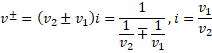网络基础概念(上)![]() https://blog.csdn.net/Small_entreprene/article/details/147261091?sharetype=blogdetail&sharerId=147261091&sharerefer=PC&sharesource=Small_entreprene&sharefrom=mp_from_link
https://blog.csdn.net/Small_entreprene/article/details/147261091?sharetype=blogdetail&sharerId=147261091&sharerefer=PC&sharesource=Small_entreprene&sharefrom=mp_from_link
网络传输的基本流程
局域网网络传输流程图
我们要学习网络通信,就必须得先学习局域网通信的原理,因为无数个局域网通信构成了广域网通信,广域网通信是结果!
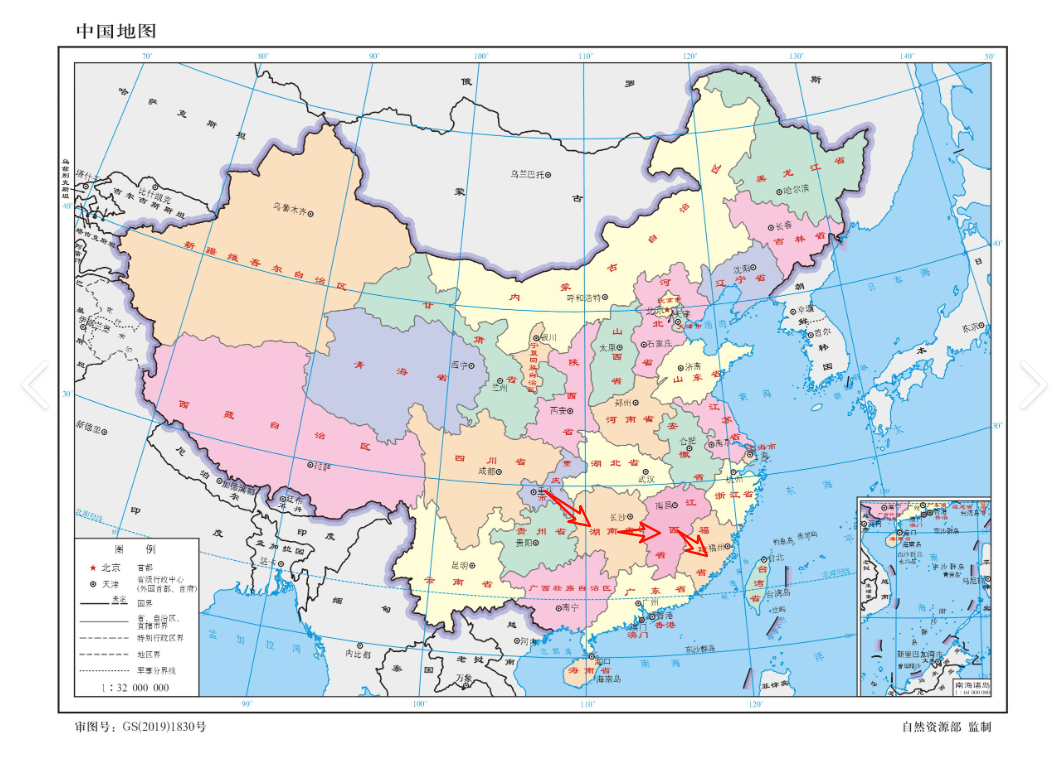
就像我们从重庆到福建,假设是做高铁,需要中转,我们必须先从重庆坐到湖南,从一个子网到另一个子网,宏观上我们是从重庆到福建,但是我们其实是需要经过多个省份的。
所以我们学习网络通信的时候,从重庆到福建,我们得先学会这么从重庆到湖南,我们要学习网络,就需要先学习一个数据包,将来是怎么样在局域网当中进行通信的。
以太网,令牌环网,无线LIN是留下来的几个突出的局域网。
认识MAC地址
在一个局域网当中要通信,首先每台主机都要有自己唯一的标识符,这种标识符我们称之为MAC地址。MAC地址是用来识别数据链路层中相连的节点的,MAC地址是一个48个比特位的数字,即6个字节,一般用16进制数字加上冒号的形式来表示(例如:08:00:27:03:fb:19),是我们网卡当中内置的,全世界的网卡制造商,在生产自己的网卡的时候,需要给网卡带上对应的标识符。虽然我们是讲网络,我们会说网卡有唯一的标识符,但是其实内存,磁盘也有其对应的标识符(磁盘上的唯一标识符叫做序列号)。
在Linux当中,我们使用指令:
ifconfig可以进行查看我们对应主机的网卡的地址。
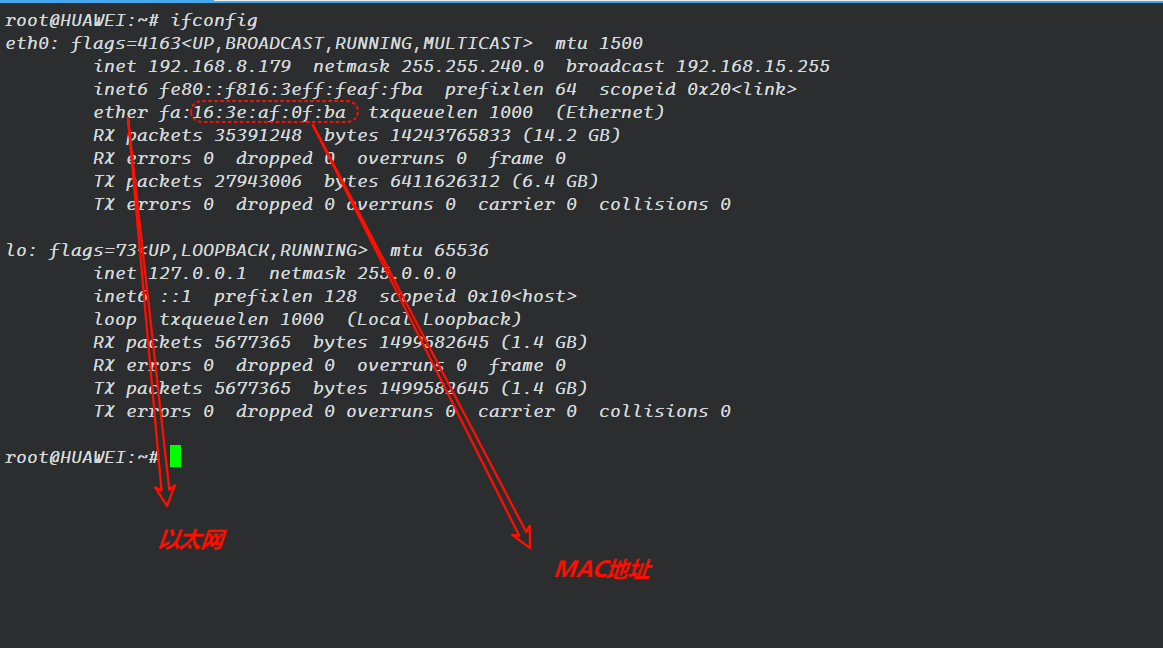
这个数字将来是可以被操作系统通过网卡驱动获取上来的,这是表示标识唯一值的数字。
局域网(以太网为例)通信原理
以太网为什么叫做以太网?
