💦 作者:韩信子@ShowMeAI
📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40
📘 本文地址:https://www.showmeai.tech/article-detail/393
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

做 Python 数据分析和机器学习的同学都非常喜欢 pandas 这个工具库,它操作简单功能强大,可以很方便完成数据处理、数据分析、数据变换等过程,优雅且便捷。
📘 Python数据分析实战教程
但是,pandas对于大型的数据处理却并不是很高效,在读取大文件时甚至会消耗大量时间。那么对于大型数据集,是否有一个工具,既可以像 pandas 一样便捷操作 Dataframe,又有极高的效率,同时也没有 spark 那样复杂的用法和硬件环境要求呢?有!大家可以试试 📘Vaex。

📘Vaex 是一个非常强大的 Python DataFrame 库,能够每秒处理数亿甚至数十亿行,而无需将整个数据集加载到内存中。这使得它对于超过单台机器可用 RAM 的大型数据集的探索、可视化和统计分析特别有用,而且 Vaex 还兼具便利性和易用性。
在本文中,ShowMeAI将给大家介绍这个强大的工具,让你在处理大数据分析工作时更加高效。
💡 vaex 使用详解
💦 1.巨型文件读取&处理(例如CSV)
Vaex 工具的设计初衷就包括以高效的方式处理比可用内存大得多的文件。借助于它,我们可以轻松处理任意大的数据集。Vaex 在过去的版本中支持二进制文件格式,例如 HDF5、 Arrow 和 Parquet 。从4.14.0版本以来,它也可以像使用上述格式一样轻松打开和使用巨型 CSV 文件。这在一定程度上要归功于 📘Apache Arrow项目,它提供了一个相当高效的 CSV 读取器。

注:本文使用到的数据可以在 📘数据官网 获取。
下面是读取大文件时的用法:
print('Check file size on disk:')
!du -h chicago_taxi_2013_2020.csv
print()
df = vaex.open('chicago_taxi_2013_2020.csv')
