一、前言
这一节主要介绍如何自定义扩展各阶段规则
虽然spark内部提供了很多优化规则,但在实际工作中,经常因为业务需求需要自定义扩展优化器或解析器,故自己实现一个优化器才对sparksql有更深的理解
二、扩展范围
spark在扩展方便做的很好,几乎所有阶段都开放了扩展点,用户可以自定义Parser/ResolutionRule/CheckRule/OptimizerRulesPlannerStrategy,如下图:

Spark用户可以在SQL处理的各个阶段扩展自定义实现,如下
injectOptimizerRule – 添加optimizer自定义规则,optimizer负责逻辑执行计划的优化,我们例子中就是扩展了逻辑优化规则。
injectParser – 添加parser自定义规则,parser负责SQL解析。
injectPlannerStrategy – 添加planner strategy自定义规则,planner负责物理执行计划的生成。
injectResolutionRule – 添加Analyzer自定义规则到Resolution阶段,analyzer负责逻辑执行计划生成。
injectPostHocResolutionRule – 添加Analyzer自定义规则到Post Resolution阶段。
injectCheckRule – 添加Analyzer自定义Check规则。
三、示例
代码:
case class MyResolutionRule(spark: SparkSession) extends Rule[LogicalPlan] with Logging {
override def apply(plan: LogicalPlan): LogicalPlan = {
logInfo("开始应用 MyResolutionRule 优化规则")
plan
}
}
case class MyPostHocResolutionRule(spark: SparkSession) extends Rule[LogicalPlan] with Logging {
override def apply(plan: LogicalPlan): LogicalPlan = {
logInfo("开始应用 MyPostHocResolutionRule 优化规则")
plan
}
}
case class MyOptimizerRule(spark: SparkSession) extends Rule[LogicalPlan] with Logging {
override def apply(plan: LogicalPlan): LogicalPlan = {
logInfo("开始应用 MyOptimizerRule 优化规则")
plan
}
}
case class MyCheckRule(spark: SparkSession) extends (LogicalPlan => Unit) with Logging {
override def apply(plan: LogicalPlan): Unit = {
logInfo("开始应用 MyCheckRule 优化规则")
}
}
case class MySparkStrategy(spark: SparkSession) extends SparkStrategy with Logging {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = {
logInfo("开始应用 MySparkStrategy 优化规则")
Seq.empty
}
}
// 自定义injectParser
case class MyParser(spark: SparkSession, delegate: ParserInterface) extends ParserInterface with Logging {
override def parsePlan(sqlText: String): LogicalPlan =
delegate.parsePlan(sqlText)
override def parseExpression(sqlText: String): Expression =
delegate.parseExpression(sqlText)
override def parseTableIdentifier(sqlText: String): TableIdentifier =
delegate.parseTableIdentifier(sqlText)
override def parseFunctionIdentifier(sqlText: String): FunctionIdentifier =
delegate.parseFunctionIdentifier(sqlText)
override def parseTableSchema(sqlText: String): StructType =
delegate.parseTableSchema(sqlText)
override def parseDataType(sqlText: String): DataType =
delegate.parseDataType(sqlText)
override def parseMultipartIdentifier(sqlText: String): Seq[String] = ???
override def parseRawDataType(sqlText: String): DataType = ???
