Do Transformers Really Perform Bad for Graph Representation?
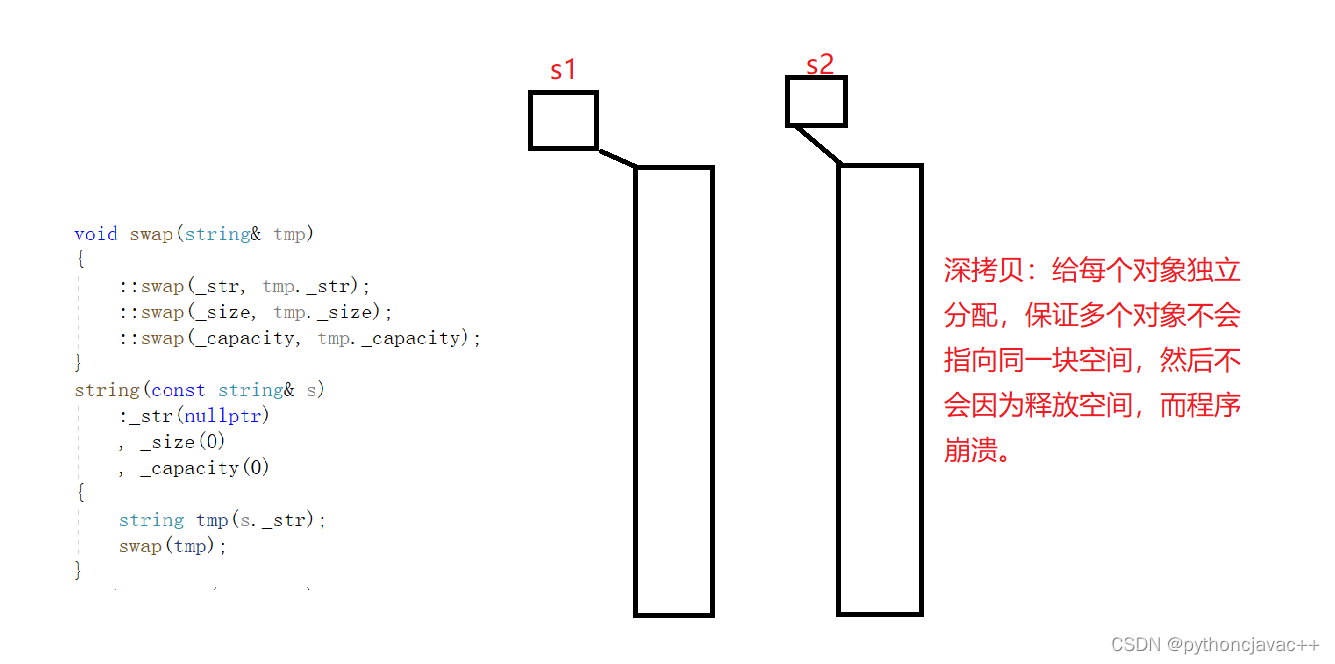
论文中提出了Graphormer,它建立在标准的Transformer架构之上,并且在广泛地图表示学习任务重获得了优异的成绩。同时,作者也提出了一些简单但是有效的结构编码方法来帮助Graphormer更好的模拟图结构数据。
Graphormer的结构编码方法如下:
1,Centrality Encoding:捕获在图中的节点的重要性。在图中,不同节点有不同的重要性,但这种重要性信息不会反应在自我关注模块中,因为在自我注意力模块中主要使用节点语义特征来计算相似度。为了解决这个问题,提出了Centrality Encoding来编码节点的中心性。
2,Spatial Encoding:捕获节点之间的结构关系。对于每个节点对,沿着最短路径计算边缘特征和可学习嵌入的点积平均值,然后将其利用于注意力模块。
相关工作
1,在GNN中,在第l层的节点Vi的表达能够用如下表示:

之后,一个READOUT函数被设计用于将最终迭代的节点特征聚合到整个图G的表示中:

2,Transformer结构是由两个Transformer层组成的,其中,每个Transformer层有两部分:a self-attention module 和 FFN.

Graphormer的详细介绍
1,节点中心性在衡量图中节点的重要性是非常重要的,然而这样的信息在当前的注意力计算中常常被忽视,在Graphormer中,使用了中心性编码,根据节点的入度和出度,为每个节点分配两个实值嵌入向量,对图中的每个节点使用这种中心性编码,将其加上节点特征作为输入。
 2,对于任何一个图G,我们考虑一个函数:
2,对于任何一个图G,我们考虑一个函数:
来衡量在图G中节点Vi和Vj的空间关系,在本论文中,作者使用两点之间的最短路径(SPD)来定义该函数,如果两点之间没有连接,那么该函数值为特定的值-1.
有:

3,在Graphormer中,作者也提出了一种新的边编码方式:对于每个有序节点对,计算边特征和一个可学习embedding的点积的平均。 作者所提出的边编码通过偏置项将边特征合并到关注模块。

4,最终描述Graphormer层如下:

(在多头注意力和FFN之前应用 layer normalizaiton(LN))