print(f'Number of rows: {df.shape[0]:,}')
print(f'Number of columns: {df.shape[1]}')
mean_tip_amount = df.tip_amount.mean(progress='widget')
print(f'Mean tip amount: {mean_tip_amount:.2f}')
df.fare_amount.viz.histogram(shape=128, figsize=(6, 4), limits=[0, 42], progress='widget');
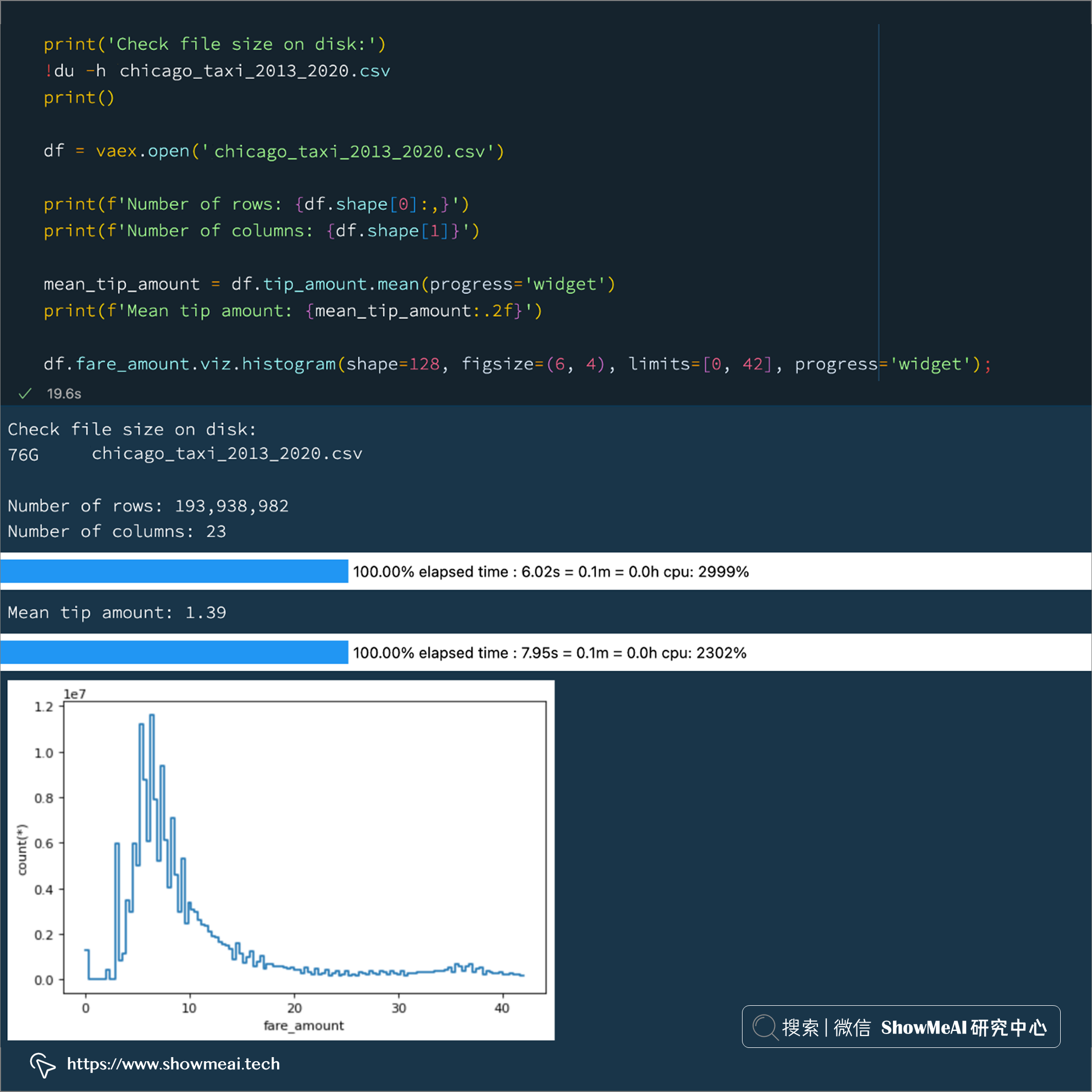
上面的示例显示了 vaex 轻松处理巨型 CSV 文件(76 GB CSV 文件)。上述过程的详细说明如下:
① 当我们使用vaex.open()对于 CSV 文件,Vaex 将流式处理整个 CSV 文件以确定行数和列数,以及每列的数据类型。这个过程不会占用大量 RAM,但可能需要一些时间,具体取决于 CSV 的行数和列数。
可以通过
schema_infer_fraction控制 Vaex 读取文件的程度。数字越小,读取速度越快,但数据类型推断可能不太准确(因为不一定扫描完所有数据)。在上面的示例中,我们使用默认参数在大约 5 秒内读取了 76 GB 的 CSV 文件,其中包含近 2 亿行和 23 列。
② 然后我们通过 vaex 计算了tip_amount列的平均值,耗时 6 秒。
③ 最后我们绘制了tip_amount列的直方图,耗时 8 秒。
也就是说,我们在 20 秒内读取了整个 76 GB CSV 文件 3 次,而无需将整个文件加载到内存中。
📢 注意,无论文件格式如何,Vaex 的 API 都是相同的。这意味着可以轻松地在 CSV、HDF5、Arrow 和 Parquet 文件之间切换,而无需更改代码。
当然,就本身性能而言,使用 CSV 文件并不是最佳选择,出于各种原因,通常应避免使用。尽管如此,大型 CSV 文件在日常工作中还是会遇到,这使得此功能对于快速检查和探索其内容以及高效转换为更合适的文件格式非常方便。
💦 2.统计:分组聚合
数据分析中最常见的操作之一就是分组聚合统计,在 Vaex 中指定聚合操作主要有两种方式:
- ① 指定要聚合的列,以及聚合操作的方法名称。
- ② 指定输出列的名称,然后显式实现vaex聚合统计方法。
下面我们看下如何实际操作。本文后续部分,我们将使用 📘NYC Taxi 数据集的一个子集,包含10亿+条数据记录。
df = vaex.open('yellow_taxi_2009_2015_f32.hdf5')
print(f'Number of rows: {df.shape[0]:,}')
print(f'Number of columns: {df.shape[1]}')
df.groupby(df.vendor_id, progress='widget').agg(
{'fare_amount': 'mean', # Option 1
'tip_amount_mean': vaex.agg.mean(df.tip_amount), # Option 2
})
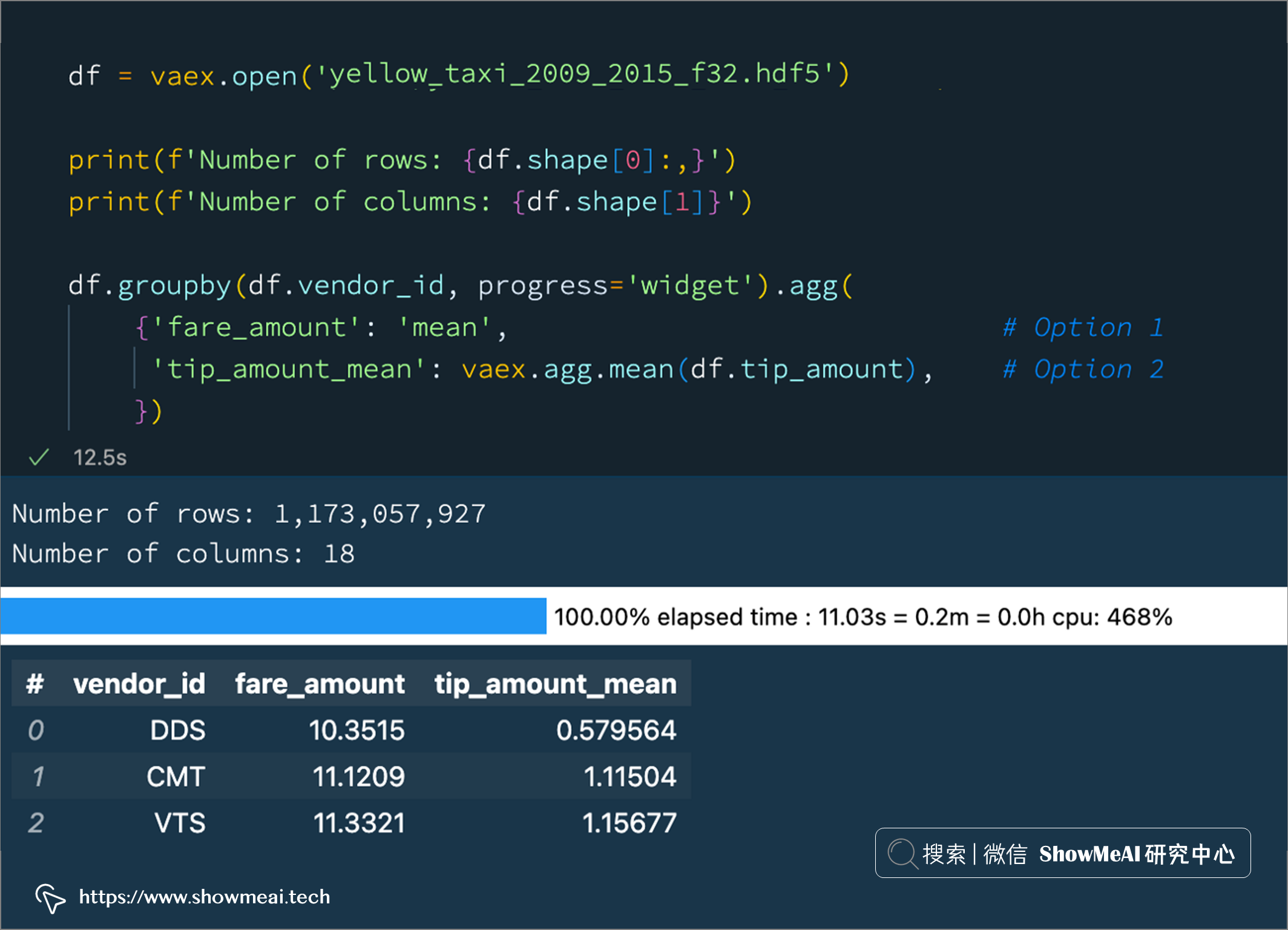
上述的操作方法和 pandas Dataframe 是基本一致的。Vaex 还支持如下的第2种方式:
df.groupby(df.vendor_id, progress='widget').agg(
{'fare_amount_norm': vaex.agg.mean(df.fare_amount) / vaex.agg.std(df.fare_amount)}
)
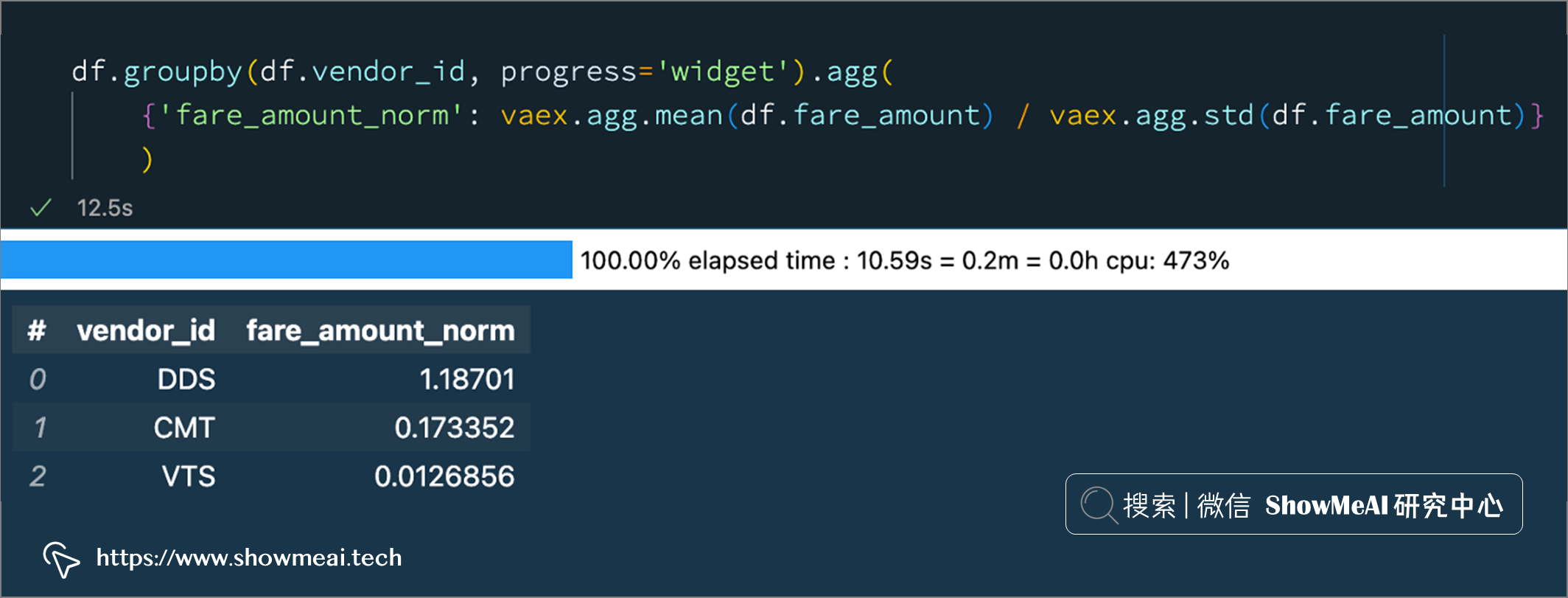
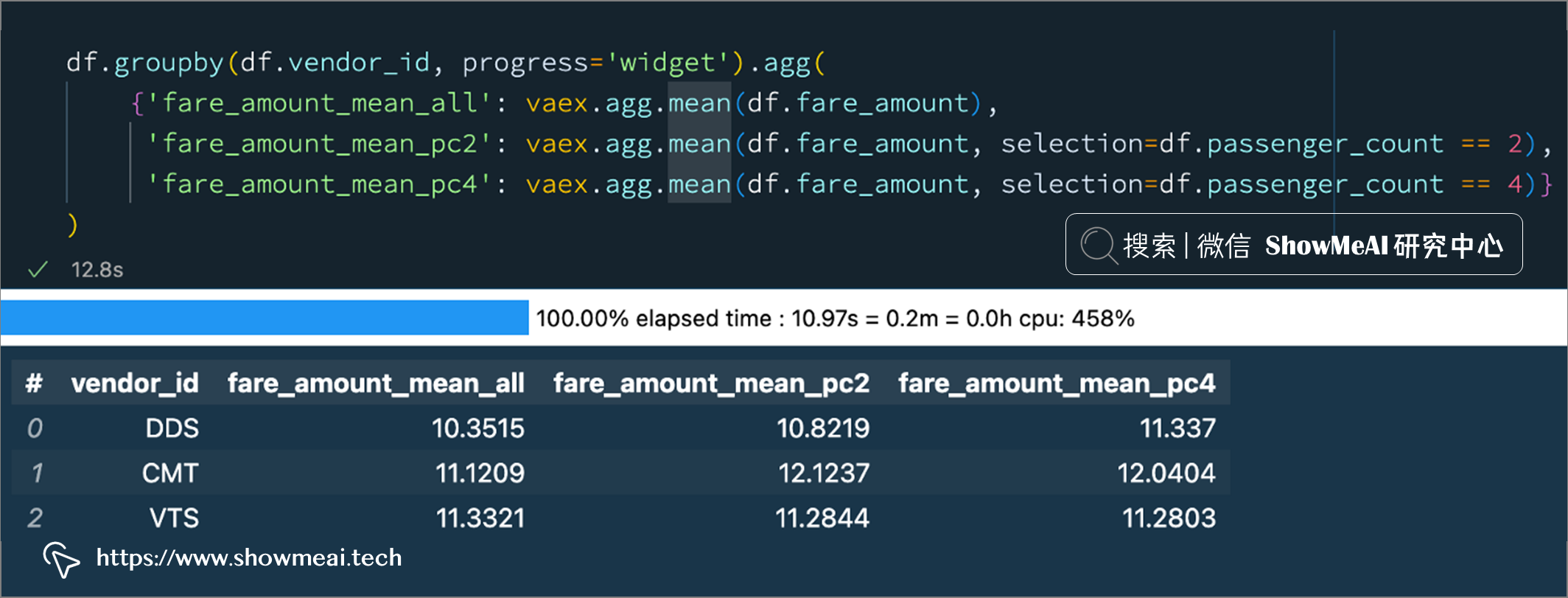
明确定义聚合函数方法(上面的第2种方式)还支持进行条件选择,例如下例中,我们对全部数据,以及passenger_count为 2 和 4 的数据进行聚合统计:
df.groupby(df.vendor_id, progress='widget').agg(
{'fare_amount_mean_all': vaex.agg.mean(df.fare_amount),
'fare_amount_mean_pc2': vaex.agg.mean(df.fare_amount, selection=df.passenger_count == 2),