}
object Test {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf)
.withExtensions(e => e.injectResolutionRule(MyResolutionRule))
.withExtensions(e => e.injectPostHocResolutionRule(MyPostHocResolutionRule))
.withExtensions(e => e.injectCheckRule(MyCheckRule))
.withExtensions(e => e.injectOptimizerRule(MyOptimizerRule))
.withExtensions(e => e.injectPlannerStrategy(MySparkStrategy))
.withExtensions(e => e.injectParser(MyParser))
.getOrCreate()
import spark.implicits._
Seq(Person("Jack", 12), Person("James", 21), Person("Mac", 30)).toDS().createTempView("person")
spark.sql("SELECT age FROM PERSON WHERE AGE > 18").explain(true)
}
}
结果打印:
22/11/01 14:43:52 INFO MyResolutionRule: 开始应用 MyResolutionRule 优化规则
22/11/01 14:43:52 INFO MyPostHocResolutionRule: 开始应用 MyPostHocResolutionRule 优化规则
22/11/01 14:43:52 INFO MyCheckRule: 开始应用 MyCheckRule 优化规则
22/11/01 14:43:52 INFO MyResolutionRule: 开始应用 MyResolutionRule 优化规则
22/11/01 14:43:52 INFO MyResolutionRule: 开始应用 MyResolutionRule 优化规则
22/11/01 14:43:52 INFO MyPostHocResolutionRule: 开始应用 MyPostHocResolutionRule 优化规则
22/11/01 14:43:52 INFO MyCheckRule: 开始应用 MyCheckRule 优化规则
22/11/01 14:43:53 INFO MyResolutionRule: 开始应用 MyResolutionRule 优化规则
22/11/01 14:43:53 INFO MyPostHocResolutionRule: 开始应用 MyPostHocResolutionRule 优化规则
22/11/01 14:43:53 INFO MyCheckRule: 开始应用 MyCheckRule 优化规则
22/11/01 14:43:54 INFO MyOptimizerRule: 开始应用 MyOptimizerRule 优化规则
22/11/01 14:43:54 INFO MyOptimizerRule: 开始应用 MyOptimizerRule 优化规则
22/11/01 14:43:54 INFO MySparkStrategy: 开始应用 MySparkStrategy 优化规则
22/11/01 14:43:54 INFO MySparkStrategy: 开始应用 MySparkStrategy 优化规则
22/11/01 14:43:54 INFO MyResolutionRule: 开始应用 MyResolutionRule 优化规则
22/11/01 14:43:54 INFO MyPostHocResolutionRule: 开始应用 MyPostHocResolutionRule 优化规则
22/11/01 14:43:54 INFO MyCheckRule: 开始应用 MyCheckRule 优化规则
22/11/01 14:43:55 INFO MyResolutionRule: 开始应用 MyResolutionRule 优化规则
22/11/01 14:43:55 INFO MyResolutionRule: 开始应用 MyResolutionRule 优化规则
22/11/01 14:43:55 INFO MyPostHocResolutionRule: 开始应用 MyPostHocResolutionRule 优化规则
22/11/01 14:43:55 INFO MyCheckRule: 开始应用 MyCheckRule 优化规则
