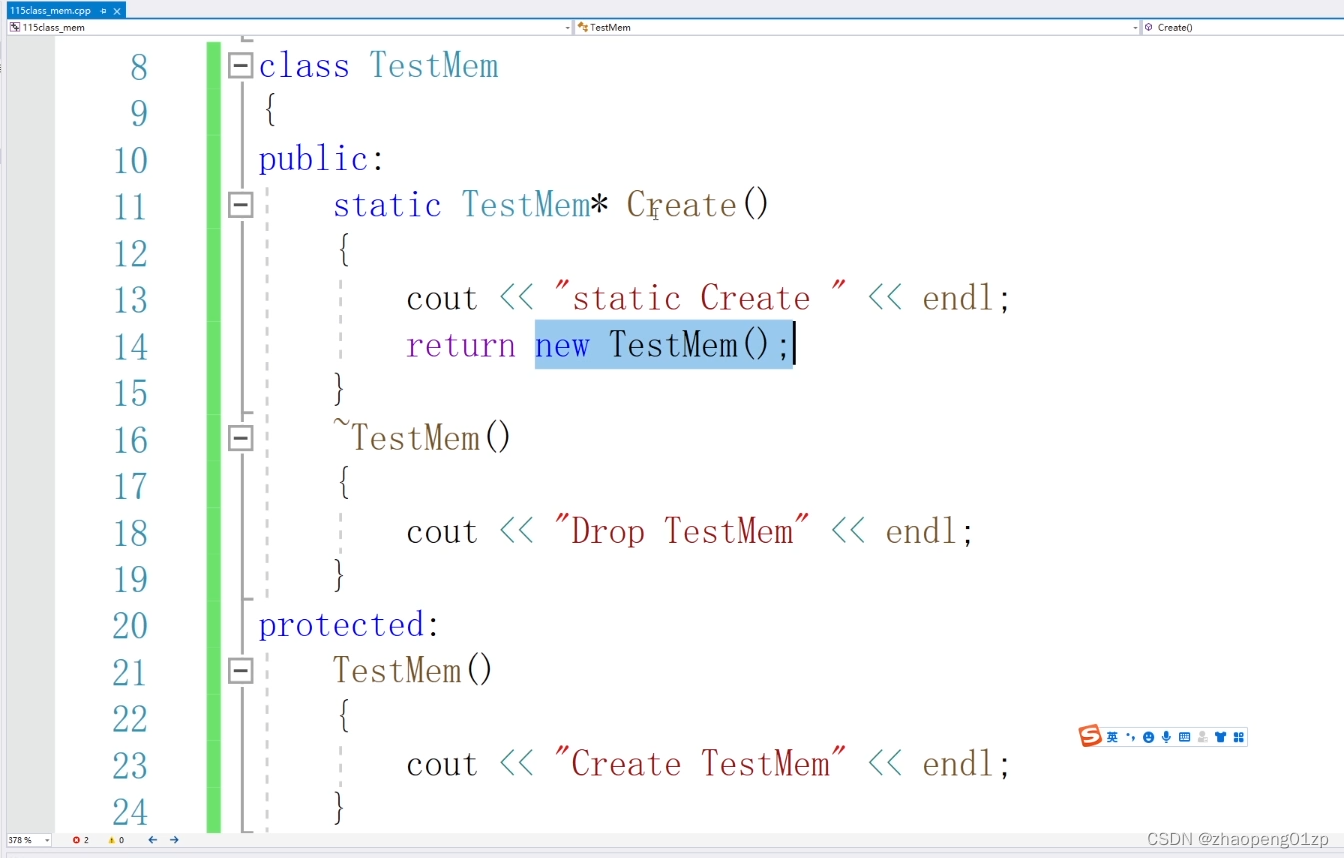
静态成员函数和全局函数的一个区别就是,它能够访问类的成员,包括私有成员和保护类型的成员,包括成员函数,就是这么一个重要的区别。



我们尽量把析构函数做成虚函数,构造函数就不需要做成虚函数了,构造函数不存在虚函数,析构函数要做成虚函数,因为你如果说是用派生类的对象来访问的时候,你可能清理不掉。



整个的清理过程都经过我们内部的方法,这样就限制了在外部直接调用delete,因为你在内部进行清理的时候,你就可以做很多的检查判断。
2、类继承和多继承内存地址分析

其实对象的重点就是它里面存的是什么,就是存的成员变量, 函数的话其实是在代码区;
在堆区或者栈区生成一个对象,它的空间里面存放的都是对应的成员变量,代码肯定不会在这里的,当然它会存一个虚函数表。






错误的理解,会以为派生类A的x1会覆盖基类B的x1,其实不存在覆盖,这两个变量的空间都会存在。


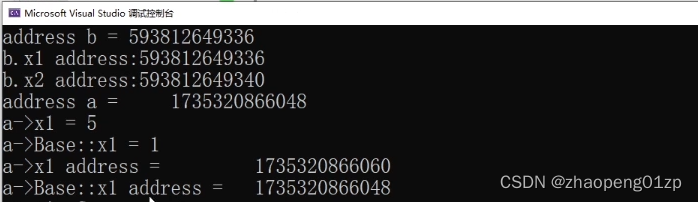
整个派生类A的对象的首地址,里面存的先是基类的成员,然后再到派生类,这就是单继承的内存分布。
多继承内存分析