以太网是一种局域网通信的标准,他并不是被用作广域网通信的,为什么名字叫做以太?因为在上个世纪初,很多的科学家们在物理学界都会有一些共识性的东西,比如说声音传播是需要介质的。
在物理学发展历史中,“以太”曾被设想为一种弥漫于整个空间的无形介质,光波等电磁波的传播被认为需要这种介质来充当传播的载体。虽然后来科学的发展证明了“以太”这种物质形态的假设并不成立,但这种概念在当时对人们理解物理现象有一定影响。
以太网借鉴了这种“以太”概念来形象地命名。在以太网中,其通信方式可以类比为数据就像是一种电磁波在空间中的传播,而“以太”就相当于那个虚拟的、无形的传输数据的介质。在以太网里,多台计算机等设备连接到一个共享的通信通道上,这个通道就像是一个虚拟的“以太”空间,数据在这个空间中按照一定的规则进行传输,各设备在这个共享的“以太”中发送和接收数据,就如同在有“以太”存在的环境中传递信号一样,所以这种网络就被命名为以太网。
早期的以太网采用同轴电缆作为传输介质,数据在同轴电缆这种介质中传输时,其传输方式也和电磁波在空间传播有一些相似之处,这也促使了人们用“以太”这个概念来命名这种网络通信方式。
两台主机在同一个局域网内,是否能够直接通信?
两台主机在同一个局域网内是可以直接通信的。例如,在一个公司办公室内搭建了一个局域网,将两台电脑(主机)都连接到同一台交换机上,它们处于同一局域网。这两台电脑可以直接通过共享文件夹来进行通信。其中一台电脑(主机 A)在本地磁盘共享一个文件夹,另一台电脑(主机 B)可以在网上邻居或浏览网络邻居时找到主机 A 上共享的这个文件夹,并且可以访问里面的内容,如打开、复制文件等,这就是两台主机在同一个局域网内直接通信的一种体现。这种通信是基于局域网内的网络协议(如/IP TCP 协议),数据在局域网内部的网络设备之间(像交换机等)直接传输,实现了两台主机之间的通信。
局域网通信的原理确实可以类比为上课的场景。在上课时,老师(信息的发送方)和学生(信息的接收方)在同一间教室(局域网)内,通过约定好的规则(网络协议)进行交流。例如:
-
广播通信:就好比老师提问时说:“同学们,请翻开课本第10页。”这句话是广播给所有学生的,类似于局域网中的广播帧,发送给同一网络内的所有设备。
-
单播通信:老师点名提问某个学生:“小明,你来回答这个问题。”这相当于单播通信,信息只发送给特定的接收者(小明)。
-
数据传输规则:在局域网中,数据会按照一定的协议(比如TCP/IP协议)进行封装和传输,这就如同课堂上有发言规则,学生不能随意打断老师,要举手发言等,保证了通信的有序性。
但是这样的话,就像老师提问小明,小明会受理,但是其他人也会听到,这样消息不就被监听了嘛?是的!这也是我们会听说到的抓包工具抓包,凭什么可以抓到,正是因为局域网当中数据是公开的,所以为了保证数据的安全,我们会面会学习加密!
在课堂上,老师和学生通过名字来识别彼此,确保交流的对象明确。同样,在计算机局域网中,每台主机都有一个唯一的标识符(如MAC地址和IP地址),用于确保数据能够正确地发送到目标主机。
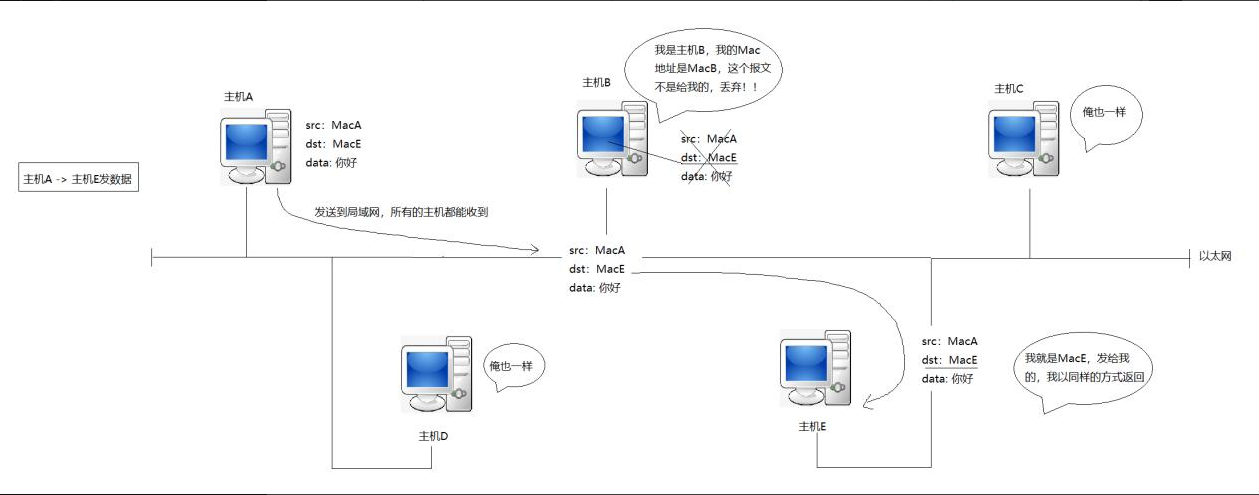
假设今天的目标是主机A向主机E发送数据,主机A的MAC地址就称为MacA,主机E的MAC地址称为MacE。未来主机A就会讲自己要发送的报文添加好,内容一般都会添加原MAC地址,目标MAC地址,还有消息主题。将来要表示这种结构,不就是一个结构体嘛。内容就是结构化数据,也就是一种协议了,所以主机A就将自己对应的消息可以直接发送到网络当中了,发送到网络之后,主机B/C/D/E其实都是知道的,因为他要做泛洪(将数据包发送到网络中的所有节点,不考虑节点是否需要该数据),对于主机B/C/D/E,会提取报文的前两个(src和dst)字段,判断比较MAC地址,不符合就丢弃报文。所以在局域网当中,主机A和E就可以进行直接通信,但是周围是可以有一大批的吃瓜群众的。这就是局域网通信的原理。
在上课的时候,是不允许说老师跟小明说话,小明同时又跟小王说话的,就是在计算机当中,不允许一对以上的主机在通信,我正在向主机发送送信息,这些信息将来都是光电信号,所以我对应的主机A向对应的局域网里发送一段消息是二进制序列,是波形图/电路图,发送出去之后,以太网就一定会有高低电频的变化,当我正在发送的时候,主机B正在给主机D也要发,两个信息就可能会在物理层面上发生干扰。(就像我们往平静的湖面丢下一块石头,就会按照入水点产生波纹,但是在丢一个就会导致波纹的变化)
我们在人多的时候,wife下载东西的速度会比较慢,但是在人少的时候就很快,这正是因为在一个子网当中,入网主机增多了,发生碰撞的概率增加了,所以自己丢包的概率就增加了,导致单位时间之内,能够发出去的报文就减少了,所以网速就变慢了。(局域网==碰撞域)
- 以太网中,任何时刻,只允许一台机器向网络中发送数据
- 如果有多台同时发送,会发生数据干扰,我们称之为数据碰撞
- 所有发送数据的主机要进行碰撞检测和碰撞避免(因为自己发送的自己也是可以看到的,碰撞了就做各种碰撞避免的算法,其实也就是休眠,然后在合适的时机再重发)
- 没有交换机的情况下,一个以太网就是一个碰撞域
- 局域网通信的过程中,主机对收到的报文确认是否是发给自己的,是通过目标 mac 地址判定
- 这里可以试着从系统角度来理解局域网通信原理(临界资源)
以太网/局域网的本质就是共享的资源!任何时刻只允许一台主机向网络当中发送数据,这不就是临界资源吗?所以碰撞检测,碰撞避免不就是在一定程度上维持以太网当中的互斥属性嘛!!!(只不过不是通过加锁的方式,而是无脑先冲,后面的发生的事情再说~~~)
无线LIN的原理和以太网的原理是同样的,无线LIN也是在一个区域当中,基于碰撞检测,碰撞避免的,只不过是通过无线技术来完成的以太网。(校运会,手机卡!!!就是基站就只有一个,大家一直都在发无线LIN,一直碰撞,报文发不出去!!!)
