1.概述
1.1 论文相关
- 题目:基向量空间中词表示的有效估计(Efficient Estimation of Word Representations in Vector Space)
- 发表时间:
- 出版:
- 原文地址:
- 代码
1.2 动机
2.对比模型
2.1 NNLM(前馈神经网络语言模型)
这是Bingio在2003年发表的一篇论文 A neural probabilistic language model

概述:首先将的文本转换成字典中对应的数字,然后将数字转换成向量,然后concat,也就是合并,比每个词语对应的是100维的向量,则concat之后就是一个200维的向量。则如图中有n-1个词向量,则concat之后就是100(n-1)维,然后其输入到一个全连接层中,并且使用tanh作为激活函数,然后再接一个全连接层,使用softmax作为激活函数。
输入层:将词映射成向量,相当于一个1xV的one-hot向量乘以一个VxD的向量得到一个1xD的向量。如下图所示是一个15的矩阵与一个53的矩阵相乘,最后得到了一个1*3的矩阵。
隐藏层:一个以tanh为激活函数的全连接层
a=tanh(d+Ux),其中d是偏置,U是相当于一个权重参数
输出层:一个全连接层,后面接了一个softmax函数来生成概率分布。y=b+wa,其中y是一个1*V的向量:
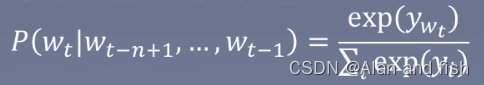
语言模型困惑度和Loss的关系:

T表示句子中词的个数,使用log是因为概率相乘计算的长度比较大,使用log之后就全部变成了加法了,然后概率都是小于1的数,加了log就是负数,所以需要加一个负号,负负得正,loss越小越好,这也就是交叉熵损失函数。通过推导,最后得到困惑度其实就是
e
L
e^L
eL,所以不用特意去求困惑度,只要求出损失就能求得困惑度。
回顾一下,就能发现问题:

- 1.仅对一部分输出进行梯度传播,比如 the a and 这些都是停用词,用处不是很大。
- 2.引入先验知识,如词性等,如果吧每个单词是名词还是形容词的词性输入进去是否准确度会更高一点呢。在加词性之前就要考虑到几个问题,第一网络是否能够学习到词性的信息,答案是可以,但是能学习到的词性够不够用?
- 3.解决一词多义问题。
- 4.加速softmax层。
2.2 RNNLM(循环神经网络语言模型)

输入层:和NNLM一样,需要将当前时间步的转化为词向量。
隐藏层:对输入和上一个时间步的隐藏输出进行全连接层操作:

输出层:一个全连接层,后面接一个softmax函数来生成概率分布
y(t)= b + Vs(t)
其中y是一个1*V的向量:

3.word2vec模型
3.1 log线性模型
定义(Log Linear Models) :将 语言模型的建立看成个多分类问题,相当于线性分类器加上softmax。
Y= softmax(wx + b)
3.2 word2vec的原理
语言模型基本思想:句子中下一个词的出现和前面的词是有关系的,所以可以使用前面的词预测下一个词。
Word2vec基本思想:句子中相近的词之间是有联系的,比如今天后面经常出现上午,下午和晚 上。所以Word2vec的基本思想就是用词来预测词。
skip - gram:使用中心词预测周围词。比如下面这个句子,我今天下午打羽毛球,设置一个Window=2,就是用这个中心词预测他前后的2个词,分别用
w
i
w_i
wi来预测我,今天,打,羽毛球。
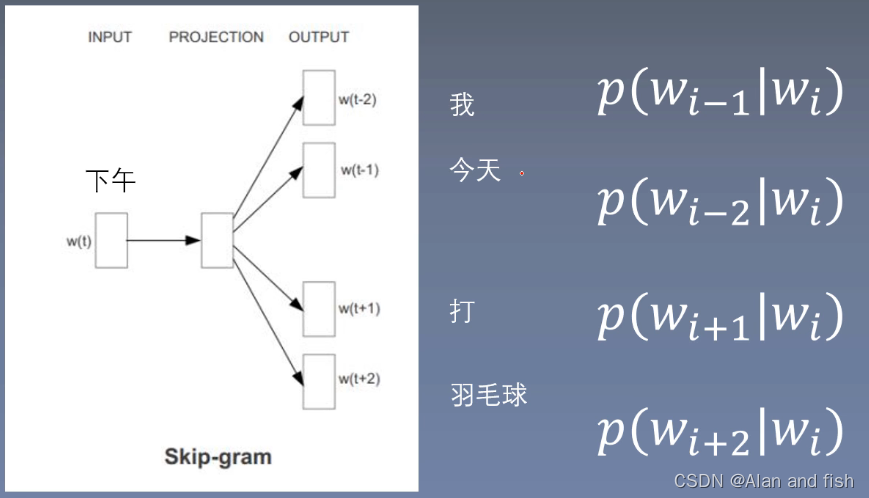
模型预算过程:
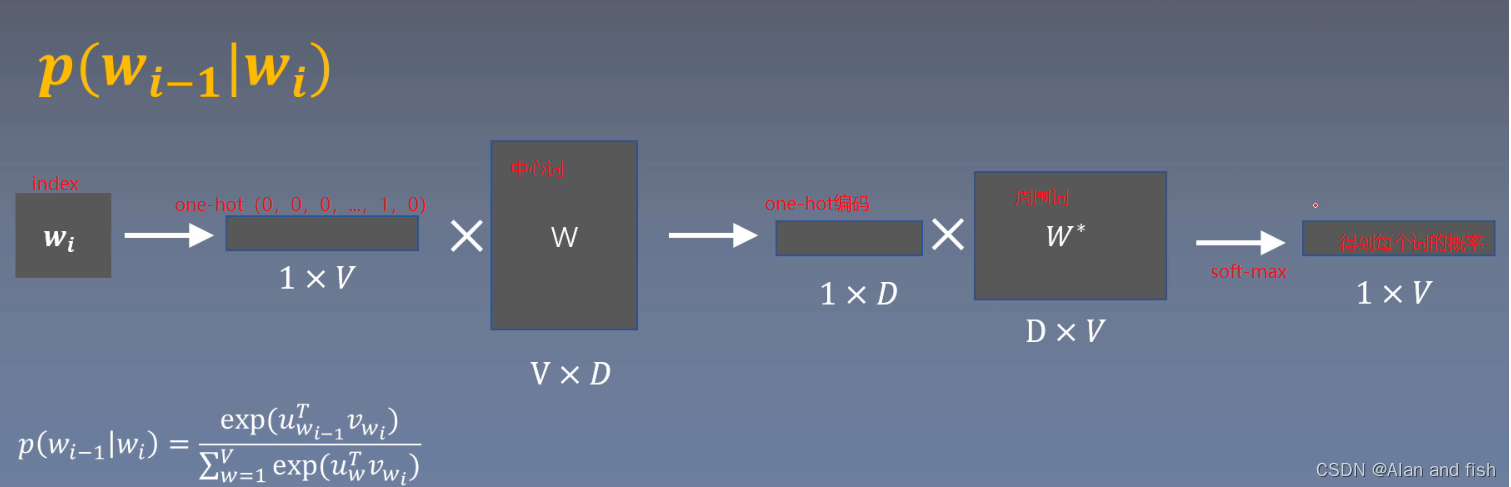
可以理解将所有周围词都放进一个袋子里,随手一抓,抓到这个周围词的概率。下面是计算损失函数:

cbow:使用周围词预测中心词
cbow也称为词袋模型bag-of-word,因为求和的时候忽略了每个词的顺序。

原理过程
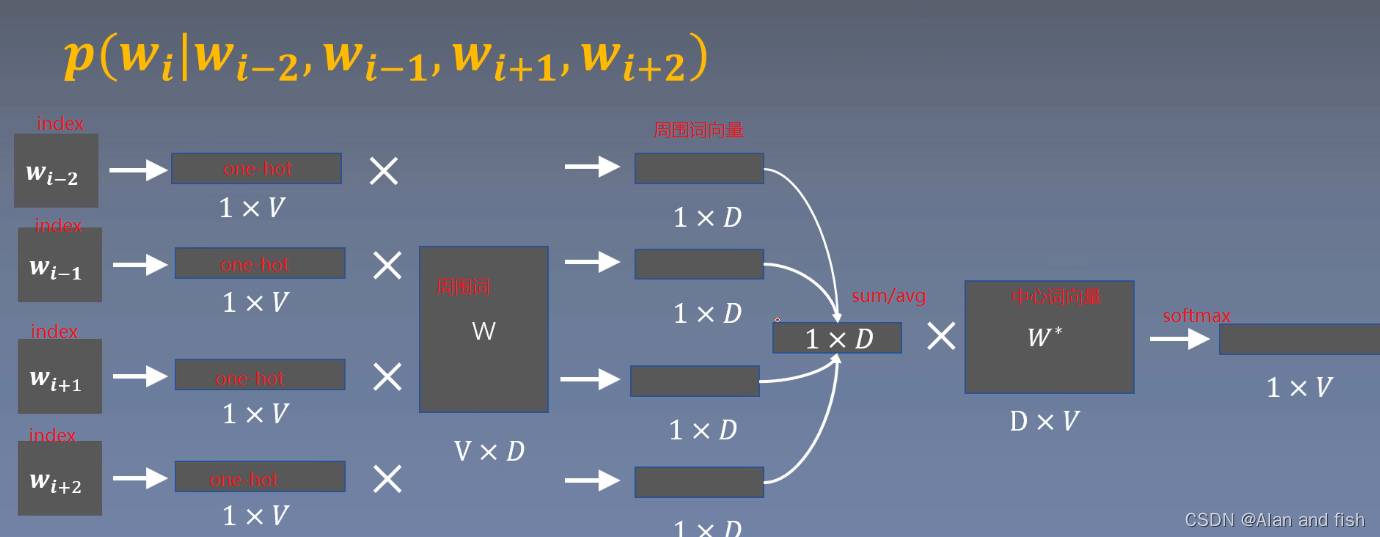
下面是计算损失函数:

复杂度讨论:

因为复杂度比较高,所以采用了2重方法降低复杂度,分别是层次softmax和负采样技术。
3.3 层次softmax(Hierachical)
如下图,要同时求四个词的softmax转换成求每个词的sigmoid,于是将其构造一个二叉树,小于0.5的在左边,大于0.5的在右边。softmax需要求V次指数操作,而每个softmax的分母就是每个词得Sigmoid的相加,因为降低了sifmoid的次数,就是降低了softmax的复杂度,只需要计算
l
o
g
2
V
log_2^V
log2V个。
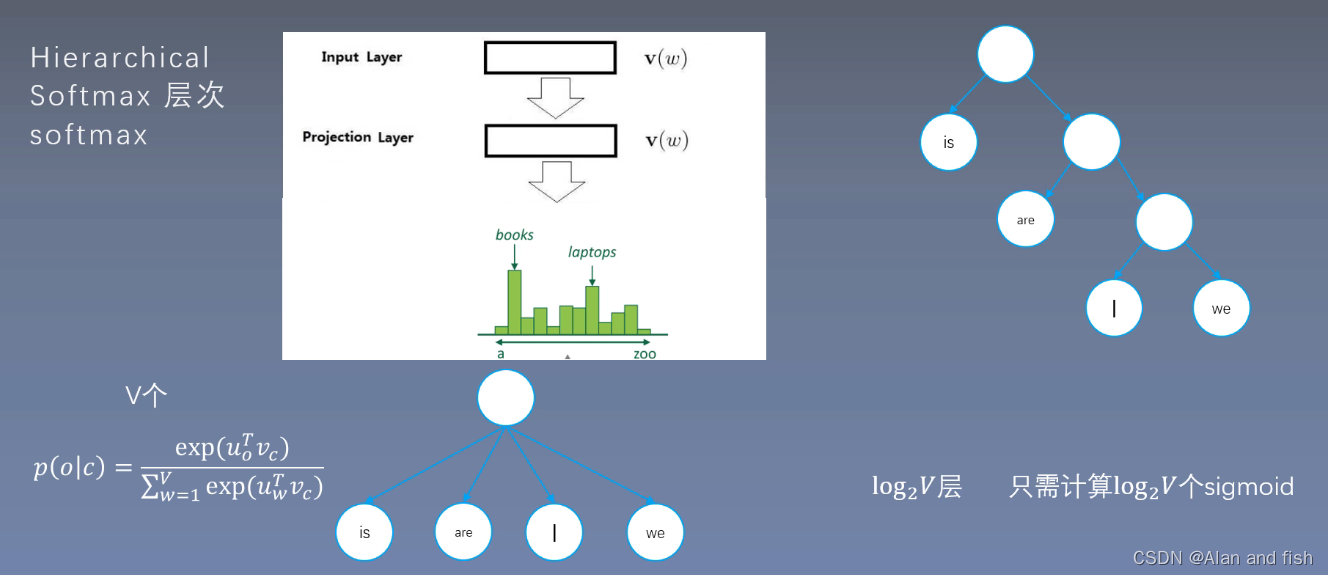
究竟为什么是
l
o
g
2
V
log_2^V
log2V个,看下面的解释:
3.4 负采样技术
4.实验及结果
5.总结
后面有空再继续完善