文章目录
- 邮件发送
- 一、群发邮件
- 二、@指定用户发邮件
- 正则表达式
- 一、预备知识正则
- 1. 正则介绍
- 2. 陷阱
- 3. 特殊的字符
- 二、 re 模块的方法
- 1 常用方法
- 2. 正则分组
- 总结

邮件发送




#第三方模块 yagmail
#pip3 install yagmail
import yagmail
"""
项目需求
yag =yagmail.SMTP(
user='自己的邮箱账号',
password='账号的授权码(不是登录密码)',
host='smtp.qq.com', #邮局的smtp 地址
port='端口号', #邮局的stmp端口25不加密
smtp_ssl=False)
yag.send(to='收件箱账号',
subject='邮件主题',
contents='邮件内容')
"""
email_user = 'm18277724978@163.com'
email_pwd = 'yourpassword'
email_host = 'smtp.163.com'
with open('/root/.emailpwd') as f:
pwd = f.read()[:-1]
email_pwd = pwd
email_content = """
如果有一天 我们都发觉
原来什么都可以 我们是否还会 停留在这里
当你的眼睛 眯着笑 当你喝可乐 当你吵
我想对你好 你从来不知道 想你 想你 也能成为嗜好
当你说今天的烦恼 当你说夜深 你睡不着
我想对你说 却害怕都说错 好喜欢你 知不知道
也许空虚 让我想得太多 也许该回到被窝
梦里会相遇 就毫不犹豫 大声的说 我要说
当你的眼睛 眯着笑 当你喝可乐 当你吵
我想对你好 你从来不知道 想你 想你 也能成为嗜好
啦~~~~啦~~~~
我想对你说 却害怕都说错 好喜欢你 知不知道
"""
yag =yagmail.SMTP(
user=email_user,
password=email_pwd,
host=email_host, #邮局的smtp 地址
port=25, #邮局的stmp端口25不加密
smtp_ssl=False)
yag.send(to='2054210430@qq.com',
subject='等我雨婷',
contents=email_content)
一、群发邮件
#第三方模块 yagmail
#pip3 install yagmail
import yagmail
"""
项目需求
yag =yagmail.SMTP(
user='自己的邮箱账号',
password='账号的授权码(不是登录密码)',
host='smtp.qq.com', #邮局的smtp 地址
port='端口号', #邮局的stmp端口25不加密
smtp_ssl=False)
yag.send(to='收件箱账号',
subject='邮件主题',
contents='邮件内容')
"""
email_user = 'm18277724978@163.com'
email_pwd = 'yourpassword'
email_host = 'smtp.163.com'
with open('/root/.emailpwd') as f:
pwd = f.read()[:-1]
email_pwd = pwd
email_content = """
如果有一天 我们都发觉
原来什么都可以 我们是否还会 停留在这里
当你的眼睛 眯着笑 当你喝可乐 当你吵
我想对你好 你从来不知道 想你 想你 也能成为嗜好
当你说今天的烦恼 当你说夜深 你睡不着
我想对你说 却害怕都说错 好喜欢你 知不知道
也许空虚 让我想得太多 也许该回到被窝
梦里会相遇 就毫不犹豫 大声的说 我要说
当你的眼睛 眯着笑 当你喝可乐 当你吵
我想对你好 你从来不知道 想你 想你 也能成为嗜好
啦~~~~啦~~~~
我想对你说 却害怕都说错 好喜欢你 知不知道
"""
yag =yagmail.SMTP(
user=email_user,
password=email_pwd,
host=email_host, #邮局的smtp 地址
port=465, #邮局的stmp端口25端口不加密,465加密
smtp_ssl=True) #进行加密
email_users = ['2054210430@qq.com','guan12319@qq.com']
yag.send(to=email_users,
subject='晴天',
contents=email_content,
attachments='/root/python_code/work001/day001/fat.jpeg')
接收邮件


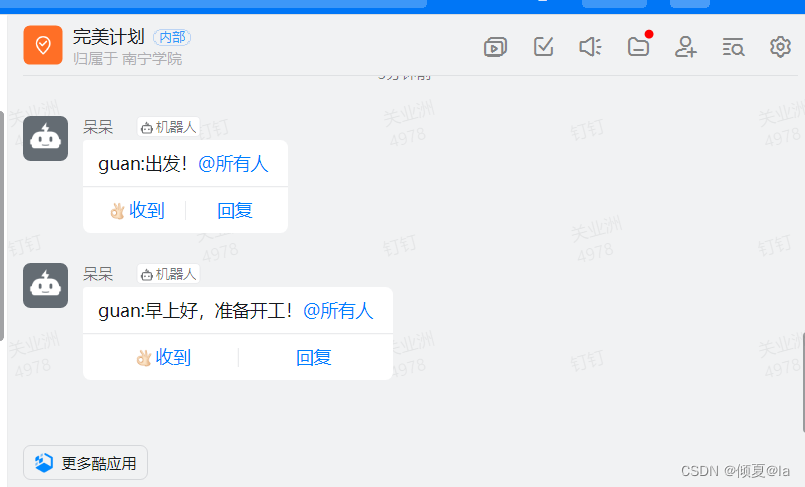
@全体成员
webhook = "https://oapi.dingtalk.com/robot/send?access_token=4e656635905747906a767d4fedac795e027470250c7e2cf9cf00e609af25ae47"
#pip3 install request
import requests
send_contents = "guan:早上好,准备开工!"
