环境:
-
ubuntu 20.04
-
python 3.8
-
tensorflow-gpu 2.4.0
-
显卡 nvidia rtx A6000 驱动 495.29.05
-
cuda 11.5
-
cudnn 8.3.0
-
tensorRT 8.4
1.将keras保存的h5模型转成darknet的weight,然后用opencv加载
cv::dnn::Net net = cv::dnn::readNetFromDarknet("load_model.weight");
卷积网络和全连接可以加载成功,lstm网络不支持,opencv源码中没有lstm网络:

2.将keras模型转成onnx,两种方式,keras2onnx和tensorflow2onnx:
- keras-onnx
keras-onnx已经停止维护了
keras2onnx has been tested on Python 3.5 - 3.8, with tensorflow 1.x/2.0 - 2.2 (CI build). It does not support Python 2.x.
import keras2onnx
import onnx
import tensorflow as tf
from tensorflow.keras.models import load_model
if "__main__" == __name__:
model = load_model('./model.h5')
model.summary()
onnx_model = keras2onnx.convert_keras(model, model.name)
temp_model_file = 'model.onnx'
onnx.save_model(onnx_model, temp_model_file)
- tensorflow-onnx

- 安装
pip install -U tf2onnx
import tensorflow as tf
from tensorflow.keras.models import load_model
if "__main__" == __name__:
model = load_model('./model.h5')
tf.saved_model.save(model, './model')
# python -m tf2onnx.convert --saved-model ./model/ --output model.onnx
先load预训练的h5模型,用tf.saved_model.save转化成pb格式,再执行
python -m tf2onnx.convert --saved-model ./model/ --output model.onnx
转成onnx格式
可以在https://netron.app/查看你的模型架构:

3.将onnx转成tensorRT的格式:

- 在https://developer.nvidia.com/nvidia-tensorrt-8x-download下载并安装8.4版本:
sudo dpkg -i nv-tensorrt-repo-ubuntu2004-cuda11.6-trt8.4.0.6-ea-20220212_1-1_amd64.deb
sudo apt-key add /var/nv-tensorrt-repo-ubuntu2004-cuda11.6-trt8.4.0.6-ea-20220212/7fa2af80.pub
sudo apt-get update
sudo apt-get install tensorrt
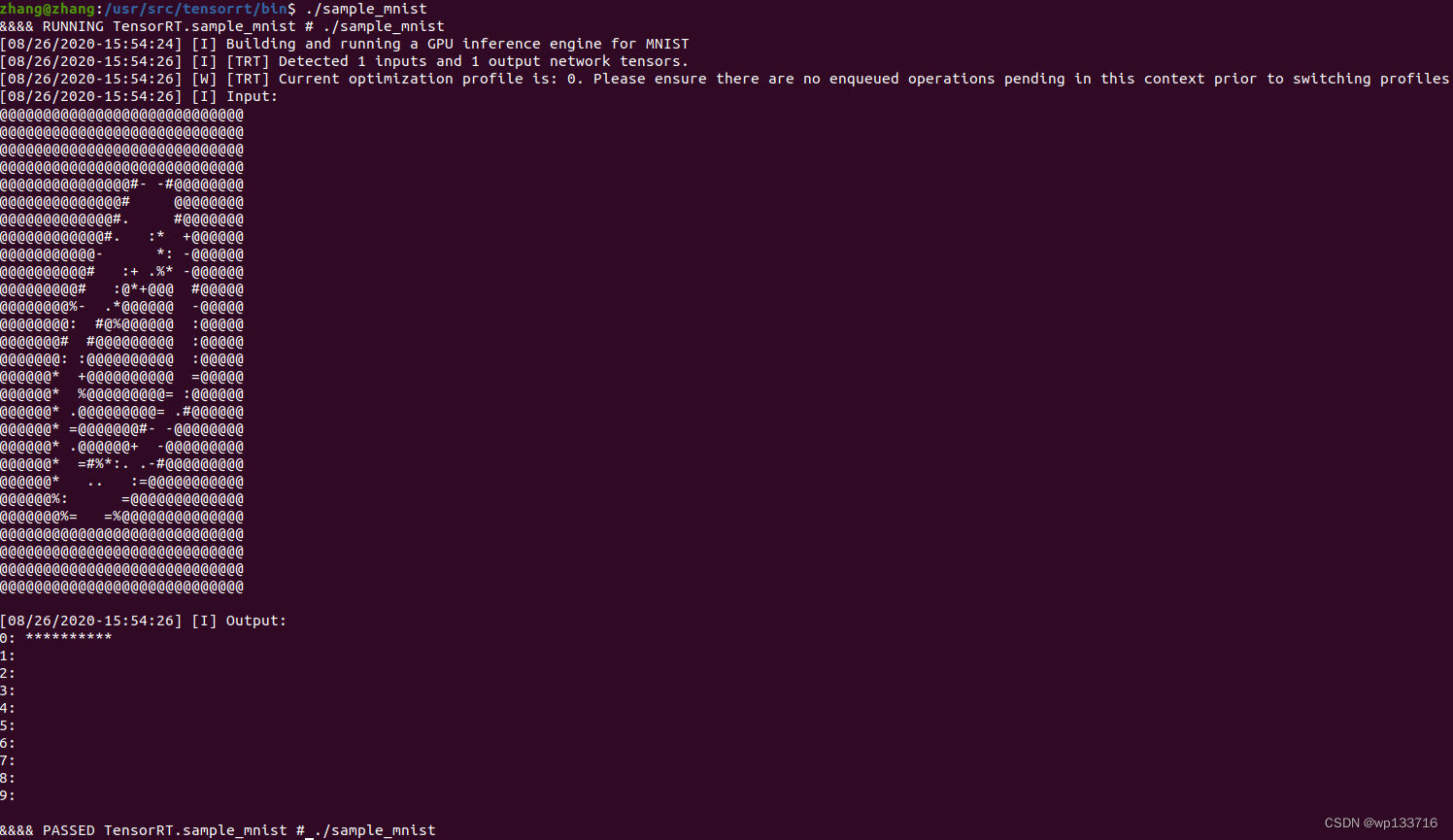
- 测试tensorrt是否安装成功
准备MNIST的.PGM图像,将10张0~9的命名为0.PGM,1.PGM…的
MNIST图像拷贝至data/mnist文件夹
sudo cp *.pgm /usr/src/tensorrt/data/mnist
cd /usr/src/tensorrt/samples/sampleMNIST
sudo make
cd ../../bin/
./sample_mnist
- 查看tensorrt版本
dpkg -l | grep TensorRT
- 安装tensorRT如果报错
- libdvd-pkg:
apt-get checkfailed, you may have broken packages. Aborting… sudo dpkg-reconfigure libdvd-pkg- 参考https://blog.csdn.net/qq_22945165/article/details/87653208
- libdvd-pkg:
将tensorRT加入环境变量
export PATH=$PATH:/usr/src/tensorrt/bin
trtexec --onnx=model.onnx --saveEngine=model.trt
- 也可参考https://github.com/onnx/onnx-tensorrt这种方式
onnx2trt my_model.onnx -o my_engine.trt
4.模型加载
参考https://github.com/shouxieai/tensorRT_Pro/
static void test_load_onnx(){
/** 加载编译好的引擎 **/
auto infer = TRT::load_infer("./model.trt");
if(infer == nullptr){
INFOE("Engine is nullptr");
return;
}
/** 设置输入的值 **/
infer->input(0)->set_to(1.0f);
/** 引擎进行推理 **/
infer->forward();
/** 取出引擎的输出并打印 **/
auto out = infer->output(0);
INFO("out.shape = %s", out->shape_string());
for(int i = 0; i < out->channel(); ++i)
INFO("%f", out->at<float>(0, i));
}
static void test_load_onnx(){
/** 加载编译好的引擎 **/
auto infer = TRT::load_infer("/home/user/my_python_test/net_float16/float32-model-2400/actor_model_32.trt");
if(infer == nullptr){
INFOE("Engine is nullptr");
return;
}
infer->print();
double timeAll = 0;
int inferTimes = 1000;
for(int i = 0; i < inferTimes; i++){
/** 设置输入的值 **/
// infer->input(0)->set_to(1.0f);
std::vector<float> input_ = {0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
2., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
3., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
4., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
5., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
6., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
7., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
8., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
9., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.};
memcpy(infer->input(0)->cpu<float>(), input_.data(), sizeof(float) * input_.size());
std::cout<<"############### input.data(): "<<input_.data()<<std::endl;
std::cout<<"############### input.size(): "<<input_.size()<<std::endl;
std::cout<<"############### infer->input(0): "<<infer->input(0)<<std::endl;
std::cout<<"############### infer->input(0)->count(): "<<infer->input(0)->count()<<std::endl;
std::cout<<"############### infer->input(0)->cpu<float>(0): "<<infer->input(0)->cpu<float>()<<std::endl;
std::cout<<"############### infer->input(0)->at<float>(): "<<infer->input(0)->at<float>(0, 3)<<std::endl;
clock_t start = clock();
/** 引擎进行推理 **/
infer->forward();
clock_t end = clock();
/** 取出引擎的输出并打印 **/
auto out_0 = infer->output(0);
auto out_1 = infer->output(1);
auto out_2 = infer->output(2);
auto out_3 = infer->output(3);
INFO("out_0.shape = %s", out_0->shape_string());
for(int i = 0; i < out_0->channel(); ++i)
INFO("%f", out_0->at<float>(0, i));
INFO("out_1.shape = %s", out_1->shape_string());
for(int i = 0; i < out_1->channel(); ++i)
INFO("%f", out_1->at<float>(0, i));
INFO("out_2.shape = %s", out_2->shape_string());
for(int i = 0; i < out_2->channel(); ++i)
INFO("%f", out_2->at<float>(0, i));
INFO("out_3.shape = %s", out_3->shape_string());
for(int i = 0; i < out_3->channel(); ++i)
INFO("%f", out_3->at<float>(0, i));
double spend_time = (double)(end - start)/CLOCKS_PER_SEC*1000;
std::cout << "############## Total inference time is " << spend_time << "ms" << std::endl;
if(i>0)
timeAll += spend_time;
}
std::cout << "############## average inference time is " << timeAll/inferTimes << "ms" << std::endl;
}