1. 引言
ClickHouse 是一款备受欢迎的开源列式在线分析处理 (OLAP) 数据库管理系统,专为在海量数据集上实现高性能实时分析而设计,并具备极高的数据摄取速率 1。其在各种行业中得到了广泛应用,包括众多知名企业,例如超过半数的财富全球 2000 强公司都信赖 ClickHouse 来处理其生产工作负载 1。值得注意的是,在 2024 年,ClickHouse 的设计与架构以一篇名为 “ClickHouse - Lightning Fast Analytics for Everyone” 的论文形式发表于国际顶级数据库会议 VLDB (Very Large Data Bases) 上,该论文简洁地阐述了 ClickHouse 实现极速性能的关键架构和系统设计组件 1。
对于处理大规模分析工作负载的后端基础架构工程师而言,深入理解 ClickHouse 的内部机制至关重要。尤其是在诸如网络分析、金融和电子商务等领域,数据量巨大且持续增长,ClickHouse 能够提供高效的解决方案 1。本报告旨在深入探讨 ClickHouse 的架构、设计理念、性能优化策略以及固有的设计权衡,从而帮助后端工程师全面理解并有效利用这一强大的分析型数据库。报告将涵盖其核心架构层、存储和查询处理的细节、集成能力、性能考量以及在一致性和事务支持等方面的权衡。
ClickHouse 的设计与架构能够获得学术界的认可,并在顶级的 VLDB 会议上发表论文 1,这标志着它从一个纯粹由工程驱动的项目发展成为一个拥有学术理论支撑的系统。这一成就预示着 ClickHouse 的设计原则和实现方法经过了严格的审查,并被认为是数据库领域的重要贡献,有助于在更广泛的企业环境中建立信任并获得更广泛的应用。
ClickHouse 论文及其相关资料中反复强调的“PB 级数据集和高摄取率(在大数据数据库的语境下,“高摄取率”通常指的是数据被快速、高效地接收、存储和处理的能力)” 1 表明,ClickHouse 的设计目标是解决现代分析应用中面临的核心挑战。处理如此庞大的数据量以及持续高速的数据流入,必然要求 ClickHouse 在存储和写入操作上具备极高的效率,这也直接影响了其架构决策,例如采用列式存储和 MergeTree 存储引擎。
2. ClickHouse 架构深度解析
-
2.1 主要分层概述 1
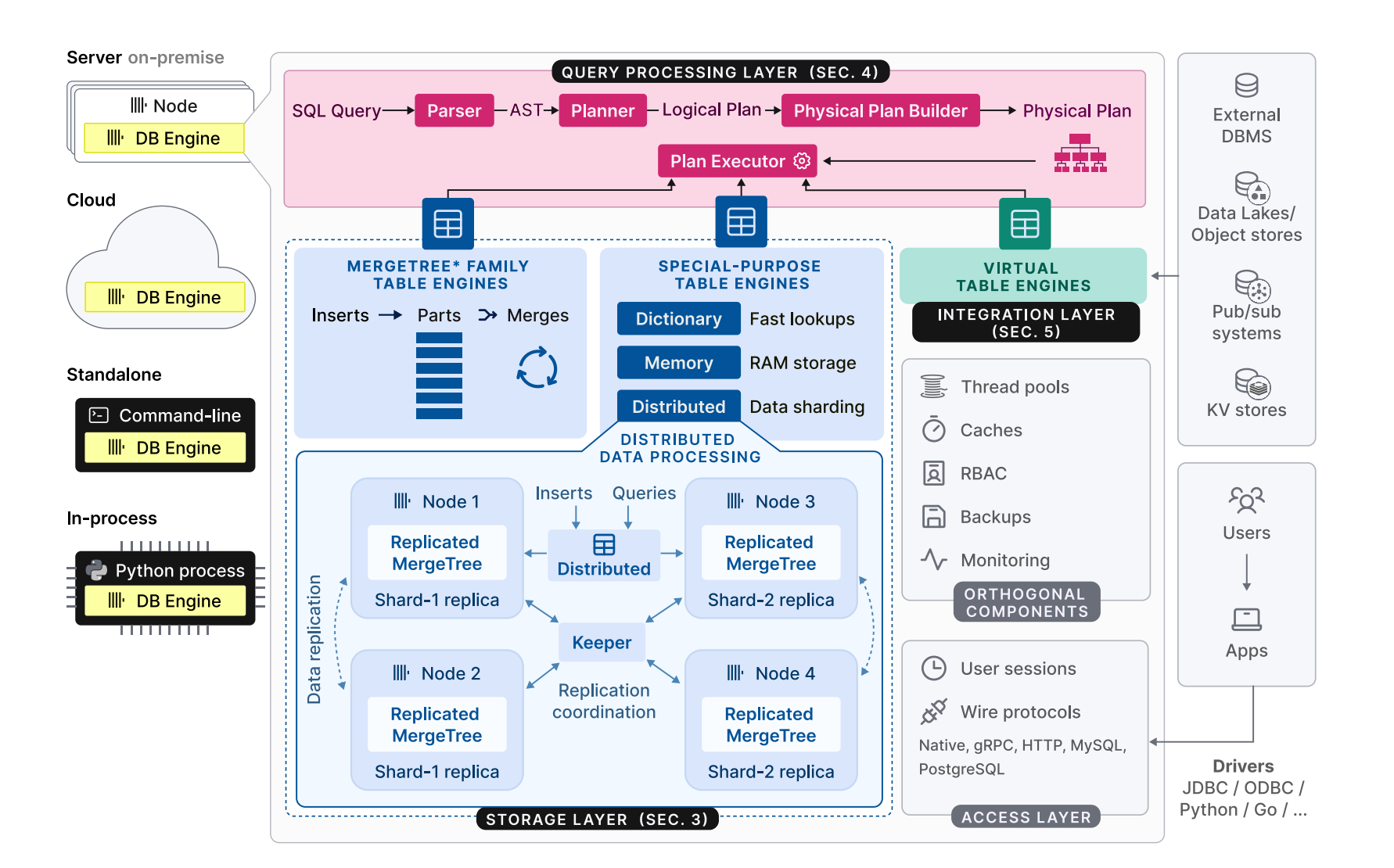
ClickHouse 的架构清晰地划分为若干主要层次,每一层负责不同的功能 1。查询处理层负责解析用户输入的查询语句,构建并优化查询的逻辑和物理执行计划,并最终通过向量化执行模型和可选的代码编译来执行这些计划 1。存储层则负责管理表数据的存储格式和物理位置,其中 MergeTree 系列是 ClickHouse 最主要的持久化存储引擎。存储层还负责数据的磁盘存储、索引管理以及后台的数据合并等操作 1。集成层提供了与各种外部系统、数据存储和数据格式进行数据交换的能力,通过表函数、表引擎和数据库引擎等机制实现 1。访问层则负责处理用户会话的管理以及通过各种协议与应用程序进行通信,这些协议包括 ClickHouse 的原生协议、MySQL 和 PostgreSQL 的二进制线协议以及 HTTP RESTful API 1。
除了以上核心层次,ClickHouse 还包含一些正交组件,例如负责并行执行的线程管理、用于提升性能的缓存机制、保障数据安全的基于角色的访问控制、用于数据恢复的备份与恢复功能以及用于监控系统运行状态的持续监控能力 2。值得一提的是,ClickHouse 完全使用 C++ 语言开发,并编译成一个独立的、静态链接的二进制文件,不依赖于任何外部库,这有助于实现接近硬件底层的性能并简化部署过程 1。
将复杂的数据库功能划分为逻辑分层 1 体现了 ClickHouse 设计上的严谨性和模块化。这种分离使得开发团队能够专注于每个组件的改进和优化,而不会对其他部分产生不必要的副作用,从而保证了系统的整体稳定性和性能。例如,查询处理层的优化可以独立进行,而无需修改底层的存储机制。
选择 C++ 语言并生成自包含的静态链接二进制文件 1 明确表明了 ClickHouse 对性能和操作简易性的高度重视。C++ 语言以其高性能和对系统资源的底层控制而闻名。通过静态链接所有必要的库到一个可执行文件中,ClickHouse 避免了运行时依赖问题,并减少了与托管运行时环境(如 JVM)相关的性能开销,这直接支持了其提供“闪电般快速分析”的目标。 -
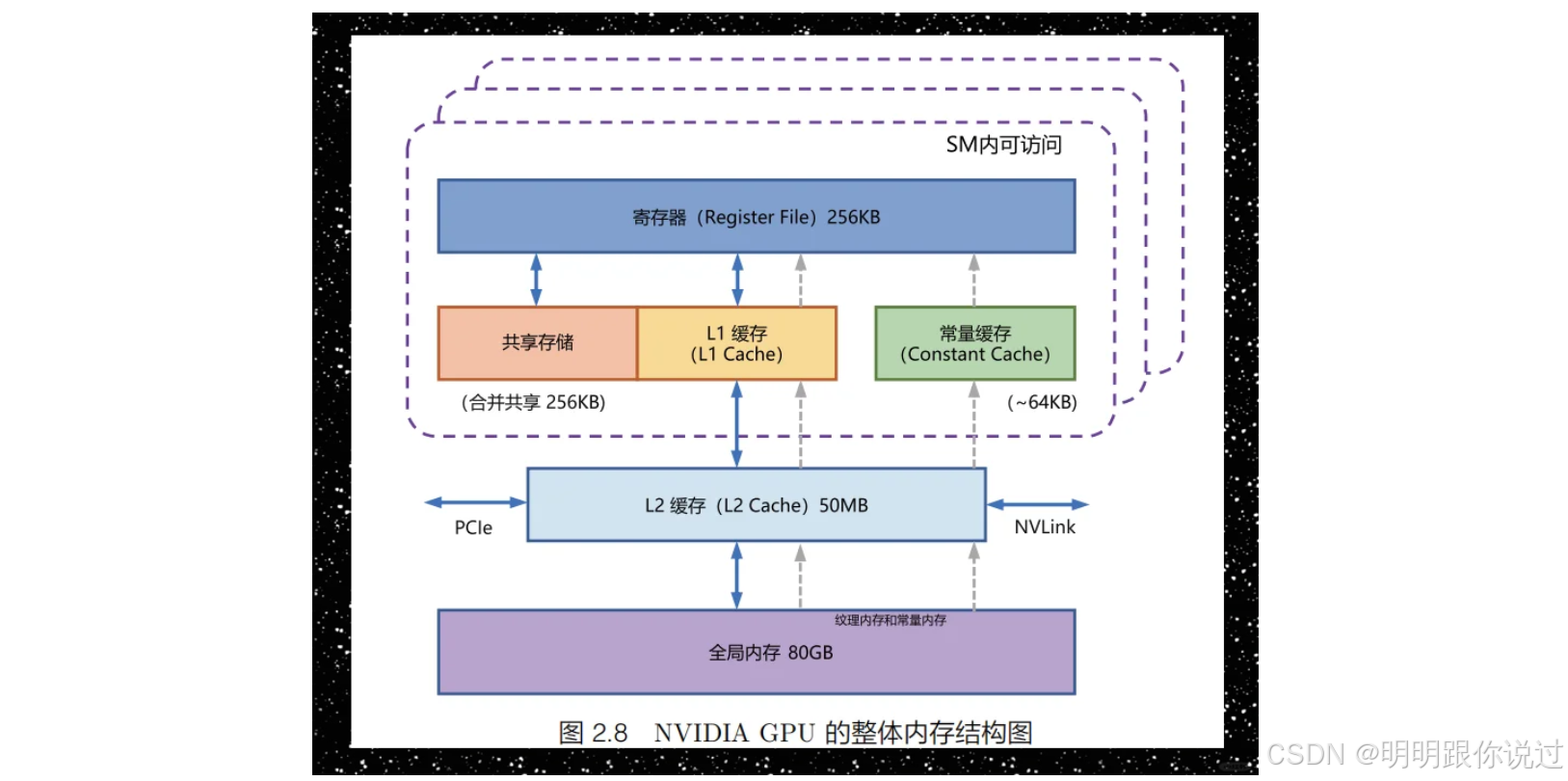
2.2 存储层详解 1
-
-
2.2.1 MergeTree 系列 2
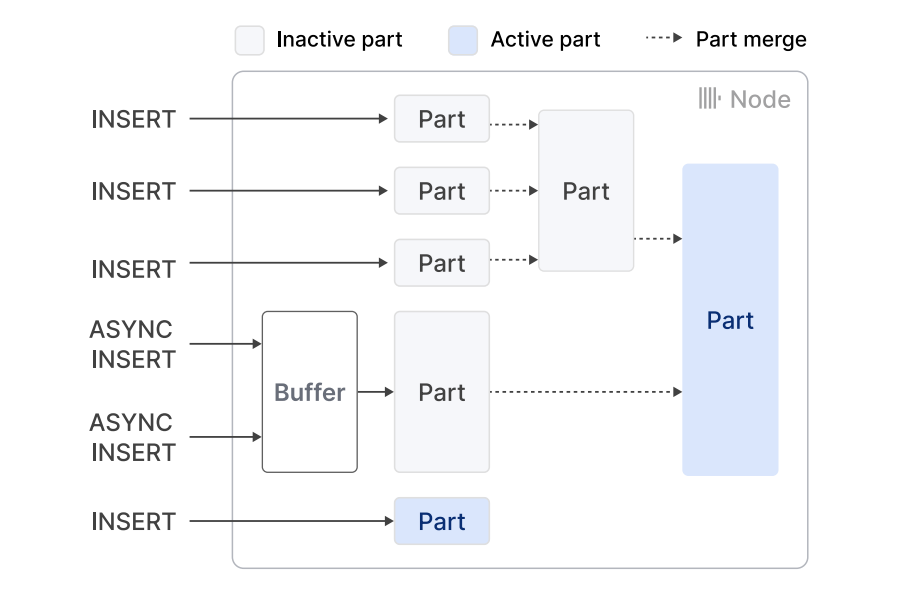
MergeTree 系列引擎是 ClickHouse 存储层的基石,专为高数据摄取速率和海量数据存储而设计 2。其设计思想来源于日志结构合并树 (Log-Structured Merge Tree, LSM Tree) 2,数据首先以小而有序的数据部分顺序写入磁盘。后台进程会持续地将这些较小的部分合并成更大、更优化的部分 2,这对于高效查询和管理大量数据部分至关重要。MergeTree 系列中包含不同的引擎(如 ReplacingMergeTree、AggregatingMergeTree、SummingMergeTree、CollapsingMergeTree),它们在合并过程中提供了不同的行为,以满足各种分析需求,例如去重、预聚合以及处理状态变化的数据 2。MergeTree 系列还支持使用任意表达式对表进行分区 2,从而可以在查询执行期间根据分区值有效地跳过不相关的数据。此外,它还利用主键来定义每个数据部分内的排序顺序 10,这有助于高效搜索和数据跳过。 -
2.2.2 磁盘格式 1
ClickHouse 中的表由多个数据部分组成,每个部分在磁盘上都表现为一个目录 9。在每个数据部分内部,数据根据表的主键进行排序 10。数据部分在逻辑上被划分为粒度 (granule),粒度是连续的行块(通常为 8192 行,由 index_granularity 设置控制) 1。粒度是基于索引查找时读取数据的最小单元。对于表中的每个列,数据以单独文件的形式存储在 Wide 格式中 10。另一种选择是 Compact 格式,它将所有列的数据存储在单个文件中,这对于频繁的小批量插入可能更有益 10。数据部分中的数据块(由多个粒度组成)使用高效的算法(默认使用 LZ4)进行压缩 1,从而减少存储空间并提高 I/O 性能。 -
2.2.3 数据剪枝技术 1
ClickHouse 采用多种数据剪枝技术来避免扫描不相关的数据,从而提高查询效率 1。
-
主键索引: MergeTree 表会维护一个稀疏的、基于内存的主键索引 1。该索引将主键值映射到数据部分内的起始标记(粒度),允许使用二分搜索有效地过滤数据范围。索引之所以是稀疏的,是因为它并非索引每一行,而是每隔 index_granularity 行索引一次 10。