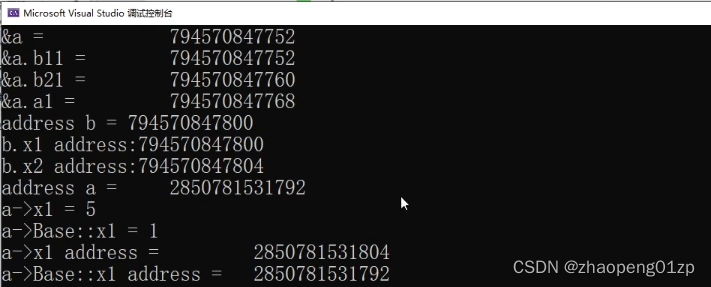
通过这些代码,我们也基本上推导出它的内存空间的分配情况。
3、多继承中的二义性和虚基类内存问题分析



Base1和Base2都包含有C:c1,而A又继承于Base1和BAse2,同一个类的成员C:c1有两份,这时候在代码当中你是没法区分它们的。



现在编译是没有问题,如果我们通过A3这个对象去访问c1的时候,可以看到异常提示:“A3::c1 不明确”:

我们把类C加进来限定一下:

此时你说赋的哪份c1的值呢?这时候我们应该是有两份c1的。
我们可以把地址打印出来:


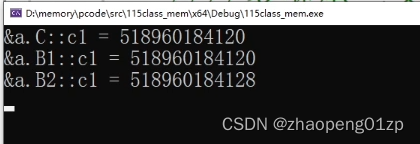
可以看到它其实取到的是B1的c1,这样操作会带来很大的歧义性问题,我们变得不可知,当涉及到调用一些函数的时候,它访问成员的时候,那究竟是访问的哪一个成员,你就没法确定,所以我们其实希望的是c1只有一份。
虚基类、虚继承

这时候我们称C为虚基类。


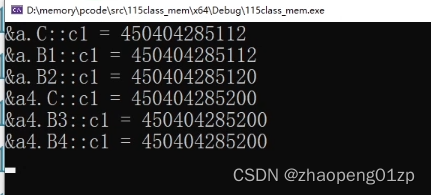
我们可以看到所有的c1是在同一个地址下面,这样就确保了我们只存储了一份。
那你说它是怎么实现的这个功能呢?怎么能确保它只存了一份呢?我们这个虚继承究竟做了什么事情呢?
这是在编译器层面就解决了的,编译器在整个编译过程当中就能够知道你是一个虚继承,它本身也可以在继承的过程当中存放这个空间,因为你编译器必须要指定这块内存的分配方式。
4、虚函数原理和内存分析

