一、502意味着什么
502 Bad Gateway是指错误网关,无效网关;在互联网中表示一种网络错误。表现在WEB浏览器中给出的页面反馈。它通常并不意味着上游服务器已关闭(无响应网关/代理) ,而是上游服务器和网关/代理使用不一致的协议交换数据。鉴于互联网协议是相当清楚的,它往往意味着一个或两个机器已不正确或不完全编程。
根据百科词条说明,502错误是浏览器上游服务器问题,那么上游服务器就有Nginx和Server两种。挨个进行排查。
首先Server如果导致502,也就是服务不响应的情况可能有两种原因 ,一是 服务宕机或者假死 二是tomcat的链接数被占满,新到的socket链接被tomcat直接拒绝导致的。
其次是nginx,经过查询资料,nginx具有限流和健康检查机制,会将nginx认为不可用的服务进行下线,进而直接返回502.
二、错误排查
1 、首先是服务器(因为最熟悉)
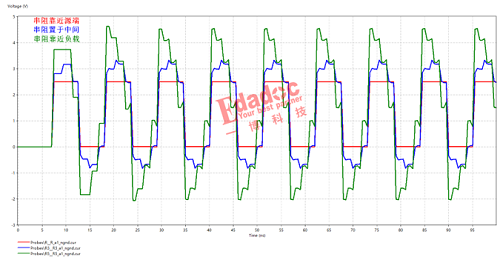
 图1
图1
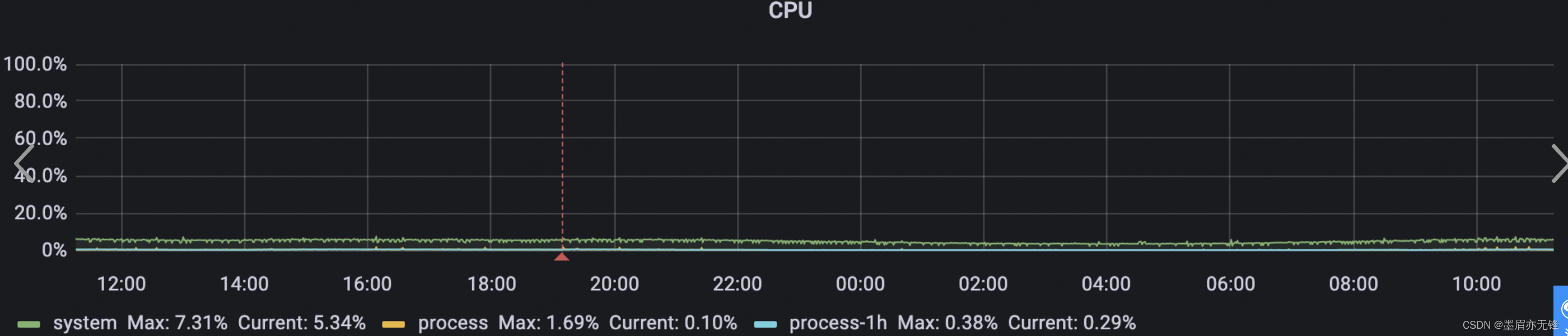 图2
图2
监控结果如图1所示,tomcat的线程数量在502错误报出的是时候,线程数量没有被占满。所以不会存在Tomcat的acceptCount被占满,进而Tomcat直接拒绝链接的情况。
监控结果如图2所示,server的cpu也是种比较低一些,查看服务日志也是没有出现服务宕机和假死的情况。
2、nginx排查

通过查看nginx的access日志发现 502报错,执行时间是0.00秒,也就是nginx并没有向server发起请求,二是直接返回前端了,印证了Server和Tomcat并没有问题的思路。
排查nginx的error日志发现 502的时候nginx都是先出现timeout 几次,然后就是no live upstreams while connecting to upstream。
至此,基本确定是nginx的健康检查机制造成的502问题。
三、原因分析
1、nginx原因分析:
nginx的检查机制相关的配置参数说明
问题:两台服务并没有宕机,为什么会no live upstreams
答:nginx默认配置有健康检查机制。nginx做反向代理,如果后端节点服务器宕掉的话,还会有请求转发到后端的这台realserver上面,这样势必造成网站访问故障。并且因为upstream 里面设置了ip_hash。所以导致访问网站时怎么刷新都是有问题的,所以nginx为了避免上述情况,对nginx后方realserver的健康状态进行检查,如果发现后端服务器不可用,则请求不转发到这台服务器。当两台服务都被标记为不可用的时候,请求就不转发到server,而由nginx直接返回502.
问题:服务不可用是如何判定的?