22/11/01 14:43:55 INFO CodeGenerator: Code generated in 18.564505 ms
22/11/01 14:43:55 INFO MyOptimizerRule: 开始应用 MyOptimizerRule 优化规则
22/11/01 14:43:55 INFO MyOptimizerRule: 开始应用 MyOptimizerRule 优化规则
22/11/01 14:43:55 INFO MySparkStrategy: 开始应用 MySparkStrategy 优化规则
22/11/01 14:43:55 INFO MySparkStrategy: 开始应用 MySparkStrategy 优化规则
== Parsed Logical Plan ==
'Project ['age]
+- 'Filter ('AGE > 18)
+- 'UnresolvedRelation [PERSON]
== Analyzed Logical Plan ==
age: int
Project [age#3]
+- Filter (AGE#3 > 18)
+- SubqueryAlias person
+- LocalRelation [name#2, age#3]
== Optimized Logical Plan ==
LocalRelation [age#3]
== Physical Plan ==
LocalTableScan [age#3]
可以看到自定义扩展生效
四、源码
实例中通过sparkSession.withExtensions函数传递自定义扩展类,点进去看发现是将SparkSessionExtensions类传递给入参【即我们调用的各种inject函数】:

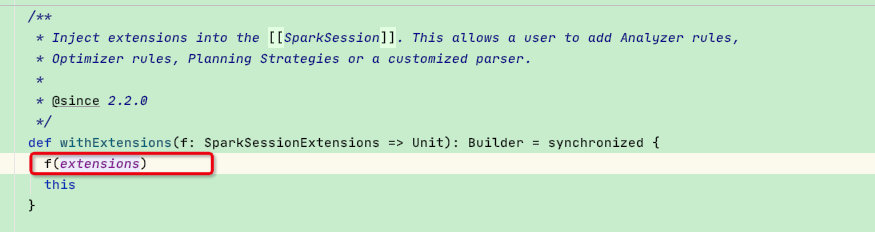
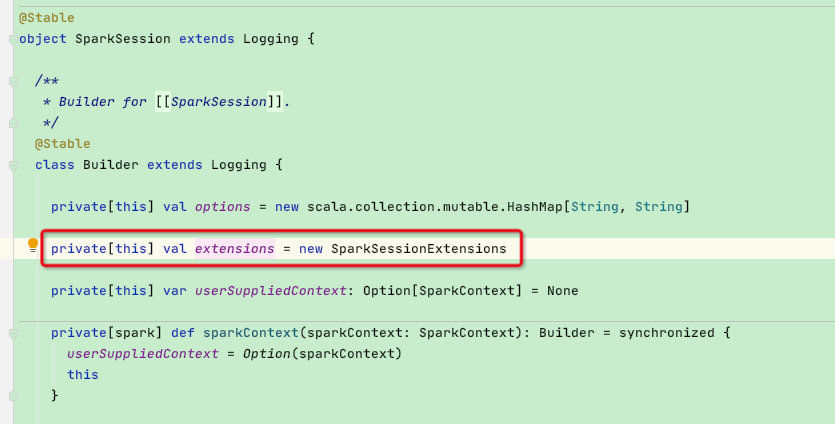
此时我们看一下SparkSessionExtensions类内部的 inject 函数,类较长这里直接贴一下代码:可以发现其内部是将外部自定义类通过 += 的方式赋予内部集合变量*
type RuleBuilder = SparkSession => Rule[LogicalPlan]
type CheckRuleBuilder = SparkSession => LogicalPlan => Unit
type StrategyBuilder = SparkSession => Strategy
type ParserBuilder = (SparkSession, ParserInterface) => ParserInterface
type FunctionDescription = (FunctionIdentifier, ExpressionInfo, FunctionBuilder)
type ColumnarRuleBuilder = SparkSession => ColumnarRule
......
private[this] val resolutionRuleBuilders = mutable.Buffer.empty[RuleBuilder]
private[this] val postHocResolutionRuleBuilders = mutable.Buffer.empty[RuleBuilder]
private[this] val checkRuleBuilders = mutable.Buffer.empty[CheckRuleBuilder]
private[this] val optimizerRules = mutable.Buffer.empty[RuleBuilder]
......
def injectResolutionRule(builder: RuleBuilder): Unit = {
resolutionRuleBuilders += builder
}
def injectPostHocResolutionRule(builder: RuleBuilder): Unit = {
postHocResolutionRuleBuilders += builder
}
def injectCheckRule(builder: CheckRuleBuilder): Unit = {
checkRuleBuilders += builder
}
def injectOptimizerRule(builder: RuleBuilder): Unit = {
optimizerRules += builder
}
......
那么赋值之后的SparkSessionExtensions如何应用在各个阶段呢?