令牌环网就好比上课中,只有持有一个指定瓶子的人才可以说话,也就是说谁拿着这个瓶子(令牌),谁就可以在这个局域网当中通信。所以这个令牌不就是锁嘛!!!
初步明白了局域网通信的原理,再来看同一个网段内的两台主句进行发送消息的过程:
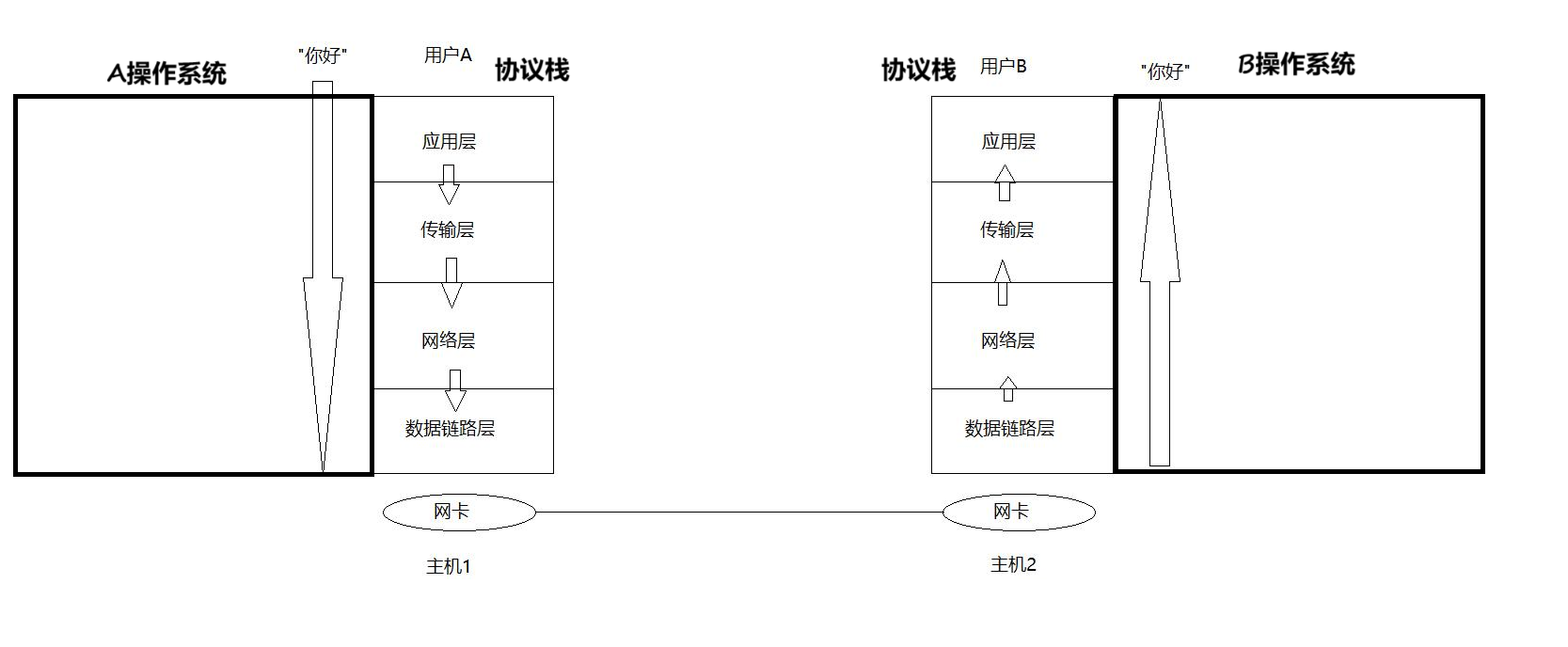
我们以后就不要将主机单纯看成就是一个主机,而是将一个主机看成一个协议栈。
我们发送消息大部分都是人在发送,所以数据("你好")在用户层上开始,自顶向下,贯穿整个协议栈,也就是整个操作系统(通过一系列的系统调用),然后将数据交给网卡,然后将数据发送到对端的网卡,一定是对端的网卡硬件先收到对应的报文,然后自底向上进行交付,到达对应的应用层。
所以:
- 主机之间通信,我们必须认识到,本质就是两个协议栈在通信!!!
- 数据发送的原始动力:是人(大部分)!
目前,我们知道:协议就是定义好的结构化数据的字段!那么每一层都有协议!!!