content = {
"msgtype": "text",
"text": {
"content": send_contents
},
"at": {
#发送给群里的所有人
"isAtAll": True
}
}
headers = {"Content-Type": "application/json;charset=utf-8"}
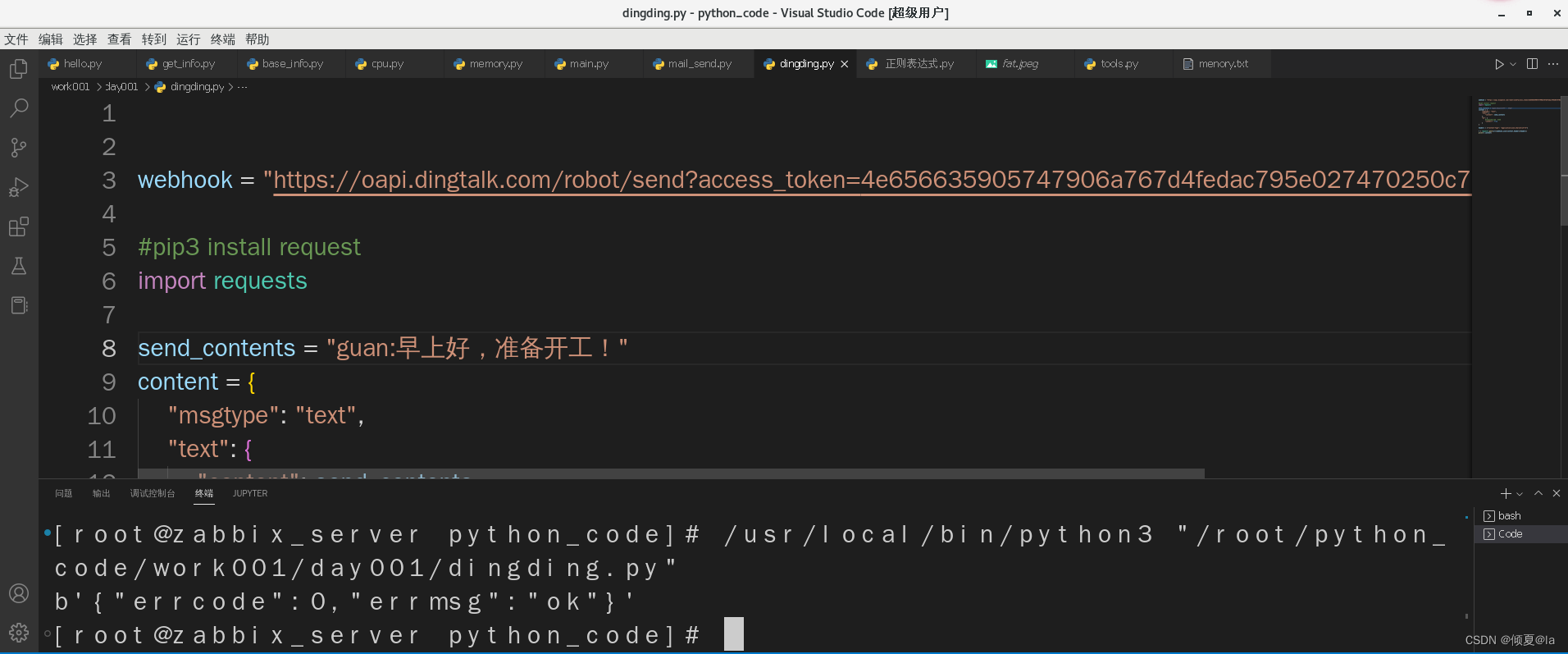
r = requests.post(url=webhook,json=content,headers=headers)
print(r.content)
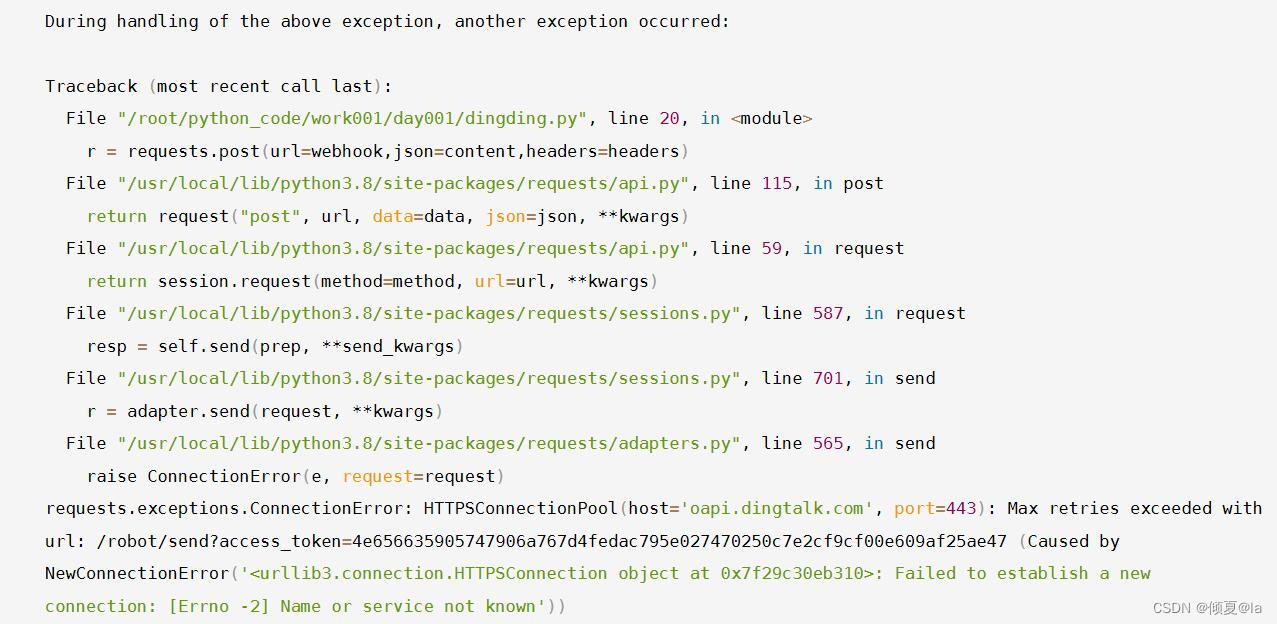
如果出现上面的报错,要检查dns 和 ping一下测网络是否连通
二、@指定用户发邮件
webhook = "https://oapi.dingtalk.com/robot/send?access_token=4e656635905747906a767d4fedac795e027470250c7e2cf9cf00e609af25ae47"
#pip3 install request
import requests
send_contents = "guan:早上好,准备开工!"
content = {
"msgtype": "text",
"text": {
"content": send_contents
},
"at": {
#发送给群里的所有人
#"isAtAll": True
"atMobiles": [
#单独@某个人,使用绑定的手机号
# 多个人,用户用英文逗号隔开
"18277724978",
"17877170938",
"182xxxxxxxxxxx"
]
}
}
headers = {"Content-Type": "application/json;charset=utf-8"}
r = requests.post(url=webhook,json=content,headers=headers)
print(r.content.decode)
正则表达式
一、预备知识正则
1. 正则介绍
Python 中的正则,本质上是嵌入在Python中的一种微小的、高度专业化的编程语言,可通过
re这个内置模块获得。
正则表达式模式几乎和 shell 中的一样,更接近grep -P的效果,因为 Python 中的re模块提供的是类似 Perl 语言中的正则表达式。
正则表达式模式会被编译成一系列字节码,然后由用 C 编写的匹配引擎执行。
2. 陷阱
友情提示:
正则表达式语言相对较小且受限制,因此并非所有可能的字符串处理任务都可以使用正则表达式完成。还有一些任务 可以 用正则表达式完成,但表达式变得非常复杂。 在这些情况下,你最好编写 Python 代码来进行处理;虽然 Python 代码比精心设计的正则表达式慢,但它也可能更容易理解。
3. 特殊的字符
在 Python 中有一些特殊的字符,在正则表达式模式中的作用和 shell 和 grep -P 时候有一些细微的差别
正则特殊字符 匹配内容 \w匹配单个字母、数字、汉字(shell中没有)或下划线 类似于 [a-zA-Z0-9_]\d匹配单个数字 类似于 [0-9]\s匹配单个任意的空白符,这等价于 [ \t\n\r\f\v]\S匹配任何非空白字符, [^ \t\n\r\f\v]
二、 re 模块的方法
其实,前面在 shell 中我们已经学习正则,这里我们主要学习的是 Python 中如何使用正则的,就是
re模块中都有哪些方法。
接下来我们就学习几个常间的方法,更多请移步正则扩展知识完整版
1 常用方法
match() 就看开头有没有
只在整个字符串的起始位置进行匹配
示例字符串
s = "isinstance yangge enumerate www.qfedu.com 1997"
示例演示:
import re
In [4]: r = re.match("is\w+", s)
In [8]: r.group() # 获取匹配成功的结果
Out[8]: 'isinstance'
search() 只查到第一个匹配的
从整个字符串的开头找到最后,当第一个匹配成功后,就不再继续匹配。
In [9]: r = re.search("a\w+", s)
In [10]: r.group()
Out[10]: 'ance'
findall() 查到所有
搜索整个字符串,找到所有匹配成功的字符串,比把这些字符串放在一个列表中返回。
In [16]: r = re.findall("a\w+", s)
In [17]: r
Out[17]: ['ance', 'angge', 'ate']
sub() 替换
把匹配成功的字符串,进行替换。
# 语法:
"""
("a\w+", "100", s, 2)
匹配规则,替换成的新内容, 被搜索的对象, 有相同的话替换的次数
"""
In [24]: r = re.sub("a\w+", "100", s, 2)
In [25]: r
Out[25]: 'isinst100 y100 enumerate www.qfedu.com 1997'
# 模式不匹配时,返回原来的值
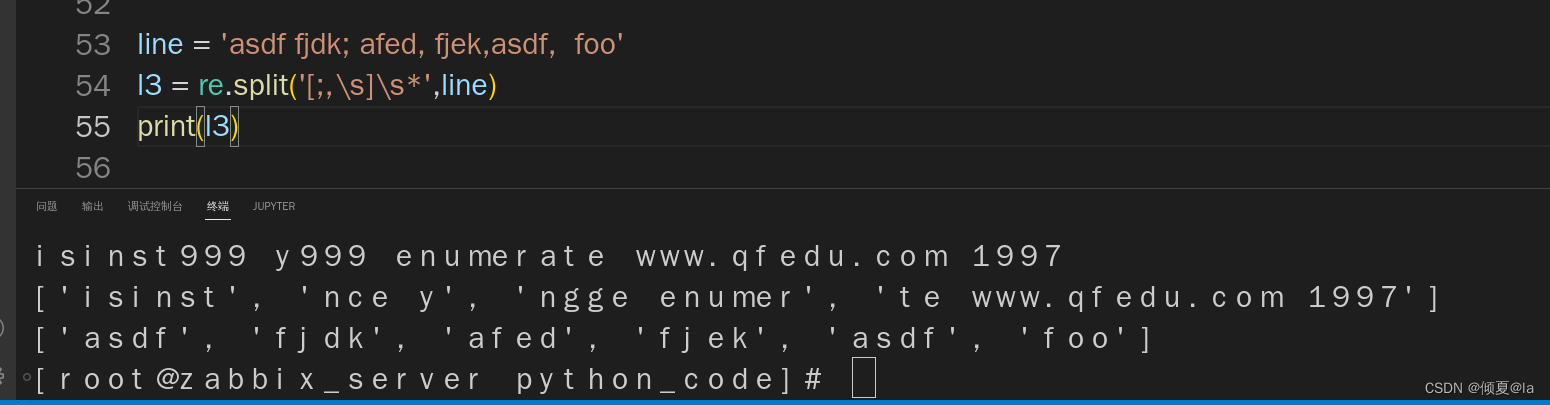
split() 分割
和 awk -F '[d]' 一样效果,以匹配到的字符进行分割,返回分割后的列表
In [26]: s
Out[26]: 'isinstance yangge enumerate www.qfedu.com 1997'
In [27]: r = re.split("a", s, 1)
使用多个界定符分割字符串
>>> line = 'asdf fjdk; afed, fjek,asdf, foo'
>>> import re
>>> re.split(r'[;,\s]\s*', line)
['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']
2. 正则分组
就是从已经成功匹配的内容中,再去把想要的取出来
# match
In [64]: s
Out[64]: 'isinstance yangge enumerate www.qfedu.com 1997'
In [65]: r = re.match("is(\w+)", s)
In [66]: r.group()
Out[66]: 'isinstance'
In [67]: r.groups()
Out[67]: ('instance',)
# search
# 命名分组
In [87]: r = re.search("is\w+\s(?P<name>y\w+e)", s)
In [88]: r.group()
Out[88]: 'isinstance yangge'
In [89]: r.groups()
Out[89]: ('yangge',)
In [90]: r.groupdict()
Out[90]: {'name': 'yangge'}
# findall
In [98]: s
Out[98]: 'isinstance yangge enumerate www.qfedu.com 1997'
In [99]: r = re.findall("a(\w+)", s)
In [100]: r
Out[100]: ['nce', 'ngge', 'ny', 'te']
# 内置模块 re
"""
\w 匹配单个字母、数字、汉子(shell中没有)和下划线,类似于[a-z A-Z 0-9]
\d [ 0-9 ]
\s 单个任意的空白字符,等价于[\t \n \r \f \v]
\S 当非空白字符
"""
# 内置模块 re
"""
\w 匹配单个字母、数字、汉子(shell中没有)和下划线,类似于[a-z A-Z 0-9]
\d [ 0-9 ]
\s 单个任意的空白字符,等价于[\t \n \r \f \v]
\S 当非空白字符
"""
import re
#match
#
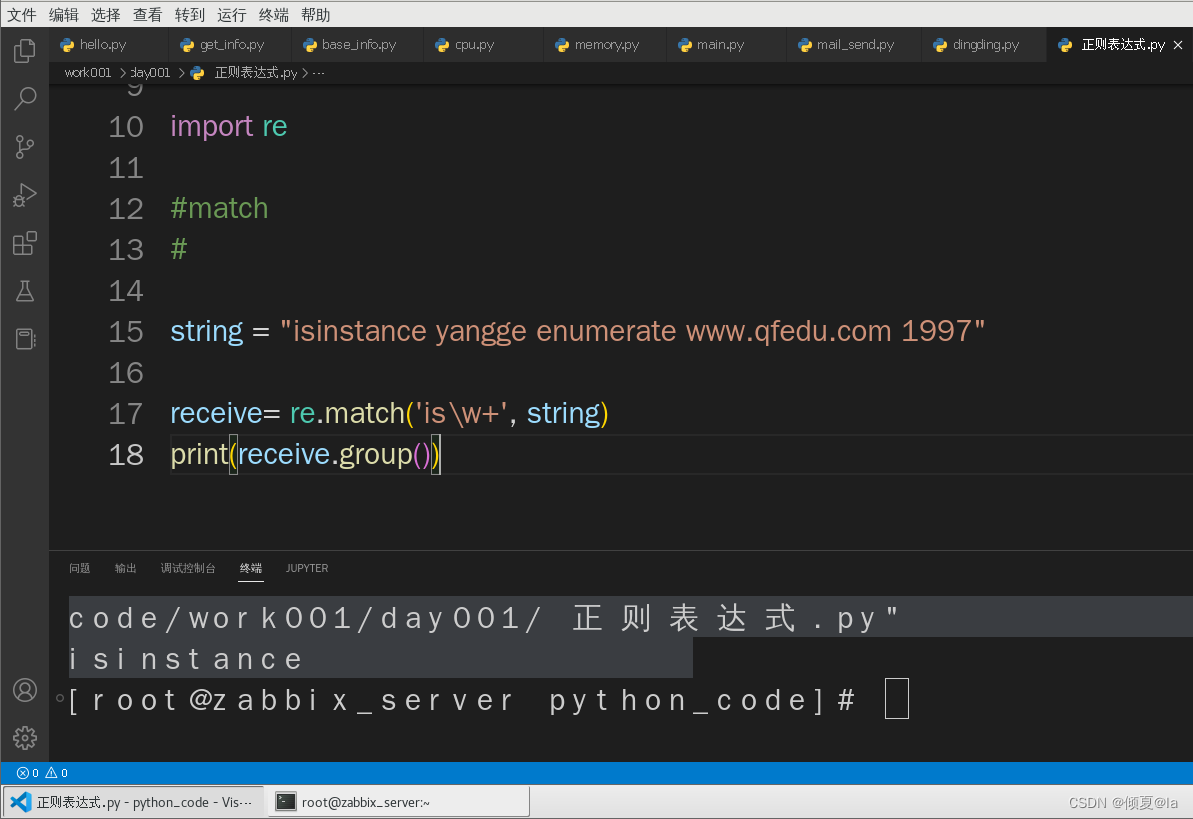
string = "isinstance yangge enumerate www.qfedu.com 1997"
receive= re.match('is\w+', string) #匹配以is开头的单词...
print(receive.group())
[root@zabbix_server python_code]# /usr/local/bin/python3 "/root/python_code/work001/day001/ 正则表达式.py"
isinstance
#search
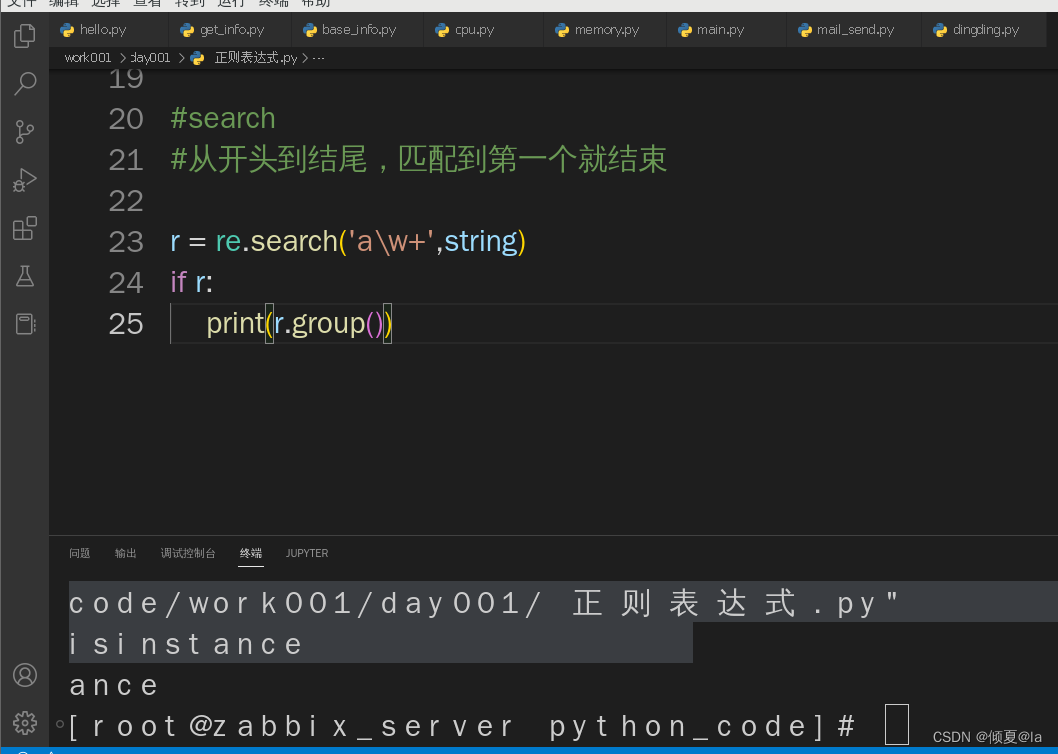
#从开头到结尾,匹配到第一个就结束
r = re.search('a\w+',string) #在一串字符串中,匹配到一个单词中带字母a的就返回,后面的就不进行匹配了
if r:
print(r.group())
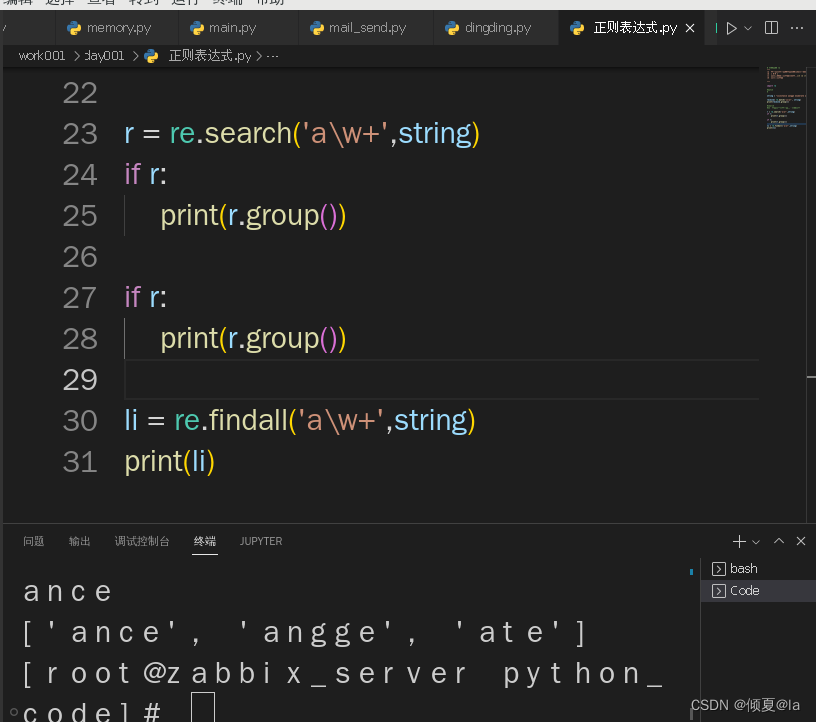
if r:
print(r.group())
li = re.findall('a\w+',string) #匹配一串字符串中所有单词中带字母a的并返回
print(li)
#sub 替换
#语法
"""
sub("a\w+", "100","string", 2)
匹配规则,替换成的新内容, 被搜索的对象,有相同的话替换的次数
"""
s1 = re.sub('a\w+','999',string)
print(s)
print(s1)

# split 相当于awk -F'[,]'
string = "isinstance yangge enumerate www.qfedu.com 1997"
l2 = re.split('a',string)#在string字符串中以字母a为分隔符
print(l2)

line = 'asdf fjdk; afed, fjek,asdf, foo'
l3 = re.split('[;,\s]\s*',line)
print(l3)
斗图地址:https://www.pkdoutu.com/
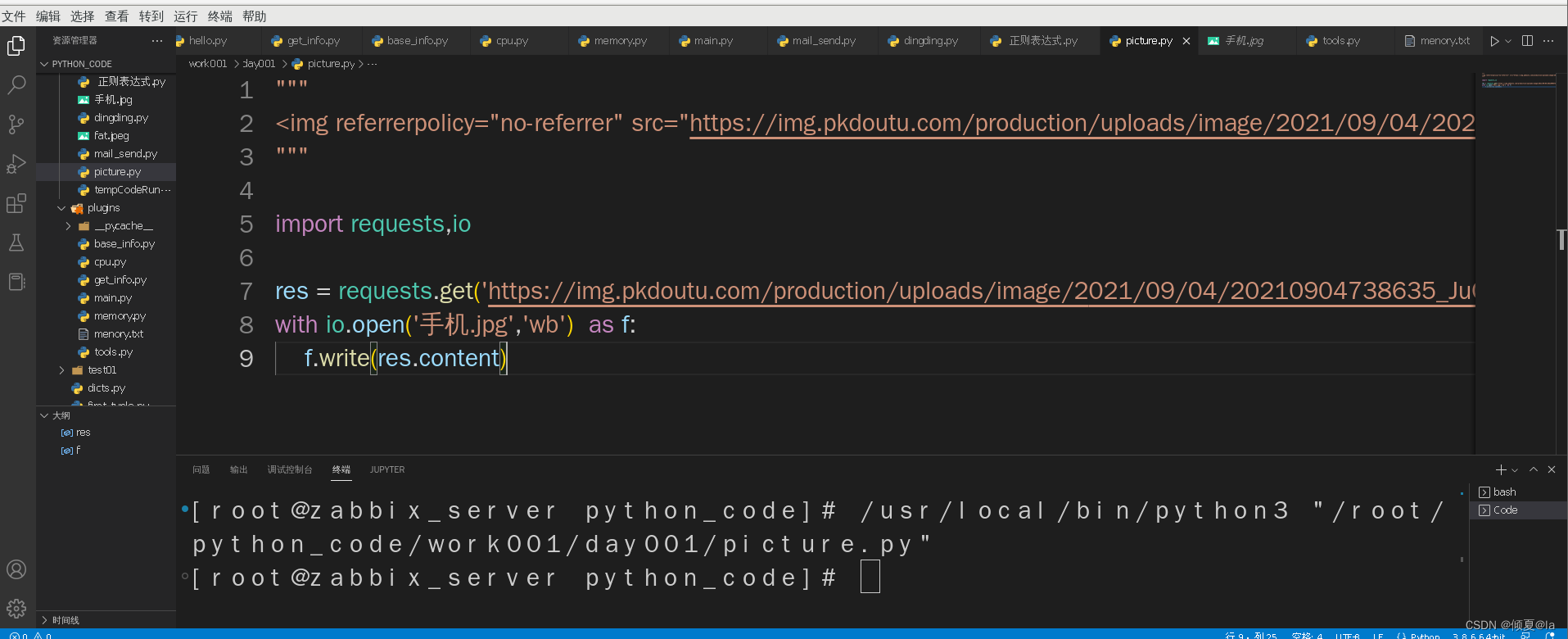
获取图片的html代码




用 requests 爬取单张图片
"""
<img referrerpolicy="no-referrer" src="https://img.pkdoutu.com/production/uploads/image/2021/09/04/20210904738635_JuCdnK.jpg" data-original="https://img.pkdoutu.com/production/uploads/image/2021/09/04/20210904738635_JuCdnK.jpg" alt="手机" class="img-responsive lazy image_dta loaded" data-backup="https://img.pkdoutu.com/production/uploads/image/2021/09/04/20210904738635_JuCdnK.jpg" data-was-processed="true">