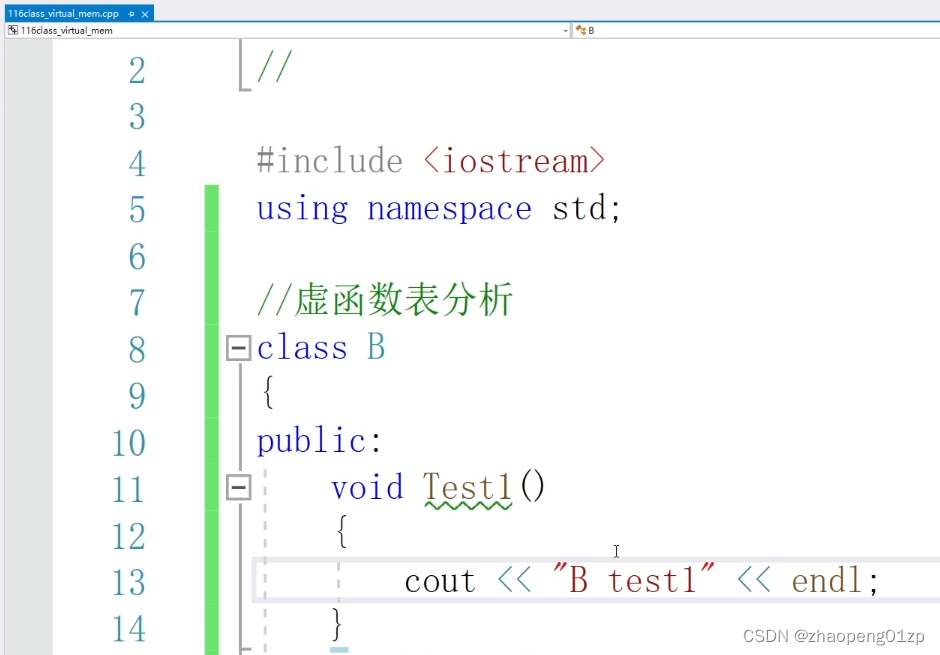


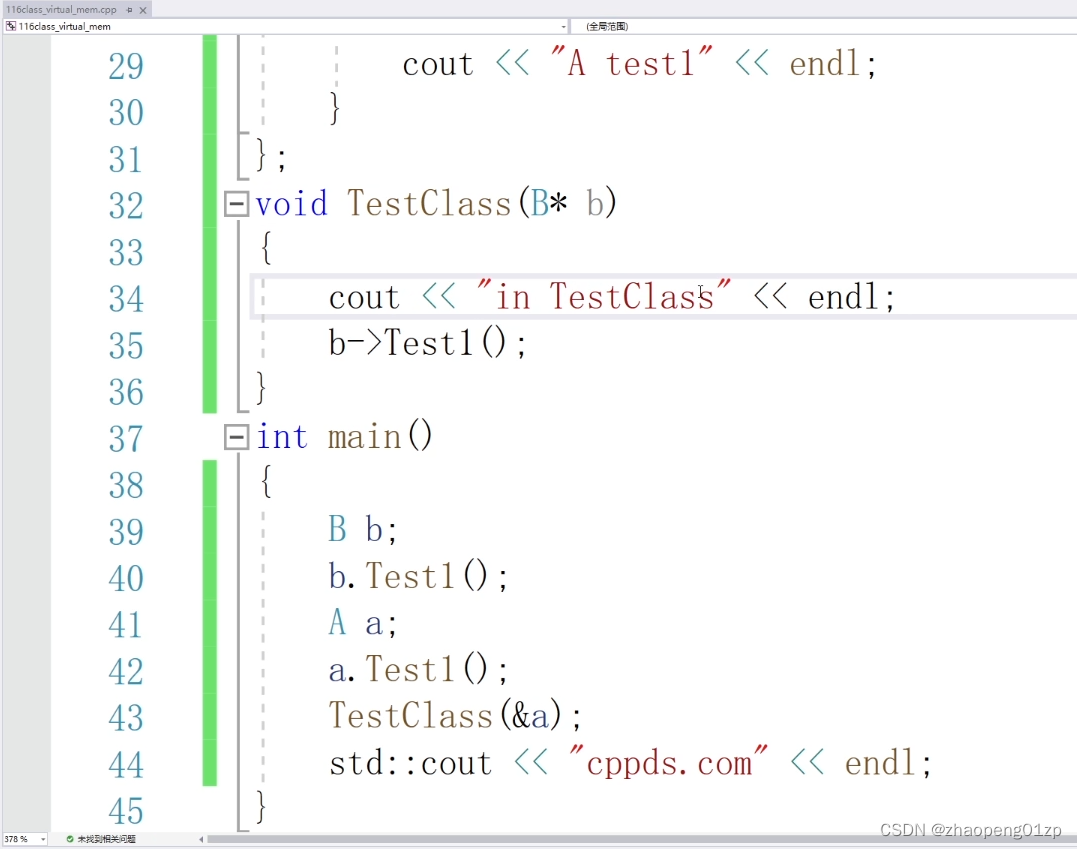

我们可以看到它访问的是B的test1,但是我们传进去的是一个A的对象,我期望它调用的是A的test1,因为经过函数参数的类型转换,转换成基类的指针,因为我们在设计当中经常会这么做。