这里暂停一下,需要先了解SessionState,这对于我们后面如何应用自定义构建规则会有帮助
SessionState
在之前几节中,我们了解到QueryExecution是一条sql执行的关键类【负责sql的解析,优化,物化等】,而这些阶段都需要使用sparkSession.sessionState.xxx[属性],如下图
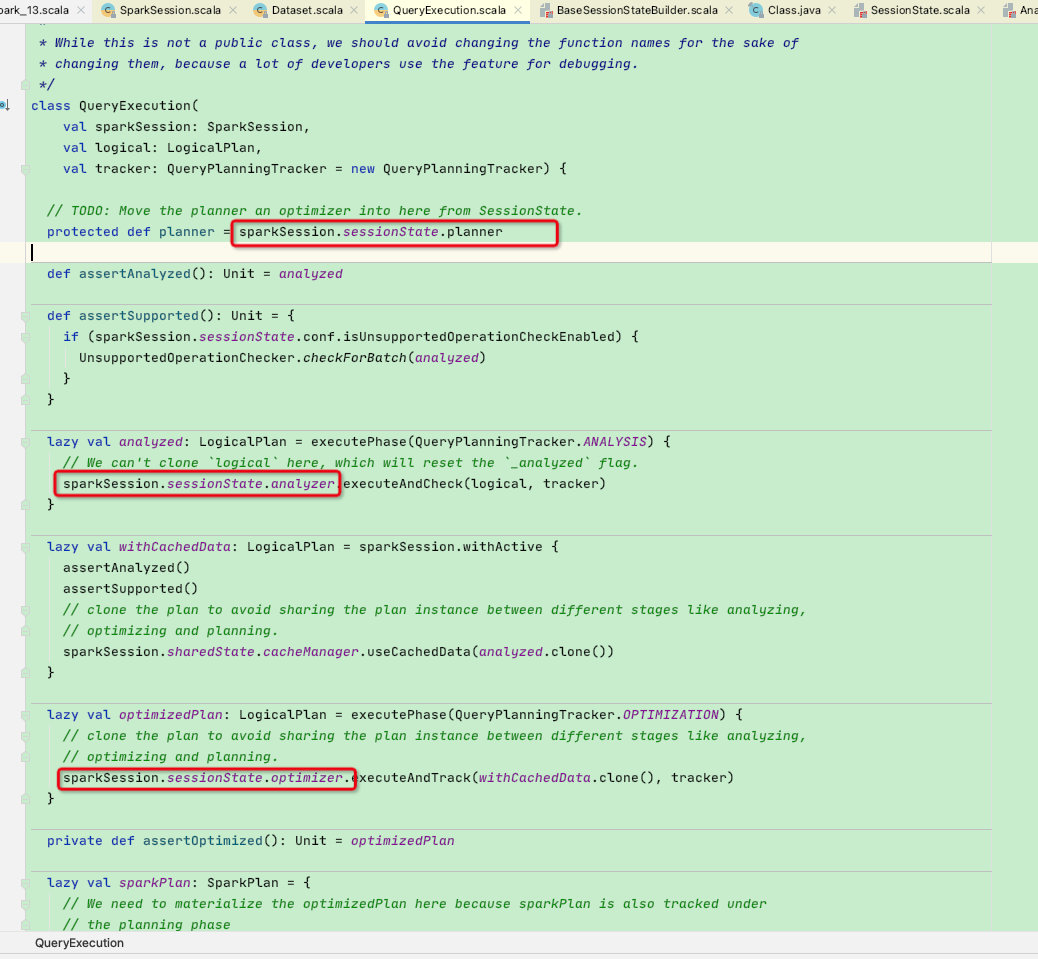
SessionState的属性是通过创建SessionState的时的传参,故需要看构建SessionState过程。

而sessionState是保存在SparkSession中,所以需要先来看SparkSession的构建过程,常见创建sparkSession是通过getOrCreate函数

SparkSession
这里回顾一下sparkSession的创建过程
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf)
.getOrCreate()
省略其他代码段后看到 new SparkSession(sparkContext, None, None, extensions) 创建SparkSession,可以看到最后一个参数是:extensions
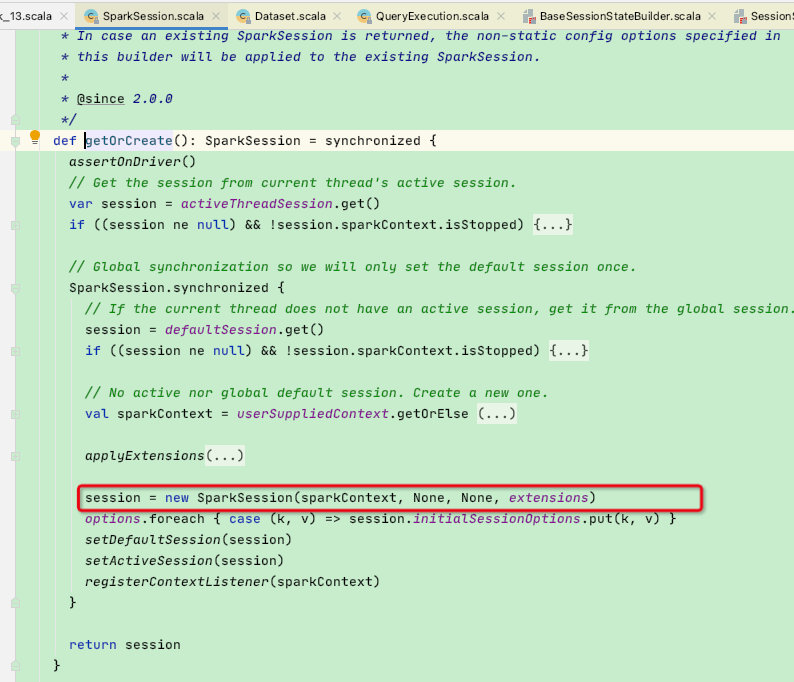
extensions正是我们前面看到的SparkSessionExtensions类,此时sparkSession中包含了我们扩展好的SparkSessionExtensions类了;
不过只是包含而已,还没和各个阶段整合到一起;接下来看SparkSession中的sessionState属性:期间调用了instantiateSessionState 函数
这里贴一下源码:可以看出构建的SessionState有两种子类,一种hive【HiveSessionStateBuilder】,一种普通memory【SessionStateBuilder】但最终返回的结果是统一的父类:BaseSessionStateBuilder
lazy val sessionState: SessionState = {
parentSessionState
.map(_.clone(this))
.getOrElse {
val state = SparkSession.instantiateSessionState( // 调用instantiateSessionState函数构建SessionState
SparkSession.sessionStateClassName(sparkContext.conf), // 调用sessionStateClassName函数确定构建hive还是普通SessionState
self)
initialSessionOptions.foreach { case (k, v) => state.conf.setConfString(k, v) }