-
表投影: 表投影允许创建表的替代内部版本,这些版本可以根据不同的主键进行排序 1。当查询需要根据表的主键以外的其他列进行过滤或排序时,这些投影可以通过提供预排序的数据来显著提高查询速度。
-
跳跃索引: 跳跃索引是一种辅助索引,允许 ClickHouse 在查询的 WHERE 子句中包含条件时,跳过读取那些保证不包含匹配行的整个数据块(粒度) 1。ClickHouse 提供了多种类型的跳跃索引,包括:
-
minmax:存储每个数据块中表达式的最小值和最大值,适用于对松散排序的数据进行范围查询 13。
-
set(N):存储每个数据块中最多 N 个不同的值,对于每个块内基数较低的列非常有效 13。
-
bloom_filter:一种概率数据结构,可以快速判断某个值是否可能存在于一个数据块中,适用于优化对高基数列的等值检查 13。
-
tokenbf_v1 和 ngrambf_v1:专门为在字符串数据中搜索标记或 n-gram 而设计的 Bloom 过滤器变体,特别适用于日志分析和文本搜索 14。
跳跃索引通过一个表达式、索引类型、名称和粒度来定义 13,并且仅适用于使用 MergeTree 系列引擎的表 14。
-
2.2.4 合并时数据转换 2
ClickHouse 在后台合并过程中持续进行增量数据转换,从而减轻查询执行的负担 2。
-
ReplacingMergeTree:在合并过程中,对于主键相同的行,仅保留具有最新版本(基于指定的版本列或插入顺序)的行,从而有效地处理数据重复 2。
-
AggregatingMergeTree:在合并过程中,通过指定的聚合函数将具有相同主键的行合并为聚合后的行。这通常与物化视图结合使用,以显著提高查询性能 2。
-
TTL (Time-to-Live) 合并:允许根据时间定义规则,在合并过程中自动将数据移动到不同的存储层、重新压缩数据或删除过期数据 2。
-
2.2.5 更新和删除 2
虽然 ClickHouse 针对追加式工作负载进行了优化,但它也提供了更新和删除数据的机制。
-
Mutation:允许对表中已有的数据执行任意转换,包括更新和删除。Mutation 会就地重写所有数据部分,并且是异步和非原子的 2。
-
轻量级删除:引入了一种使用内部位图将行标记为已删除的机制。物理删除的行将在后续的合并操作中被移除 2。
-
2.2.6 幂等性插入 2
为了确保在发生网络问题或客户端重试的情况下数据的一致性,ClickHouse 会维护最近插入的数据部分的哈希值。如果在一定的时间范围内再次插入相同的数据,则可以忽略该插入操作,从而保证了插入的幂等性 9。 -
2.2.7 数据复制 1
ClickHouse 支持分片和复制,以实现可伸缩性和高可用性 1。
-
分片涉及根据分片键或表达式将表水平分割到多个独立的节点(分片)上 2。一个特殊的 Distributed 表引擎提供了所有分片的全局视图 2。
-
复制通过在不同的节点上维护表的多个副本(副本)来确保数据冗余和容错能力 1。复制表使用基于 Raft 共识算法的多主协调方案(通常使用 ClickHouse Keeper 实现)来确保副本之间的数据一致性 2。
-
2.2.8 ACID 合规性 2
ClickHouse 通过最小化锁的使用,优先考虑分析查询的高性能和可伸缩性。它为单个查询提供快照隔离,这意味着查询在其开始时看到数据的一致性快照 2。然而,传统的完整 ACID(原子性、一致性、隔离性、持久性)事务并非完全保证,尤其是在影响同一数据部分的并发写入操作的情况下 2。
MergeTree 引擎的精巧设计,借鉴了 LSM 树的原理,并融入了合并时转换和各种索引策略等特性,是 ClickHouse 能够处理海量数据并保持查询性能的关键驱动因素。理解不同 MergeTree 引擎及其配置的细微差别,对于针对特定分析工作负载优化 ClickHouse 至关重要。LSM 树架构通过将数据顺序追加到磁盘来优化写入性能,而后台合并过程则优化数据以提高读取性能。这种设计,加上在合并过程中执行聚合和去重等转换的能力,将计算负载从查询时间转移到后台,从而加快了分析查询的速度。各种 MergeTree 引擎的出现为根据不同的数据特征和分析需求定制存储层提供了灵活性。粒度(固定行数的数据块)的概念是 ClickHouse 在 MergeTree 表中管理和索引数据的基本方式。index_granularity 设置直接影响这些粒度的大小,并影响索引大小(内存使用)和数据跳过精度之间的权衡。选择合适的 index_granularity 是重要的性能调优考虑因素。稀疏主键索引指向每个粒度的开头。较小的 index_granularity 意味着更频繁的索引条目,从而产生更大的索引,但也可能实现更精确的数据跳过。相反,较大的 index_granularity 会减小索引大小,但可能导致扫描更多不必要的数据。最优值取决于特定的工作负载和数据分布。ClickHouse 的数据剪枝技术,包括主键索引、表投影和各种跳跃索引,对于在大型数据集上实现高查询性能至关重要。通过在从磁盘读取数据之前有效地过滤掉不相关的数据,这些技术显著减少了 I/O 和 CPU 使用,从而加快了查询执行速度。理解何时以及如何使用每种类型的索引是 ClickHouse 管理员和开发人员的关键技能。对于通常涉及按特定条件进行过滤的分析查询,避免扫描整个数据集的能力对于性能至关重要。ClickHouse 提供了多种实现此目的的机制。主键索引有助于根据主键进行过滤,而跳跃索引则基于各种统计或概率方法将此功能扩展到其他列。表投影通过提供数据的替代排序视图来优化查询。MergeTree 系列的合并时数据转换能力突显了 ClickHouse 的一个核心设计理念,即将计算工作从查询时间转移到后台进程。这使得数据摄取非常高效,并显著加快了对预处理或转换数据的分析查询,例如去重或预聚合的结果。通过在后台合并过程中执行去重和聚合等任务,ClickHouse 减少了用户运行查询时需要完成的工作量。这对于可以利用这些预处理数据的常用分析查询尤其有利,从而带来显著的性能提升。
-
2.3 查询处理层深入分析 1
-
2.3.1 向量化执行模型 2
ClickHouse 是一个真正的列式数据库管理系统,它按列存储数据,并以数组(列的向量或块)的形式处理数据 9。尽可能地,操作直接在这些数组上分派,而不是在单个值上操作,这通过减少函数调用的开销并提高 CPU 缓存利用率,带来了显著的性能提升 9。这种模型允许高效地利用单指令多数据 (SIMD) 处理器指令,从而可以使用一条指令并行处理向量中的多个数据元素 1。IColumn 接口表示内存中的列(以块的形式),并为实现各种关系运算符提供了辅助方法。对列的大部分操作都是不可变的,它们创建新的修改后的列,而不是更改原始列 21。 -
2.3.2 并行化策略 2
-