"""
import requests,io
res = requests.get('https://img.pkdoutu.com/production/uploads/image/2021/09/04/20210904738635_JuCdnK.jpg')
with io.open('手机.jpg','wb') as f:
f.write(res.content)
获取多图
import io,re
import requests
base_url = "https://www.pkdoutu.com/photo/list/"
res = requests.get(url=base_url)
html = res.content.decode()
urls = []
for line in html.splitlines():
if 'data-original' in line:
re.search(r'.*data-original="(.*)".*',line)
if r:
url = r.groups()
url = url[0]
urls.append(url)
for index,img_url in enumerate(urls,1):
res = requests.get(url=img_url)
file_name = f'picture{index}.jpg'
with io.open(file_name,'wb') as f:
f.write(res.content)
enumerate用法介绍
>>> li = [1,2,3,4]
>>> for i in li:
... print(i)
...
1
2
3
4
>>> for i in enumerate(li):
... print(i)
...
(0, 1) #返回一个元组,第一列为序号默认从0开始,第二例为对应地值
(1, 2)
(2, 3)
(3, 4)
>>> for index,item in enumerate(li):
... print(index,item)
...
0 1 #去掉括号
1 2
2 3
3 4
>>> for index,item in enumerate(li,1):
... print(index,item)
...
1 1 #修改默认值为1
2 2
3 3
4 4
>>>