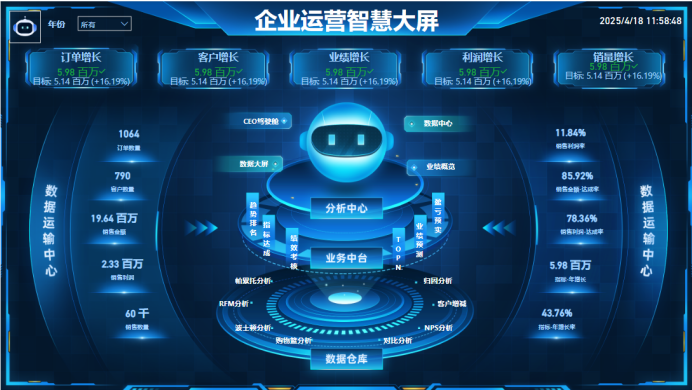
记:全体LRU,ttl LRU,全体LFU,ttl LFU,全体随机,ttl随机,最快过期,不淘汰(八种)
Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
Redis 实现的 LRU 算法的优点:
- 不用为所有的数据维护一个大链表,节省了空间占用;
- 不用在每次数据访问时都移动链表项,提升了缓存的性能;
但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。
Redis 对象头中的 lru 字段,在 LRU 算法下和 LFU 算法下使用方式并不相同。
在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。
- ldt 是用来记录 key 的访问时间戳;
- logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5。
注意,logc 并不是单纯的访问次数,而是访问频次(访问频率),因为 logc 会随时间推移而衰减的。
在每次 key 被访问时,会先对 logc 做一个衰减操作,衰减的值跟前后访问时间的差距有关系,如果上一次访问的时间与这一次访问的时间差距很大,那么衰减的值就越大,这样实现的 LFU 算法是根据访问频率来淘汰数据的,而不只是访问次数。访问频率需要考虑 key 的访问是多长时间段内发生的。key 的先前访问距离当前时间越长,那么这个 key 的访问频率相应地也就会降低,这样被淘汰的概率也会更大。
对 logc 做完衰减操作后,就开始对 logc 进行增加操作,增加操作并不是单纯的 + 1,而是根据概率增加,如果 logc 越大的 key,它的 logc 就越难再增加。
所以,Redis 在访问 key 时,对于 logc 是这样变化的:
- 先按照上次访问距离当前的时长,来对 logc 进行衰减;
- 然后,再按照一定概率增加 logc 的值
redis.conf 提供了两个配置项,用于调整 LFU 算法从而控制 logc 的增长和衰减:
- lfu-decay-time 用于调整 logc 的衰减速度,它是一个以分钟为单位的数值,默认值为1,lfu-decay-time 值越大,衰减越慢;
- lfu-log-factor 用于调整 logc 的增长速度,lfu-log-factor 值越大,logc 增长越慢。