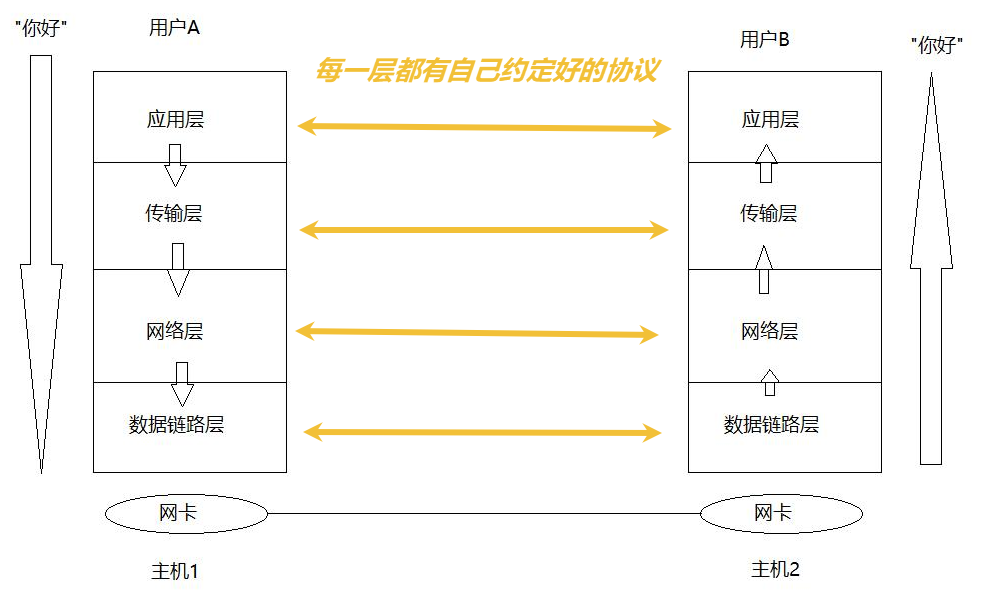
人在打电话的时候,有人与人之间的协议,我们接通之后一般都是"喂",对方也是"喂",没有人教过,为什么我们双发要在用户层"喂"--"喂"一下呢?因为因为我们双方要在应用层上完成协议的交换,这样双方"喂"之后,双方就清楚可以听到了。这就是应用层协议。
打电话的时候,电话本身将来可能会给被人发送各种各样的光电信号,告诉其要建立连接,一发,对方电话就响了,这是两个电话之间的通信。
我想说的是:既然网络协议栈是分层的,不考虑物理层,只考虑其他4层,因为所有的操作系统的网络协议栈都是一样的,所以同层之间就需要有协议。
数据包封装和分用
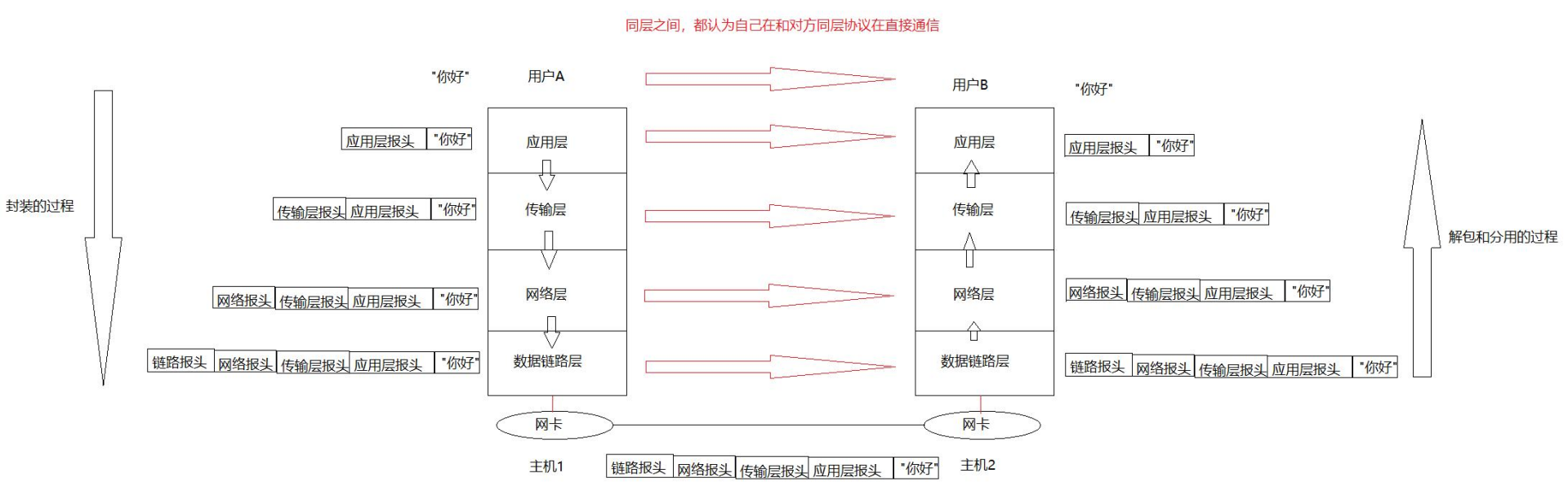
正因为都需要有协议,我们在发送报文的时候,都要把自己的协议信息携带上(我们自己定义的一个结构化字段,表明数据谁发的,发给谁,数据的内容,协议类型等等,别人按照同样的结构化字段来进行解析,这就是一种共识,所以,既然每一层都有协议,我们将报文向下层交付时,就需要将当前层的协议信息携带上,这个协议信息我们称之为对应的协议报头。
补充:协议的本质是一组规则,这些规则往往通过特定的结构体来体现。结构体定义了数据的格式、顺序和含义。协议报头就是这个结构体的一个实例。在发送数据时,按照协议规定的结构体格式创建一个协议报头,填充相应的信息,并将其附加到数据前面。例如,TCP协议定义了一个包含源端口、目的端口、序列号等字段的结构体,发送数据时,根据这些字段创建TCP报头,并填充具体信息。
举个例子:我今天在淘宝上买了一个洗面奶,那么快递员将快递发送到我这里的时候,他并不会手里面拿着拆开的洗面奶,我们收到的是除了一个洗面奶之外,还有一个包装盒,盒子上贴了一张单,收到的是一个包裹。换句话说,当我们收到了一个包裹之后,站在我的角度,我只要这个洗面奶,但是实际上收到的是除了商品之外,还有快递单,这个快递单就是协议包头。
因为每一层都有自己的协议,所以当我们把报文交给下层时,需要将本层的协议信息(通常以报头的形式)添加到报文中。这个过程贯穿整个网络通信的封装过程。以下是详细解释:
- 添加应用层协议报头 :在应用层,根据具体的应用协议(如 HTTP、FTP 等),会在要传输的数据(如用户发送的 “你好” 消息)前面添加应用层报头。这个报头包含了诸如源端口号、目的端口号、数据长度、校验和等信息,用于标识数据的来源和去向等。例如,当用户在浏览器(应用层软件)中访问一个网页时,浏览器会按照 HTTP 协议格式添加相应的报头信息,如请求方法(GET、POST 等)、请求的 URL、HTTP 协议版本等,然后将这些数据和报头一起向下传递给传输层。
- 添加传输层协议报头 :传输层主要的任务是负责端到端的通信。当传输层收到应用层的数据后,会根据所使用的协议(如 TCP 或 UDP)添加对应的传输层报头。以 TCP 为例,报头中包含源端口号、目的端口号、序号、确认号、数据偏移、紧急指针、校验和等信息。这些信息用于确保数据能够可靠地从源端传输到目的端,比如通过序号和确认号来实现数据的可靠传输,接收方可以根据这些信息对数据进行排序和确认,从而保证数据的完整性和有序性。