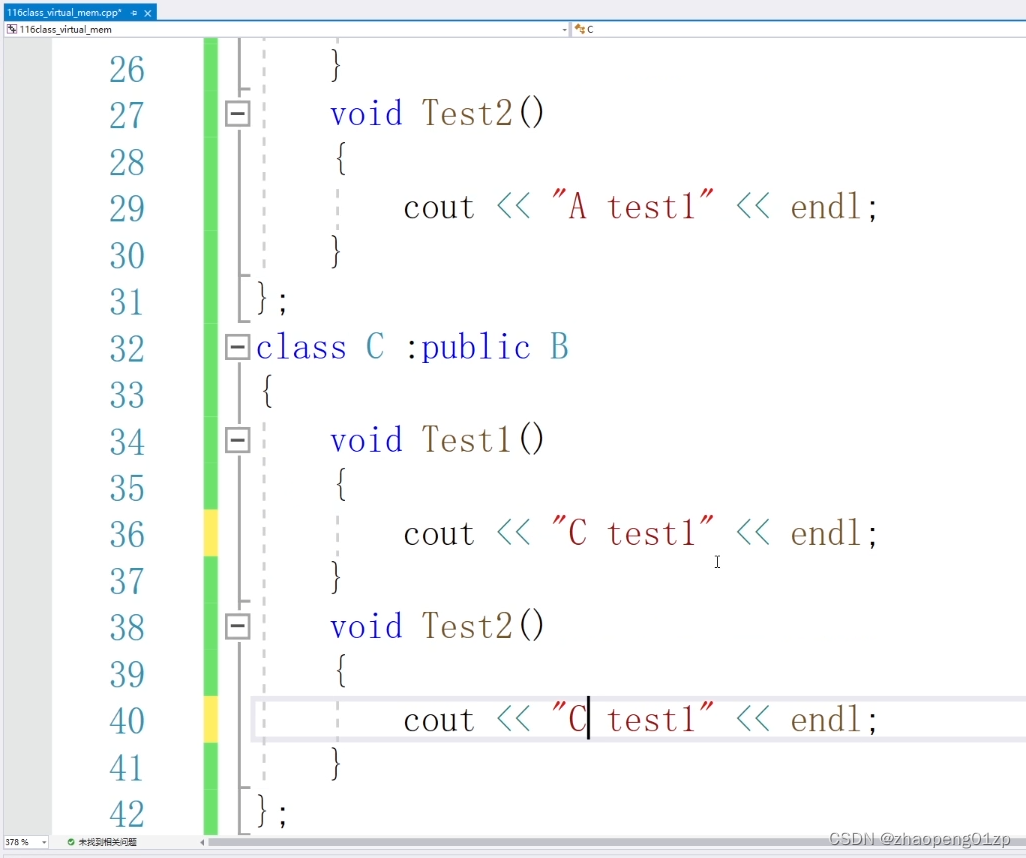
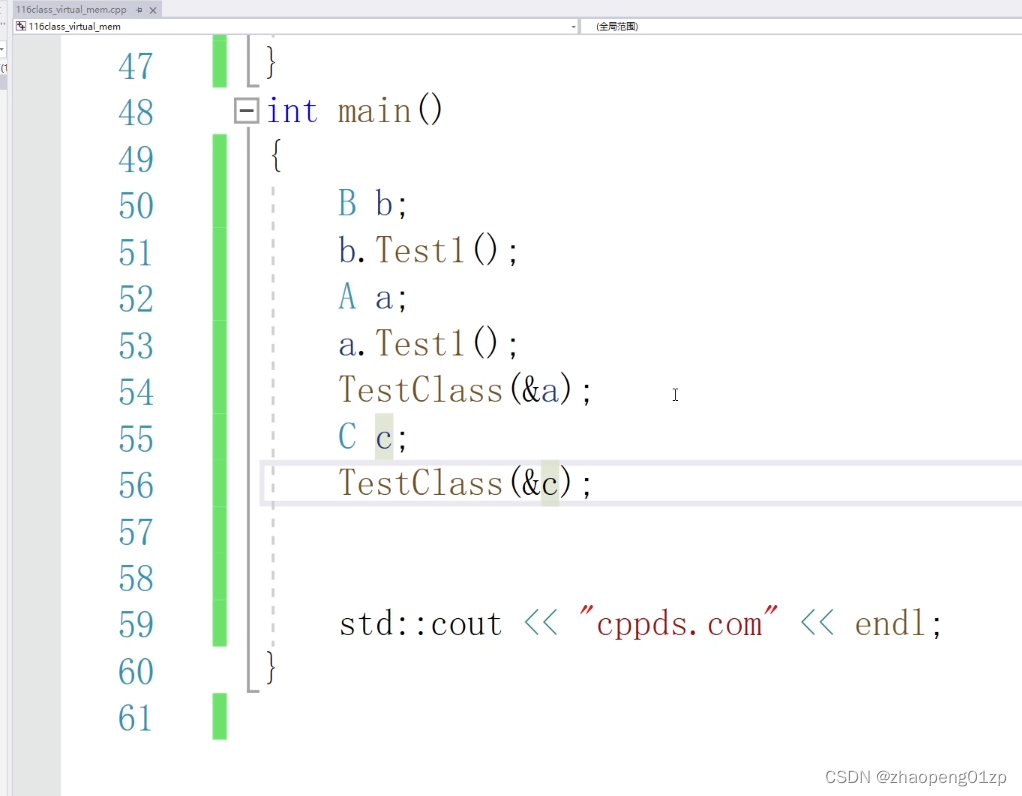

它也是调用的B的test1,而我们期望传递进去是C的对象,它就应该调C的函数,我们传递的是A对象,它就应该调用A的函数,但实际情况不是这样的,那这时候我们怎么处理呢。