SIMD 并行化: 通过向量化执行模型实现,允许使用 SIMD 指令对向量中的数据进行并行操作 2。
-
多核并行化: 查询执行计划通常展开为 N 个通道(通常每个 CPU 核心一个通道),要处理的数据分解为不重叠的范围,这些范围由这些通道并行处理 4。诸如 Repartition 和 Distribute 等交换运算符确保工作负载在这些并行通道之间保持平衡 4。这通过有效地利用单台服务器上的所有可用 CPU 核心来实现垂直扩展 4。
-
多节点并行化: 对于分片表上的查询,最初接收查询的服务器(启动节点)会将尽可能多的查询执行下推到持有各个分片的其他节点 2。远程节点可以在其本地分片上执行过滤、聚合甚至整个查询,然后再将结果发送回启动节点进行最终聚合。这允许在服务器集群中水平扩展查询处理能力 27。
-
2.3.3 查询优化技术 1
ClickHouse 采用广泛的标准查询优化技术,包括常量折叠、公共子表达式消除、谓词下推(将过滤器移动到更靠近数据源的位置)以及重新排序操作以提高效率 9。查询优化器利用主键索引来高效地评估 WHERE 子句条件,从而允许快速的二分搜索来识别相关的数据范围,而不是进行全列扫描 2。跳跃索引用于进一步优化查询执行,允许 ClickHouse 避免读取已知不满足查询过滤条件的整个数据块 2。高度优化的哈希表具有各种实现(包括两级布局和特定于字符串的优化),用于高效的 GROUP BY 操作和连接 9。ClickHouse 支持所有标准的 SQL 连接类型(INNER、LEFT、RIGHT、FULL、CROSS),并提供各种连接算法,包括哈希连接、排序-合并连接和索引连接,以及用于分布式查询的并行变体,如共享分区哈希连接 9。优化器根据所涉及表的大小和可用资源选择最合适的连接算法。 -
2.3.4 可选代码编译 2
ClickHouse 利用基于 LLVM 的运行时代码生成(或 JIT 编译)将查询执行计划中相邻的操作符动态编译成高度优化的机器代码 2。这项技术减少了虚函数调用的开销,并允许编译器执行进一步的优化,例如将中间数据保存在 CPU 寄存器中并改进分支预测,从而为计算密集型查询带来了显著的性能提升 9。
列式存储和向量化执行的结合 9 是分析查询处理的强大范例。通过对列数据的连续块进行操作,ClickHouse 最大化了数据局部性,提高了缓存命中率,并能够高效地使用 SIMD 指令,与传统的面向行的系统相比,为分析工作负载带来了数量级的性能提升。在分析查询中,通常只需要对表中的少数几列执行聚合和过滤操作。列式存储确保只从磁盘读取相关的列。向量化执行然后利用这种连续的列数据,通过以大块处理数据,使 CPU 能够更高效地工作,并减少处理单个行的开销。这种协同作用是 ClickHouse 速度的关键原因。多级并行化策略 2 使 ClickHouse 能够有效地进行垂直扩展(通过利用单台机器上的所有核心)和水平扩展(通过将查询分布到节点集群中)。这种可伸缩性对于处理 VLDB 论文中概述的“海量数据集”挑战至关重要 1。现代服务器通常拥有许多 CPU 核心,而分析数据集可能会变得非常大,需要分布式处理。ClickHouse 在指令级别(SIMD)、核心级别(多核)和节点级别(多节点)并行执行查询的能力确保了它可以利用所有可用的计算资源来快速处理查询,无论数据大小或查询复杂性如何。ClickHouse 精密的查询优化器 1 在将用户编写的 SQL 查询转换为高效的执行计划方面发挥着至关重要的作用。它利用索引、数据跳过和选择最佳连接算法的能力对于在不需要用户手动调整每个查询的情况下获得良好的性能至关重要。理解如何编写优化器可以有效处理的查询对于后端工程师仍然很重要。查询优化器充当查询处理层的“大脑”。它分析查询和可用的数据和元数据,以确定检索所需结果的最有效操作序列。这包括决定使用哪些索引,如何在管道中尽早过滤数据,以及哪种连接算法性能最佳。一个精心设计的优化器可以自动处理许多性能考虑因素,使使用者能够专注于其查询的逻辑。可选的 JIT 编译功能 2 代表了一种先进的优化技术,可以通过生成针对特定查询和数据定制的机器代码,为某些类型的查询提供显著的性能提升。这表明 ClickHouse 对性能的持续追求及其采用尖端技术的意愿。JIT 编译可以通过将查询执行计划的部分直接翻译成 CPU 可以执行的本机机器代码来消除解释指令的开销。这可以加快执行速度,尤其对于查询中计算密集型的表达式或循环。虽然并非总是必需,但它是 ClickHouse 可以为要求苛刻的分析工作负载利用的强大工具。
-
2.4 集成层描述 1
ClickHouse 提供了丰富的集成能力,提供了超过 50 个表函数和表引擎来连接各种外部系统 1。这些系统包括关系数据库(如 MySQL 和 PostgreSQL)、消息队列(如 Kafka)、对象存储(如 S3)以及各种数据湖。表函数提供了一种在单个查询的范围内临时访问外部数据的方式,而无需在 ClickHouse 中创建持久表 2。表引擎允许在 ClickHouse 中创建表示驻留在外部系统中的数据的持久本地表 2。这些引擎可以以被动模式(将查询转发到外部系统)或主动模式(定期拉取数据或订阅数据流)运行。数据库引擎提供了一种将远程数据库模式中的所有表映射到 ClickHouse 中的机制,从而可以轻松地跨不同的数据库系统查询数据 2。ClickHouse 中的字典可以使用集成表函数或引擎从外部数据源填充,从而为在查询处理期间执行查找和丰富数据提供了一种有效的方式 2。ClickHouse 本身支持超过 90 种不同的数据格式,用于读取和写入数据 1,包括常见的格式如 CSV、JSON、Parquet、Avro 和 ORC。这种广泛的格式支持有助于与各种工具和系统进行无缝的数据摄取和交换。对于客户端连接,ClickHouse 支持其自身的原生协议、标准的 HTTP 协议,并且还提供了与 MySQL 和 PostgreSQL 的二进制线协议的兼容性 2。这使得各种现有的数据库客户端和工具都可以与 ClickHouse 进行交互。
广泛的集成层 1 使 ClickHouse 成为各种数据源和系统组成的复杂生态系统中的数据分析中心。这减少了数据孤岛,并允许对组织整个数据环境进行统一的查询和分析。在现代数据架构中,数据通常分散在多个专门的系统中。ClickHouse 无需用户首先将所有数据移动到 ClickHouse 中,即可无缝连接和查询来自各种来源(如关系数据库、消息队列和对象存储)的数据的能力,极大地增强了其效用并降低了操作复杂性。这种集成能力对于解决 VLDB 论文中提到的“多样化的数据存储环境”挑战至关重要 1。支持广泛的数据格式 1 显著降低了将数据摄取到 ClickHouse 和从 ClickHouse 提取数据的门槛。这种灵活性使其能够与各种数据生产和消费管道无缝集成,而无需考虑所使用的具体格式。不同的系统和应用程序通常使用不同的数据格式。ClickHouse 对众多常用数据格式(如 CSV、JSON、Parquet 和 ORC)的全面支持确保用户可以轻松地处理来自几乎任何来源的数据,而无需事先执行复杂且耗时的数据转换。这简化了数据工作流程并增强了互操作性。与多种数据库协议(原生、HTTP、MySQL、PostgreSQL)的兼容性 2 使 ClickHouse 更容易被更广泛的开发人员和工具所使用。工程师可以利用他们现有的知识和熟悉的客户端库与 ClickHouse 进行交互,从而缩短了学习曲线并促进了采用。通过支持常用的数据库协议,ClickHouse 允许开发人员使用他们首选的工具和编程语言连接和操作数据库。这减少了学习新协议或使用专用客户端库的需要,从而更容易将 ClickHouse 集成到现有的应用程序和工作流程中。
3. 设计理念和核心原则
ClickHouse 的核心设计理念围绕着为在线分析处理 (OLAP) 工作负载实现高性能和可伸缩性 1。
-
列式存储: 这是 ClickHouse 性能的基础原则。按列而非按行存储数据可以高效地处理查询所需的列,显著提高 I/O 效率和 CPU 缓存利用率 1。由于列中的数据往往更加相似,因此也带来了更好的数据压缩效果 8。其动机在于分析查询通常只涉及对数据子集的聚合或过滤 23。
-
向量化执行: 以批处理(列数据的向量或块)而非逐行的方式处理数据,减少了函数调用的开销,并能够高效地利用 SIMD 指令,从而最大限度地提高 CPU 效率 2。
-
数据跳过: ClickHouse 积极采用各种索引和数据跳过技术(主键索引、表投影、跳跃索引),以最大限度地减少每个查询需要读取和处理的数据量,从而显著提高查询性能 1。
-
MergeTree 架构: 基于 LSM 树思想的 MergeTree 引擎系列是 ClickHouse 设计的核心,通过允许顺序写入和高效的后台数据部分合并,针对高数据摄取率进行了优化 2。
-
并行处理: ClickHouse 旨在利用所有可用的硬件资源,包括多个 CPU 核心(通过多核并行化)和 SIMD 单元(通过向量化执行),以并行执行查询并减少查询延迟 4。对于分片表上的分布式查询,它还利用多节点并行化。
-
可扩展性: 精心设计的集成层使 ClickHouse 能够与各种外部系统和数据格式无缝交互,使其能够适应各种数据架构 1。
-
开发人员还专注于 ClickHouse 整体设计的简洁性和效率,最大限度地减少不必要的组件,以确保可靠性和易用性 37。
列式存储 1 作为一项基本原则的选择,对 ClickHouse 的许多其他设计决策产生了深远的影响,包括向量化执行模型和压缩技术的有效性。这突显了一个核心架构选择如何塑造整个系统。按列存储数据可以更有效地进行压缩,因为列中的数据往往更加同质。它还允许查询引擎仅读取查询所需的列,从而减少 I/O。这种列式布局也非常适合向量化处理,在这种处理中,操作在数据数组上执行,从而提高了 CPU 利用率。因此,使用列式存储的决定是驱动 ClickHouse 许多性能优势的基础要素。
在 ClickHouse 的设计理念描述中,反复强调“最大化硬件利用率” 1 是一个核心主题。这表明 ClickHouse 非常注重性能工程,并渴望从底层基础架构中提取全部潜力。ClickHouse 不仅仅拥有高效的算法;它还旨在利用现代硬件的功能。向量化执行模型、跨多个核心的并行处理以及存储引擎中最小化磁盘寻道和最大化数据局部性的优化都表明,ClickHouse 的设计深刻理解并针对底层硬件进行了优化。这种对硬件效率的关注是 ClickHouse 在分析数据库领域的一个关键区别。
ClickHouse 的设计理念反映出,它明确优先考虑分析工作负载的读取性能,而不是事务工作负载的写入性能 42。这种权衡在 MergeTree 引擎的追加优化特性和复制的最终一致性模型中显而易见。理解这种基本的权衡对于确定 ClickHouse 是否适合给定的用例至关重要。ClickHouse 擅长快速查询和分析大量数据。其架构,特别是 MergeTree 引擎,旨在提高数据摄取的效率,但更侧重于优化数据布局和索引以实现快速读取。这种对读取密集型分析工作负载的关注意味着它可能不是具有高事务需求且需要强一致性和频繁更新的应用程序的最佳选择。
4. 性能优化策略
-
4.1 选择合适的表引擎 2
对于大多数需要高数据摄取和高效查询的常见分析工作负载,MergeTree 引擎是首选 2。当处理只需要最新版本的记录的数据(例如,跟踪实体的最新状态)时,可以使用 ReplacingMergeTree 在合并期间根据指定的版本列或插入顺序自动去重数据 2。对于涉及数据预聚合的场景(通常与物化视图结合使用以加快常见聚合的速度),AggregatingMergeTree 非常有效,因为它在合并过程中根据指定聚合函数将具有相同主键的行合并为聚合后的行 2。其他专门的 MergeTree 引擎,如 SummingMergeTree(通过对指定列求和来聚合具有相同主键的行)和 CollapsingMergeTree(允许有效跟踪可以处于需要显式“取消”或“关闭”的“状态”的事件),则适用于特定的分析模式 10。除了 MergeTree 系列之外,ClickHouse 还提供了其他用于不同目的的表引擎,例如与外部系统(如 Kafka、MySQL)集成或处理特定的数据格式。选择合适的表引擎是优化给定工作负载性能的第一步,通常也是最重要的一步 41。 -
4.2 有效使用主键和跳跃索引 1
在分析查询中,根据最常用的过滤列(在 WHERE 子句中)和排序列(在 ORDER BY 子句中)定义主键 10。如果可能,在主键定义中将基数较低的列放在前面。对于时间序列数据,请考虑在主键中包含基于时间的组件,因为按时间进行过滤很常见 32。在查询中经常使用但不是主键一部分的列上使用跳跃索引 13。根据数据分布和查询模式选择合适的跳跃索引类型:minmax 用于范围查询,set 用于低基数列,bloom_filter 用于高基数列的等值检查,tokenbf_v1/ngrambf_v1 用于文本搜索 14。注意主索引和跳跃索引的粒度设置 (index_granularity) 13。较小的粒度可以提高数据跳过的有效性,但可能会增加索引大小和内存使用。尝试不同的粒度值,以找到适合您的工作负载的最佳平衡。 -
4.3 数据分区 1
根据常用的过滤列(如日期或类别标识符)对表进行分区 2。这允许 ClickHouse 执行分区剪枝,即跳过不包含与查询相关数据的整个分区,从而显著减少扫描的数据量。对于时间序列数据,按月分区通常是一个不错的起点 32。 -
4.4 查询优化技术 1
编写高效的 SQL 查询,避免不必要的操作或复杂的子查询(如果存在更简单的替代方案) 32。为您的需求使用最合适的聚合函数。例如,如果您只需要知道某个值是否存在,请使用 any() 而不是可能更消耗资源的 countDistinct() 44。利用 EXPLAIN 语句(及其各种形式,如 EXPLAIN PLAN 和 EXPLAIN PIPELINE)来理解 ClickHouse 如何执行您的查询,识别潜在的瓶颈,并查看索引是否被有效使用 19。在适当的情况下考虑使用 Nullable 和 LowCardinality 数据类型,以优化存储并可能提高具有许多重复值或大量空值的列的查询性能 32。 -
4.5 硬件考量 1
使用快速存储(如 SSD),因为磁盘 I/O 通常是分析数据库的瓶颈 37。确保您的服务器拥有足够的 RAM,以便 ClickHouse 能够将经常访问的数据缓存在内存中 37。对于大型工作负载,通常建议至少 64GB 的 RAM 37。ClickHouse 旨在随着更多 CPU 核心的增加而良好地扩展,因此使用具有多核处理器的服务器将提高查询并行性和整体性能 4。 -
4.6 数据压缩 1
ClickHouse 的默认压缩(LZ4)非常快,但您可以尝试使用其他压缩编解码器(如 ZSTD)以获得更高的压缩率,尽管压缩速度会略有下降 8。高效的压缩可以降低存储成本并提高 I/O 性能。 -
4.7 查询编译 2
对于经常执行且计算密集型的查询,考虑启用查询编译(compile_expressions = 1 设置),以通过生成优化的机器代码来潜在地获得显著的性能提升 2。 -
4.8 批量插入 11
在将数据摄取到 ClickHouse 中时,目标是以较大的批次插入数据,而不是许多小的单独插入。这对于 MergeTree 引擎来说更有效,因为它创建的数据部分更少,从而减少了后台合并的开销并提高了查询性能 11。考虑使用异步插入以进一步优化 36。
ClickHouse 中有效的性能优化需要深入理解其架构,特别是 MergeTree 引擎及其索引机制。仅仅增加硬件可能并不总能产生所需的结果。一个战略性的方法,包括模式设计、索引、查询调优和硬件考虑因素,对于最大化性能至关重要。ClickHouse 的性能高度依赖于数据模式和查询如何设计以利用其独特的功能。例如,选择不当的主键或缺少适当的跳跃索引可能会抵消其列式存储和向量化执行的优势。因此,后端工程师需要投入时间来理解这些概念并有效地应用它们。各种 EXPLAIN 语句选项 19 的可用性提供了强大的内省能力,用于理解查询执行。定期使用这些工具对于识别瓶颈和验证索引和分区剪枝等优化是否按预期工作至关重要。EXPLAIN 语句允许工程师查看 ClickHouse 执行查询的逐步过程。通过分析输出,他们可以识别耗时过长的阶段,确定查询是否正在利用可用的索引,并了解数据如何在不同的线程和节点之间处理。这种详细的洞察对于性能故障排除和优化非常宝贵。考虑 Nullable 和 LowCardinality 数据类型 32 的建议突显了 ClickHouse 对高效存储和处理的关注。适当地使用这些类型可以显著减少内存使用,并可能加快查询执行速度,尤其对于具有特定数据特征的列。Nullable 允许 ClickHouse 有效地存储空值,而 LowCardinality 则针对具有相对少量不同值的列进行了优化。通过在适用时使用这些类型,工程师可以减少其数据所需的存储量,并通过启用查询引擎中的特定优化来潜在地提高查询性能。
5. 设计权衡与考量
-
5.1 一致性与性能 20
ClickHouse 优先考虑分析工作负载的卓越性能,这在数据一致性方面带来了一些权衡。虽然它提供了诸如同步复制之类的功能,但默认行为倾向于最终一致性,以最大限度地减少延迟并最大化吞吐量 2。对于事务完整性,ClickHouse 为单个查询提供快照隔离,确保查询在其启动时看到数据的一致性视图 2。然而,它不提供传统意义上的完整 ACID 事务支持,尤其是在影响相同数据的多个并发写入操作的情况下 2。JOIN 操作虽然受支持,但在 ClickHouse 中可能成为性能瓶颈,尤其是在处理大型表时。诸如非规范化(由于潜在的冗余和对压缩的影响,应谨慎使用)、利用物化视图进行数据预连接以及使用字典进行维度表的查找等策略可以帮助缓解这些限制 33。JOIN 中表的顺序也会显著影响性能 33。 -
5.2 事务支持的局限性 42
ClickHouse 明确不是为需要高并发、短小原子事务和强一致性保证的在线事务处理 (OLTP) 工作负载而设计的 42。它的优势在于处理大型数据集上的复杂分析查询。与传统的关联数据库管理系统 (RDBMS)(如 PostgreSQL 或 MySQL)相比,ClickHouse 对复杂的事务操作的支持有限,包括诸如具有回滚功能的多语句事务等功能 43。 -
5.3 强调追加式工作负载 2
ClickHouse 的架构,特别是 MergeTree 引擎,针对主要追加数据且很少更新或删除数据的工作负载进行了高度优化 2。虽然通过诸如 mutation 和轻量级删除之类的功能支持更新和删除,但这些操作可能相对昂贵,尤其是涉及重写数据部分的 mutation。因此,ClickHouse 在处理不可变数据或不经常更新的数据时最有效。 -
5.4 模式刚性 43
由于其专注于分析工作负载的性能优化,与某些其他数据库系统相比,ClickHouse 往往具有更刚性的模式设计 43。对大型表进行重要的模式更改可能是一个更复杂的过程。虽然 ClickHouse 支持各种数据类型,但其主要重点是那些针对分析查询优化的数据类型。与更通用的数据库相比,对高度自定义或复杂数据结构的支持可能更有限 43。 -
5.5 复杂性 9
ClickHouse 中提供的广泛的功能和配置选项,虽然提供了极大的灵活性和强大功能,但也可能在管理、调优和理解给定工作负载的最佳设置方面引入复杂性 9。
ClickHouse 的设计权衡明确地将分析查询的查询性能和可伸缩性置于强事务一致性和数据可变性之上。后端基础架构工程师在考虑将 ClickHouse 用于其应用程序时,需要敏锐地意识到这些权衡,并相应地设计其数据管道和查询模式。ClickHouse 的架构是一个明确的选择,旨在擅长一个特定的领域——快速分析处理。这种侧重导致了其他方面的妥协,例如与传统事务数据库相比,一致性模型较弱。认识到这些局限性对于做出关于何时使用 ClickHouse 以及如何将其集成到更大的数据架构中的明智决策至关重要。例如,一个应用程序可能会使用传统的 RDBMS 进行事务操作,而使用 ClickHouse 对该数据进行分析报告。ClickHouse 的追加优化特性 2 对数据的管理方式产生了重大影响。后端工程师应努力设计主要追加数据的摄取管道,并尽量减少频繁更新或删除的需求,因为这些操作会影响性能。可能需要采用诸如使用 ReplacingMergeTree 通过插入处理更新或在非高峰时段执行批量更新之类的策略。虽然 ClickHouse 提供了强大的功能和优化,但其复杂性 9 意味着实现最佳性能通常需要深入了解其内部工作原理和仔细的调优。后端工程师应准备好投入时间学习 ClickHouse 的配置选项、索引策略和查询优化技术,以充分利用其功能。
6. 从 ClickHouse 学习:可应用的思想和示例
-
列式存储原则: 列式存储对于分析查询的效率 1 可以启发其他数据处理系统或自定义工具的设计,在这些系统中,只有一部分数据属性经常被访问。例如,在构建自定义日志分析工具时,以列式格式存储日志可以显著提高专注于特定日志字段的查询的性能。
-
向量化处理概念: 向量化处理的性能优势 2 可以应用于数据库之外的其他数据处理管道。考虑通过以块或向量的形式处理数据来优化 ETL/ELT 过程或数值计算中的数据转换步骤,以利用 SIMD 指令和提高 CPU 缓存利用率。
-
数据跳过策略: ClickHouse 采用的各种数据跳过技术 1 为优化其他系统中的数据检索提供了宝贵的经验。考虑如何在内存数据存储或分布式缓存系统中使用轻量级索引或元数据存储来避免根据查询谓词处理或检索不相关的数据。
-
合并时转换: 在数据合并期间作为后台进程执行数据转换的想法 2 可以应用于其他场景,以减少实时数据摄取或查询服务的负载。例如,在时间序列数据收集系统中,考虑将数据聚合或汇总实现为定期运行的后台任务,而不是在查询时执行这些计算。
-
系统设计中的权衡: ClickHouse 的设计突显了根据应用程序的特定需求,在不同系统属性(如一致性、性能和可伸缩性)之间进行有意识权衡的重要性 33。在设计任何基础架构系统时,仔细考虑主要用例,并就优先考虑哪些属性以及在何处可以接受妥协做出明智的决策。例如,根据应用程序对陈旧数据的容忍度,为分布式缓存系统选择适当的一致性级别就是一个类似的权衡考虑。
ClickHouse 作为一款专业的 OLAP 数据库所取得的成功 8 强调了构建高度优化以适应特定用例的系统的重要性。它所采用的设计原则和优化可以作为构建其他高性能数据处理系统(即使它们不是完整的数据库)的宝贵经验。与其尝试构建一个万能的数据解决方案,ClickHouse 展示了专注于特定类型的工作负载(分析查询)并定制架构和实现以在该领域表现出色的强大之处。这种专业化带来了显著的性能优势,并且可以成为设计具有特定性能要求的其他基础架构组件的指导原则。存储和计算分离的架构模式,以 ClickHouse Cloud 和其他现代数据平台 2 为例,是构建可扩展且经济高效的云数据基础架构的一个有价值的概念。这种分离允许根据需求独立扩展这些资源,并可以提高资源利用率和成本效益。通过解耦存储和计算,组织可以根据其特定需求独立扩展每个组件。例如,如果一个系统查询流量激增但数据量保持不变,他们可以扩展计算资源而无需配置更多存储。这种分离提供了更大的灵活性,并可以优化资源消耗,从而在云环境中节省成本。ClickHouse 充满活力的开源社区 1 突显了社区协作在推动软件开发中的创新和解决实际挑战方面的重要性。用户和开发人员的积极参与有助于系统的快速发展和改进。开源项目受益于来自不同社区的集体智慧和贡献。这可以更快地识别和解决错误,根据用户需求开发新功能,并创建一个更健壮和经过充分测试的系统。ClickHouse 活跃的社区证明了协作开发在创建成功且被广泛采用的软件方面的力量。
一、ClickHouse跳表索引(Skipping Index)的存储结构
ClickHouse的跳表索引是稀疏索引的典型实现,其核心设计围绕数据分块存储展开:
- 索引结构:基于主键或特定字段创建稀疏索引,索引标记间隔存储(如每8192行一个标记),通过多级跳表结构快速定位数据块56;
- 数据块存储:数据按主键排序后划分为固定大小的块(默认8192行),每个块头部存储该块的统计信息(如min/max值),配合索引实现高效过滤56;
- 压缩机制:每个数据块独立压缩(默认LZ4算法),压缩后合并写入文件系统,降低存储成本的同时减少I/O压力5。
二、与普通数据库索引的核心差异
| 特性 | ClickHouse索引 | 传统数据库(如MySQL) |
|---|---|---|
| 索引密度 | 稀疏索引(间隔存储) | 密集索引(逐行记录) |
| 存储开销 | 存储空间占用低,适合海量数据 | 存储开销高,数据膨胀明显 |
| 适用场景 | OLAP场景,侧重范围查询和聚合 | OLTP场景,侧重点查询和事务 |
| 数据更新影响 | 不支持高频更新,索引维护成本低 | 支持实时更新,但索引维护开销高 |
三、物化视图与数据冗余的关联
- 物化视图的本质:存储预计算结果的冗余表,通过空间换时间提升查询性能23;
- 与索引的协同:
- 物化视图通过独立的存储结构和索引(如AggregatingMergeTree引擎),实现聚合结果的快速查询36;
- 数据冗余带来的存储成本可通过合并机制(如SummingMergeTree)部分优化3;
- 典型应用场景:高频聚合查询(如实时统计报表)、多表关联的中间结果缓存37。
四、技术栈整体交互流程示例
写入流程: 数据 → 主表(MergeTree引擎) → 触发物化视图计算 → 结果写入物化视图表(含独立索引)
查询流程: 用户查询 → 优先命中物化视图(通过其索引快速响应) → 若未命中,回退到主表稀疏索引定位数据块
7. 结论
总而言之,ClickHouse 是一款卓越的高性能开源 OLAP 数据库,其精心设计旨在为海量数据集提供闪电般快速的分析能力。其关键的架构特性,包括列式存储、向量化执行、MergeTree 引擎系列以及具有可选代码编译的复杂查询处理层,使其能够在要求苛刻的分析工作负载中表现出色。
后端基础架构工程师可以从理解 ClickHouse 的设计原则和优化策略中获得显著的价值。对列式存储、向量化处理、数据跳过和合并时转换的深入了解可以为其他数据密集型系统的设计和优化提供借鉴。
虽然 ClickHouse 提供了卓越的性能和可伸缩性,但务必了解其固有的设计权衡,尤其是在一致性、事务支持以及其对追加式工作负载的强调方面。选择合适的工具并理解 ClickHouse 的优势和局限性对于构建健壮高效的数据基础设施至关重要。
通过学习 ClickHouse 的设计理念及其为解决现代分析数据管理挑战而提出的创新方案,后端工程师可以提高其构建和管理各种领域高性能数据系统的能力。
表 1:MergeTree 表引擎比较
| 引擎名称 | 描述 | 主要用例 | 主要特点 |
| MergeTree | 最常用的通用引擎,适用于高摄取率和海量数据的分析工作负载。 | 日志分析,点击流数据,时间序列数据。 | 基于主键排序,支持分区,数据复制,多种统计和采样方法。 |
| ReplacingMergeTree | 在合并过程中删除具有相同主键的重复项,保留最新版本。 | 数据去重,仅保留最新状态的场景。 | 基于版本列或插入顺序进行去重。 |
| AggregatingMergeTree | 在合并过程中根据指定的聚合函数聚合具有相同主键的行。 | 预聚合数据,与物化视图结合使用。 | 存储聚合状态,合并时进行增量聚合。 |
| SummingMergeTree | 在合并过程中将具有相同主键的行的指定数值列的值相加。 | 聚合指标数据,例如计数或总和。 | 自动对指定列进行求和。 |
| CollapsingMergeTree | 用于处理可以“折叠”或“取消”的事件流,通过使用符号列来跟踪状态变化。 | 事件状态跟踪,例如订单的创建和取消。 | 使用符号列进行状态管理。 |
表 2:ClickHouse 跳跃索引类型
| 索引类型 | 描述 | 适用场景 | 主要参数 |
| minmax | 存储每个数据块中表达式的最小值和最大值。 | 对松散排序的数据进行范围查询。 | 无。 |
| set(N) | 存储每个数据块中最多 N 个不同的值。 | 每个块内基数较低的列。 | N:要存储的最大不同值数量。 |
| bloom_filter([bf_size, hash_functions, random_seed]) | 一种概率数据结构,用于快速判断一个值是否可能存在于一个数据块中。 | 对高基数列进行等值检查。 | bf_size:Bloom 过滤器的大小(字节),hash_functions:哈希函数的数量,random_seed:随机种子。 |
| tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, seed) | 针对字符串中的标记(由非字母数字字符分隔)进行优化的 Bloom 过滤器。 | 日志数据,文本搜索,按单词过滤。 | size_of_bloom_filter_in_bytes:Bloom 过滤器的大小(字节),number_of_hash_functions:哈希函数的数量,seed:随机种子。 |
| ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, seed) | 针对字符串中的 n-gram(连续的字符序列)进行优化的 Bloom 过滤器。 | 文本搜索,模糊匹配。 | n:n-gram 的长度,size_of_bloom_filter_in_bytes:Bloom 过滤器的大小(字节),number_of_hash_functions:哈希函数的数量,seed:随机种子。 |
表 3:ClickHouse 与传统数据库的关键差异
| 特性 | ClickHouse | 传统行式 OLTP 数据库(例如,PostgreSQL,MySQL) |
| 存储格式 | 列式 | 行式 |
| 主要用例 | OLAP(在线分析处理) | OLTP(在线事务处理) |
| 查询处理 | 向量化 | 基于行 |
| 事务支持 | 快照隔离 | ACID |
| 数据可变性 | 追加优化 | 可变 |
| 可伸缩性 | 水平扩展(分析) | 垂直扩展(事务) |
ClickHouse 的设计哲学是极致的性能和高吞吐量,尤其是在分析型查询(OLAP)场景下。为了实现这个目标,它在事务处理方面做出了有意识的权衡。
ClickHouse 对事务支持的详细说明:
- 有限的原子性: ClickHouse 提供了原子性写入的能力,这意味着在单个
INSERT语句中,要么所有数据都成功写入,要么都不写入。这通过内部的块(block)机制保证。 - 缺乏 ACID 中的隔离性 (Isolation): ClickHouse 主要关注高并发读取,写入操作通常是批量进行。它不提供严格的事务隔离级别,例如可串行化(Serializable)或可重复读(Repeatable Read)。在写入过程中,可能会出现脏读(Dirty Reads)的情况,即查询可能会读到尚未提交的数据块。不过,已经成功写入的数据块对于后续查询是可见的。
- 不支持跨表事务: ClickHouse 不支持跨多个表的原子性操作。如果你需要同时修改多个表并保证一致性,需要在应用层进行复杂的逻辑控制。
- 不支持回滚 (Rollback) 完整的事务: 虽然 ClickHouse 在写入失败时不会留下部分数据,但它没有提供显式的
ROLLBACK语句来撤销已经成功写入的数据(在同一个INSERT语句的上下文中)。
为什么这样设计?
- OLAP 场景的特点: 分析型数据库通常面临海量数据的查询和聚合操作,对写入性能的要求相对较低,但对读取性能和并发能力要求极高。复杂的事务管理会带来额外的锁开销和性能损耗,这与 ClickHouse 的设计目标相悖。
- 简化架构: 放弃复杂的事务管理可以简化数据库的内部架构,减少锁的竞争,提高整体的吞吐量和查询性能。
- 批量写入优化: ClickHouse 鼓励批量写入数据,这种方式更适合追加式的数据更新,也减少了事务管理的复杂性。
- 数据一致性的权衡: 在某些对数据一致性要求不是绝对严格的分析场景下,为了追求极致的性能,可以接受一定的最终一致性。
ClickHouse 的哲学再次强调:极致性能优先,牺牲复杂事务。 它专注于提供快速、高效的数据分析能力,为此牺牲了传统关系型数据库中复杂的事务特性。在需要强事务一致性的场景下,可能需要结合其他数据库或在应用层实现相应的保障机制。
引用的著作
-
Architecture Overview | ClickHouse Docs, 访问时间为 四月 22, 2025, Architecture Overview | ClickHouse Docs
-
ClickHouse - Lightning Fast Analytics for Everyone - VLDB Endowment, 访问时间为 四月 22, 2025, https://www.vldb.org/pvldb/vol17/p3731-schulze.pdf
-
[Paper Reading] ClickHouse - Lightning Fast Analytics for Everyone - Taro Event, 访问时间为 四月 22, 2025, [Paper Reading] ClickHouse - Lightning Fast Analytics for Everyone - Taro Event
-
ClickHouse - Lightning Fast Analytics for Everyone - GitHub, 访问时间为 四月 22, 2025, https://raw.githubusercontent.com/ClickHouse/clickhouse-presentations/master/2024-vldb/VLDB_2024_presentation.pdf
-
First ClickHouse research paper: How do you make a modern data analytics database lightning-fast?, 访问时间为 四月 22, 2025, First ClickHouse research paper: How do you make a modern data analytics database lightning-fast?
-
Use cases | ClickHouse, 访问时间为 四月 22, 2025, Use cases | ClickHouse
-
VLDB 2024 - ClickHouse: Lightning Fast Analytics for Everyone, 访问时间为 四月 22, 2025, VLDB 2024 - ClickHouse: Lightning Fast Analytics for Everyone
-
ClickHouse Architecture 101—A Comprehensive Overview (2025) - Chaos Genius, 访问时间为 四月 22, 2025, ClickHouse Architecture 101—A Comprehensive Overview (2025)
-
Why is ClickHouse so fast?, 访问时间为 四月 22, 2025, Why is ClickHouse so fast? | ClickHouse Docs
-
MergeTree | ClickHouse Docs, 访问时间为 四月 22, 2025, MergeTree | ClickHouse Docs
-
ClickHouse MergeTree: Configuring Storage Infrastructure & Indexes for Performance, 访问时间为 四月 22, 2025, ClickHouse MergeTree: Storage Infrastructure & Indexing
-
Data storage or what is a MergeTree - Handbook - PostHog, 访问时间为 四月 22, 2025, Data storage or what is a MergeTree - Handbook - PostHog
-
Understanding ClickHouse Data Skipping Indexes, 访问时间为 四月 22, 2025, Understanding ClickHouse Data Skipping Indexes | ClickHouse Docs
-
Use Data Skipping Indices where Appropriate | ClickHouse Docs, 访问时间为 四月 22, 2025, Use Data Skipping Indices where Appropriate | ClickHouse Docs
-
Indexing and data processing in ClickHouse® | Aiven docs, 访问时间为 四月 22, 2025, Indexing and data processing in ClickHouse® | Aiven docs
-
How Data Skipping Indexes are implemented in ClickHouse? - ChistaDATA, 访问时间为 四月 22, 2025, How Data Skipping Indexes are implemented in ClickHouse?
-
Improve query performance with ClickHouse Data Skipping Index - IBM, 访问时间为 四月 22, 2025, Improve query performance with ClickHouse Data Skipping Index | IBM
-
ClickHouse® MergeTree on S3 - Administrative Best Practices - Altinity, 访问时间为 四月 22, 2025, https://altinity.com/blog/clickhouse-mergetree-on-s3-administrative-best-practices
-
ClickHouse: The Key to Faster Insights - CloudRaft, 访问时间为 四月 22, 2025, ClickHouse: The Key to Faster Insights
-
How to achieve data read consistency in ClickHouse?, 访问时间为 四月 22, 2025, How to achieve data read consistency in ClickHouse? | ClickHouse Docs
-
Architecture Overview | ClickHouse Docs, 访问时间为 四月 22, 2025, Architecture Overview | ClickHouse Docs
-
Architecture Overview | ClickHouse Docs, 访问时间为 四月 22, 2025, Architecture Overview | ClickHouse Docs
-
What is ClickHouse: A revolutionary tool for real-time data processing - DoubleCloud, 访问时间为 四月 22, 2025, What is ClickHouse Database? Your Ultimate Guide to Columnar Databases | DoubleCloud
-
Understanding ClickHouse®: Products, architecture, tutorial and alternatives, 访问时间为 四月 22, 2025, https://www.instaclustr.com/education/understanding-clickhouse-products-architecture-tutorial-and-alternatives/
-
Vectorized Query Processing for ClickHouse Performance - ChistaDATA, 访问时间为 四月 22, 2025, Overview of Vectorized Query Processing in ClickHouse
-
State-of-the-art query processing layer | Why is ClickHouse fast? (Part 6) - YouTube, 访问时间为 四月 22, 2025, https://www.youtube.com/watch?v=O5qecdQ7Y18
-
How ClickHouse executes a query in parallel, 访问时间为 四月 22, 2025, How ClickHouse executes a query in parallel | ClickHouse Docs
-
Real-Time Data Analytics Platform - ClickHouse, 访问时间为 四月 22, 2025, Real-Time Data Analytics Platform | ClickHouse
-
Guide for Query optimization | ClickHouse Docs, 访问时间为 四月 22, 2025, Guide for Query optimization | ClickHouse Docs
-
Understanding Query Execution with the Analyzer | ClickHouse Docs, 访问时间为 四月 22, 2025, Understanding Query Execution with the Analyzer | ClickHouse Docs
-
Comprehensive Guide to ClickHouse EXPLAIN - ChistaDATA, 访问时间为 四月 22, 2025, Comprehensive Guide to ClickHouse EXPLAIN
-
A simple guide to ClickHouse query optimization: part 1, 访问时间为 四月 22, 2025, A simple guide to ClickHouse query optimization: part 1
-
Six Months with ClickHouse at CloudQuery (The Good, The Bad, and the Unexpected), 访问时间为 四月 22, 2025, Six Months with ClickHouse at CloudQuery (The Good, The Bad, and the Unexpected) | CloudQuery Blog
-
JIT compilation of queries in ClickHouse - Maksim Kita, 访问时间为 四月 22, 2025, JIT compilation of queries in ClickHouse
-
Why is ClickHouse so fast? Features that make it lightning fast - DoubleCloud, 访问时间为 四月 22, 2025, ClickHouse apeed secrets: Unveiling the fastest data warehouse features | DoubleCloud
-
Turning an OLAP database into a fully-fledged data hub - VLDB 2023 - Ryadh Dahimene, PHD - YouTube, 访问时间为 四月 22, 2025, https://www.youtube.com/watch?v=go3E2drwngQ
-
What is ClickHouse? A Deep Dive into Its Features and Advantages - CelerData, 访问时间为 四月 22, 2025, What is ClickHouse? A Deep Dive into Its Features and Advantages
-
What is Clickhouse? Features, Practices and Implementation Guide - Decube, 访问时间为 四月 22, 2025, What is Clickhouse? Features, Practices and Implementation Guide | Decube
-
Engineering Resources / Columnar databases explained - ClickHouse, 访问时间为 四月 22, 2025, Columnar databases explained | ClickHouse Engineering Resources
-
What is a columnar database? | ClickHouse Docs, 访问时间为 四月 22, 2025, What is a columnar database? | ClickHouse Docs
-
ClickHouse®: A beginner's guide to “the fastest” open source OLAP DBMS - Instaclustr, 访问时间为 四月 22, 2025, https://www.instaclustr.com/blog/clickhouse-a-beginners-guide-to-the-fastest-open-source-olap-dbms/
-
Can I use clickhouse as key-value storage? - Stack Overflow, 访问时间为 四月 22, 2025, https://stackoverflow.com/questions/53973623/can-i-use-clickhouse-as-key-value-storage
-
ClickHouse vs PostgreSQL: Detailed Analysis - RisingWave, 访问时间为 四月 22, 2025, ClickHouse vs PostgreSQL: Detailed Analysis - RisingWave: Open-Source Streaming Database
-
2024 Changelog | ClickHouse Docs, 访问时间为 四月 22, 2025, 2024 Changelog | ClickHouse Docs
-
Why Denormalization Slows You Down in ClickHouse—and What to Do Instead - Glassflow, 访问时间为 四月 22, 2025, Why Denormalization Slows You Down in ClickHouse—and What to Do Instead
-
Migration to ClickHouse® - Altinity, 访问时间为 四月 22, 2025, https://altinity.com/blog/2017-10-23-migration-to-clickhouse
-
Of course it does - it's purpose built for a narrow use case. However it's an ex... | Hacker News, 访问时间为 四月 22, 2025, https://news.ycombinator.com/item?id=28601086
Snowflake vs Clickhouse - Reddit, 访问时间为 四月 22, 2025, https://www.reddit.com/r/snowflake/comments/1cozp88/snowflake_vs_clickhouse/