- 添加网络层协议报头 :网络层负责将数据从源主机发送到目的主机,通常使用 IP 协议(如 IPv4 或 IPv6)。网络层会添加网络层报头,其中包含了源 IP 地址、目的 IP 地址、协议版本、报文长度、TTL(生存时间)等信息。这些信息帮助路由器等网络设备确定数据包的转发路径。例如,当数据从主机 A 发往主机 B 时,网络层会根据路由选择算法,在报头中记录源主机和目的主机的 IP 地址,路由器根据这些 IP 地址将数据包一步步转发到目的主机。
- 添加数据链路层协议报头和报尾 :数据链路层主要负责在同一网络中的不同设备之间进行数据传输。当数据链路层收到网络层的数据后,会添加数据链路层的报头和报尾。报头中包含源物理地址(MAC 地址)、目的物理地址(MAC 地址)、帧类型等信息,用于标识发送和接收的物理设备。报尾通常包含帧校验序列(FCS),用于检测数据在传输过程中是否出现错误。例如,在以太网中,数据帧的报头和报尾就承担了这些功能,确保数据能够在局域网中的不同设备之间正确传输。
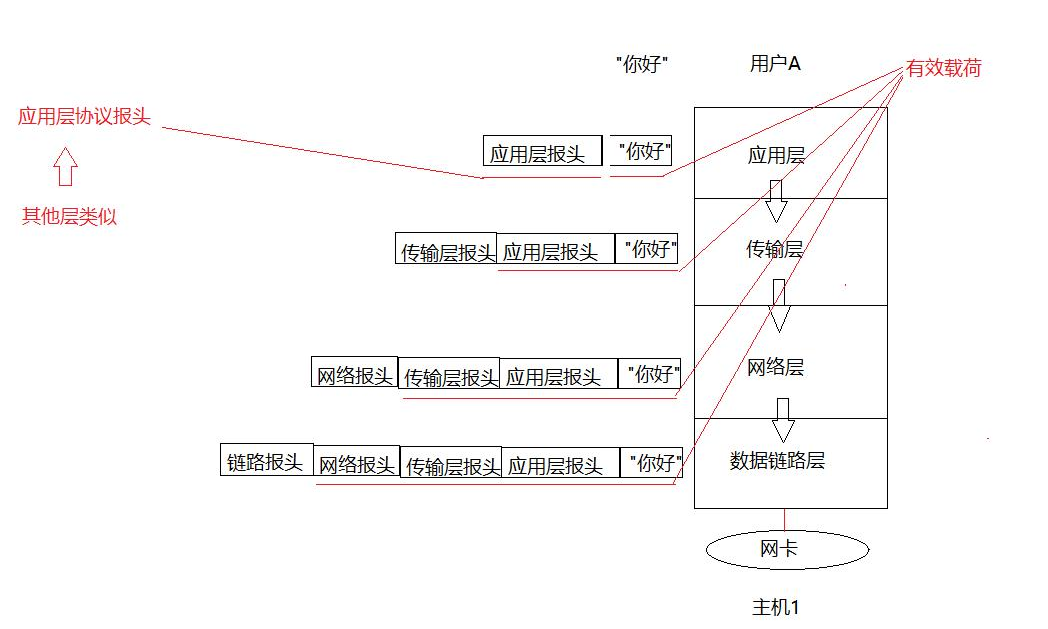
网络通信中,有效载荷指数据包中实际传输的数据部分,不包含协议报头等控制信息。以用户发送的“你好”消息为例,有效载荷就是“你好”,在应用层其是原始消息内容,传输层中有效载荷为应用层的报头和消息内容,网络层中有效载荷为传输层的报头和消息内容,数据链路层中的有效载荷为网络层的报头和消息内容等。有效载荷是传输的核心内容,需经过多层封装和解封装处理,其大小有限,过大会影响传输效率,过小则降低网络利用率。
数据在不同网络层次(应用层、传输层、网络层、数据链路层)之间的封装和解封装过程。每一层都会添加或移除相应的报头,以确保数据能够正确地在网络中传输和被接收方解析。最终,这种分层的协议结构和共识机制确保了网络通信的可靠性和有效性。
我们需要注意:上面的以太网通信,主机A和主机E进行通信主要是在数据链路层,上面的几层并没有考虑。在解封装过程,对于数据链路层,因为同层之间是有共同协议的,所以就可以拿取对应的报文的链路报头,就是对应报头和有效载荷进行分离,这个分离过程我们称之为解包过程。然后将有效载荷传给上层,交付有效载荷给上一层的过程,我们称之为分用过程(头部含有应该交给上层哪一个协议的字段)。最终,同层之间都拿到了对方同层要发送的数据报文,我们称之为在逻辑上,同层之间在直接通信。
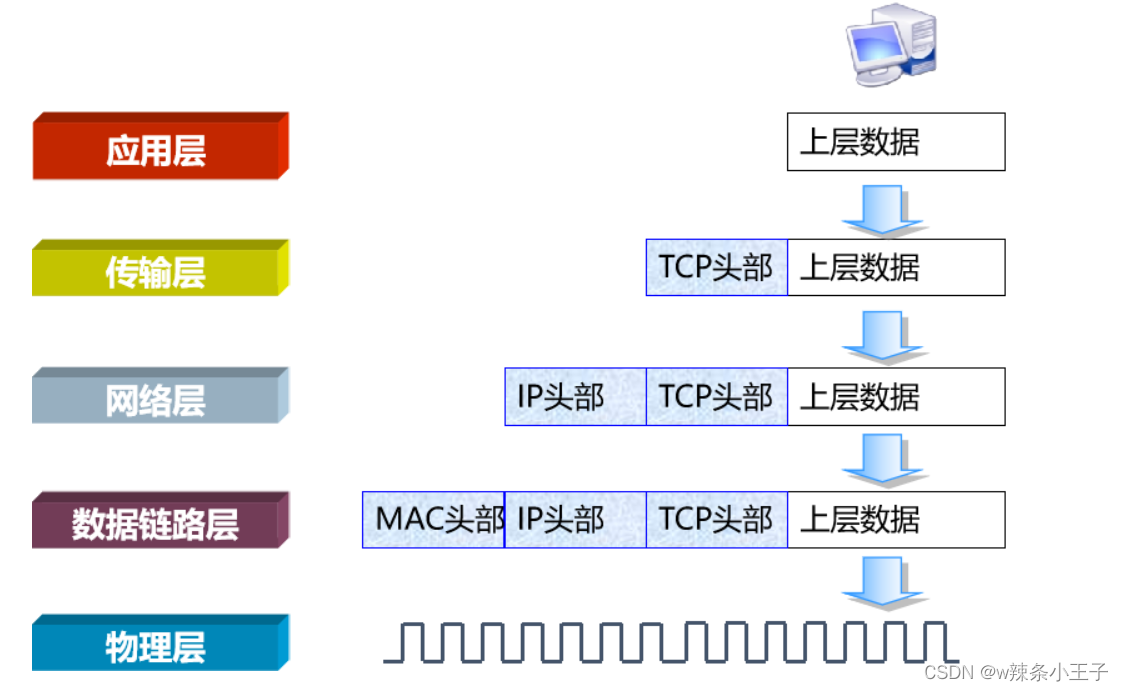
封装:
分用:
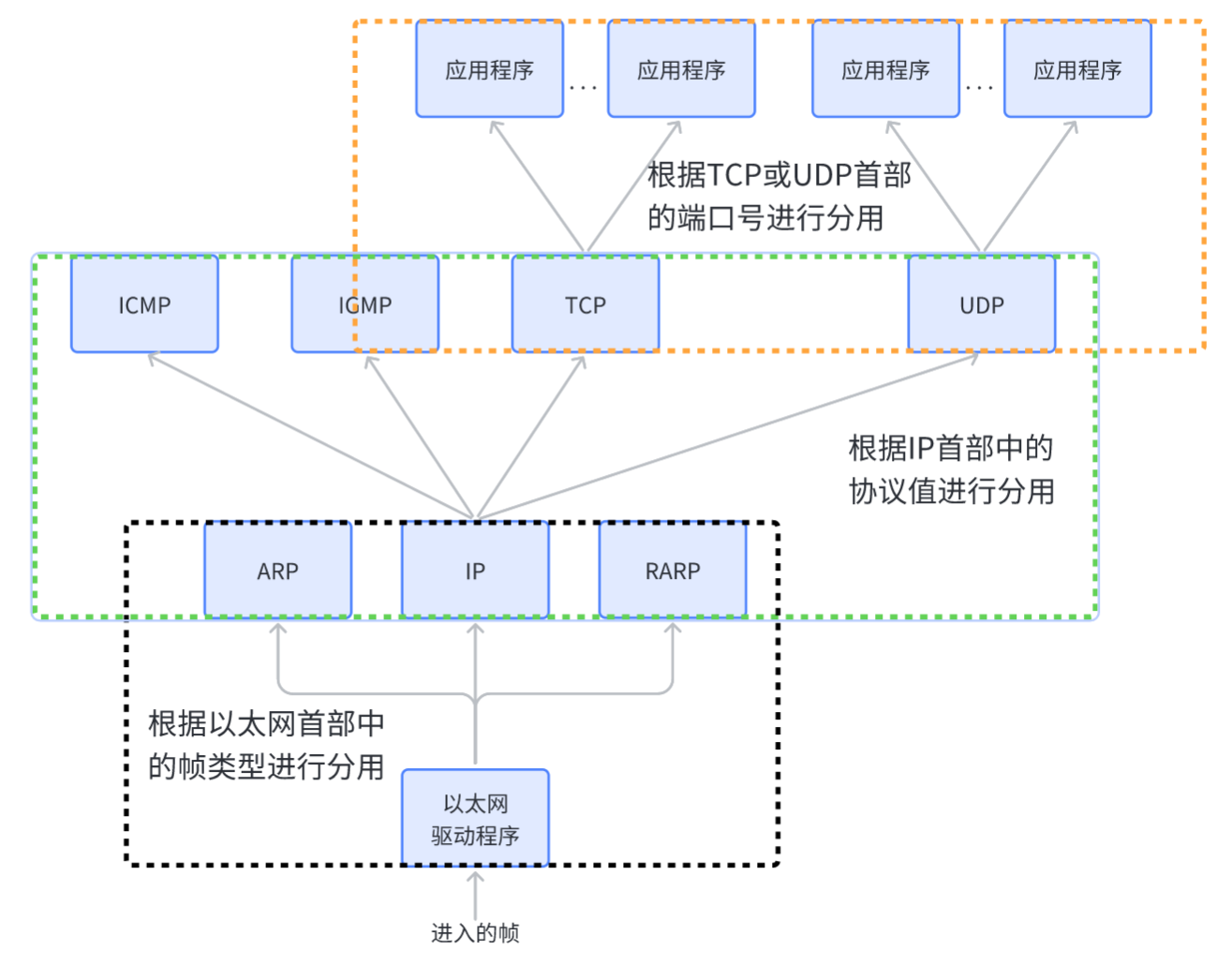
更直观来说,任何一层都只需要关心自己对应的报头,根本就不需要关系有效载荷!!!