state
}
}
// 如果构建SparkSession时调用了enableHiveSupport来连接hive,则此时会构建HiveSessionStateBuilder
private val HIVE_SESSION_STATE_BUILDER_CLASS_NAME =
"org.apache.spark.sql.hive.HiveSessionStateBuilder"
private def sessionStateClassName(conf: SparkConf): String = {
conf.get(CATALOG_IMPLEMENTATION) match {
case "hive" => HIVE_SESSION_STATE_BUILDER_CLASS_NAME
case "in-memory" => classOf[SessionStateBuilder].getCanonicalName
}
}
// 注意:这里将hive | in-memory的 className构建成了统一的父类BaseSessionStateBuilder,并且调用了.build()函数
private def instantiateSessionState(
className: String,
sparkSession: SparkSession): SessionState = {
try {
// invoke `new [Hive]SessionStateBuilder(SparkSession, Option[SessionState])`
val clazz = Utils.classForName(className)
val ctor = clazz.getConstructors.head
ctor.newInstance(sparkSession, None).asInstanceOf[BaseSessionStateBuilder].build() // 这里将sparkSession传参进去
} catch {
case NonFatal(e) =>
throw new IllegalArgumentException(s"Error while instantiating '$className':", e)
}
}
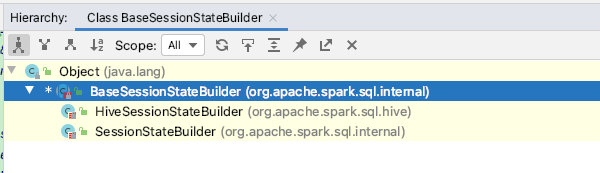
此时看一下BaseSessionStateBuilder.build函数:由于BaseSessionStateBuilder类代码较多,这里以优化器阶段为主介绍,其他阶段类似
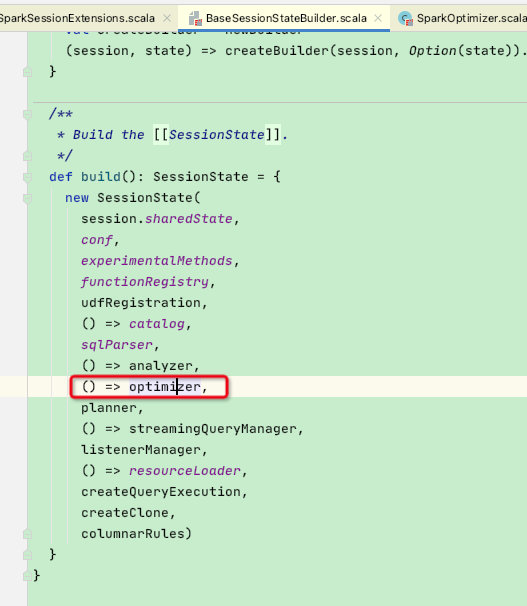
这里new SparkOptimizer对象,正是QueryExecution中用到的optimizer,并重写了optimizer的extendedOperatorOptimizationRules属性,将父类原有属性集合中加入了扩展:customOperatorOptimizationRules函数返回规则集合

