文章目录
- 集合
- 2.1 介绍一下集合
- 2.2 集合遍历的方法
- 2.3 线程安全的集合
- 2.4 数组和集合的区别
- 2.5 ArrayList和LinkedList的区别
- 2.6 ArrayList底层原理
- 2.7 LinkedList底层原理
- 2.8 CopyOnWriteArrayList底层原理
- 2.9 HashSet底层原理
- 2.10 HashMap底层原理
- 2.11 HashTable底层原理
- 2.12 ConcurrentHashMap底层原理
- 2.13 HashMap和HashTable的区别
- 2.14 HashTable和ConcurrentHashMap的区别
- 2.15 HashMap、HashTable、ConcurrentHashMap的区别
集合
2.1 介绍一下集合
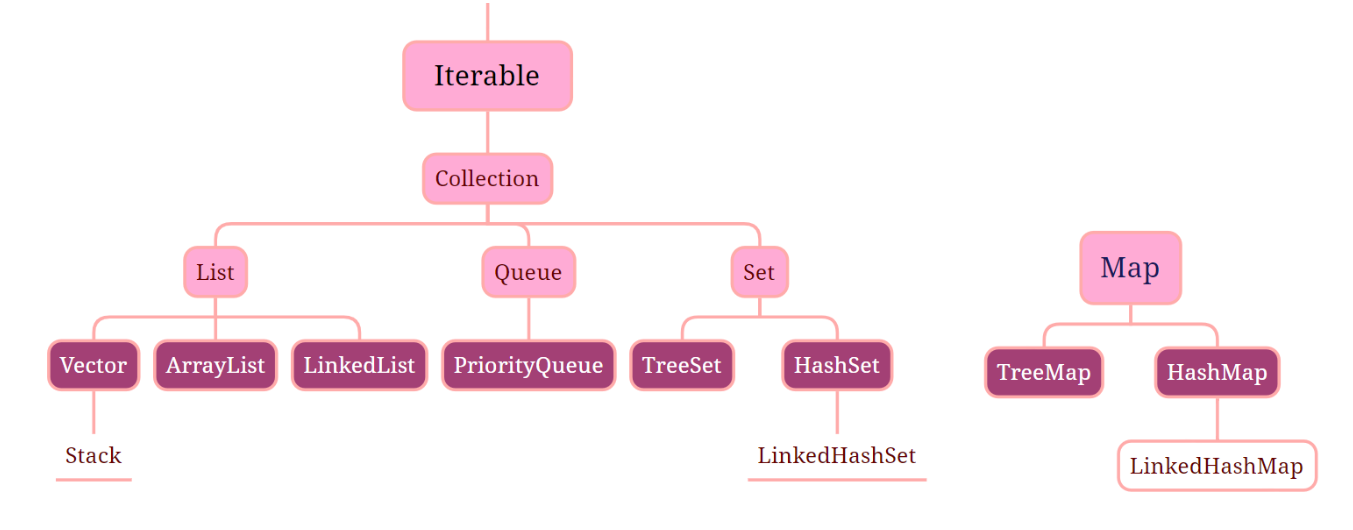
集合分为单列集合Collection和双列集合Map,Collection有有序、可重复、有索引的List和无序、不可重复、无索引的Set,List实现有ArrayList、LinkedList,Set实现有HashSet、LinkedHashSet、TreeSet;
Map的特性是无序、键不可重复、无索引,其实现有HashMap、LinkedHashMap、TreeMap;(了解它们的特性)
2.2 集合遍历的方法
- 普通for循环
- 增强for循环(遍历单列集合,双列集合需要进行转换)
- 迭代器
- stream流foreach方法
1.List可以一边遍历一边修改吗?
在普通循环遍历中可以,但如果使用迭代器则不可以;因为迭代器在创建的时候会记录集合的modCount,如果使用集合的方法,modCount改变而迭代器内部的expectedModCount不会改变,从而导致抛出ConcurrentModificationException异常。2.Map遍历需要使用到entrySet()或keySet()方法
2.3 线程安全的集合
java.util:
- Vector:内部的方法都经过了synchronized修饰
- HashTable:内部方法都经过了synchronized修饰,不支持null键和值
java.util.concurrent
- ConcurrentHashMap:
jdk1.8之前:加的是分段锁,锁的是一部分,不同分段之间并发操作不影响
jdk1.8之后:锁的是每一行,减少并发冲突的概率;put操作时,位置为空,则使用CAS操作设置值,位置不为空,使用synchronized申请锁,进行操作 - ConcurrentSkipListMap:可排序的并发集合,能够在log(n)的时间内完成增删查改操作
- ConcurrentSkipListSet:可排序的并发集合,基于ConcurrentSkipListMap实现
- CopyOnWriteArraySet:
- CopyOnWriteArrayList:写操作时加锁ReentrantLock,复制原数组进行操作,而读操作则直接读原数组,实现了读写分离,提高了并发性能。
1.ArrayList是线程不安全的?
添加元素的步骤:
1)判断是否需要扩容
2)将size位置设置为待加入的值
3)size+1
可能导致数组下标越界、元素覆盖、数组大小和实际插入大小不一致,可以使用CopyOnWriteArrayList、Vector代替,使之变成线程安全的。2.HashMap是线程不安全的?
1)死循环:jdk1.7时,在多线程的情况下使用头插法,导致链表指针顺序被修改,出现环形链表,形成死循环(jdk1.8之后采用尾插法避免了链表倒置)
2)数据覆盖:哈希冲突时,元素被覆盖
3)数据丢失:扩容的时候,会出现部分数据未被正常迁移的情况
2.4 数组和集合的区别
- 长度:数组长度固定;集合可以动态扩容
- 元素:数组可以包含基本数据类型和对象;集合只能包含对象
- 方法:数组是能通过下标访问数据;集合提供了丰富的API方法,如add()、remove()
2.5 ArrayList和LinkedList的区别
- 底层数据结构:ArrayList的底层的数据结构是数组;LinkedList的数据结构是链表;
- 访问速度:ArrayList访问一个元素的时间复杂度为O(1);LinkedList访问一个元素的时间复杂度为O(n)
- 插入和删除速度:ArrayList插入和删除元素的时间复杂度为O(n);LinkedList插入和删除元素的时间复杂度为为O(1)
- 空间占用:ArrayList会预分配一段连续的空间,占用空间比较大;LinkedList插入的时候才会分配空间,占用空间比较小
2.6 ArrayList底层原理
底层数据结构:数组
底层原理:
-
空参创建集合时,在底层创建一个长度为0的数组
-
添加第一个元素时,创建一个长度为10的数组
-
添加过程:
1)判断是否存满,满则扩容为原来的1.5倍
扩容机制:
创建:创建一个长度为原来1.5倍的新数组
复制:将原数组复制到新数组
更新引用:将原数组的引用指向新数组
2)将size位置设置为待加入的值
3)size+1
ArrayList是线程不安全的:
可能导致数组下标越界、空值、数组大小和实际插入大小不一致,可以使用CopyOnWriteArrayList、Vector代替,使之变成线程安全的。
2.7 LinkedList底层原理
底层数据结构:链表
因为长度不是固定的,所以不需要考虑扩容的情况。
2.8 CopyOnWriteArrayList底层原理
如何保证线程安全?
- volatile关键字修饰数组,保证对数组的修改对其他线程是可见的
- 写操作(加锁ReentrantLock):创建一个新数组,将原数组拷贝到新数组,并将原数组的引用指向新数组;
读操作(不加锁):读取原数组;
2.9 HashSet底层原理
底层数据结构:哈希表(数组+链表+红黑树)
底层原理:
- 空参创建时,底层创建一个长度为0的数组
- 添加首个元素时,创建一个长度为16的数组,默认加载因子是0.75(即达到数组的0.75倍,会进行扩容)
- 添加过程:
1)调用hashCode()根据属性值计算哈希值;
2)再根据(n-1)&hash计算桶的位置;
3)如果位置为空,直接存入;如果位置不为空,调用equals()方法比较属性值,一样不存入,不一样,挂在下面,形成链表
4)如果链表长度>8 & 数组长度>=64,自动转换为红黑树;如果树中节点<6,自动退化为链表
5)判断元素个数是否超过了数组大小*加载因子,超过则扩容
扩容机制:
创建:创建一个长度为原来2倍的新数组
复制:将原数组的键值对重新哈希分配到新数组中
更新引用:将原数组的引用指向新数组
LinkedHashSet:底层数据结构是哈希表+双向链表,使用双向链表维护了插入顺序或访问顺序
2.10 HashMap底层原理
底层数据结构:哈希表(数组+链表+红黑树)
底层原理:
- 空参创建时,底层创建一个长度为0的数组
- 添加首个元素时,创建一个长度为16的数组,默认加载因子是0.75(即达到数组的0.75倍,会进行扩容)
- 添加过程:
1)调用hashCode()根据属性值计算哈希值;
2)再根据(n-1)&hash计算桶的位置;
3)如果位置为空,直接存入;如果位置不为空,调用equals()方法比较属性值,一样则覆盖,不一样,挂在下面,形成链表
4)如果链表长度>8 & 数组长度>=64,自动转换为红黑树;如果树中节点<6,自动退化为链表
5)判断负载因子是否超过阈值,超过则扩容
扩容机制:
创建:创建一个长度为原来2倍的新数组
复制:将原数组的键值对重新分配到新数组中
更新引用:将原数组的引用指向新数组
1.HashMap的key可以是null?
可以是null键,但只能有一个。计算哈希值时,如果为null返回02.如何解决哈希冲突?
哈希冲突:不同属性值计算出的哈希值相同
使用拉链法解决哈希冲突
jdk1.8之前:数组+链表
jdk1.8之后:数组+链表+红黑树3.其他解决哈希冲突的方法?
- 拉链法:将哈希值相同的连接在同一个桶中
- 开发寻址法:在哈希表中寻找另一个可用的位置
- 再哈希法:使用另一个哈希函数计算哈希值,直到找到空槽
- 哈希表扩容:扩大哈希表,减少冲突的概率
4.为什么是扩大2倍(HashMap大小为什么总是2的n次方)?
因为这样在扩容的时候,只需要将原哈希值和len-1进行按位与,高位为0则索引不变,高位为1则新索引=原索引+旧数组容量,从而把哈希冲突的节点随机分配到了新数组中。
2.11 HashTable底层原理
内部的方法基本都经过synchronized的修饰,锁住的是整个哈希表,锁的粒度比较大,保证线程的安全
2.12 ConcurrentHashMap底层原理
jdk1.7:使用分段锁,用的是ReentrantLock,锁住的是一部分数据,当一个线程访问其中一段数据时,其他线程也能访问其他段
jdk1.8:使用CAS机制或synchronized,锁的是头结点,锁的粒度更细,提高了并发能力;put操作时,hash槽位为空,则使用CAS操作设置值,槽位不为空,使用synchronized申请锁,进行操作
为什么要同时使用CAS、synchronized?
结合锁竞争情况,选择不用的方法
1)竞争较弱:CAS是无锁的,通过硬件实现原子性,但当锁竞争激烈的时候,CAS操作会频繁失败,导致线程不断重试,降低性能。
2)竞争激烈:synchronized在锁竞争激烈的情况下,通过锁升级机制可以有效控制线程的竞争。
2.13 HashMap和HashTable的区别
线程安全:HashMap线程不安全;HashTable安全
效率:HashMap效率较高;HashTable,使用了锁,效率较低
底层数据结构:HashMap在jdk1.8之后底层的数据结构为数组+链表+红黑树,当链表长度>8 & 数组长度>=64,会转换为红黑树,如果数组长度<64,则扩容;HashTable则没有这种机制
对null键和null值的支持:HashMap支持null键和null值,但null键只能有一个;HashTable不支持null键和null值,会抛出空指针异常
初始容量大小和扩充容量大小:HashMap默认初始容量为16,扩容为2n,如果指定了容量大小,会扩充为2的幂次方;HashTable默认容量为11,扩容为2n+1,如果指定了容量大小,直接使用
哈希函数的实现:HashMap在计算哈希值时进行了高位和低位的混合扰动处理;HashTable则直接使用哈希值
2.14 HashTable和ConcurrentHashMap的区别
线程安全方式:HashTable是通过synchronized修饰方法保证线程安全;ConcurrentHashMap是通过CAS或synchronized保证线程安全的。
底层数据结构:HashTable的底层数据结构是数组+链表;ConcurrentHashMap的底层数据结构jdk7是分段数组+链表、jdk8是数组+链表+红黑树
2.15 HashMap、HashTable、ConcurrentHashMap的区别
线程安全:不安全;安全;安全
底层数据结构:数组+链表+红黑树;数组+链表;数组+链表+红黑树
对null键和null值的支持:不支持;支持;支持;
初始容量大小和扩充容量大小:16、2n ;11、2n+1;16、2n
哈希函数的实现:高低位混合扰动;直接使用哈希值;高低位混合扰动