今天非常荣幸有机会在Speechhome语音技术研讨会上分享我们团队在开源项目上的一些工作。今天我分享的主题是声纹识别开源工具ASV-Subtools。
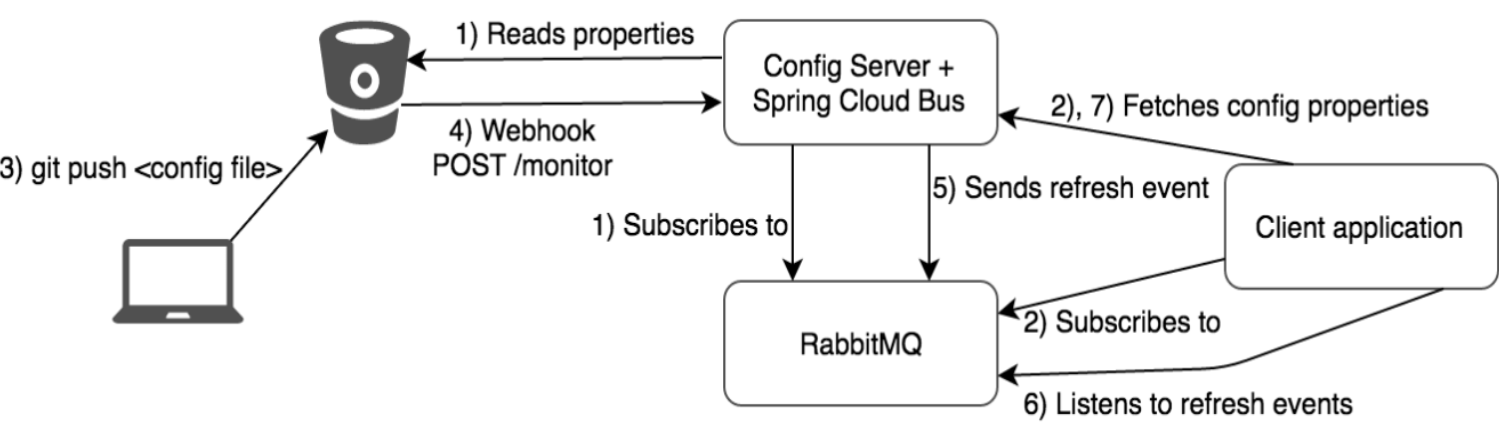
今天我分享的主要有5个部分的内容,分别是背景介绍、工具介绍、实验结果、Subtools工程化、总结与展望。其中Subtools工程化是我这次报告的一个重点,近期我们开源了Subtools工程化的,该模块可以快速的将PyTorch训练的模型进行C++的调用,快速的部署在工业环境中。

01背景介绍
我先简要介绍一下声纹识别的基本内容。声纹是指人的语音中所蕴含的能够表证说话人身份的一种生物特征,与指纹、人脸、虹膜等相比,声纹具有非接触获取、采集成本低、便于远程认证的优点。而声纹识别也就是一种利用说话人的声音去判定说话人身份的技术。
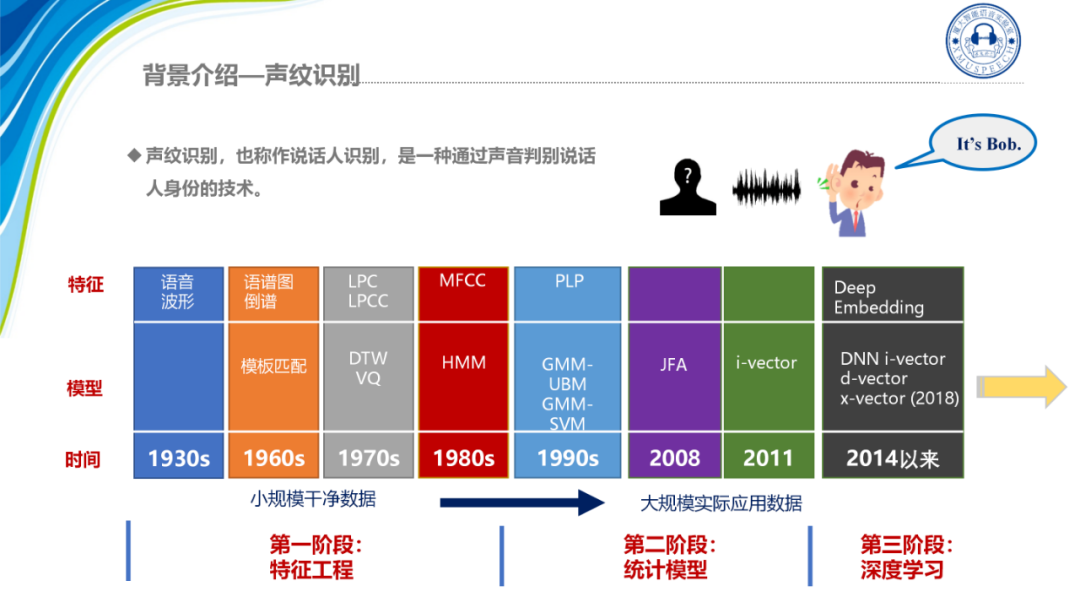
随着技术的发展,声纹识别也从最初的一个特征工程转向概率统计模型去表征说话人的身份,14年谷歌团队提出d-vector,他的核心思想是在训练时用说话人的身份,作为训练语音每一帧的标签对神经网络进行训练,将声纹识别从传统的方法——参数估计方法转为一个分类问题。这种完全基于神经网络的框架,标志着声纹识别进入了深度表征学习的阶段,但d-vector对帧级别信息进行建模。2017年Dan Povey等人对其做出了一个重大的改进,提出在神经网络中通过池化层将帧级别特征融合成段级别特征再对其进行分类,即x-vector框架。x-vector的框架可以从不等长的整句语音中提取出固定维度的Embedding。在大数据的情况下,更能利用神经网络强大的表征能力来提升模型的性能。因此成为了当下最为流行的声纹识别框架。
声纹识别的系统框架如图所示:
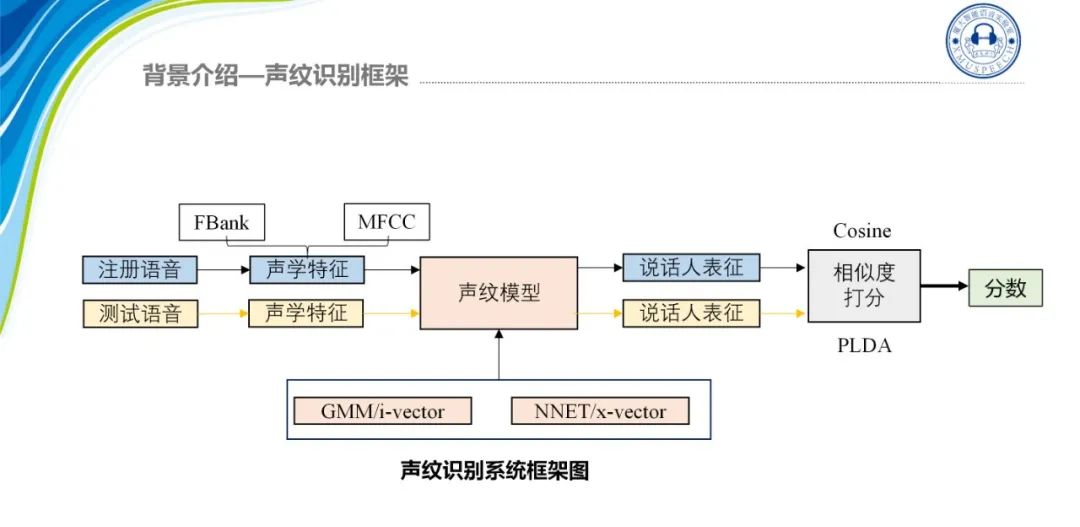