customOperatorOptimizationRules函数调用了SparkSessionExtensions的buildOptimizerRules,如下:将SparkSessionExtensions内部扩展的optimizerRules集合元素进行创建后返回
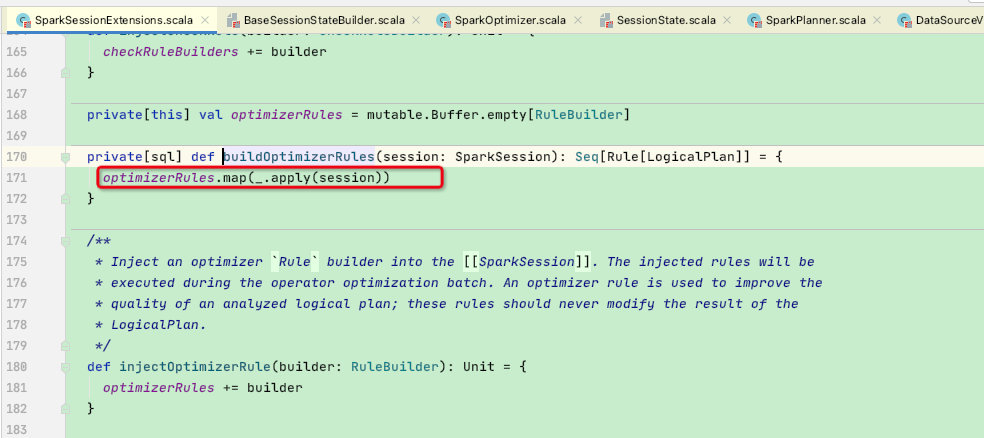
到这里就可以和上面暂停的地方结合起来看了,最开始我们将自定义的扩展类存储到了各个集合当中,如下:
type RuleBuilder = SparkSession => Rule[LogicalPlan]
type CheckRuleBuilder = SparkSession => LogicalPlan => Unit
type StrategyBuilder = SparkSession => Strategy
type ParserBuilder = (SparkSession, ParserInterface) => ParserInterface
type FunctionDescription = (FunctionIdentifier, ExpressionInfo, FunctionBuilder)
type ColumnarRuleBuilder = SparkSession => ColumnarRule
......
private[this] val resolutionRuleBuilders = mutable.Buffer.empty[RuleBuilder]
private[this] val postHocResolutionRuleBuilders = mutable.Buffer.empty[RuleBuilder]
private[this] val checkRuleBuilders = mutable.Buffer.empty[CheckRuleBuilder]
private[this] val optimizerRules = mutable.Buffer.empty[RuleBuilder]
......
def injectResolutionRule(builder: RuleBuilder): Unit = {
resolutionRuleBuilders += builder
}
def injectPostHocResolutionRule(builder: RuleBuilder): Unit = {
postHocResolutionRuleBuilders += builder
}
def injectCheckRule(builder: CheckRuleBuilder): Unit = {
checkRuleBuilders += builder
}
def injectOptimizerRule(builder: RuleBuilder): Unit = {
optimizerRules += builder
}
......