答:nginx有两个参数设置用来判定服务不可用以及不可用时间:fail_timeout 和 max_fails
默认值fail_timeout为10s,max_fails为1次。该参数的意思是:转发给后端服务时,若10s发现后端服务故障1次,则将请求转发给其他节点进行处理,并将服务器标记为故障、在10s时间内不再转发给故障服务器。10s后重试转发给故障服务器,若仍旧不成功则重复刚才的操作;
这也刚好印证了mdata用户出现502的时候,很快又不会再报错502 ,正是因为这个10秒的恢复时间。
问题:服务器标记故障的依据是什么
答: nginx的失败判定其由proxy_next_upstream定义,不过,不管proxy_next_upstream如何配置,error,timeout,invalid_header都将被认为是失败。
根据nginx的日志,mdata本次502问题正是因为链接超时导致的。
问题: 超时引起的,那么这个超时是什么超时
答:根据nginx的官网说明,共有三个类型的超时:tcp链接建立超时,读超时,写超时,超时时间配置项分别是:
proxy_connect_timeout ; #nginx服务器与被代理的服务器建立连接的超时时间,默认60秒
proxy_read_timeout ; #nginx服务器想被代理服务器组发出read请求后,等待响应的超时间,默认为60秒。
proxy_send_timeout ; #nginx服务器想被代理服务器组发出write请求后,等待响应的超时间,默认为60秒。
问题:本次502的超时是哪一个呢
答:经过排查,本次502属于读超时,根据nginx的日志可以看到no live upstreams 错误的前几个请求大部分是/getdistinct接口。该接口的作用是从用户配置的视图中查询中维度信息,具体逻辑是select distinct from (用户视图),根据追踪,fsgbi-vip这个库压力比较大,用户的sql属于关联查询,所以很难在60s内返回全表扫描才能获取的数据。所以该接口超时概率较大,尤其是在fsgbi-vip进行数据加工,回溯的时候。具体排除服务的原因,会在tomcat原理分析和Server分析进行说明。
2、Tomcat原理分析
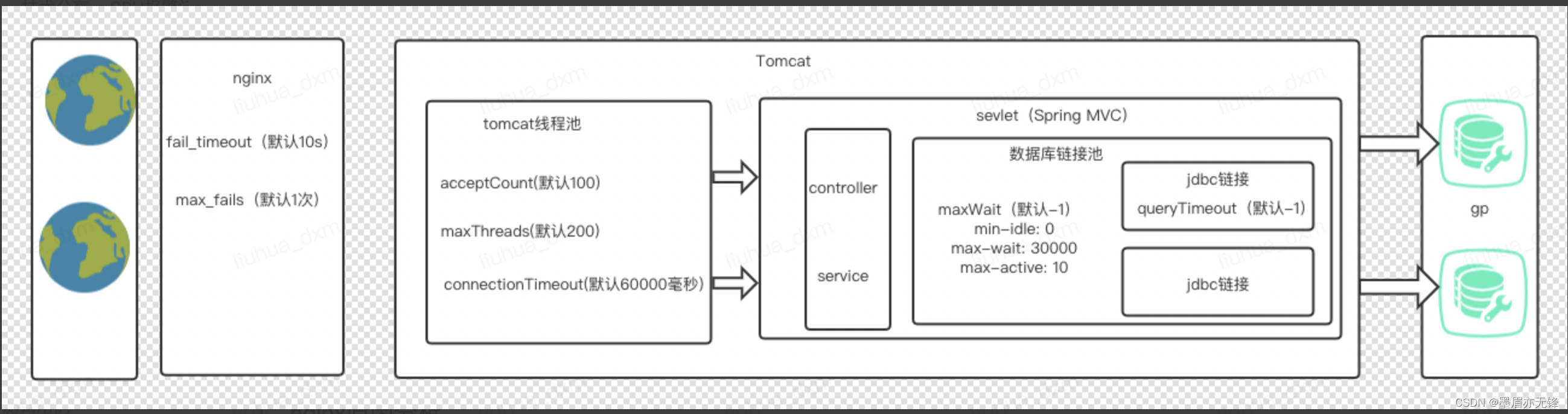
问题:Tomcat会导致502和超时吗。
答:是可能的。Tomcat作为sevlet的容器,内部有一个工作线程池和一个TCP链接的队列
有三个参数与该场景有关,进行简要说明:
acceptCount值调整(默认100):accept队列的容量。该队里用来保存那些完成三次握手建立连接,等待工作线程处理响应,没得到service的tcp连接。
maxThreads值调整(默认200):worker线程池的大小,代表最大的并发请求数
当acceptCount的值设置的太小的时候,当请求量大的时候,accept已经满了,无法接受TCP连接。操作系统无法给tomcat建立更多的连接(无法完成三次握手),系统进行自我保护,当超出负载能力的时候,迅速fail fast,返回503。
当maxThreads太小,或者服务压力比较大时,accept队列中的链接如果一直没得到service,则client得不到响应,出现read timeout,最糟糕的情况是连接在accept队列等待了很久,等到能得到worker线程服务的时候,已经超时了,这样其实浪费了很多连接。
问题:本次现象和Tomcat有关吗
答:经过上述说明,结合Tomcat监控可以看到current_threads 稳定在75左右,远没有达到maxThreads,所以accept队列是空的,Tomcat也就不会直接拒绝三次握手,也就不会出现502情况
3、server原理分析
问题:mdata服务哪个地方可能会导致超时进而导致502
答:mdata服务内部是通过druid连接池获取链接查询数据库的,所以druid连接池的一些逻辑会导致查询超时
1 连接池中为避免占用gp宝贵的链接,mdata的配置牺牲了高效性,将链接空闲时间设置的较低,导致很多查询会走建立连接的过程。且重试机制会导致超时。
2 看板配置的单图和筛选器较多,并发请求量很大,导致有些查询连接池总的链接长时间获取不到,进而导致超时。
3 查询时间长,gp数据量很大,借据明细,授信明细表类的单图,可能会全表扫描,gp压力大的时候,查询较慢,可能超时。
问题:超时问题如何解决
答:
1链接重拾机制计算,将重试次数和时间控制在nginx的超时时间内。
2 连接池的等待时间修改,小于nginx的readtime时间
3 jdbc的connection的查询时间理论上也需要设置查询时长来控制链接占用时间,但考虑到有缓存机制,所以暂时没有更改,执行时间是无限时长。
四、问题解决方案
针对以上排查出来的问题进行处理解决:
短期方案:
1、nginx的proxy_read_timeout修改为300s,该值目前基本覆盖了mdata的90以上的sql查询时间。
2、nginx的健康检查机制修改:fail_timeout为10s,max_fails为5次,5是取值大部分看板的筛选器的数量。避免多个筛选器并发导致检查失败。
3、tomcat的链接由200 改为800
长期方案:
1、短链接和长链接进行拆分。