- 预备知识:
- 说话人自适应技术是利用特定说话人数据对说话人无关(Speaker Independent,SI)的码本进行改造,其目的是得到说话人自适应(SPeaker Adapted, SA)的码本来提升识别性能。
- 在某个说话人的训练数据足够多的时候,针对当前说话人数据采用传统的训练方法可以得到×说话人相关(Speaker Dependent, SD)的码本,由于SD码本很好的反应了当前说话人的特征,因此效果往往更好,但实际中往往缺少足够的数据,因此采用说话人自适应,这样只需要很少量的数据就可以得到比较大的性能提升。其实质是利用自适应数据调整SI码本以符合当前说话人特性。
- 由于传统训练方法得到的 SI 码本不可避免地受训练集特性的影响, 在训练集和自适应数据失配时这会导致自适应效果变得不明显, 原始码本越具有说话人无关性, 在自适应时就越能迅速地趋近当前说话人的特征。与自适应相结合的码本训练对 SI 码本、训练集内每个说话人特性分别建立模型, 因此可以得到更具说话人无关性的 SI 码本。
- FMLLR:
- 针对特定的说话人,其码本可以用SI码本经过线性变换后的SA码本表示,即SA码本中的任意均值矢量可以表示为:x∗=Ax+b,其中x表示N维SI码本的均值矢量,A为N×N的线性变换矩阵,b表示偏移量,不同的均值矢量可以有不同的变换矩阵A。fMLLR码本自适应的目的就是估算变换矩阵A从而更新SA码本。
- 如何得到变换矩阵?
- 可以将其作为参数,使用参数估计的方法得到。
- 假设有K个说话人的训练数据,每个说话人的SA码本均由SI码本线性变换得到,训练的目标是使得输出概率函数最大,即:

- 式中λ表示SI码本的参数集合(均值和方差),Ak表示第k个说话人的变换矩阵,AK=[bk,Uk]。Ok表示第k个说话人的训练数据集合,W∗,λ∗表示参数的最佳估计。
- 从码本包含信息的角度分析, 语音信号总是包含两部分的内容: 说话人信息( 这里指广义的说话人信息, 也包括环境变化造成的特征的不确定性) 和语意信息, 这可以看作两个相对独立的坐标轴。在训练说话人无关码本时希望码本尽量只与语意相关, 传统的训练方法对所有数据作平均, 这实际隐含着训练集中说话人信息部分可相互抵消的假设; 而自适应训练的做法是: 对每个说话人分别估计说话人信息, 期望在此基础上能够真正得到说话人无关码本, 对两部分的估计是同时进行的, 对训练集的要求相对较低。
- 参数估计
- 参数估计的目标是更新码本的均值、方差和每个说话人的线性变换矩阵以使得输出概率最大,由于多个优化参数的存在,需要分别实现参数更新。
- 初始时给定SI码本,转换矩阵A为单位矩阵。
- 更新说话人变换矩阵,首先根据SI码本和当前说话人矩阵A得到SA码本,依照SA码本对每个说话人训练数据做Viterbi分割,分割的结果是将每一帧分别归到某一个高斯分布,然后按照分割结果更新每个人的变换矩阵。
- 更新SI码本均值。把已经更新的变换矩阵A带入目标函数求解SI码本均值。
- 更新SI码本方差。利用更新后的说话人变换矩阵A和SI码本均值带入目标函数可以求解SI码本的方差。
- 判断统计量是否收敛,若不收敛重复2-4步进行迭代。
fmllr--学习笔记
news2026/3/26 23:57:09
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/23532.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
m基于3GPP-LTE通信网络的认知家庭网络Cognitive-femtocell性能matlab仿真
目录
1.算法概述
2.仿真效果预览
3.MATLAB部分代码预览
4.完整MATLAB程序 1.算法概述
本系统所涉及到的几个主要模块,具体有如下几个模块:
A. Simulation Flow:仿真流程
B. Initialization:初始化
C. Mobility Model&…
【每日两题】day 01 组队竞赛 删除公共字符
链接:组队竞赛__牛客网 (nowcoder.com)
解题思路
该题目就是求所有队员水平的数组中的尽可能大的水平之和
因为每个队伍都是三个人,平均水平值肯定是排序后水平中间的值 import java.util.*;public class Main {public static void main(String[] ar…