对于注册语音和测试语音来说,首先需要的就是声纹特征的提取,这里常用的特征一般为FBank和MFCC,我们将特征送入声纹模型就可以得到相应的说话人表征,然后进行相似度打分,这里我们可以采用Cosine打分,也可以用PLDA得到相似度的分数,分数越高就代表两个说话人越有可能是同一个人。在实际应用时我们可以设定一个阈值,只要两条语音的分数超过这个阈值就可以判断为两段语音来自同一个人。
随着声纹技术的发展工业界的应用也在不断的增多,例如语音交互中的用户身份判定、公安行政领域的声纹检索以及客服行业的用户身份判定等。
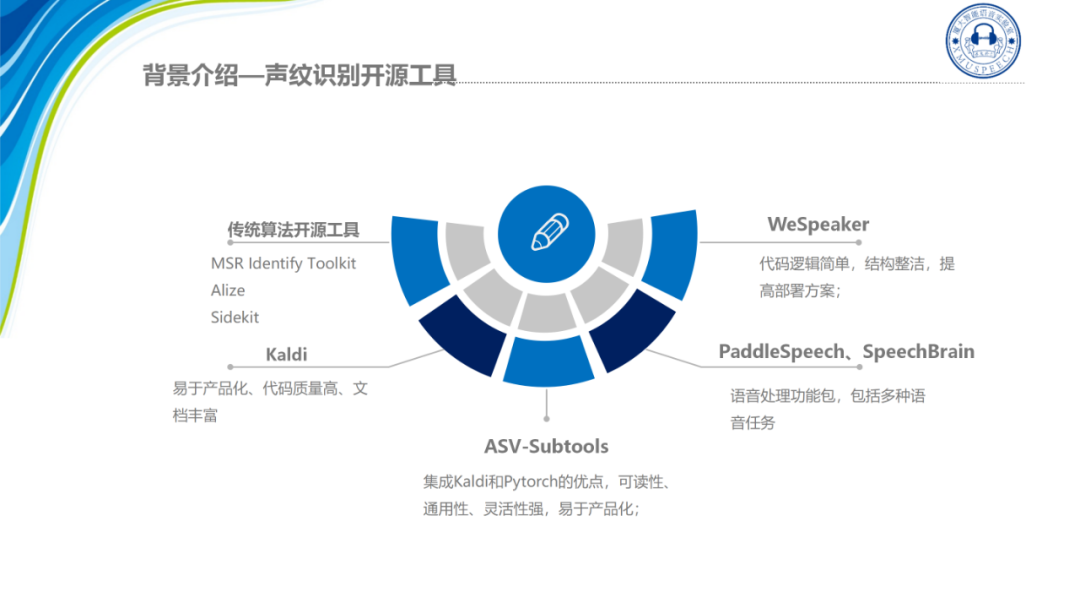
而在声纹识别的发展过程中,其实也涌现出了很多的开源工具,例如在传统的算法开源阶段有微软开源的MSR Identify Toolkit,它是一个Matlab工具箱,包括了GMM-UBM以及i-vector的一个demo。简单应用也有 C++版本的Allize和Python版本的Sidekit,它们都只包含了传统算法GMM-UBM、i-vector等方法。
而我们熟知的Kaldi也包含了i-vector、x-vector等模型。Kaldi整体的代码质量高,易于产品化也有丰富的文档,但它的代码耦合度相对来说较高,想要实现一个新的算法改动起来会比较麻烦。
Python版本呢,比如说PaddleSpeech、SpeechBrain等都是语音处理的功能包,包含了语音信号处理、语音识别、声纹识别、语音合成等语音任务,声纹识别只是他们开源框架的一个小点,而最新开源的WeSpeaker是专门做声纹识别的,在结构、代码上都很简洁,性能也很优异,这也是值得我们Subtools去学习的一个点。
Subtools是厦门大学智能语音实验室在2020年5月发布的一个开源工具,当时开发这个工具的目的是希望能够提升声纹识别研究的效率,因为在19年之前不管是用Kaldi还是用其他的一些不完整的开源代码去复现一些别的论文架构或者实现一些新的想法都是比较麻烦的,所以我们当时是集成了Kaldi和PyTorch各自的优点设计了这个全新的声纹识别开源工具。
02 工具介绍
接下来我介绍一下声纹识别工具ASV-Subtools。ASV-Subtools的设计理念在于代码高度复用的同时保持模块分化和开发自由的特性,因此也体现出四个特点:高效性、可读性、通用性、灵活性。