'fare_amount_mean_pc4': vaex.agg.mean(df.fare_amount, selection=df.passenger_count == 4)}
)
💦 3.进度条
大家在之前使用 pandas 进行数据分析时,有时候我们会将中间过程构建为 pipeline 管道,它包含各种数据处理变换步骤。每次执行,如果我们只能等待数据处理完毕,那我们对全过程没有太多的把控。
Vaex非常强大,它可以指示每个步骤需要多长时间以及整个管道完成之前还剩下多少时间,在处理巨型文件时,进度条非常有用。
实际在巨型文件上操作的过程和结果是下面这样的:
with vaex.progress.tree('rich'):
result_1 = df.groupby(df.passenger_count, agg='count')
result_2 = df.groupby(df.vendor_id, agg=vaex.agg.sum('fare_amount'))
result_3 = df.tip_amount.mean()
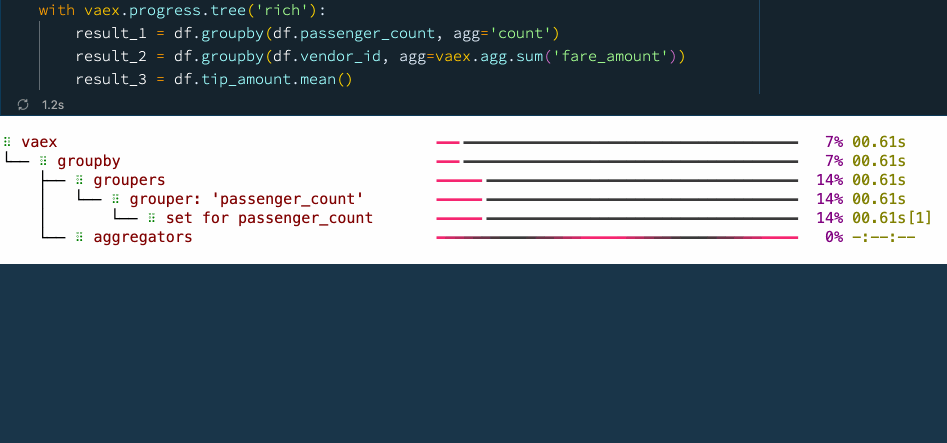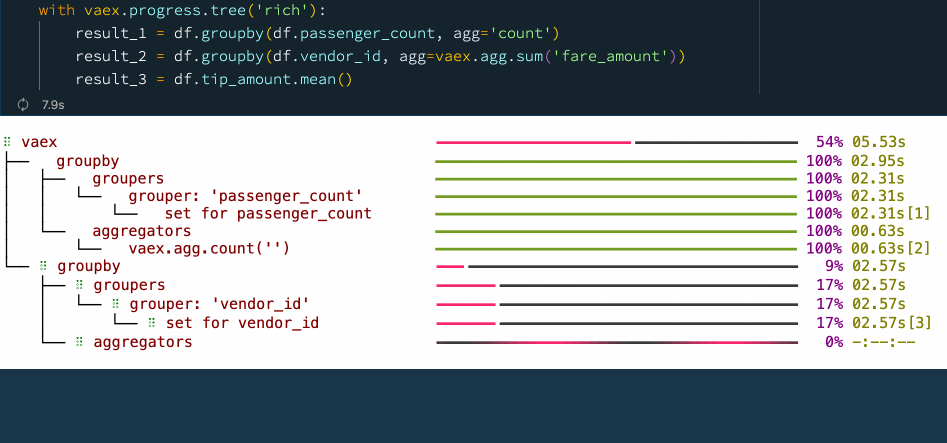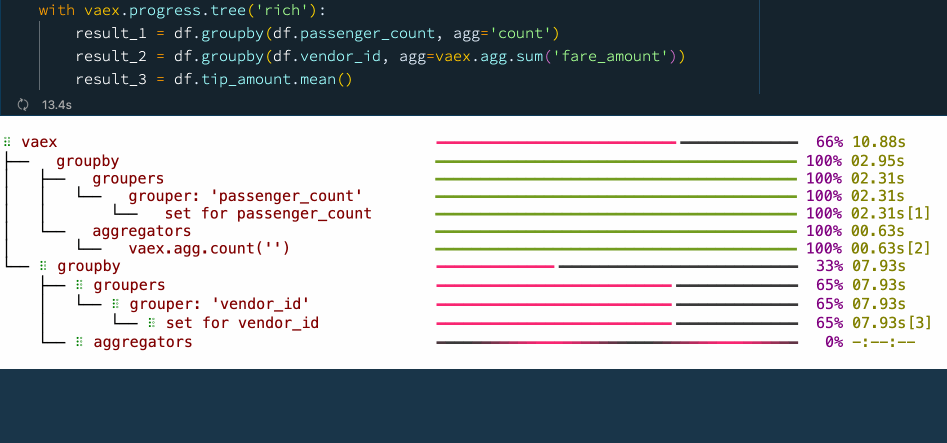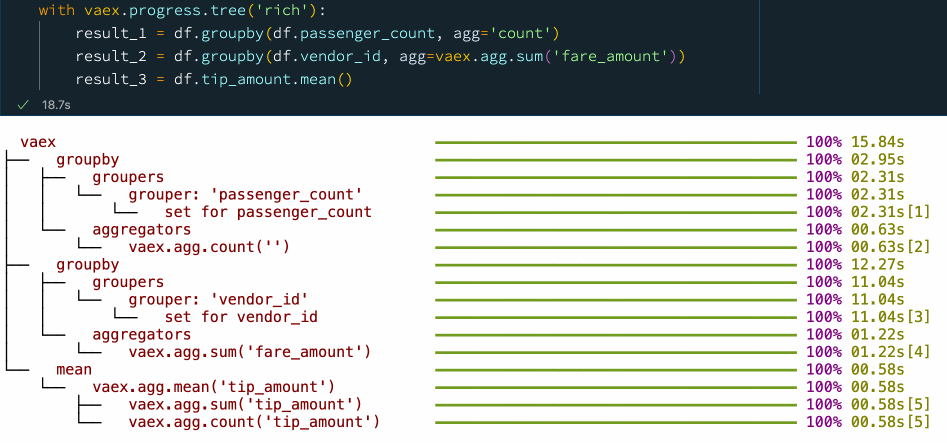
在上图示例的进度条图中,您可以看到每个步骤所花费的时间。这不仅能让我们掌握数据处理的进度和过程,也让我们知道整个流程的时间瓶颈在哪,以便更好地进行优化和处理。
💦 4.异步计算
Vaex 具备懒惰计算(lazy computation)的特效,只在必要时计算表达式。一般准则是,对于不改变原始 DataFrame 基本性质的操作,这些操作是惰性计算的。例如:
- 从现有列中创建新列
- 将多个列组合成一个新列
- 进行某种分类编码
- DataFrame 数据过滤
其他的一些操作,会进行实质性计算,例如分组操作,或计算聚合(例列的总和或平均值)。
在进行交互式数据探索或分析时,这种工作流在性能和便利性之间提供了良好的平衡。