所以可以解释说局域网两主机通信(A和E),就是对应主机的数据链路层的通信,链路报头包含src和dst,对于主机B解包,发现该解包后的链路报头的dst不是主机B对应的MAC地址,所以主机B的解包后的有效载荷就不向上交付了,就丢弃了。
我们封装过程和解封装过程可以看成是入栈和出栈!!! (难怪叫做网络协议栈😜😜😜)
综上,我们就知道了报文=报头+有效载荷!!!
对端同层,要先解包:报头和有效载荷进行分离!
我们现在来完善一下不同层的完整报文的叫法:
-
应用层:报文(Message),是用户或应用程序传输的信息,含应用程序协议内容。
-
传输层:TCP称为报文段(Segment),UDP称为用户数据报(User Datagram),含传输层控制信息和应用层数据。
-
网络层:数据报(Datagram),含网络层协议首部信息和传输层数据。
-
数据链路层:帧(Frame),含数据链路层协议的首部、尾部信息和网络层数据。
-
物理层:比特流(Bit Stream),即物理介质上传输的电信号或光信号。
其实对于网卡和数据链路层,特别是网卡,网卡可以通过驱动程序,默认把接收到的报文向上交互,但是网卡有一种模式---混杂模式,网卡混杂模式是工作在数据链路层的一种模式。它允许网卡接收所有经其物理链路的数据包,不限定目标MAC地址。正常情况下,网卡只接收目标MAC地址为本机或广播地址的帧。但开启混杂模式后,会捕获所有经过的帧,无论目标MAC地址是什么。混杂模式常用于网络监控、数据分析等场景,也需注意性能和安全风险。例如,在Linux系统中,可使用sudo ip link set eth0 promisc on启用混杂模式,Windows系统则需通过网卡属性勾选“混杂模式”。(这其实就是抓包工具的原理)
下面有几个问题:
解封装的过程中,需要将对应层的报头进行分离,然后将剩下的有效载荷传给上一层,那么我们网络协议栈中的每一层可不仅仅只有一个协议,会存在多个,就传输层,有TCB,UDP。那么:
将来怎么保证将有效载荷交给上一层确定的那一个协议呢?
不考虑应用层,任何协议,对应的协议报头都需要提供两种字段(能力):
- 报头必须要要能做到和有效载荷分离的能力;
- 报头中必须要包含如何将自己的有效载荷交付给上层的那一个具体的协议。
我们为什么要自顶向下封装?
- 自顶向下:因为发送数据的是用户,用户在最上层,但是最终实现数据发送是通过网卡的,所以必须贯穿操作系统到达底层网卡硬件;(就像我们printf打印消息到显示器也是经过系统调用到底层硬件,让显示器显示出来相应结果)
- 封装:在计算机网络中,数据从应用层向底层传输时,各层依次进行封装,就像给包裹套上不同包装。在应用层,用户数据被添加报头形成报文;到了传输层,TCP或UDP添加控制信息(如端口号)生成报文段或数据报;网络层再加IP地址等信息生成数据报;最后在数据链路层附上MAC地址等生成帧。这些帧被分解为比特流,通过物理层传输。封装确保数据在各层正确流动,最终送达目的地。
从今天开始,我们学习任何协议,都要先宏观上建立这样的认识:
- 要学习的协议,是如何做到解包的?只有明确了解包,封包也就能理解!