-
首先是高效性,它集成了Kaldi和PyTorch各自的优点,可以完整的实现深度声纹识别框架;
-
其次是可读性,我们提供了大量的注释说明和教程文档方便用户轻松的上手;
-
然后是通用性,我们将核心模块都分离出来,用户可以自由的扩展到新的模型;
-
最后是灵活性,用户只需要简单的配置和编辑文件就可以探索不同的网络结构、损失函数以及其他组件,实现最优异的性能。
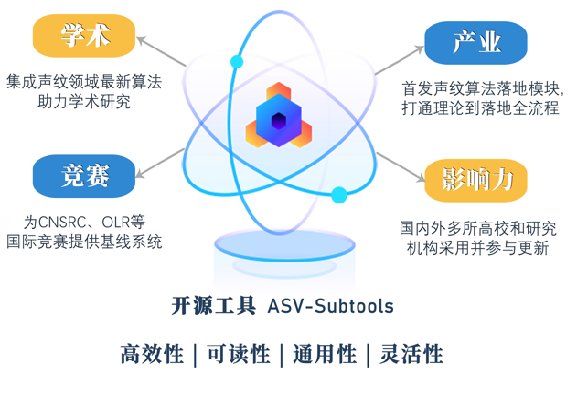
经过不断的迭代更新,现在的Subtools在学术上集成了声纹领域最新的算法可以助力学术研究;在产业应用上我们开源了Runtime模块,打通了从理论到落地的流程;同时也为东方语种竞赛CNSRC等比赛提供了基线系统,在声纹开源的领域持续贡献出自己的力量。
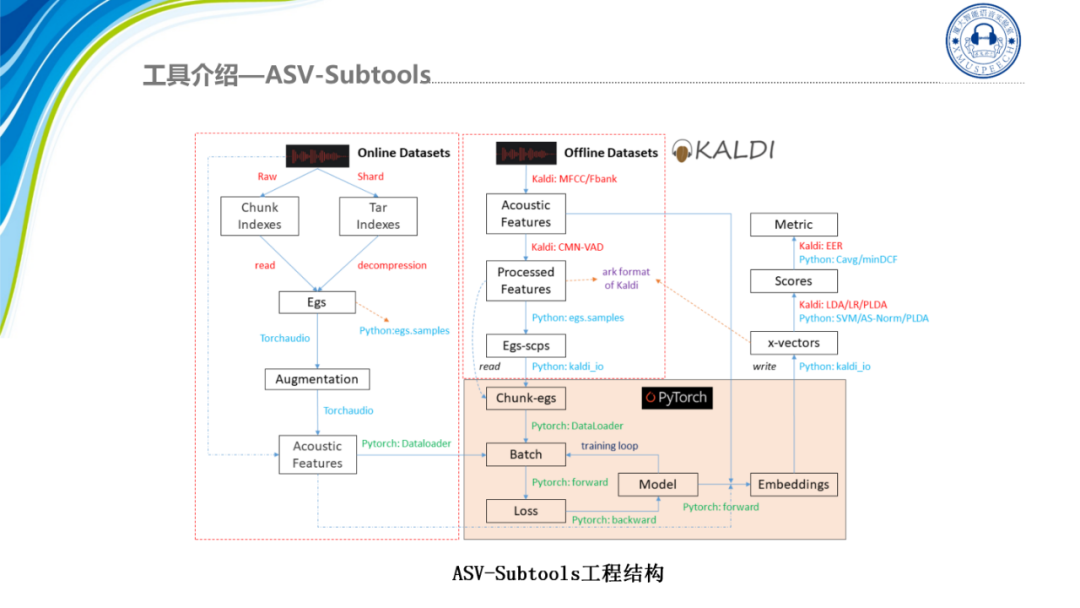
这个是我们Subtools的工程结构,可以看到Subtools从设计之初就希望能够集成Kaldi数据处理的高效性以及PyTorch对神经网络支持的灵活性。Subtools现在可以同时支持在线特征和离线特征,同时我们考虑到数据集的规模往往会较为庞大,因此我们Subtools对数据集的数据处理脚本都进行了速度的优化,如代码上的时间复用、复杂度优化以及多线程提速。在提取完特征后就是利用PyTorch加载数据分Batch进行模型训练,在提取完Embedding之后,打分模块上Subtools提供了一套完整的打分脚本,既可以利用Kaldi的LDA降维后用Cosine打分,也可以用逻辑回归或者PLDA。同时我们也有提供Python版本的支持向量机、分数规整、PLDA和自适应PLDA等。
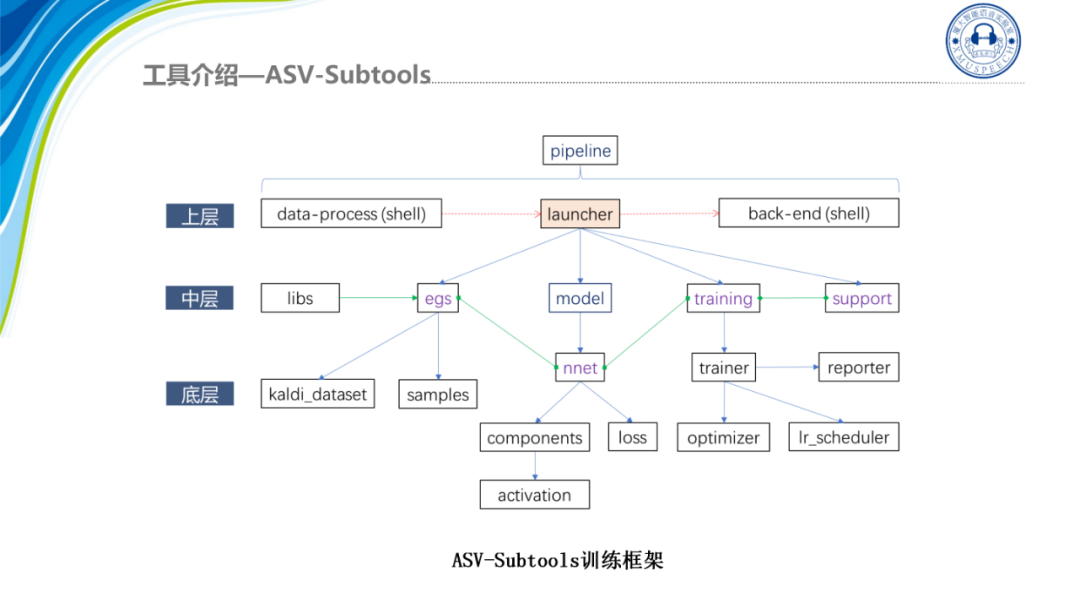
这个是Subtools的训练框架,首先最上层是训练流程包括数据的预处理、训练启动器以及后端三个部分,而中层主要是训练相关的一些高层组件,都包含在训练框架的核心库libs中,比如说样本egs、model、training以及support等,其中ASV-Subtools提供了大量的模块组件nnet,方便开发者进行网络配置,当然用户也可以用PyTorch提供的原生组件进行构建。最后,框架的底层为Python实现的各个基本对象,如对应到Kaldi映射目录的kaldi_dataset、采样方法、基本组件components、损失函数以及训练的相关流程、训练进度显示reporter以及优化器和学习率的综合配置等。
Subtools的另外一个特色是我们提供了高效的打分脚本,由于我们的后端处理可能会有很多的复杂度组合用于后端打分的训练集、注册集以及测试值之间也有多种的处理方法比如说规整、减均值、LDA、降维、白化等等,为了用户能灵活配置Subtools实现了一个高效的打分脚本score set,当给定数据的处理顺序时该脚本会通过一个图的深度遍历方法,自动的将整个打分流程给连接起来,具体如图所示:
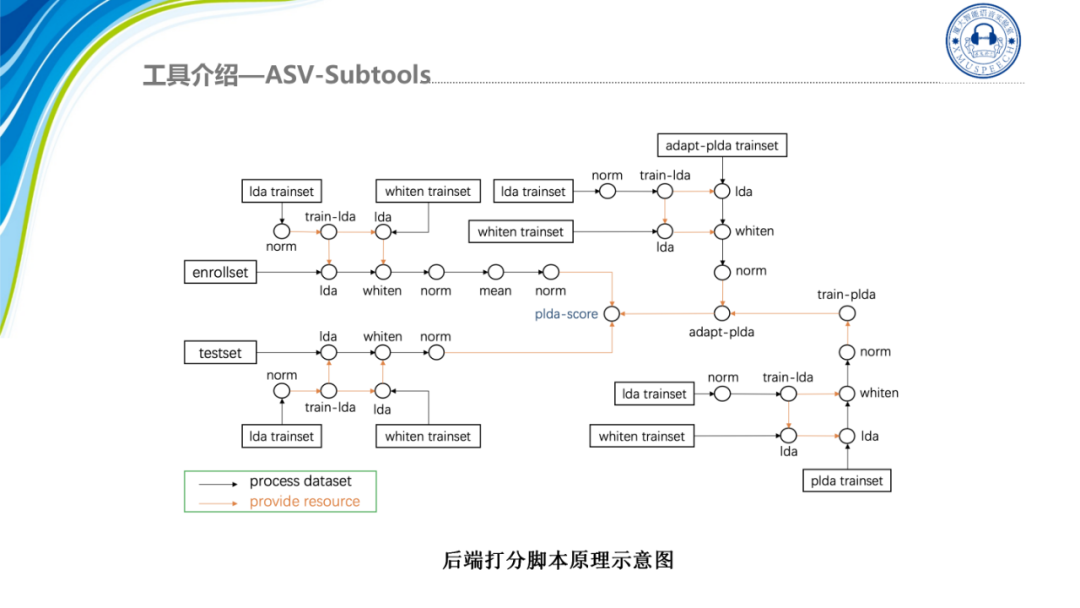
该脚本围绕注册集、测试集和打分三条线进行搜索并自动的将当前处理的输入送到下一个处理中并最终完成打分,极大的方便了用户的后端调试,无需每次都重写部分的代码。
03实验结果
接下来介绍Subtools在一些公开评测集上的结果。首先是在近年来一些比赛中提供的一些基线结果,第一个是OLR2020,Subtools提供了一个基线与当时Kaldi的两个基线进行比较,可以看到Subtools在开发集和评测集上的EER都是比Kaldi的结果好3个点左右,在Cavg上也好不少。

感兴趣的研究人员可以点击subtools/recipe/ap-olr2020-baseline/run.sh下载基线脚本,根据这个脚本完整的复现出整个Baseline。
第二个是OLR2021,Subtools是提供的唯一的基线,EER是在9.038%,Cavg是0.0826。
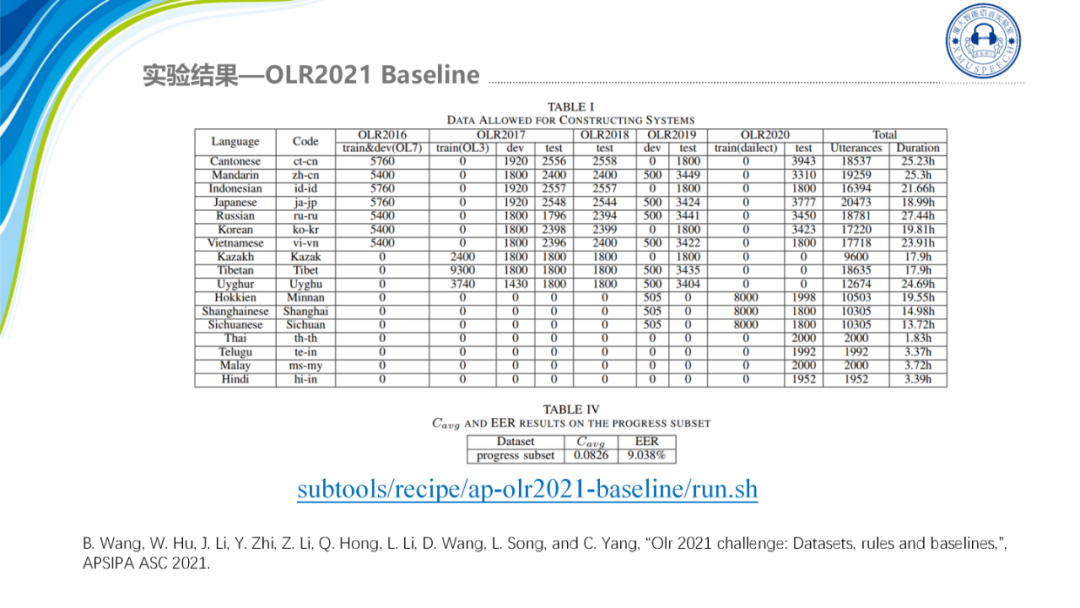
其次是我们在一些公开评测集上,如今年刚刚举办的由奥德赛组委会发起的CNSRC,本次竞赛的核心是验证当前说话人技术在复杂场景上的真实可用性,下图是一些数据的情况:
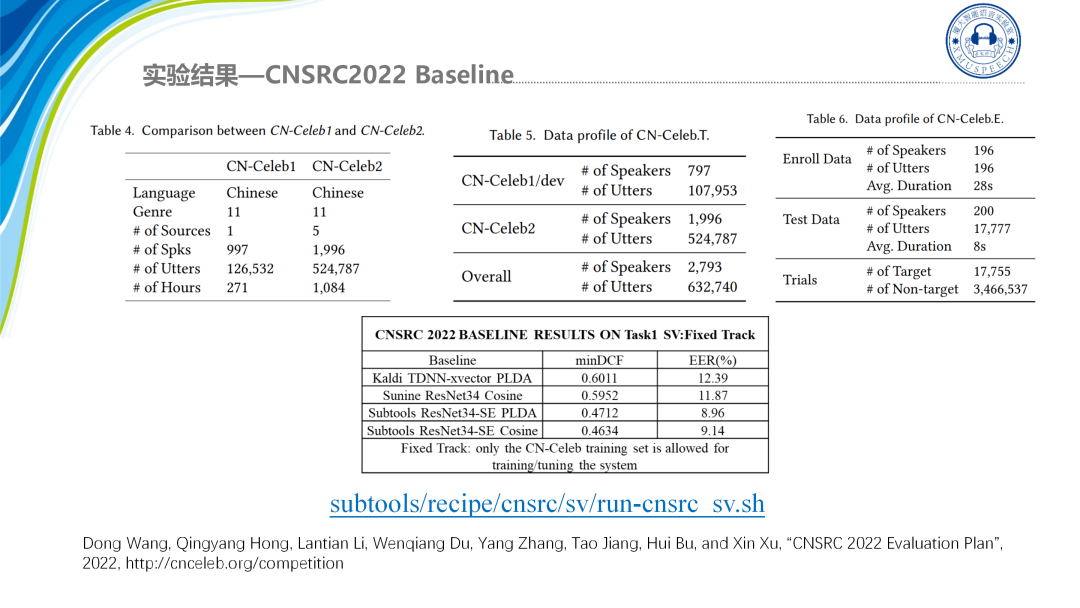
Subtools为这个比赛提供了两个基线,其中b级赛道的EER是9.14,minDCF是0.4634。接下来是在VoxCeleb CN SRC的结果。
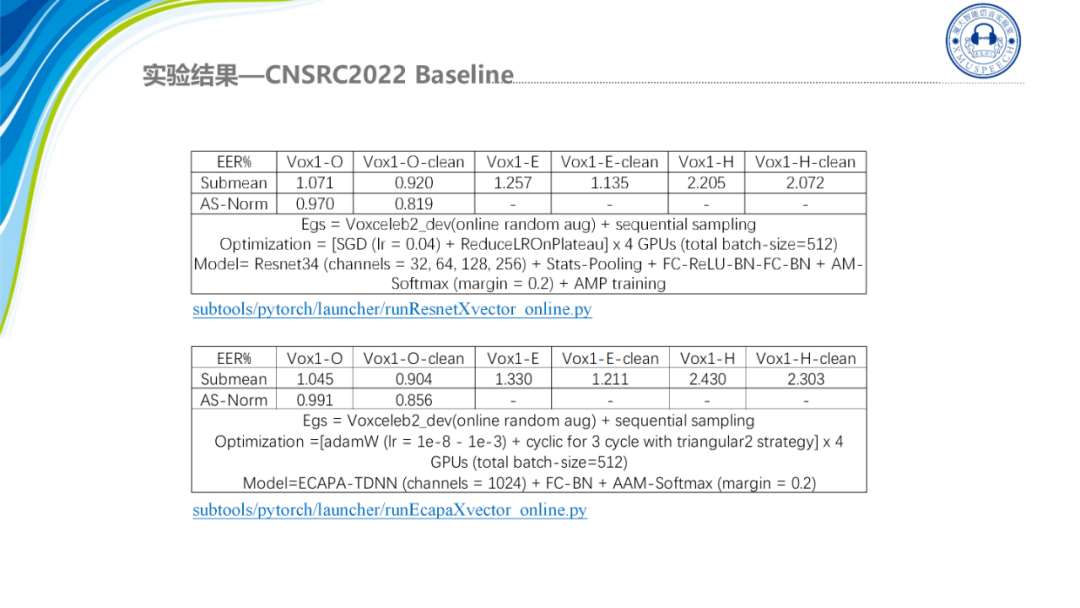
这里我们的训练集都是只用了VoxCeleb2,只训练了一次没有进行Large Margin的调优,在Resnet34上的结果是0.819 ,在ECAPA1024的channels是0.856。
除了这些我们最新的研究结果是基于conformer的xvector并重点关注结合ASR的encoder来帮助提升声纹识别系统的性能。
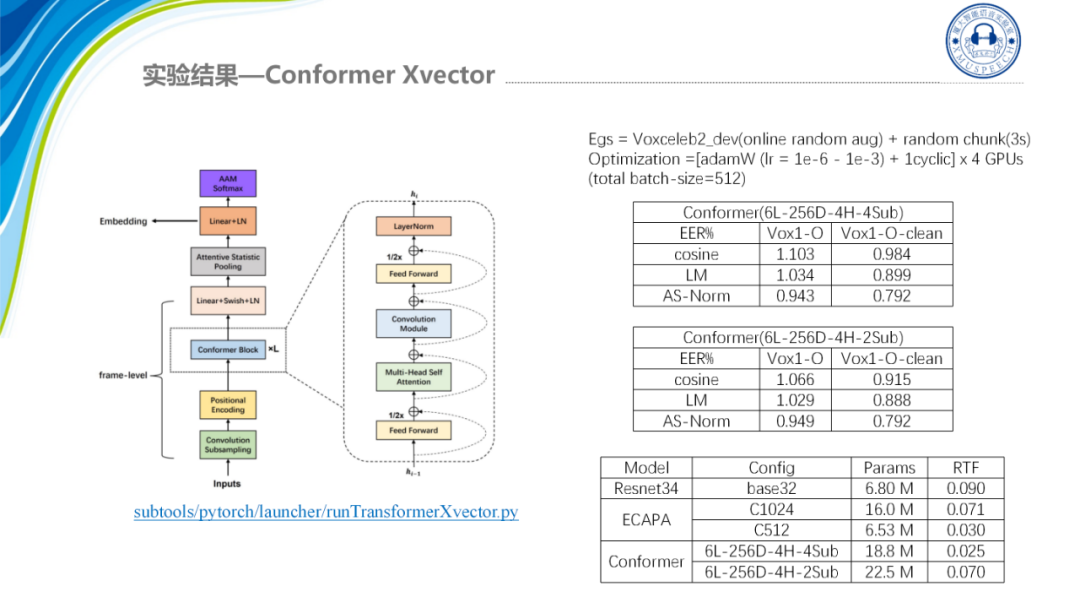
Conformer是一种混合架构它将注意力机制与卷积相结合,即通过Self-attention学习全局的交互信息,CNN捕捉局部信息。这种卷积与自注意力机制的混合设计可以很好的对长短信息进行建模。而且通常认为自注意力机制的网络模型容量是大于卷机网络的,因此更适用于大规模数据训练。之前也有团队提出MFA的Conformer架构,即利用ECAPA-TDNN的多尺度特征聚合方法,将Conformer引入到声纹识别任务中,这个的效果也是比较好的,我们也有做相关的工作,我们对比了两种模型,一种是 4倍下采样的Conformer架构,另外一种是2倍下采样的架构,可以看到在原始的模型上2倍下采样的结果是要优于4倍下采样的结果的,然后经过Large Margin的调优以及AS-Norm之后,最好的结果我们都到了0.792,这表明了ASR Conformer结构在相同的情况下输入4倍下采样的Conformer xvector可以得到和ECAPA网络性能相当的结果并且在速度上更优,然后上图是他们的RTF的展示,可以看到ECAPA1024它的RTF在0.071左右,而4倍下采样的Conformer的RTF是0.025,这意味着4倍下采样的Conformer的性能和ECAPA相等,但它的速度在实际部署的时候是更快的。
最后一个是我们希望是结合ASR任务将语音信息提取到声纹识别系统中起到提升系统性能的效果,其实之前也一直有人研究通过多任务学习将语音信息注入到声纹识别系统当中,他们的研究结果表明在共享一些低级计算时,声纹与ASR之间是存在一些积极的互相依赖性的。并且在去年东方语种的比赛上第一名的系统就是采用迁移学习的方案,即预训练U2++编码器解码器的模型,然后为语种识别任务进行进一步的调优编码器。这其实很好解释因为ASR的监督学习标签就是与语言相关的,那么ASR编码器就已经具有很强的区分语言的能力,那么在语种上结合就是比较有用的。而声纹任务与语种识别任务的信息关联就是不如语种识别那么明显,但我们还是希望能够用适当方法挖掘出他们更深层次的依赖关系,用统一的架构也可以更加方便的研究这两个任务的互通性。
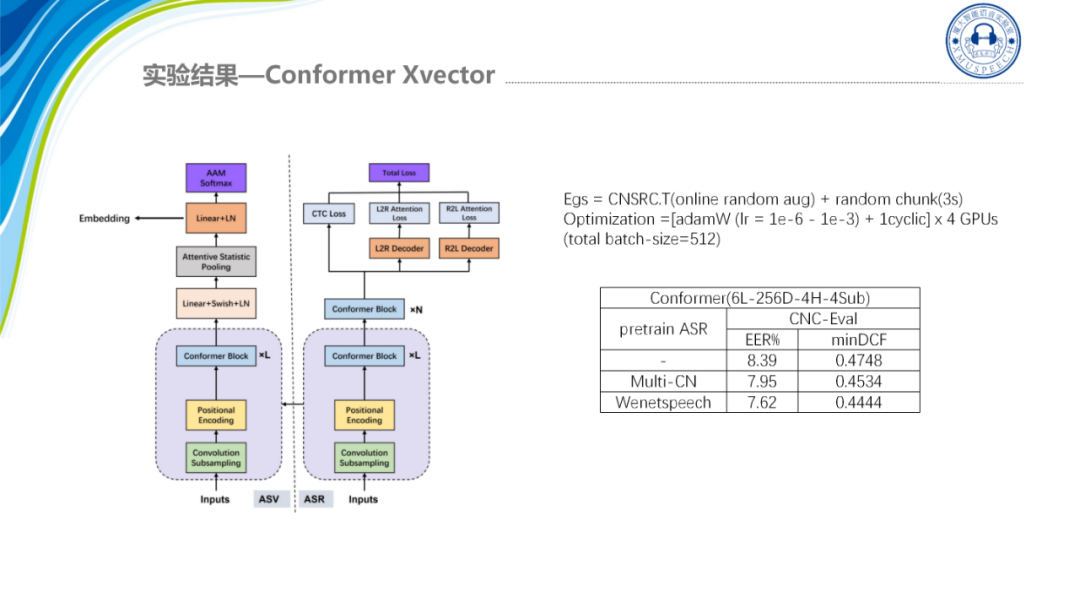
经过研究之后我们提出了一种参数传递策略,该策略可以用典型的ASR模型来提升声纹系统的性能,我们初步的研究结果是表示我们采用迁移12层ASR前面的6层就相当于我们只迁移6层的参数,发现模型是可以达到更低的loss,然后EER是大约提升了10%。这说明Conformer模型对于两种任务建模都有相应的潜力,然后这部分的代码我们也已经开源出来了,大家有兴趣可以一起参与讨论。
04 Subtools工程化
接下来介绍Subtools工程化Runtime模块,由于我们的声纹模型都是PyTorch训练的,这个模型在实际应用中会面临着调用效率的问题,即Python的速度在实际产品部署的时候是偏慢的,而在工程部署的时候我们还是希望用 C++这种高效语言调用模型,以及xvector的提取才能满足实时性的要求。
Subtools的工程化分为四个部分,一是特征集成脱离kaldi,二是模型转TorchScript,三是C++推理,四是So封装。
Runtime的工程结构如图所示:
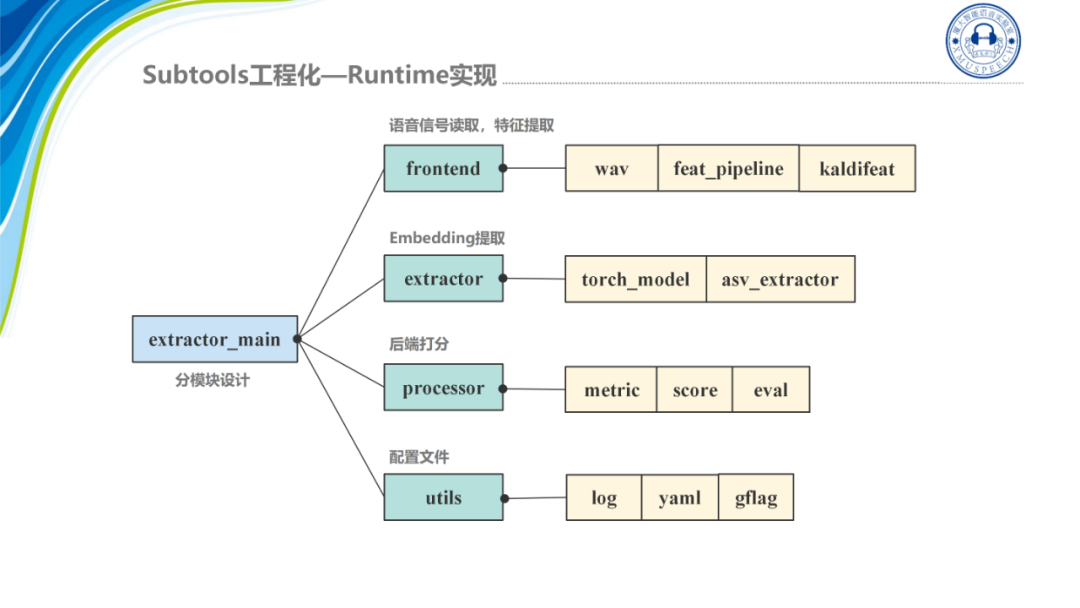
首先最上面是frontend模块,它主要是负责语音信号的读取以及特征的提取;其次是extractor模块,它涉及到Embedding的提取是整个模块的核心部分,主要负责模型的读取和模型的推理;processor是后端打分模块,提取的x-vector通过score模块打分与阈值判定就可以判断出是否为正例;最后utils模块提供了一些通用的工具,比如说日志配置文件的读取等。
特征集成模块如图所示:
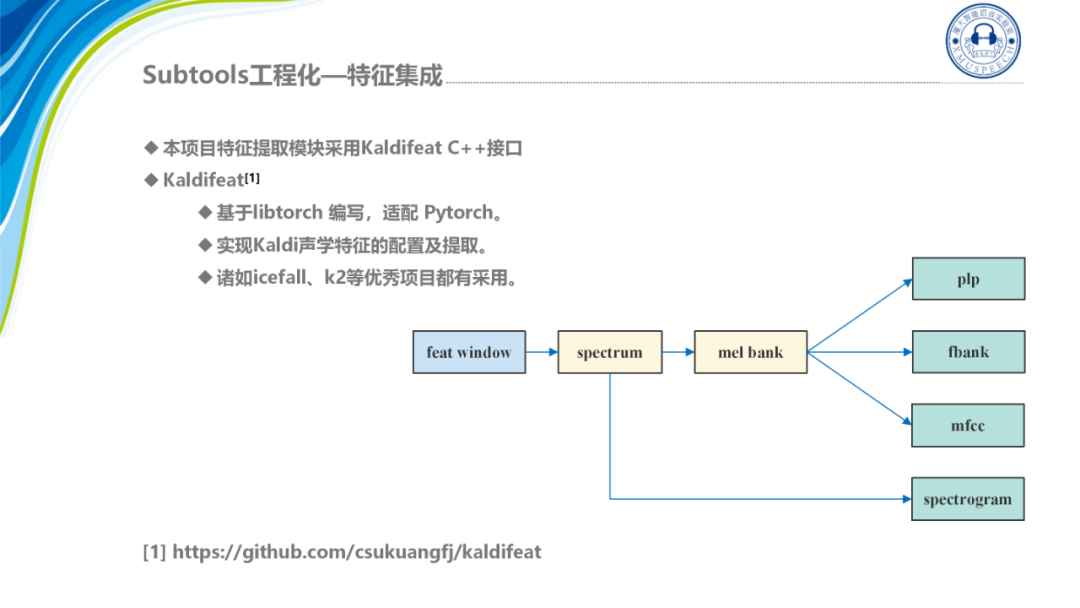
我们采用的是基于libtorch编写的特征提取模块Kaldifeat,它是开源的,可以在Pytorch端兼容Kaldi形式的特征,在icefall、k2等项目中都有所应用,基本上我们常用的一些特征它都支持,比如说plp、mfcc、fbank、语谱图等。
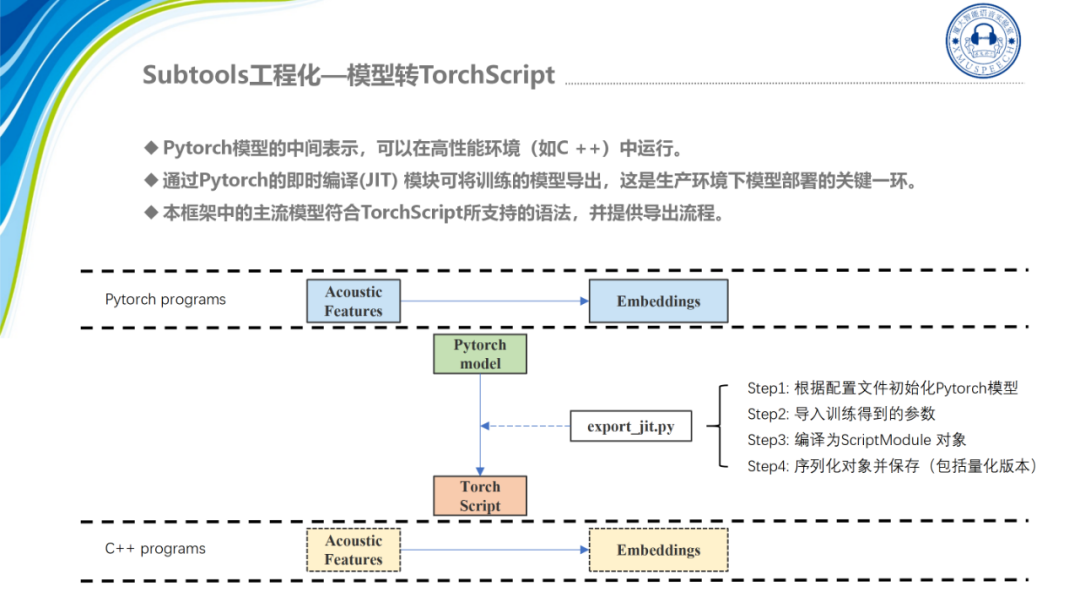
下一步是对模型进行转换,我们需要将模型转换成TorchScript的形式,TorchScript是Pytorch模型的一个中间表示可以在C++中调用,这里我们对主流的一些模型都进行了适配,即我们的开源的工具中对主流模型都提供了脚本进行一键导出模型,这里我们主要的代码就是export_jit模块,这个模块主要做4个工作:
-
第一步,根据配置文件初始化Pytorch模型;
-
第二步,导入训练得到的参数;
-
第三步,编译为ScriptModule对象;
-
第四步,序列化对象并保存(包括量化版本)。
解决完特征和模型x-vector的提取这两个最重要的模块之后,需要将整个声纹识别的流程串通起来,即利用C++代码将整个声纹识别的流程跑通。

在这个流程中,首先语音是需要经过frontend模块然后进行语音信号的处理,再进行特征提取,转化成tensor形式,再送入到模型中进行x-vector提取。
这个模块我们也集成了在实际部署中比较应用的一些功能,比如说特征的均值规划以及VAD的功能,最后提取出的x-vector存储是进入后处理模块,即进行打分,我们现在实现了余弦近似度打分,可以得到阈值对其进行判定。
我们开源的整个Runtime工程提供了cmake一键构建项目,可以直接生成可执行文件。工程目录结构如图所示:
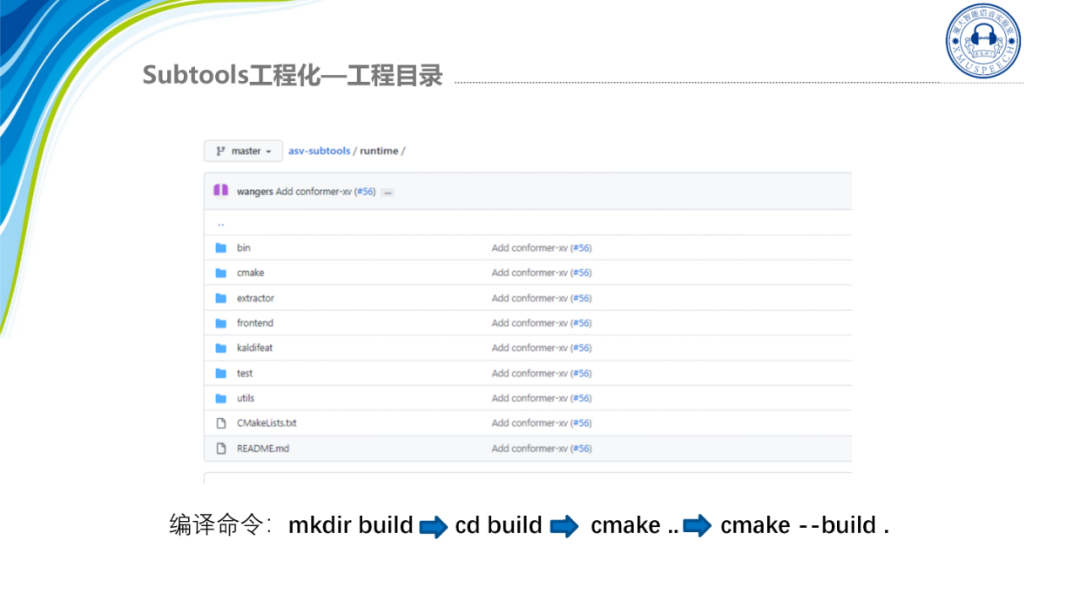
编译命令就是先新建一个文件夹,然后把build这个文件夹进行编译,最后生成一个可执行文件extractor_main。有了可执行文件后,就可以直接部署了。
05 总结与展望
首先,Subtools经过近几年的发展和更新迭代,我们是集成了TDNN、Resnet、ECAPA、Conformer x-vector等网络,在开源数据集上取得了较好的性能,研究人员可用作基线系统。
其次,我们分模块集成不同优化器、损失函数以及PLDA自适应等改进策略,方便用户调优。
第三,我们工具是给近几年的一些竞赛提供了一些基线脚本,并且,我们脚本基本上是一键式的,可以通过运行脚本就把这些比赛的实验数据跑通。
最后,我们开源了Runtime模块,方便工程应用。
当然,我们发展到现在也有一些地方是需要改进的,在未来我们可能会扩展更多的应用,比如说说话人日志以及发布自监督预训练版本的一些内容。在工程代码上我们也需要进行更进一步的精检,此外我们还需要提供更多参数调优的范本,把一些公开测试集SOTA的结果的相应的调整的一些脚本都给公开出来,另外,对我们的基础文档以及教程进行优化编写,最后,我们希望能探索出更多的一些前沿算法并开源出来供大家研究和使用。
最后的最后,感谢所有为ASV-Subtools做出贡献的人员,包括赵淼、周健峰、李铮、陆昊、江涛、童福川、廖德欣等主要开发人员,以及厦门大学智能语音实验室其他的同学。另外,感谢使用和支持ASV-Subtools的研究人员,欢迎更多参与者,共同推动声纹识别开源工具的建设。有兴趣的小伙伴们可以加入我们一起交流,下方是橘子老师的二维码,添加好友后拉入交流群。我的汇报到这里就结束了,敬请指正。






![[附源码]java毕业设计小区宠物管理系统](https://img-blog.csdnimg.cn/914e633e5a0b41e0aff893b55743b184.png)
![[附源码]java毕业设计小锅米线点餐管理系统](https://img-blog.csdnimg.cn/18dc0740a4ee456988a07ce102e2aeea.png)