当我们定义好数据转换过程或数据管道时,我们希望工具在计算时能进行性能优化。Vaex 支持delay=True等参数,可以并行执行计算与操作,使得 Vaex 可以提前构建计算图,并尝试找到最有效的计算结果的方式。
如下例:
with vaex.progress.tree('rich'):
result_1 = df.groupby(df.passenger_count, agg='count', delay=True)
result_2 = df.groupby(df.vendor_id, agg=vaex.agg.sum('fare_amount'), delay=True)
result_3 = df.tip_amount.mean(delay=True)
df.execute()
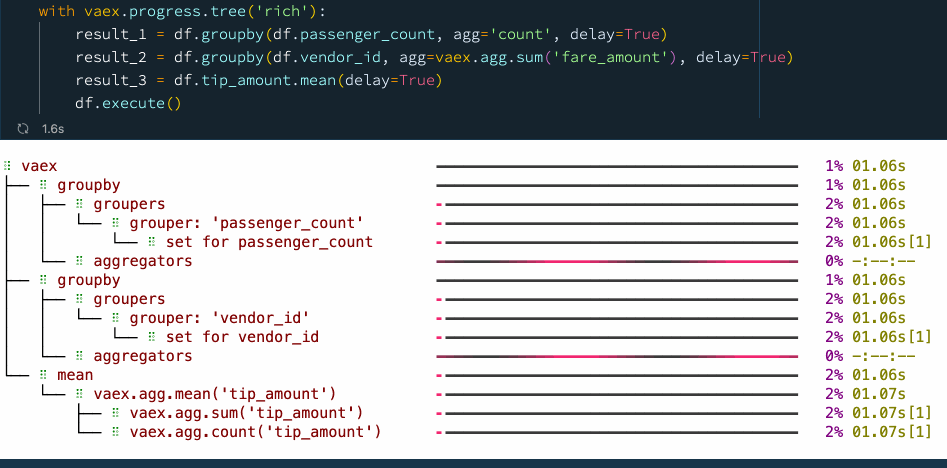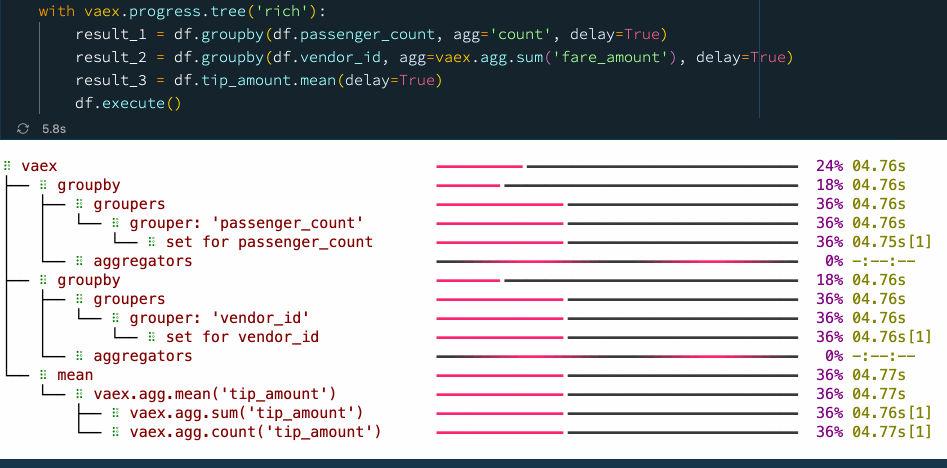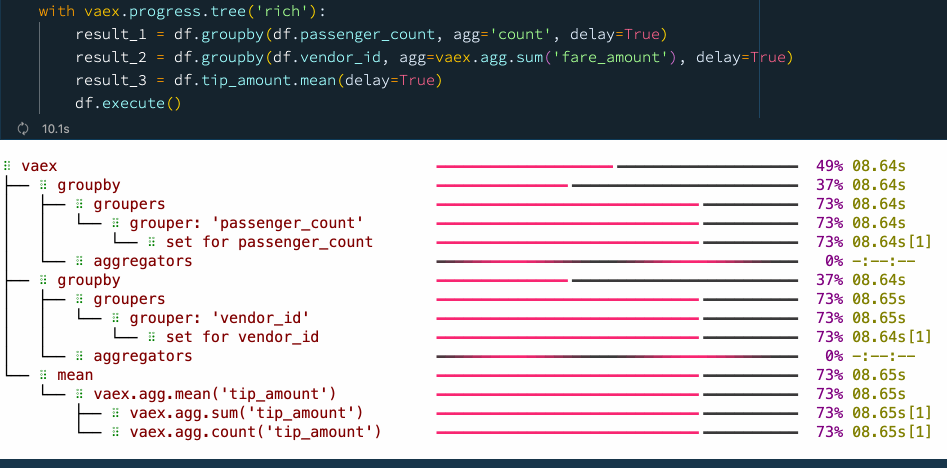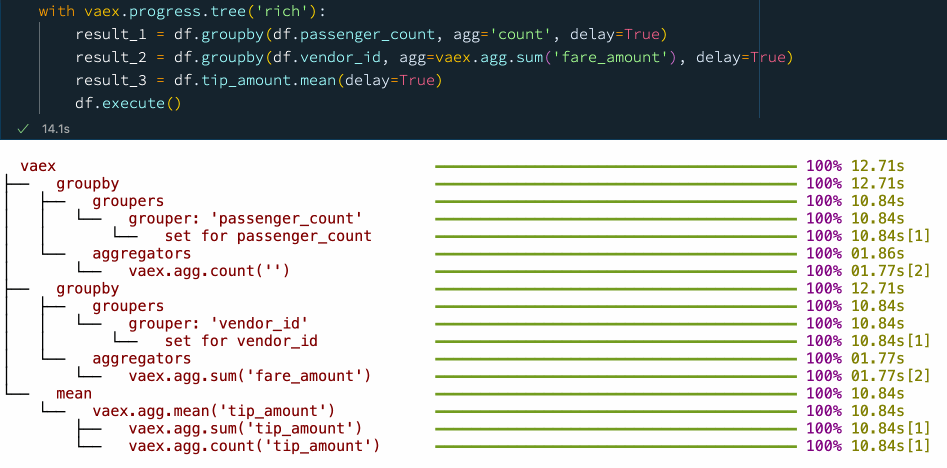
我们看到,通过显式使用延迟计算,我们可以提高性能并减少检查数据的次数。在这种情况下,我们在使用延迟计算时从 5 次通过数据变为仅 2 次,从而使速度提高了大约 30%。大家可以在 📘Vaex异步编程官方指南 里找到更多示例。
💦 5.结果缓存
因为效率高,Vaex经常会用作仪表板和数据应用程序的后端,尤其是那些需要处理大量数据的应用程序。
使用数据应用程序时,通常会在相同或相似的数据子集上重复执行某些操作。例如,用户将从同一个“主页”开始,选择常见或高频的选项,然后再深入研究数据。在这种情况下,缓存操作结果通常很有用。Vaex 实现了一种 📘先进的细粒度的缓存机制 ,它允许缓存单个操作的结果,以后可以重复使用。
以下示例是具体使用方法:
vaex.cache.on()
with vaex.progress.tree('rich'):
result_1 = df.passenger_count.nunique()
with vaex.progress.tree('rich'):
result_2 = df.groupby(df.passenger_count, agg=vaex.agg.mean('trip_distance'))