- 要学习的协议,是如何做到将自己的有效载荷,交付给上层协议的?
跨网络传输流程图
我们上面谈及的是在同一个局域网下进行通信,但是如果两台主机要进行跨网络通信,那该怎么办?
面对跨网络传输,我们就必须引入一个新的概念---IP地址。
网络中的地址管理 - 认识IP地址
本课程中提到的IP协议默认为IPv4。IP地址是IP协议中用于标识网络中不同主机的地址。对于IPv4来说,IP地址是一个4字节(32位)的整数,通常以“点分十进制”的字符串形式表示,例如192.168.0.1。其中,用点分割的每一个数字表示一个字节,范围是0-255。
IP地址是用来表示全球范围内,主机的唯一性,这里的IP地址其实是公网IP,这是我们会面默认的IP,因为所谓的内网IP或私有IP是在后面的子网划分才能谈。
IP地址我们可以在Linux中使用 ifconfig 指令来进行查看:
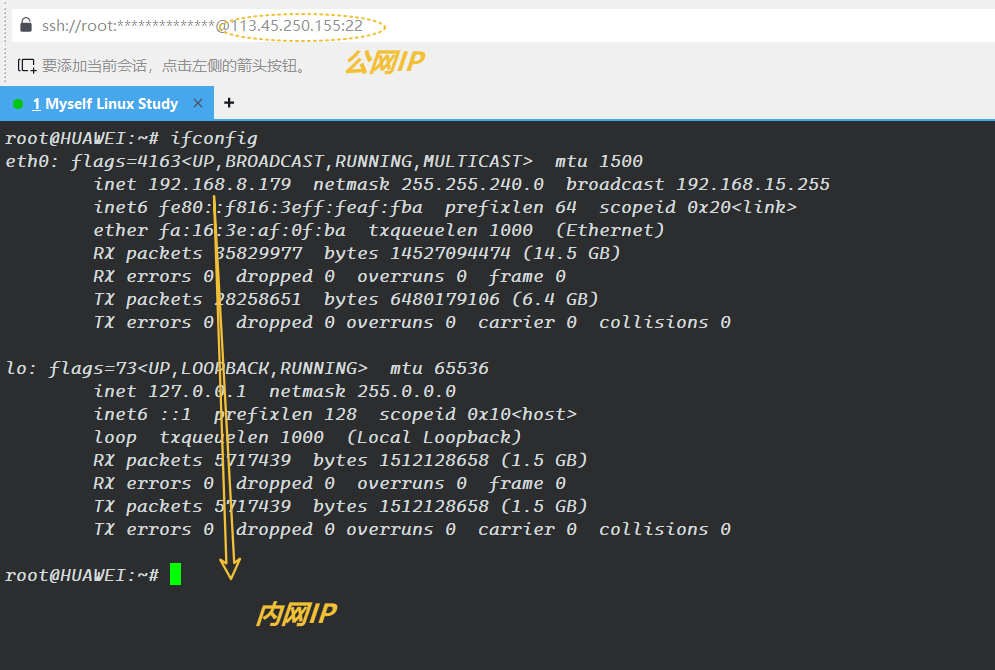
在我们的网络当中,对应的IP地址是32位的,即便是每一个IP对应一个主机的话,也就2的32次方台,使用人数是远远大于IP数的了,所以为了解决IP地址不足的问题,中国提出了IPv6,可是IPv6的推广是极其难得,不过IPv6确实是可以解决IP地址不足的问题。后来,有人就提出了一种技术---网络地址转换(NAT)技术,NAT技术主要用于解决IPv4地址不足的问题,通过将内网的私有IP地址转换为公网IP地址,使得多个内网设备可以共享有限的公网IP地址来访问互联网。
Mac地址是网络接口卡(NIC)的物理地址,由制造商分配,全球唯一。IP公网也是全球范围内,主机的唯一标识,这两者有什么区别吗?两个唯一性标识了,为什么还需要一个IP地址?
所以,我们下面来谈谈MAC地址和IP地址的区别:
Mac地址与IP地址的区别(浅理解的方式,因为才刚开始学)
尽管Mac地址具有唯一性,但它主要用于局域网内的通信。在更广泛的网络环境中,如互联网,需要一种更灵活、可扩展的地址系统来支持跨网络的通信。这就是IP地址的作用。
MAC地址(Media Access Control address)确实可以被看作是网络通信中的“身份标识”,类似于您提到的“东土大唐”和“西天”。在局域网(LAN)中,MAC地址用于标识网络设备(如计算机、路由器、交换机等)的唯一身份。当数据在局域网内传输时,它使用MAC地址来确保数据帧能够准确地从发送者传送到接收者。