随后在buildOptimizerRules函数中将集合中用户扩展的元素创建出来并返回,至此SparkOptimizer类中的extendedOperatorOptimizationRules属性包含了我们自定义扩展的规则
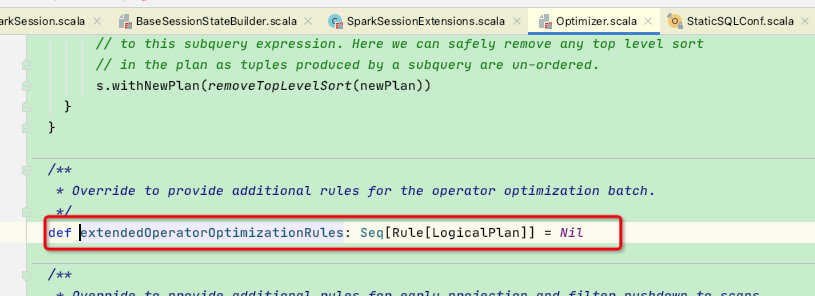
接下来看一下Optimizer是如何使用extendedOperatorOptimizationRules这个属性?
首先在Optimizer类中的defaultBatches属性中,会将我们扩展的类加入进去,至此Optimizer阶段的新增扩展类放入成功
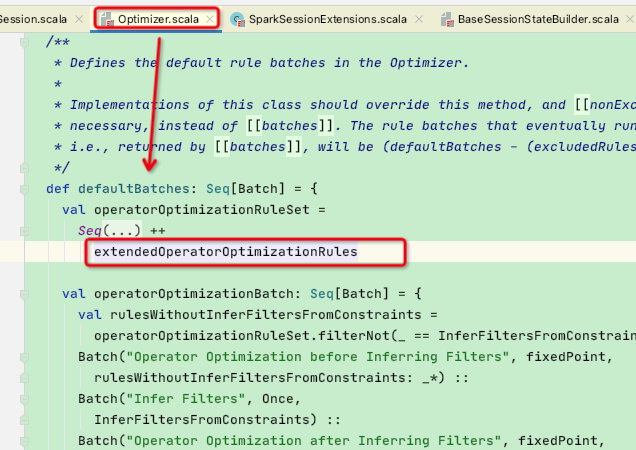
这里我们回到上一节的优化阶段,优化过程是通过batches集合迭代进行优化,而batches集合在Optimizer被重写