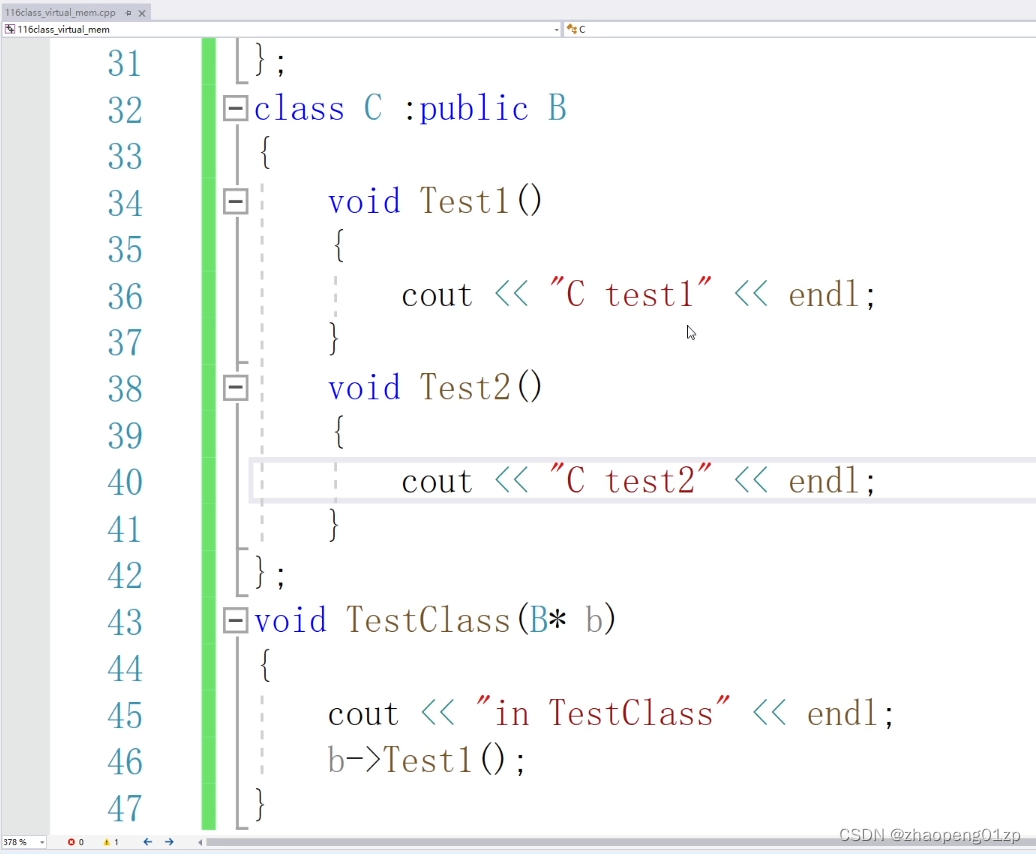

通过设定基类函数为虚函数,就解决了我们传递子类类型转成基类之后,必须要调用实际对象的方法。
你那说在你不定义虚函数的时候,它为什么找不到呢?

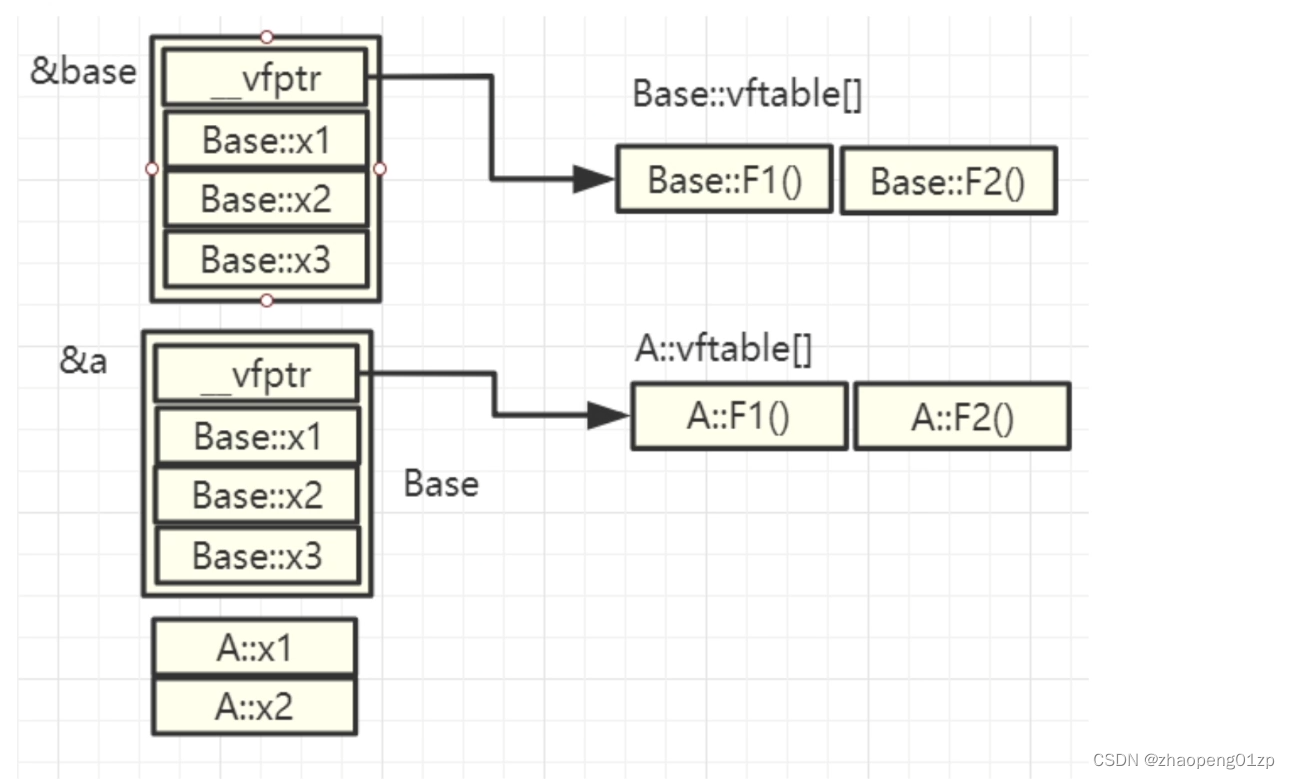
5、虚函数表指针直接访问函数的代码实验
我们来看一下两个同一类型的不同对象,指向的虚函数表是否是同一块地址:

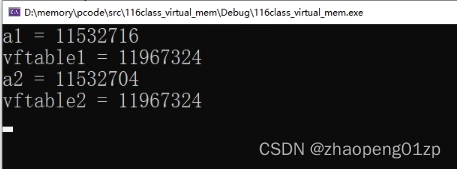
A类继承的是B,那么B的虚函数表的地址跟A的一样么?不一样的,不同类指向的是不同的虚函数表。
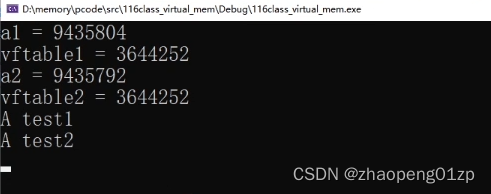
手动调用虚函数表里面的函数
我们通过虚函数表调用里面的函数,因为我们没法把这样的一个int类型转成thiscall类型的函数指针,所以只能做一个普通函数,这样调用也没有问题。