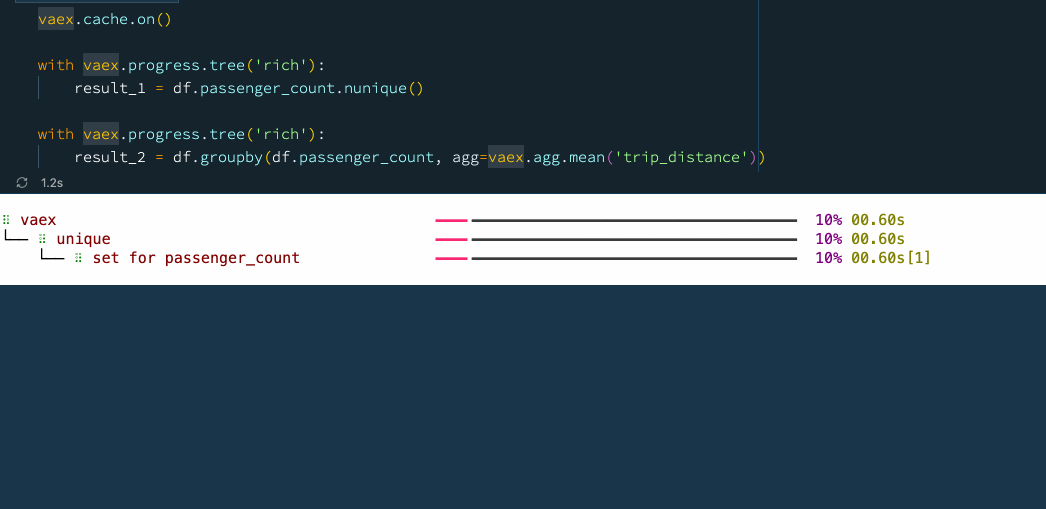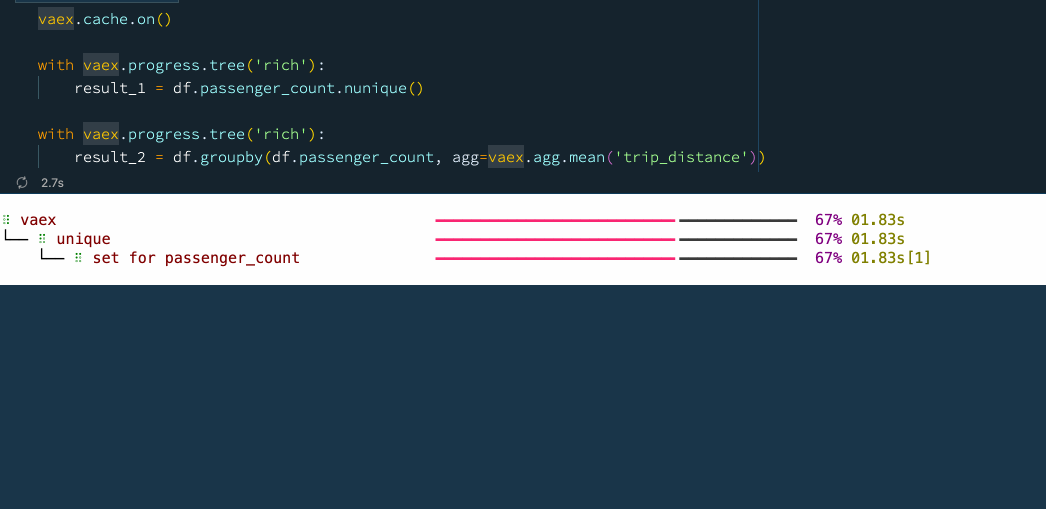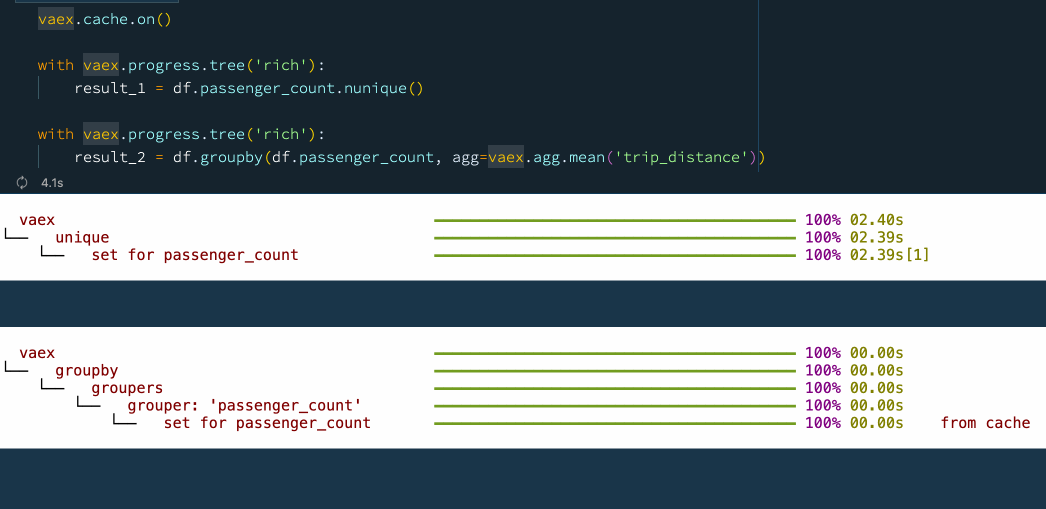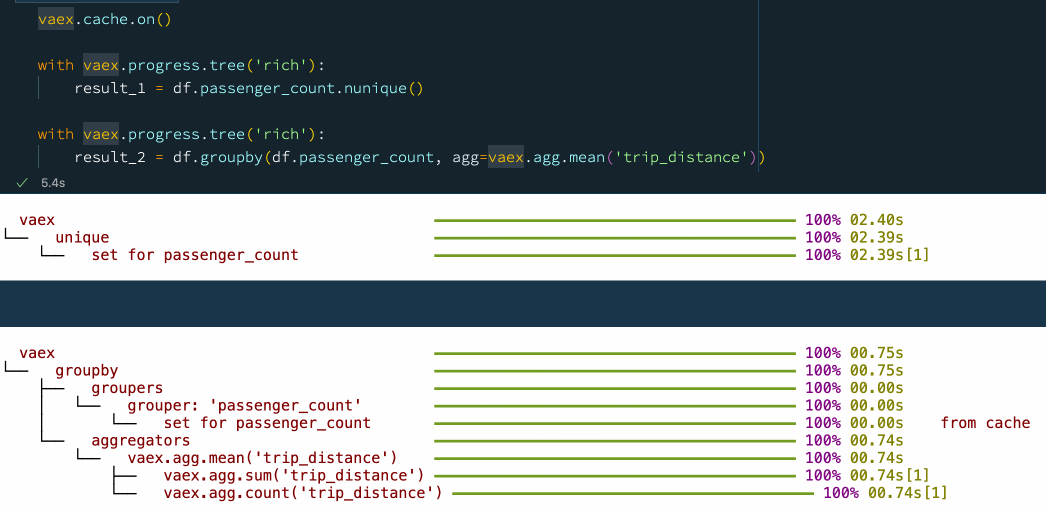
💦 6.提前停止
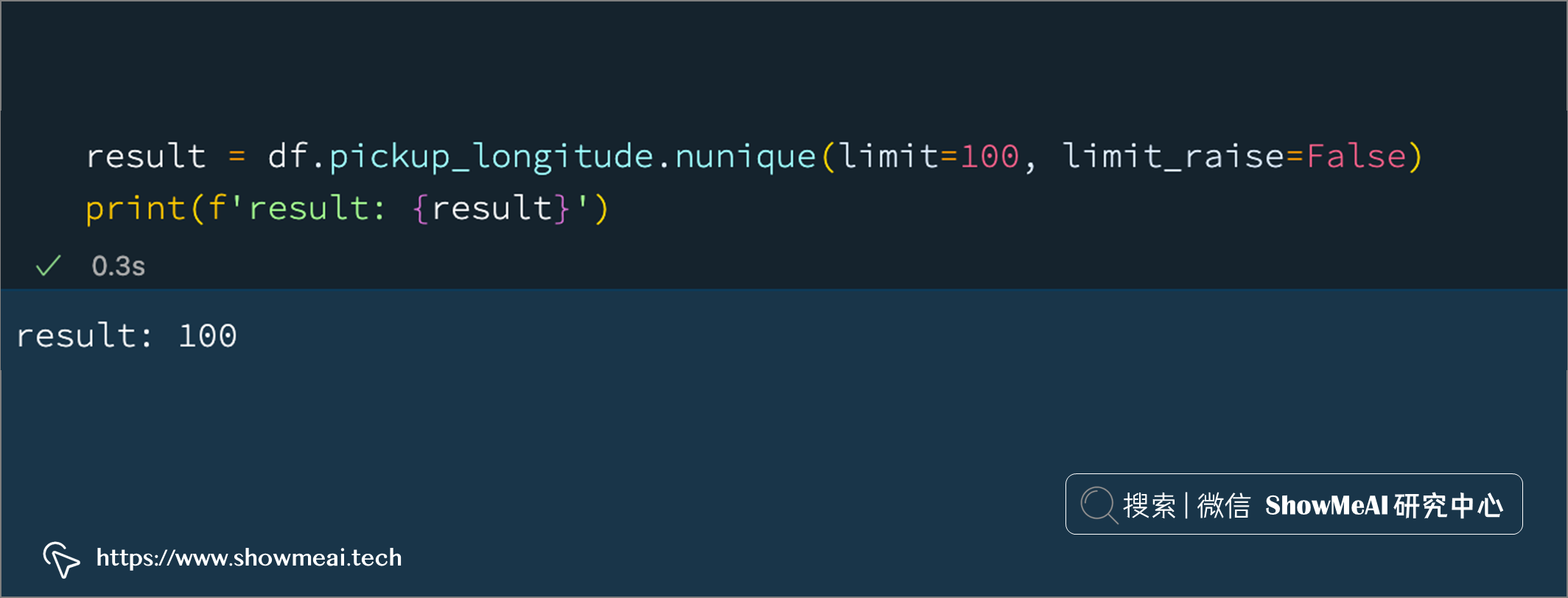
Vaex 有一种直接的方式来确定数据读取的规模,当我们在数据分析时使用 unique, nunique或者 groupby方法,在全量数据上可能会有非常大的时延,我们可以指定 limit参数,它会限制我们计算的范围,从而完成提速。
在下面的示例中,我们设置 limit到 100,它告诉 Vaex 在达到 100 时就计算并返回结果:
result = df.pickup_longitude.nunique(limit=100, limit_raise=False)
print(f'result: {result}')
随着数据集的增长,将它们存储在云中变得越来越普遍和实用,并且只将部分数据子集保留在本地。Vaex 对云非常友好——它可以轻松地从任何公共云存储下载(流式传输)数据。
并且 Vaex 只会获取需要的数据。例如,在执行 df.head() 时,只会获取前 5 行。要计算一列的平均值,只会获取该特定列的所有数据,Vaex 将流式传输该部分数据,因此并不会占用大量带宽和网络资源:
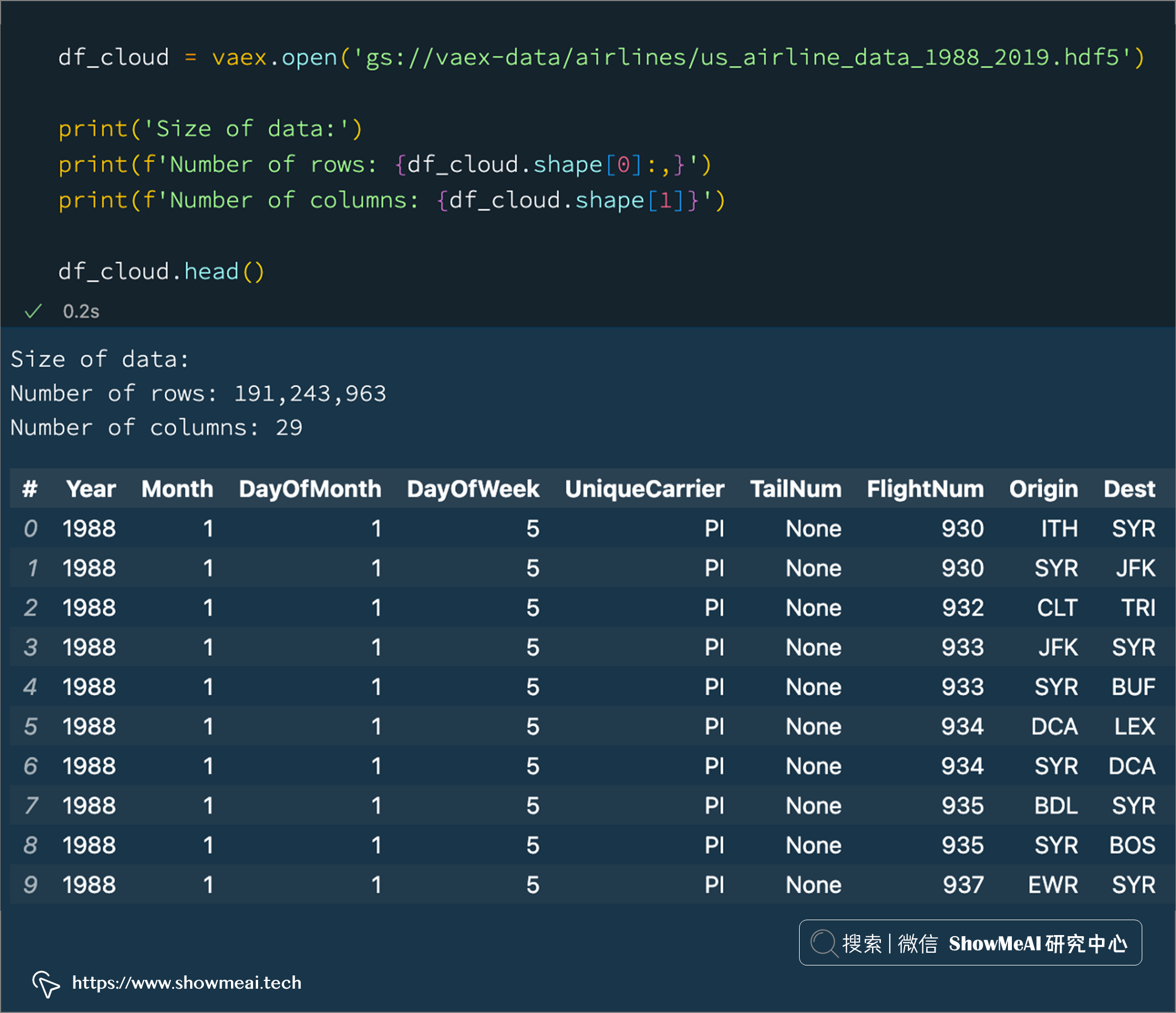
df_cloud = vaex.open('gs://vaex-data/airlines/us_airline_data_1988_2019.hdf5')
print('Size of data:')
print(f'Number of rows: {df_cloud.shape[0]:,}')
print(f'Number of columns: {df_cloud.shape[1]}')
df_cloud.head()
💦 8.GPU加速
最后,Vaex 还有非常强大功能,它可以使用 GPU 来加速,并且它支持的平台非常多:适用于 Windows 和 Linux 平台的 NVIDIA、适用于 Mac OS 的 Radeon 和 Apple Silicon。
下例中,我们定义了一个函数来计算球体上两点之间的弧距。这是一个相当复杂的数学运算,涉及大量的计算。我们使用先前的数据(数据集包含超过 10 亿行),尝试计算纽约出租车数据集中所有出租车行程的平均弧距:
print(f'Number of rows: {df.shape[0]:,}')
def arc_distance(theta_1, phi_1, theta_2, phi_2):
temp = (np.sin((theta_2-theta_1)/2*np.pi/180)**2
+ np.cos(theta_1*np.pi/180)*np.cos(theta_2*np.pi/180)
* np.sin((phi_2-phi_1)/2*np.pi/180)**2)
distance = 2 * np.arctan2(np.sqrt(temp), np.sqrt(1-temp))
return distance * 3958.8
df['arc_distance_miles_numpy'] = arc_distance(df.pickup_longitude, df.pickup_latitude,
df.dropoff_longitude, df.dropoff_latitude)
# Requires cupy and NVDIA GPU
df['arc_distance_miles_cuda'] = df['arc_distance_miles_numpy'].jit_cuda()
# Requires metal2 support on MacOS (Apple Silicon and Radeon GPU supported)
# df['arc_distance_miles_metal'] = df['arc_distance_miles_numpy'].jit_metal()
result_cpu = df.arc_distance_miles_numpy.mean(progress='widget')
result_gpu = df.arc_distance_miles_cuda.mean(progress='widget')
print(f'CPU: {result_cpu:.3f} miles')
print(f'GPU: {result_gpu:.3f} miles')
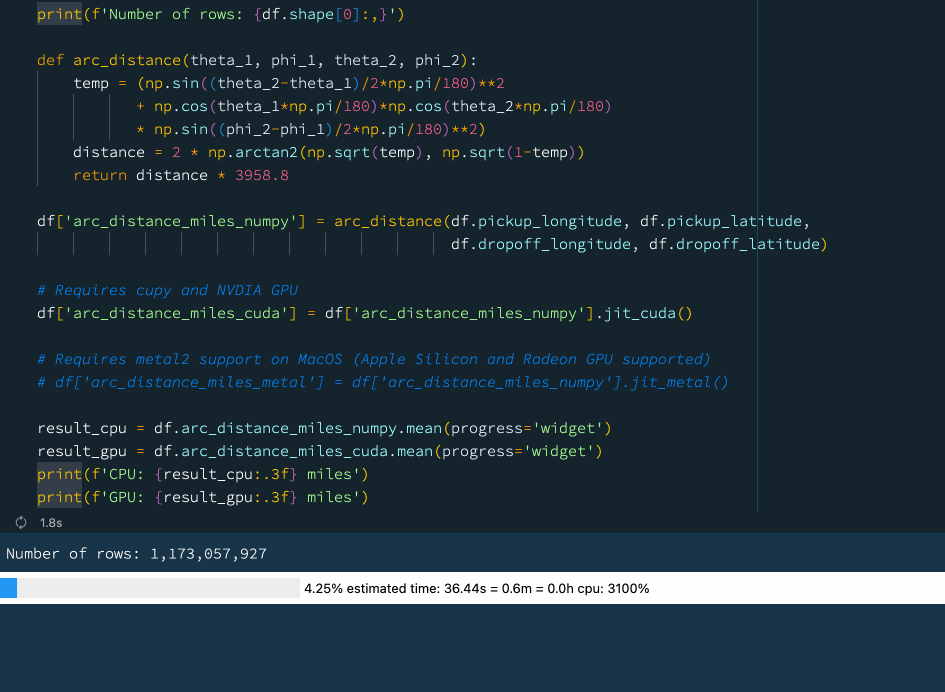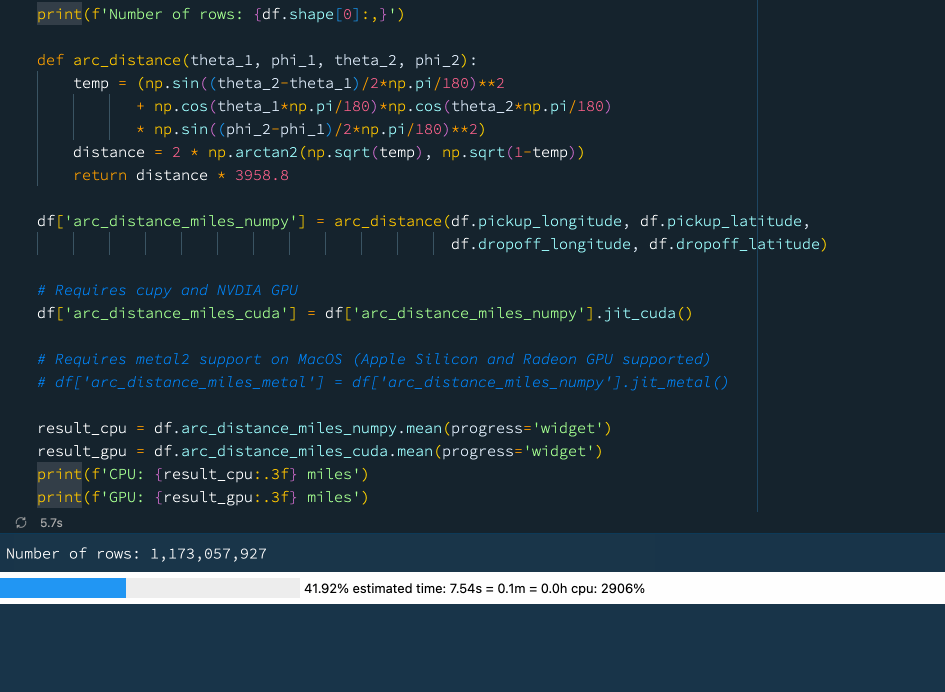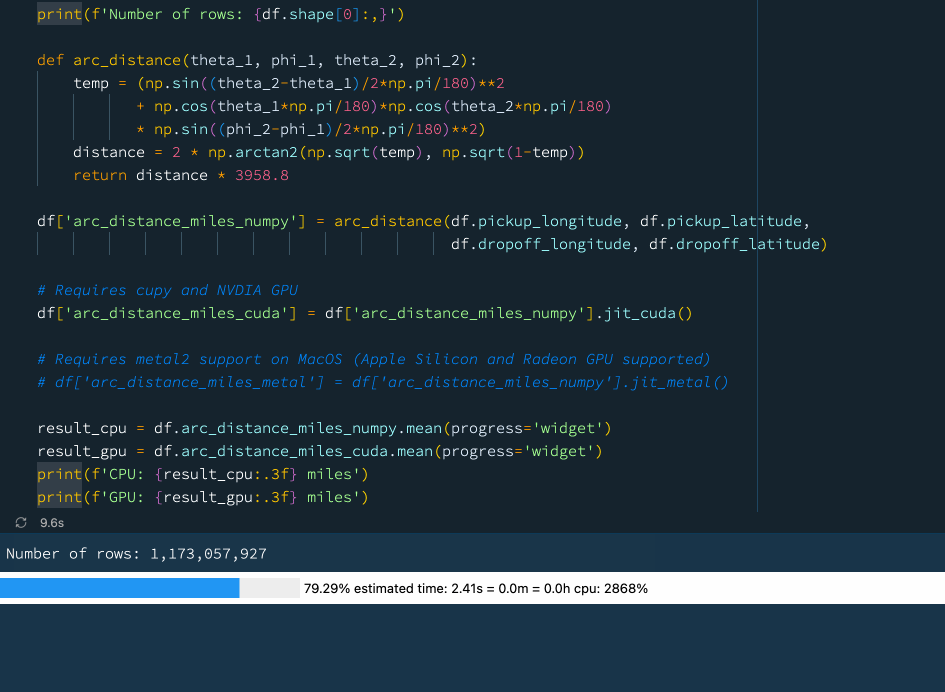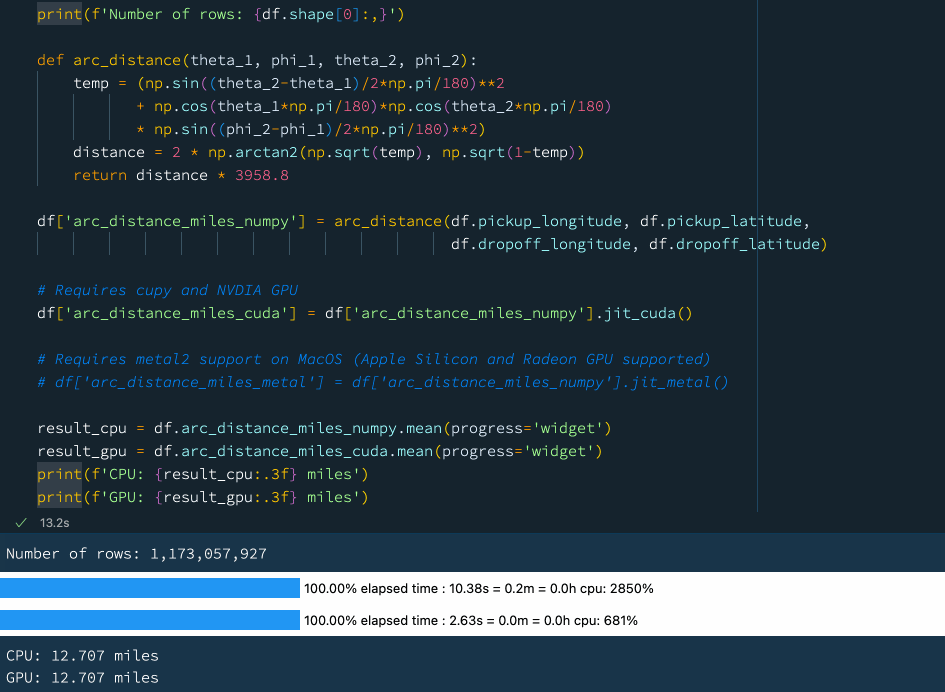
在上图中大家可以看到使用 GPU 可以获得相当不错的性能提升。如果我们没有GPU,也不用担心!Vaex 还支持通过 📘Numba和 📘Pythran 进行即时编译,这也可以显著提高性能。
参考资料
- 📘 Python数据分析实战教程:https://www.showmeai.tech/tutorials/40
- 📘 Vaex的GitHub页面:https://github.com/vaexio/vaex
- 📘 Apache Arrow:https://arrow.apache.org/
- 📘 本文使用的数据下载官网:https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- 📘 NYC Taxi 数据集的一个子集:https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- 📘 Vaex异步编程官方指南:https://vaex.io/docs/guides/async.html
- 📘 Vaex的先进的细粒度的缓存机制:https://vaex.io/docs/guides/caching.html
- 📘 Numba:https://numba.pydata.org/
- 📘 Pythran:https://pythran.readthedocs.io/en/latest/






![[CISCN2019 总决赛 Day2 Web1]Easyweb](https://img-blog.csdnimg.cn/b21f1bc85d8043f19509c1a11163f591.png)