VisualDrag低代码拖拽模板
目录背景技术&文档二开优化方案1. 优化侧边栏2. 优化图片插入3. 新增可插入画布的组件4. 解决组件鼠标默认事件冲突的问题数据保存对接&页面生成预览保存对接生成预览源码下载背景 接到一个需求做一个拖拽模板低代码生成界面(如上图),…

项目交付过程中,进度失控的原因有哪些?
在项目交付过程中,会出现项目交付的进度与计划有较大的偏差,导致这种偏差的原因往往是多种多样的,一般常见的引起进度延期的原因有哪些?
1、计划不清晰
项目开始前必须有个计划,工作思路必须事前理清。
项目经理最…
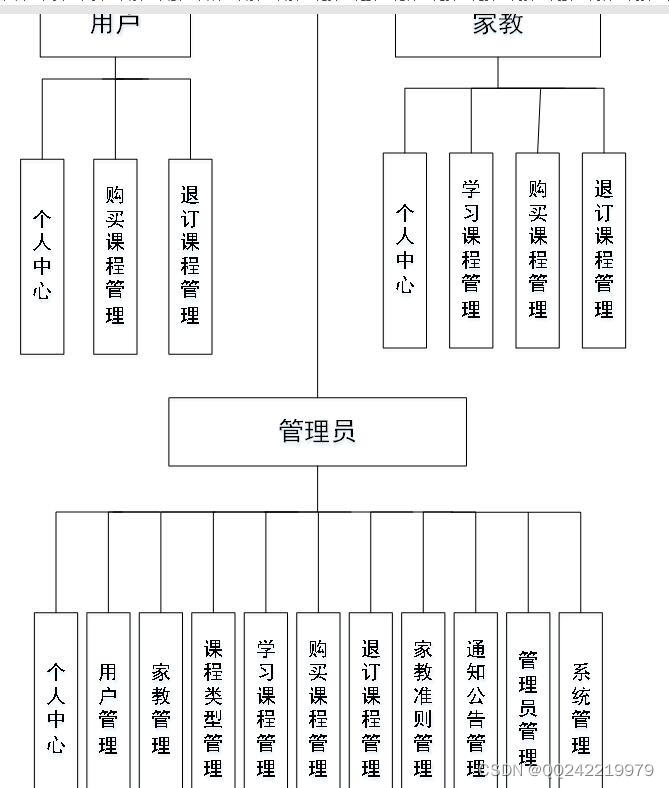
springboot+ssm大学生家教课程订购平台的设计与实现
制作一个大学生家教平台的设计与实现是非常必要的。本网站是借鉴其他人的开发基础上,用MySQL数据库和JSP定制了大学生家教平台的设计与实现。系统前台实现了用户注册、登录、学习课程、家教准则、通知公告、双减政策等功能,并且还可以修改密码、个人信息…
windows10复制文件需要管理员权限,复制需要管理员权限怎么办
在Windows10操作系统的电脑中,很多用户都遇到这样的问题:windows10复制文件需要管理员权限,很多用户都不知道该怎么解决这个问题。在本文中,我们写出了详细的解决方法,让你可以轻松复制文件,并且也修复了需…
SpringBoot中任务是什么/Quartz和SpringTask在Spring Boot中怎么使用/SpringBoot怎么给用户发邮件
写在前面: 继续记录自己的SpringBoot学习之旅,这次是SpringBoot应用相关知识学习记录。若看不懂则建议先看前几篇博客,详细代码可在我的Gitee仓库SpringBoot克隆下载学习使用!
3.5.2 任务
3.5.2.1 简述
定时任务是企业应用中常…

多种BCN点击试剂:1426827-79-3,endo BCN-PEG4-COOH,1841134-72-2
双环[6,1,0]壬炔 (BCN) (环丙烷环辛炔)可以通过无铜的点击化学与叠氮化物标记的分子或生物分子反应生成稳定的三氮唑连接。同样其可以和多种不同的基团进行连接,包括acid,NHS ester,amine等。西安凯新生物科技有限公司…
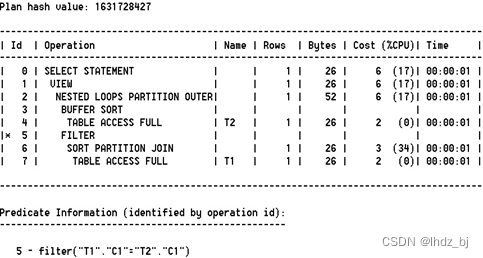
Oracle SQL执行计划操作(7)——排序相关操作
7. 排序相关操作
该类操作和SQL语句执行计划中的排序操作相关。根据不同的具体SQL语句及其他相关因素,如下各操作可能会出现于相关SQL语句的执行计划。
1)BUFFER SORT
在会话服务进程内存中对某个行源数据进行排序或其他相关操作,该操作最…

Vue高级篇--实现前后端分离
目录 一、安装Nodejs服务器 二、安装Npm 三、安装vue脚手架 四、使用vue脚手架搭建vue工程 五、vue工程安装需要的插件和依赖 六、安装前端的开发工具 七、使用webstorm打开vue工程 7.1 运行vue工程 八、src目录结构的介绍 一、安装Nodejs服务器 等价于我们java端的Tomcat服务…

聊聊自制的探索大全扑克牌
这是鼎叔的第四十篇原创文章。
行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注本人专栏和微信公众号《敏捷测试转型》,大量原创思考文章陆续推出。
这是鼎叔的第四十篇原创文章。
行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注…
Oracle中ALTER TABLE的五种用法(一)
首发微信公众号:SQL数据库运维 原文链接:https://mp.weixin.qq.com/s?__bizMzI1NTQyNzg3MQ&mid2247485212&idx1&sn450e9e94fa709b5eeff0de371c62072b&chksmea37536cdd40da7a94e165ce4b4c6e70fb1360d51bed4b3566eee438b587fa231315d0a5a…
(必经点)局部优化达到全局最优的最短路径算法探讨
首先,存在无序的点集.
记.
再记初始路径为.
于是,我们称以下为一次变换:
if |C[i]-C[i1]||C[i2]-C[i3]| > |C[i]-C[i2]||C[i1]-C[i3]|
{swap(C[i1],C[i2]);
} 需要注意的是.
最直观的就是如下的变换: 我们对C上的每一点&a…
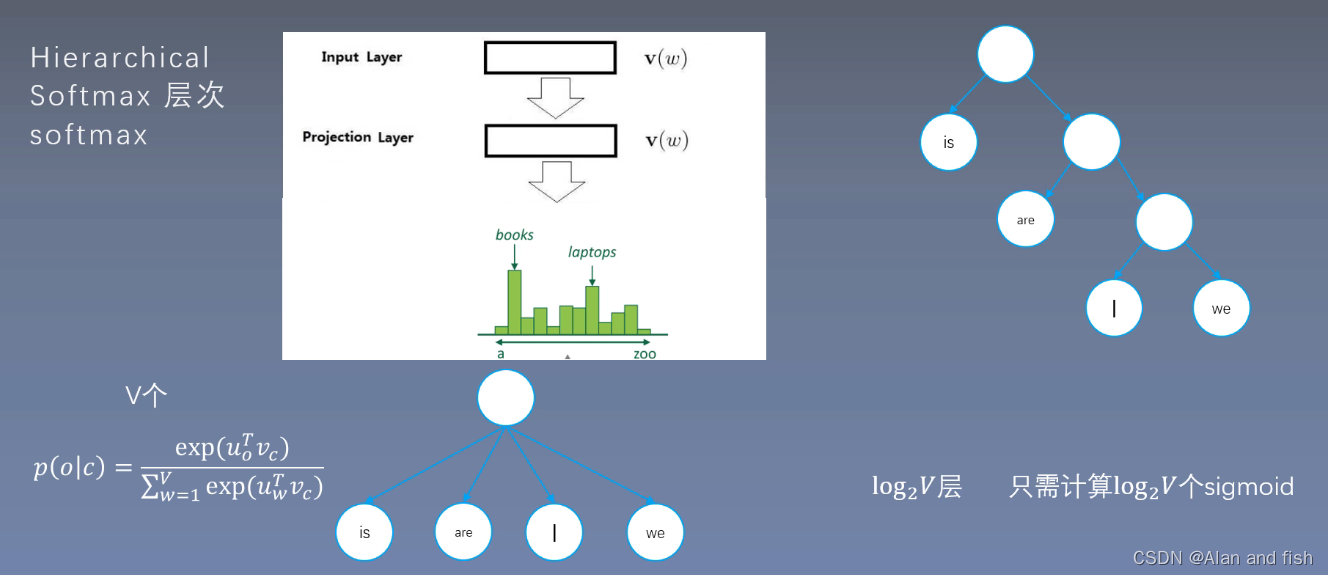
论文阅读【3】Efficient Estimation of Word Representations in Vector Space
1.概述
1.1 论文相关
题目:基向量空间中词表示的有效估计(Efficient Estimation of Word Representations in Vector Space)发表时间:出版:原文地址:代码
1.2 动机
2.对比模型
2.1 NNLM(前…

表单控件绑定:checkbox表单绑定v-model
表单checkbox,绑定的v-model是一个布尔值,要么为true,要么为false;因为它是勾选,或者不勾选的形式;为true了就是勾选,为false了就是不勾选;
代码:
<body><div …
Vue-cli3 通过配置 public 目录下的 config.js 和config.json 实现一次编译,修改生效
文章目录1.背景2.配置步骤3.小结1.背景
最近实施部门,有个需求就是研发人员通过vue 写完代码,yarn build 编译完成代码后,移交实施,通过修改public 文件夹下的 config 文件来实现修改,请求后台的 requestUrl 和 titil…

day10 分布式缓存
单机的 Redis 存在以下四大问题: 1、Redis持久化 Redis有两种持久化方案: RDB 持久化AOF 持久化
1.1、RDB 持久化
RDB 全称 Redis Database Backup file(Redis数据备份文件),也被叫做 Redis 数据快照。简单来说就是把…

《500强高管谈VE》-面向STAKEHOLDERS东方企业的VM
文章出处:日本VE协会杂志文章翻译:泰泽项目部
关注泰泽:实现高利润企业
《500强高管谈VE》-面向STAKEHOLDERS东方企业的VM
作者:常务董事八木隆 本公司的日高工厂和丰浦工厂两个事业所获得了迈尔斯奖。这些都是支持企业活动的V…

无代码开发平台选型指南
一、如何选购SaaS
SaaS评测网的面世,也原因在于有感于选型难于,期望可以提供更多有用的信息协助大家找出更可信赖与最合适的产品。简而言之授之以鱼、比不上授之以渔,接下来的系列产品该文,则是撷取选型的方法及避坑实战经验。
…

【大数据处理技术】第二篇 大数据存储与管理(持续更新)
文章目录第3章 分布式文件系统HDFS3.1 分布式文件系统3.1.1 计算机集群结构3.1.2 分布式文件系统的结构3.1.3 分布式文件系统的设计需求3.2 HDFS3.2.1 HDFS 简介及相关概念3.2.2 HDFS 体系结构3.2.3 HDFS 存储原理3.2.4 HDFS 数据读写过程3.2.5 HDFS 编程实践第4章 分布式数据库…