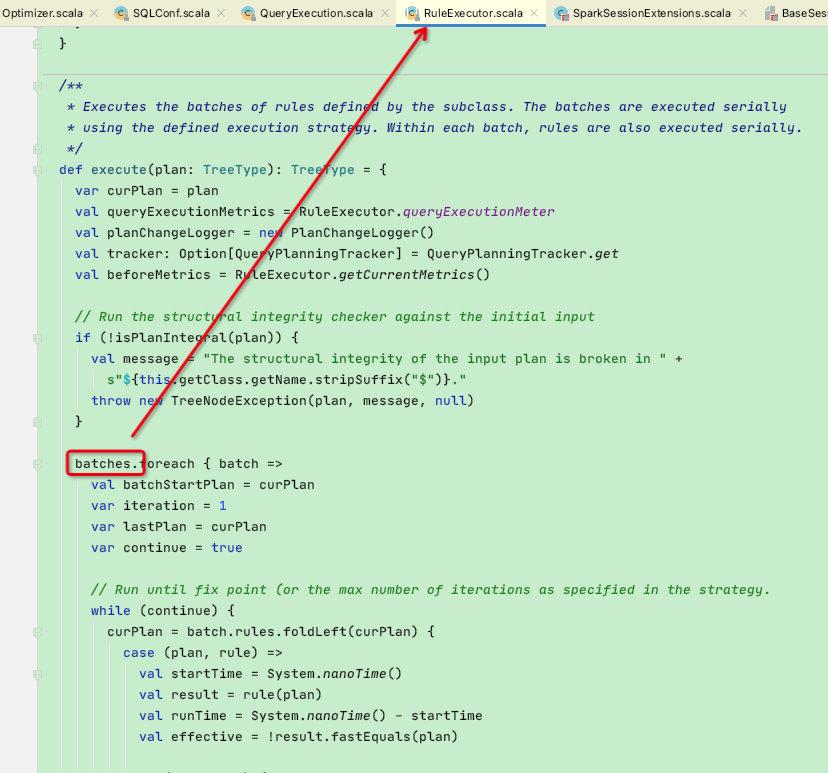
可以看到被重写的batches使用了defaultBatches属性
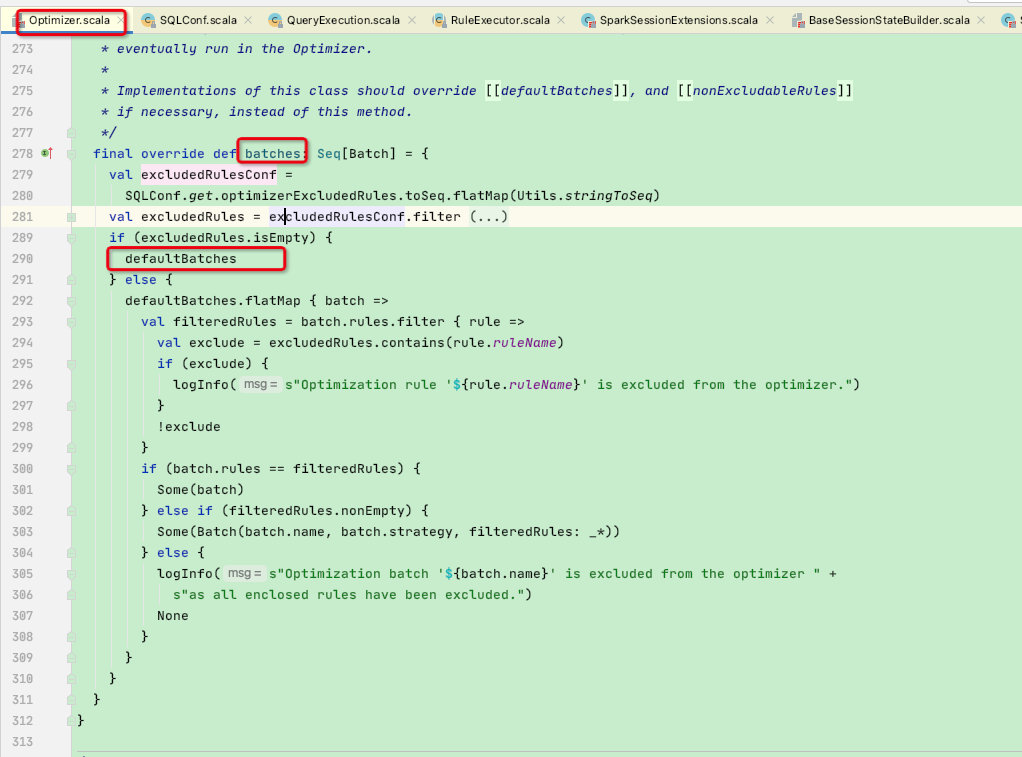
而defaultBatches中的extendedOperatorOptimizationRules集合正包含了用户自定义扩展的规则
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iMHQFuiO-1669103114622)(/Users/hzxt/Library/Application Support/typora-user-images/image-20221101170442557.png)]
至此优化器自定义扩展全流程结束;关于其他阶段的扩展大致思想相同,感兴趣的小伙看可以看一下源码,方便理解