第五章 C++17内存池
1、c++17内存池memory_resource内存池原理
2、c++17内存池synchronized空间申请源码分析

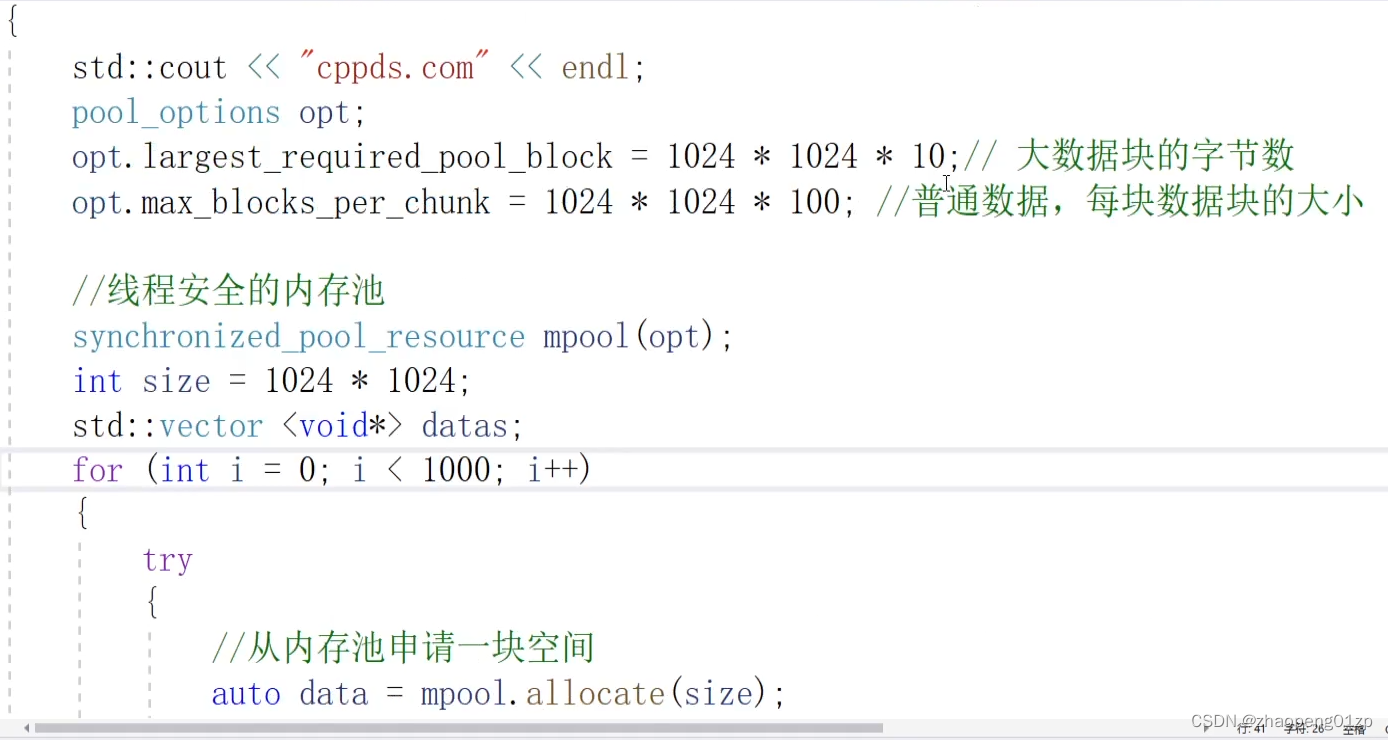
写代码测试内存池
我们先创建好了内存池,然后在内存池中创建1000个小的数据块,把申请数据的指针存到vecor当中,再把它释放了;然后再创建大的数据块,我们来看看小数据块和大数据块在代码当中的一个区别。
实际当中我们什么时候会用内存池,用内存池一定是它的空间不确定的,每次申请的空间不固定,如果空间固定的话那我们就不一定要用内存池了,我们固定的用一个链表自己来运维反而更简单。
当然,这里测试的时候可以让它空间是固定的。




vs2019有内存分析的诊断工具,从右图诊断工具那里可以看到申请了1G的内存,申请速度有点快,我们把速度放慢点,这样可以看到申请的过程:


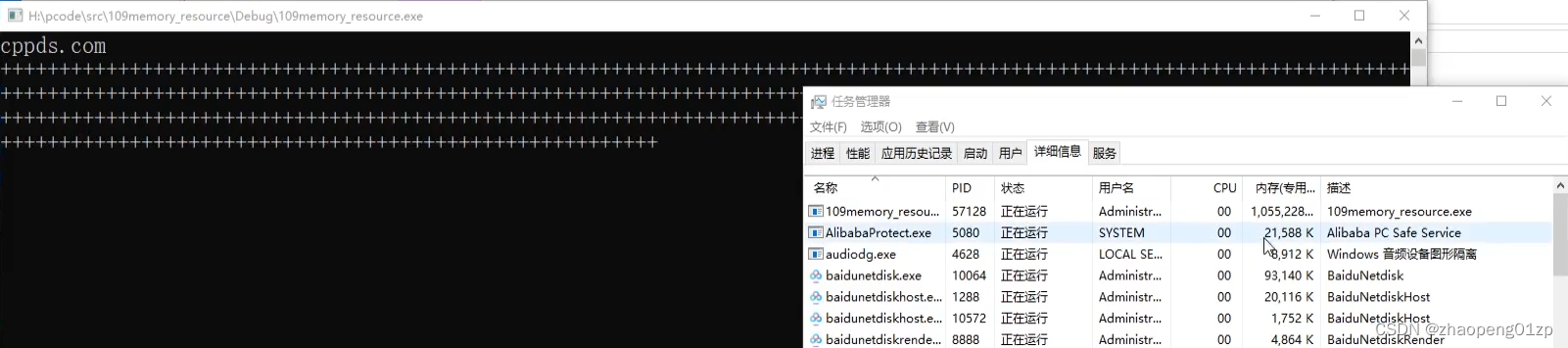
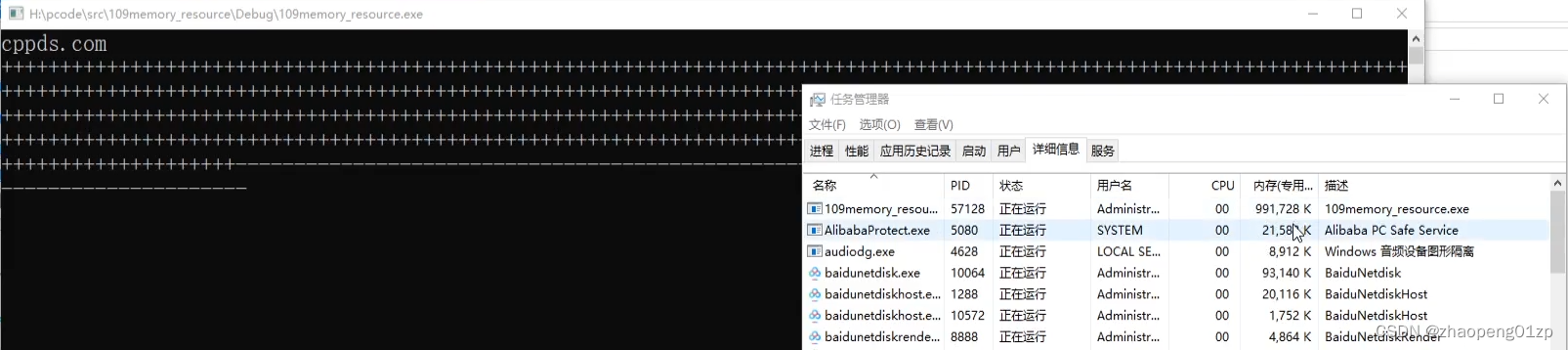
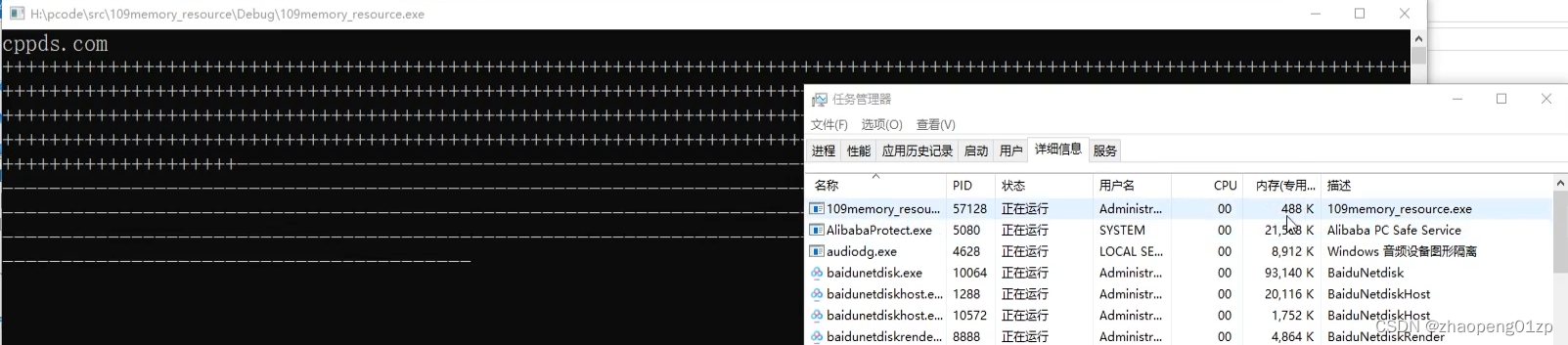
我们观察内存诊断工具中的进程内存快照,可以看到内存的曲线图是成倍加大的,内存是以指数级往上翻倍的,从100M(实际的数值可能是142M),200M(285M),400M(570M)这样子增长,直接翻到了1G(右图的数据每次多一些);
它这样的好处是减少了你的内存分割,如果你是用new和delete,你可能会不断地申请不断地释放,会有大量的内存碎片,并且申请过程的消耗比较大;
它这样的好处是,你每次申请空间的时候,其实这个空间已经申请好了,只是返回一个地址而已,那这个效率肯定会高很多,特别是对于一些数据量比较大的操作。
测试内存溢出的情况:


可以看到可以抛出异常。
我们来看下源码:
我们的do_allocate是线程安全的内存池的:


线程安全的线程池的do_allocate,其实是调用了非线程安全的线程池的do_allocate,只不过在这里面加了一个锁,也就是说进入这个函数它肯定是线程安全的。
我们再进入到非线程安全的线程池的do_allocate当中:

如果说传入_Bytges大于largest_required_pool_block的话,就调用大的空间的分配方法:


可以看到它是拿到基类的对象,然后调用基类的分配内存的方法(_Resource->allocate)。


创建内存之后,把这块内存加入到_Chunks,也就是大块的数据空间当中。
所以这是我们的一个申请空间的流程,其中我们就理解了它的机制:
如果是第一次进来,那肯定是直接在内存池当中找到一块空的空间,然后直接返回;
如果多次进来之后,中途有一些内存被释放了,它其实会到里面去找,找到一个被释放的,并且跟它的大小是符合的,比方说它需要1M,那有一个1.5M的数据,那就可以直接给它,因为你不太可能找到完全一样的。
如果说你设定的max_blocks_per_chunk是100M,那这个时候到了1G的时候,就给它翻倍,翻倍到2G,哪怕你这次只申请了1M的空间,变成1G+1M,它会预先把内存池翻一倍,就变成了2G,如果是个32位程序的话,一下就把资源耗尽了,这样就导致空间的浪费,如果要充分使用内存池,那你还是要预先把这个空间准备好,或者干脆搞两个内存池,你确定下一个池给它1G,这是根据你的业务逻辑来确定怎么做。
3、c++17内存池空间释放代码分析

从同步内存池里面看内存释放的源码:



可以看到,我们资源释放的时候并没有真正的释放,那么在什么时候会去真正的释放呢?

如果空闲的空间小于容器的空间,这个时候它是不释放的;
只有当它的空间减少到足够程度的时候才真正的释放,所以内存池也是减少了我们的一个释放的过程。



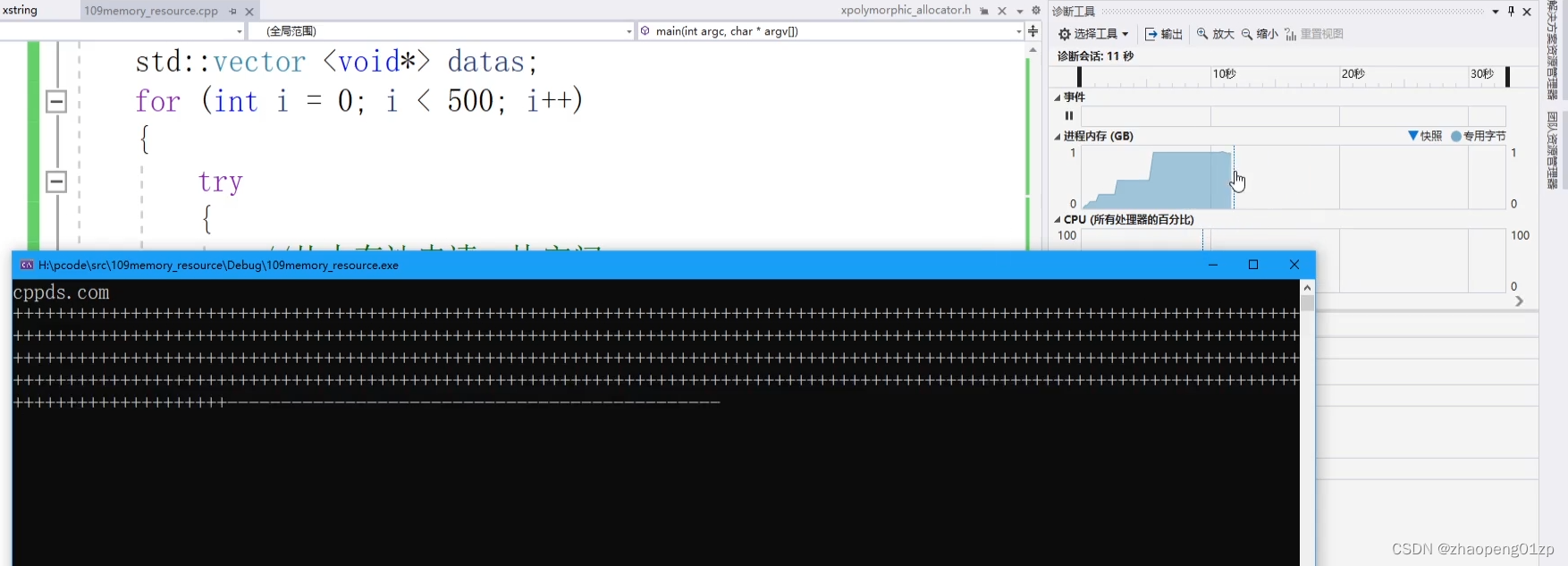
看右图的变化情况,当申请内存到1G完成之后,开始释放内存:

从右图空间释放的图形变化来看,可以看到它是一块一块空间进行释放的(图形下降的坡度会缓一点),直到最后我们把所有的空间都释放完毕;
但是这时候它其实还保留了一部分空间的,在我们的整个数据块当中它并没有完全清理掉,如果我们想完全清理掉的话:

我们在任务管理器中实际看一下内存的使用情况: