Hadoop面试题汇总
HDFS部分
1、请描述HDFS的写流程。

答:
- 首先由客户端向 NameNode 发起文件上传请求,NameNode 检查文件要上传的目录,并鉴权。
- 如果上传用户对此目录有权限,则允许客户端进行上传操作。客户端接收到允许指令后,将要上传的文件切分为 Block,之后按照顺序依次上传 block1、block2…block N,不允许多线程并发写入。
- 按照顺序,开始上传 block1。Client向 NameNode 发起请求,NameNode 会按照 block 副本放置策略,为 block1 选择合适的 DataNode 节点,并按照与客户端的路由由近到远的顺序进行排序,之后将 DataNode 列表返回给客户端。
- 客户端接收到 DataNode 列表后,便按照列表顺序(由近到远),依次与 DataNode 建立连接管道Pipline。
- 连接建立后,将 block1 以packet包的形式发送到第一个 DataNode 中,当数据写入到 DataNode 内存后,在落盘的同时会将block通过连接管道发送到第二个 DataNode 中。第二个 DataNode 接收到数据后,也会将数据推送到第三个 DataNode。
- 当最后一个 DataNode 接收到数据,并将数据写入到磁盘后,便通过Pipline管道向上一个 DataNode(即第二个)返回成功信息。第二个 DataNode 接收到返回的成功信息,并且也已经完成了数据的落盘,此时会向 第一个 DataNode 返回成功信息。第一个 DataNode 类似,接收到成功信息,并且完成数据落盘后,向Client客户端返回写入成功信息。
- 客户端接收到成功信息后,便向 NameNode 报告 block1 写入成功,然后按照此步骤,依次将剩余的 block存储到DataNode中。
- 所有的 block 存储完成后,NameNode 会在内存中生成文件所对应的元数据,提供数据查询功能。
2、请描述HDFS的读流程。

答:
- 客户端首先向 NameNode 发起读取文件的请求,NameNode 鉴定用户权限。
- 如果用户对文件有读取权限,则查询文件的元数据信息,将文件的Block组成、以及Block对应的DataNode存储位置按照与客户端的路由距离由近到远排序后返回给客户端。
- 客户端接收到 NameNode 的返回后,依次与最近的 DataNode 进行连接,请求读取 block 数据。
- DataNode将Block数据以packet包的形式发送到客户端,发送前会完成数据校验。
- 所有的 block 读取完成后,客户端会将 block 组装成文件,返回给用户。
3、请描述HDFS副本选择策略(3副本)。
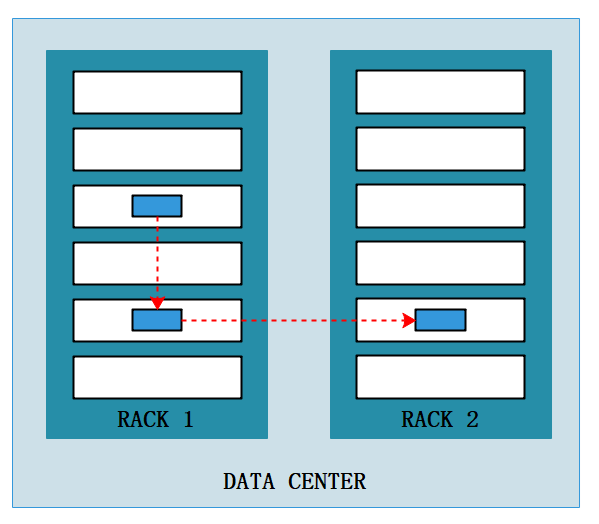
答:
- 在第一个副本放置时,会随机选择 DataNode 节点进行存放,优先选择最近、最空闲的 DataNode 节点。如果 Client 在 DataNode 节点(登录到 DataNode 节点,调用客户端进行文件上传),会直接存放在当前节点(因为网络拓扑距离最近)。
- 第二个副本会放在与第一个副本相同的机架中,选择最空闲的节点。
- 第三个副本为了保证数据的安全性,会存放在其它机架中。
- 在单机架的情况下,会随机选择空闲节点进行存储。
4、请描述HDFS的缓存机制。
答:
HDFS提供了一个高效的缓存加速机制—— Centralized Cache Management ,它允许用户指定要缓存的HDFS路径。NameNode会和保存着所需Block数据的所有DataNode通信,并指导它们把块数据缓存在堆外内存(off-heap)中进行缓存。DataNode会通过心跳机制向NameNode汇报缓存状态。
NameNode查询自身的缓存指令集来确定应该缓存哪个路径。缓存指令持久化存储在fsimage和edit日志中,可以通过Java和命令行API被添加、移除或修改。
在使用HDFS完成数据缓存时,首先要创建一个缓存池。缓存池是一个管理实体,用于管理缓存指令组。缓存池拥有类UNIX的权限,可以限制哪个用户和组可以访问该缓存池。写权限允许用户向缓存池添加、删除缓存指令 。读权限允许用户列出缓存池内的缓存指令,还有其他元数据。
缓存池也可以用于资源管理,可以设置一个最大限制值,用于限制缓存的数据量。
缓存池创建成功后,可以通过命令,将HDFS某个目录、文件缓存到缓存池中,从而完成数据缓存功能。
#创建缓存组,默认为cache_data
hdfs cacheadmin -addPool cache_data -mode 0777
#生成一个1GB大小的文件
dd if=/dev/zero of=/tmp/test.zero bs=1M count=1024
#将文件上传到HDFS
hdfs dfs -put /tmp/test.zero /data
#生成缓存指令
hdfs cacheadmin -addDirective -path /data -pool cache_data -ttl 1d
#显示缓存池的信息
hdfs cacheadmin -listPools -stats cache_data
#统计信息,显示EXP Date
hdfs cacheadmin -listDirectives -path /data
#删除缓存指令
hdfs cacheadmin -removeDirectives -path /data
#删除缓存池
hdfs cacheadmin -removePool cache_data
扩展阅读:官网文档、官网文档翻译
4、请说出几个常用的HDFS Shell命令。
答:
HDFS命令有两种风格,①hadoop fs ②hdfs dfs 。在使用上没有区别,hadoop fs内部会转换为hdfs dfs来使用。
# HDFS Shell帮助命令,help更加详细,usage简略些
hadoop fs -help [option]
hadoop fs -usage [option]
# 查看文件目录
hadoop fs -ls /
hadoop fs -ls -R /
# 创建文件
hadoop fs -touchz /edits.txt
# 创建目录
hadoop fs -mkdir /tmp_data
# 追加文件
hadoop fs -appendToFile edits.txt /edits.txt
# 查看文件内容
hadoop fs -cat /edits.txt
# 上传文件
hadoop fs -put /LocalPath /HDFSPath
hadoop fs -copyFromLocal /LocalPath /HDFSPath
hadoop fs -moveFromLocal /LocalPath /HDFSPath
# 下载文件
hadoop fs -get /HDFSPath /LocalPath
hadoop fs -copyToLocal /HDFSPath /LocalPath
# 删除文件
hadoop fs -rm /edits.txt
hadoop fs -rm -skipTrash /edits.txt
# 递归删除
hadoop fs -rm -r /shell
# 移动文件
hadoop fs -mv /originFile /newFile
# 拷贝文件
hadoop fs -copy /FilePath /dictPath
# 文件查找
hadoop fs -find / -name part-r-00000
5、HDFS文件的x权限是指?
答:
HDFS文件的x权限没有实际意义,在使用时可以忽略。目录的x权限表示是否可以访问这个目录。
6、HDFS企业级调优
答:
调整namenode处理客户端的线程数为dfs.namenode.handler.count=20 * log2(Cluster Size)。比如集群规模为8台时,此参数设置为60。
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。
Yarn部分
1、如何开启JobHistoryServer。
答:
先配置mapred-site.xml,开启JobHistoryServer。
<!-- MapReduce HistoryServer地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<!-- HistoryServer Web地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<!-- MapReduce日志保存位置 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/mr-history/log</value>
</property>
<!-- HistoryServer日志保存位置 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/mr-history/done</value>
</property>
然后配置yarn-site.xml,开启日志聚合。
<!-- 聚合日志开启后,保存到HDFS中 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
对于yarn-site.xml,还可以增加以下额外参数。
<!-- 聚合日志保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>2592000</value><!--30 day-->
</property>
<!-- 聚合日志压缩类型 -->
<property>
<name>yarn.nodemanager.log-aggregation.compression-type</name>
<value>gz</value>
</property>
<!-- 不启用聚合日志,日志在本地保存的时间 -->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>604800</value><!-- 7 day -->
</property>
<!-- nodemanager 本地文件存储目录 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/app/hadoop-2.7.7/hadoopDatas/yarn/local</value>
</property>
<!-- resourceManager 最多保存已完成任务个数 -->
<property>
<name>yarn.resourcemanager.max-completed-applications</name>
<value>1000</value>
</property>
配置文件分发到各个节点后,重启yarn。在HisotryServer节点,启动服务。
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
2、如何配置Yarn公平调度。
答:
- 首先在yarn-site.xml中进行全局配置,表示开启公平调度策略。
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>开启公平调度策略</description>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/opt/app/hadoop-2.7.7/etc/hadoop/fair-scheduler.xml</value>
<description>公平调度策略配置文件目录</description>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
<description>开启资源抢占</description>
</property>
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>0.8f</value>
<description>当集群的整体资源利用率超过80%,则开始抢占</description>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
<description>默认提交到default队列</description>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
<description>任务无法提交到现有队列,是否允许新建一个队列</description>
</property>
- 然后再编辑fair-scheduler.xml,对公平调度进行详细配置。
<?xml version="1.0"?>
<allocations>
<!-- 每个队列中的默认调度策略,默认值是fair -->
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<user name="hadoop">
<!-- 用户hadoop最多运行的任务数 -->
<maxRunningApps>30</maxRunningApps>
</user>
<!-- 默认运行任务数 -->
<userMaxAppsDefault>10</userMaxAppsDefault>
<!-- 队列划分 -->
<!-- 共有4个队列:default、hadoop、develop、test -->
<!-- 权重weight分别是:1、2、1、1.5 -->
<queue name="root">
<minResources>512mb,4vcores</minResources>
<maxResources>102400mb,100vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<weight>1.0</weight>
<schedulingMode>fair</schedulingMode>
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name="default">
<minResources>512mb,4vcores</minResources>
<maxResources>30720mb,30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<!-- 允许提交任务的用户和组 -->
<!-- 格式为:用户名1,用户名2 用户名1所属组,用户名2所属组 -->
<!-- * 表示接收所有用户的任务 -->
<!-- 默认情况下,当任务没有指定队列时,会提交到default中 -->
<aclSubmitApps>*</aclSubmitApps>
</queue>
<queue name="hadoop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>2.0</weight>
<!-- 允许提交任务的用户和组 -->
<aclSubmitApps>hadoop hadoop</aclSubmitApps>
<!-- 允许管理任务的用户和组 -->
<aclAdministerApps>hadoop hadoop</aclAdministerApps>
</queue>
<queue name="develop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1</weight>
<aclSubmitApps>develop develop</aclSubmitApps>
<aclAdministerApps>develop develop</aclAdministerApps>
</queue>
<queue name="test">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.5</weight>
<aclSubmitApps>test,hadoop,develop test</aclSubmitApps>
<aclAdministerApps>test group_businessC,supergroup</aclAdministerApps>
</queue>
</queue>
<!-- 任务提交规则,由scheduler调度器决定提交的任务进入指定队列 -->
<!-- 包含多个rule标签,rule标签默认情况下create参数=true,表示当前rule可以创建一个新队列来存放任务 -->
<queuePlacementPolicy>
<!-- 任务被提交到指定的队列;如果队列不存在,则不创建 -->
<rule name="specified" create="false"/>
<!-- 任务被提交到,以提交用户所属组名称所命名的队列;如果队列不存在,则不创建 -->
<rule name="primaryGroup" create="false" />
<!-- 当不满足以上规则,则提交到root.default队列(默认值) -->
<rule name="default" queue="root.default"/>
</queuePlacementPolicy>
</allocations>
3、如何配置Yarn容量调度。
答:
- 现在要划分的队列如下
root
├── prod
└── dev
├── spark
└── hdp
- 首先在yarn-site.xml中进行全局配置,表示开启容量调度策略。
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
- 配置capacity-scheduler.xml,对容量调度进行详细配置。
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>hdp,spark</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.hdp.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.spark.capacity</name>
<value>50</value>
</property>
</configuration>
4、可以动态更新调度器策略吗?
答:
可以,在集群不重启的情况下,在主节点执行以下命令即可。
yarn rmadmin -refreshQueues
但动态更新,只能新增、关闭队列,不能删除队列。
5、作业提交时,如何指定到特定队列。
答:
在MR中,使用mapreduce.job.queuename参数来指定。
Configuration conf = new Configuration();
conf.set("mapreduce.job.queuename", "hadoop");
6、Yarn参数调优。
答:
根据实际调整每个节点和单个任务申请内存值
-
yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,YARN不会智能的探测节点的物理内存总量,可能会导致系统宕机
-
yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)
MapReduce
1、MapReduce调优。
答:
- 采用CombineTextInputFormat来作为输入,解决输入端大量小文件场景。大量的小文件会产生大量的map任务,任务都需要初始化,从而导致mr运行缓慢
- 减少spill溢写次数:通过调整mapreduce.task.io.sort.mb及mapreduce.map.sort.spill.percent参数的值,增大触发spill的内存上限,减少spill次数,从而减少磁盘io的次数。
- 减少merge合并次数:调整mapreduce.task.io.sort.factor参数(默认10),增大merge的文件数,减少merge的次数,从而缩短mr处理时间
- 在map之后,不影响业务逻辑的情况下,先进行combine处理,减少I/O。
- 设置合理的map、reduce个数
- map进行到一定阶段时,开始分配reduce资源。由mapreduce.job.reduce.slowstart.completedmaps参数配置(默认0.05,即map进行到5%时,开始为reduce分配资源并运行),可以适当调大,如0.8,减少reduce的等待时间。
- 尽量避免使用reduce
- 合理设置reduce端的buffer:默认情况下,数据达到一定阈值的时候,Buffer中的数据会写入磁盘,然后reduce会从磁盘中获得所有的数据。即Buffer与reduce没有关联的,中间多次写磁盘、读磁盘的过程。那么可以通过调整参数,使得Buffer中的数据可以直接输送到reduce,从而减少I/O开销;mapreduce.reduce.input.buffer.percent默认为0.0,当值大于0的时候,会保留指定比例的内存读Buffer中的数值直接拿给Reducer使用。这样一来,设置Buffer需要内存,读取数据需要内存,Reduce计算也需要内存,所以要根据作业的运行情况进行调整。
- 设置数据压缩:在map端可以设置数据压缩,减少shuffle开销。reduce处理结果落盘时,也可以进行数据压缩,减少数据量。
2、常见调优参数。
- 资源相关参数,在MR程序中设置即可生效。
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.map.memory.mb | 一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.reduce.memory.mb | 一个ReduceTask可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.map.cpu.vcores | 每个MapTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.cpu.vcores | 每个ReduceTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.shuffle.parallelcopies | 每个Reduce去Map中取数据的并行数。默认值是5 |
| mapreduce.reduce.shuffle.merge.percent | Buffer中的数据达到多少比例开始写入磁盘。默认值0.66 |
| mapreduce.reduce.merge.inmem.threshold | Buffer中的数据文件达到多少后开始写入磁盘,默认1000 |
| mapreduce.reduce.shuffle.input.buffer.percent | Buffer大小占Reduce可用内存的比例。默认值0.7 |
| mapreduce.reduce.input.buffer.percent | 指定多少比例的内存用来存放Buffer中的数据,默认值是0.0 |
- 资源相关参数,需要重启yarn才会生效(yarn-site.xml)
| 配置参数 | 参数说明 |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 给应用程序Container分配的最小内存,默认值:1024 |
| yarn.scheduler.maximum-allocation-mb | 给应用程序Container分配的最大内存,默认值:8192 |
| yarn.scheduler.minimum-allocation-vcores | 每个Container申请的最小CPU核数,默认值:1 |
| yarn.scheduler.maximum-allocation-vcores | 每个Container申请的最大CPU核数,默认值:32 |
| yarn.nodemanager.resource.memory-mb | 给Containers分配的最大物理内存,默认值:8192 |
- Shuffle性能优化的关键参数,重启yarn后生效(mapred-site.xml)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.task.io.sort.mb | Shuffle的环形缓冲区大小,默认100m |
| mapreduce.map.sort.spill.percent | 环形缓冲区溢出的阈值,默认80% |
- Shuffle性能优化的关键参数,重启yarn后生效(mapred-site.xml)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.map.maxattempts | 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.reduce.maxattempts | 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.task.timeout | Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个Task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远Block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。 |
3、MapReduce过程中,如何解决数据倾斜问题
答:
- 注意空数据的情况,否则空数据都会被分发到reduce-0中进行运算。可以提前对空数据进行过滤,或者将空数据均匀赋值。
- 使用Combiner进行预合并,精简数据,减少数据倾斜的可能。
- 可以进行自定义分区Partitioner,决定数据的分发过程。
- 采用Map Join,尽量避免Reduce Join
4、MapReduce过程中,如何避免小文件问题
答:
- 数据上传HDFS时,提前进行数据合并。可以物理合并,或者打包成sequence file。
- 存在HDFS上的小文件,可以使用hadoop archive进行归档。它能将多个小文件打包成一个HAR文件。
- 在MapReduce进行处理时,使用CombineFileInputFormat将多个文件合并成一个单独的split;或者开启jvm重用,设置mapreduce.job.jvm.numtasks值在10到20之间,一个map运行在一个jvm上,开启重用的话,该map在jvm上运行完毕后,此jvm中会继续运行此job的其他map任务。
5、请描述Reduce过程。
答:
-
Copy阶段:ReduceTask从各个MapTask上远程拷贝数据,并针对某一块数据,如果其大小超过一定阈值(内存缓存*25%),则写到磁盘上,否则直接放到内存中(jvm*70%)。
-
Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,一次合并10个,合并成有序的大文件,以防止内存使用过多或磁盘上文件过多。
-
Sort阶段:当所有map task的分区数据全部拷贝完,会对数据进行分组操作,将key相同的数据聚在一起。Hadoop采用了基于排序的策略,由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
-
Reduce阶段:数据交给reduce任务进行运算,将计算结果写到HDFS上。
6、MapReduce在进行HashPartitoner时,会获取key的hashCode,之后为什么要与Integer.MAX_VALUE进行逻辑与计算?
答:
- 源码部分如下
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
- (key.hashCode() & Integer.MAX_VALUE),因为Integer.MAX_VALUE最高位是符号位0,表示正数。如果hashCode得到的值为负数,符号位为1,会影响哈希取模的结果(Partition不能为负),此时进行逻辑与计算后,会变成一个正整数,从而保证取模结果正确。
7、如何实现自定义Partitioner?
答:
- 创建自定义类,继承Partitioner,重写getPartition方法。
public class MyPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// TODO Auto-generated method stub
return 0;
}
}
- 在Job中设置setPartitionerClass,并配置ReduceTask数量。
job.setNumReduceTasks(5);
job.setPartitionerClass(MyPartitioner.class);
8、Hadoop为什么不用Java内置的序列化方法
答:
Java的序列化框架(Serializable)比较重,对象被序列化后,会携带很多额外信息(校验值、Header、继承体系等),不便于在网络中高效传输。所以Hadoop开发了自己的序列化机制。
9、Hadoop数据类型Writable,与Java基本数据类型有什么区别?
答:
public interface WritableComparable<T> extends Writable, Comparable<T>
Writable实现了WritableComparable接口,间接继承了Writable, Comparable类,实现了序列化、排序的功能。而这两个功能,在MapReduce中非常重要,排序是MapTask、ReduceTask默认操作,在集群中进行数据传输时要进行序列化。
10、Hadoop中如何实现自定义序列化
答:
在自定义类中,实现org.apache.hadoop.io.Writable接口,并实现write、readFields方法,完成序列化操作。
public class Person implements Writable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "My name is " + this.name + ", and i'm " + this.age + " years old.";
}
// 序列化
@Override
public void write(DataOutput out) throws IOException {
out.write(this.name.getBytes());
out.writeInt(this.age);
}
// 反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.setName(in.readLine());
this.setAge(in.readInt());
}
}
11、在MapReduce进行数据处理时,会进行split数据切片,它的默认拆分规则是?如果不按照默认规则进行拆分,会发生什么现象?
答:
- MapReduce默认按照128M进行数据split切分(与HDFS Block大小相同),具体计算规则为:
Math.max(minSize, Math.min(maxSize, blockSize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue 默认值Long.MAXValue
blockSize为128M
- 可以通过改变minsize、maxSize参数,来调整split规则。
mapreduce.input.fileinputformat.split.maxsize
mapreduce.input.fileinputformat.split.minsize
- 当剩余的文件大于splitSize的1.1倍时,才进行拆分,避免生成较小的切片。例如当前文件为129M,小于splitSize(128M)的1.1倍,所以不做拆分。
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
...
bytesRemaining -= splitSize;
}
- 如果数据存储在HDFS中,按128M进行拆分。调整了split大小后,会导致数据移动。假设需要处理的文件大小为300M,存储到HDFS中后被拆分为3个Block块(128M、128M、44M)。此时MapReduce按照100M进行split,那么Block1拆出100M后剩余的28M会通过网络传输到Block2节点,Block2拆分100M后剩余56M通过网络传输到Block3节点,Block3此时正好拥有100M数据,完成切分。这个过程,会增加额外开销。
12、在MapReduce中InputFormat做了什么事情?
答:
- InputFormat抽象类拥有两个方法,getSplits、createRecordReader。
- 其中,getSplits完成数据的切片操作。createRecordReader为切片后的数据创建RecordReader。
- RecordReader可以将数据拆分为key/value形式。
13、请描述MapReduce所有的FileInputFormat,并分别说明它们的用法(除CombineTextInputFormat)。
答:
- TextInputFormat、KeyValueInputFormat、NLineInputFormat、CombineTextInputFormat、FixedLengthInputFormat、SequenceFileInputFormat。
- TextInputFormat使用默认InputFormat的切片方法,在进行数据读取时,createRecordReader会返回LineRecordReader,它会将每一行数据的行号作为key,这行数据作为value。
- NLineInputFormat使用自定义切片方法,每N行会拆分为一片。在进行数据读取时,createRecordReader会返回LineRecordReader,它会将每一行数据的行号作为key,这行数据作为value。
- KeyValueInputFormat使用默认InputFormat的切片方法,在进行数据读取时,createRecordReader会返回KeyValueLineRecordReader,它会将每一行数据默认按照\t进行切分,拆分后赋值给key、value。可以通过配置conf.set(KeyValueLineRecordReaderKEY_VALUE_SEPERATOR, “\t”)来设定分隔符。
- FixedLengthInputFormat使用默认InputFormat的切片方法。在进行数据读取时,createRecordReader会返回FixedLengthRecordReader,它会将数据的偏移量作为key,数据作为value。
- SequenceFileInputFormat使用默认InputFormat的切片方法。在进行数据读取时,createRecordReader会返回SequenceFileRecordReader,它会读取Sequence文件。
14、请详细描述下CombineTextInputFormat。
答:
- CombineTextInputFormat使用自定义切片方法,它能够解决小文件问题。生成切片的过程包括:虚拟存储过程和切片过程两部分。切分时,需要设置虚拟存储切片最大值。
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
-
虚拟存储过程:将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
-
切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
15、如何自定义InputFormat?
答:
- 创建自定义类,继承需要的InputFormat,如FileInputFormat。重写createRecordReader方法,返回自定义RecordReader。
- 创建自定义RecordReader,继承RecordReader类,并重写方法。
// 初始化资源,一般用于打开IO流
// 常用IO流为FSDataInputStream,默认会定义在成员变量中:inputStream
public void initialize(InputSplit split,
TaskAttemptContext context
) throws IOException, InterruptedException
{
FileSplit fs = (FileSplit) split;
Path path = fs.getPath();
FileSystem fileSystem = path.getFileSystem(context.getConfiguration());
inputStream = fileSystem.open(path);
}
// 关闭资源,一般用于关闭IO流
public void close() throws IOException {
IOUtils.closeStream(inputStream);
}
// 类似于指针,如果要读取的数据存在,返回true,否则返回false
public boolean nextKeyValue() throws IOException, InterruptedException {
}
// 获取当前行的key
public KEYIN getCurrentKey() throws IOException, InterruptedException;
// 获取当前行的value
public VALUEIN getCurrentValue() throws IOException, InterruptedException;
// 返回数据读取进度,0-1
public float getProgress() throws IOException, InterruptedException;
- 为Job指定InputFormat。
job.setInputFormatClass();
16、自定义InputFormat时,如果不想让文件在读取时被切片,可以怎么做?
答:
- 重写isSplitable方法,返回false。
17、如果没有自定义Map、Reduce,默认会执行什么操作?
答:
- Mapper会读取数据,然后输出(key,value)。Reducer接收数据,遍历value后输出(key,value)。相当于是按照InputFormat将数据读取为(key,value)格式后原样输出。
18、如何实现自定义排序?
答:
- 默认排序方式是按照字典序升序,使用快速排序实现。
- 自定义排序,需要在自定义数据类中,实现WritableComparable接口(Writable、Comparable),重写compareTo方法。
// 如果返回正数,o在前面;返回负数,表示o在后面;相等,返回0
// 意味着如果降序,则o>this时,返回正数;o<this时返回负数。升序时,this>o返回正数;this<o返回负数
public int compareTo(T o) {
return Long.compare(o.value,this.value);
};
19、什么是Combiner?如何设置?
答:
- Combinner是在Map端提前进行的数据聚合操作,对Key相同的数据进行合并。以减少在shuffle阶段传输的数据量。
- 在Job中使用setCombinerClass进行配置。
20、如果Map输出时value没有意义(为空),应该如何处理?
答:
- 在使用Context写出时,value定义为NullWritable.get(),表示数据为空。
21、如何实现自定义分组
答:
- 自定义类,继承WritableComparator类。实现OrderComparator、comparable方法。
public class OrderGroupingComparator extends WritableComparator {
// 初始化空对象用于数据接收
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b;
int result;
if (aBean.getOrder_id() > bBean.getOrder_id()) {
result = 1;
} else if (aBean.getOrder_id() < bBean.getOrder_id()) {
result = -1;
} else {
result = 0;
}
return result;
}
}
22、Reduce如何实现分组操作?
答:
- Reduce分组的结果是,把key相同的数据,value值放置在一个迭代器中,即(key,Iterable(values))。
- 从Map端拿到所需文件后,合并成一个有序的大文件。然后指针会指向文件的第一个数据,将key,value进行反序列化,处理后,指针会指向下一条数据。此时会判断当前数据是否和上一条数据为一组,如果是一组则返回true,否则返回false。
23、如何实现自定义输出?
答:
- 自定义MyRecordWriter,继承RecordWriter,实现方法,完成自定义输出。
public class MyRecordWriter extends RecordWriter<Text, IntWritable> {
private FSDataOutputStream file;
// 自定义方法,开流
public void initialize(TaskAttemptContext job) throws IOException {
String outdir = job.getConfiguration().get(FileOutputFormat.OUTDIR);
FileSystem fileSystem = FileSystem.get(job.getConfiguration());
file = fileSystem.create(new Path(outdir));
}
// 将数据写出
@Override
public void write(Text key, IntWritable value) throws IOException, InterruptedException {
// TODO Auto-generated method stub
file.write(value.hashCode());
}
// 关闭资源
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
IOUtils.closeStream(file);
}
}
- 自定义OutputFormat,继承FileOutputFormat,重写getRecordWriter方法。
public class MyOutputFormat extends FileOutputFormat<Text, IntWritable> {
@Override
public RecordWriter<Text, IntWritable> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
MyRecordWriter mRecordWriter = new MyRecordWriter();
mRecordWriter.initialize(job);
return mRecordWriter;
}
}
24、如何在MapReduce中实现MapJoin?
答:
- 在驱动函数中将数据加载到缓存
job.addCacheFile(new URI("path"));
- 在Mapper的setup阶段,将文件读取到缓存集合中。
URI[] cacheFiles = context.getCacheFiles();
String path = cacheFiles[0].toString();
BufferReader bufferReader = new BufferReader(new FileReader(path));
String line;
while (StringUtils.isNotEmpty(line = bufferReader.readLine())){
//进行数据处理
}