IP地址(Internet Protocol address)则记录了网络设备在更广泛网络环境中的位置信息,这包括局域网和广域网(WAN)。IP地址不仅标识设备,还标识设备所在的网络。在您的比喻中,可以将IP地址看作是记录了“前一个驶离地”(如东土大唐)和“下一站”(如花果山)的信息。
具体来说:
-
源IP地址:表示数据包的起始位置,即“前一个驶离地”。在您的比喻中,这可以是东土大唐,表示数据包是从这里发出的。
-
目的IP地址:表示数据包的目的地,即“下一站”。在您的比喻中,这可以是花果山,表示数据包需要到达的地方。
-
路由选择:在数据包从源到目的地的传输过程中,可能会经过多个中间节点(如路由器)。每个节点都会根据数据包的目的IP地址来决定如何转发数据包。这就像是在旅途中,每个站点(如花果山)都会根据目的地(如西天)来决定下一站应该去哪里。
MAC地址:用于局域网内的直接通信,确保数据能够准确无误地从发送者传送到接收者。它标识的是设备的唯一身份。
IP地址:用于在更广泛的网络环境中标识设备,帮助数据包找到从源到目的地的最佳路径,即使这个路径需要跨越多个网络。它记录了数据包的起始位置和目的地,以及可能经过的中间节点。
跨网段的主机的数据传输. 数据从一台计算机到另一台计算机传输过程中要经过一个或多个路由器。
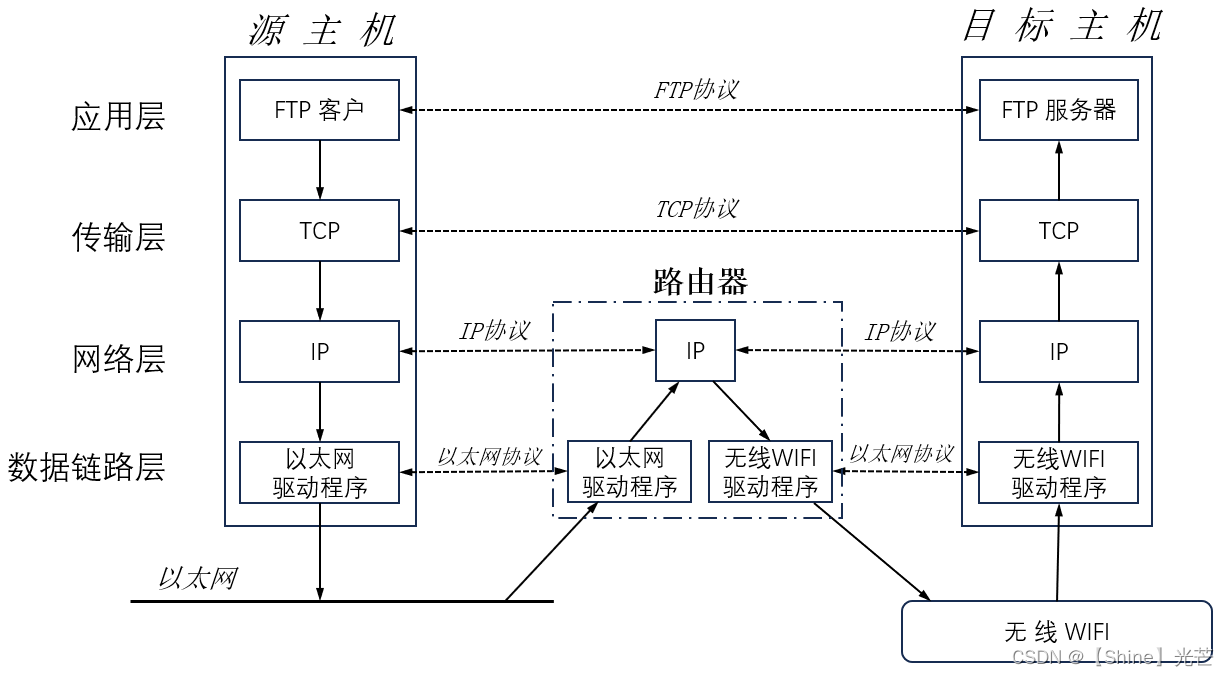
路由器这种设备主要是用来做桥接两个不同的子网,对于路由器,我们可以认为路由器将来需要配上两张网卡,两个网卡分别用来连接两个不同的子网。
也就是:路由器可以用来连接子网!!!
这里补充一下,以后不管是电脑还是手机,会更或者是路由器等设备,我们统称为主机。所以路由器本身也是需要做数据包路由的,也是需要在每一个子网上配IP地址(除了两张网卡外)。
我们看图可以发现,路由器是工作在网络层和数据链路层的。当代路由器已不仅仅工作于此了,当代路由器甚至可以直接支持到应用层了!
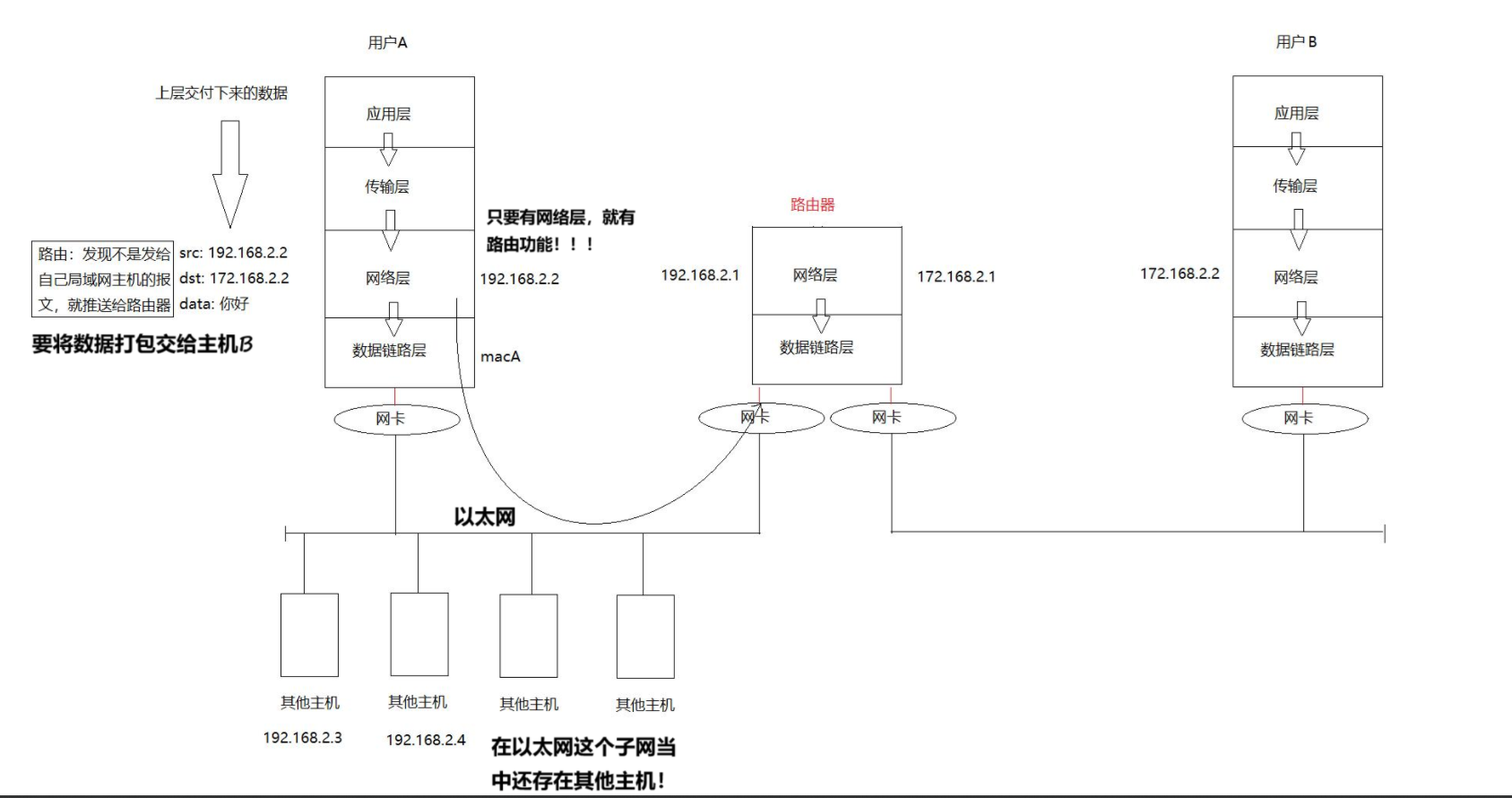
主机A要向主机B发送数据,两台主机的网络部分都是一样的,都有网络层,路由器是工作在网络层的,一旦有网络层,就有路由功能。路由时就发现该信息不是发送到所处子网内的主机的,因为IP地址跟子网内的所有主机的IP地址都对不上(不知道172.168.2.2),那么既然不是推送给自己局域网内的主机的,所以主机A就可以确定就是要推送给路由器了! ,接着就添加报头信息,数据帧(源IP地址和目的IP地址),然后往下传添加报头信息(源MAC地址和目的MAC地址)
所以,有了目的IP,主机就可以判定数据是否要发送给路由器。
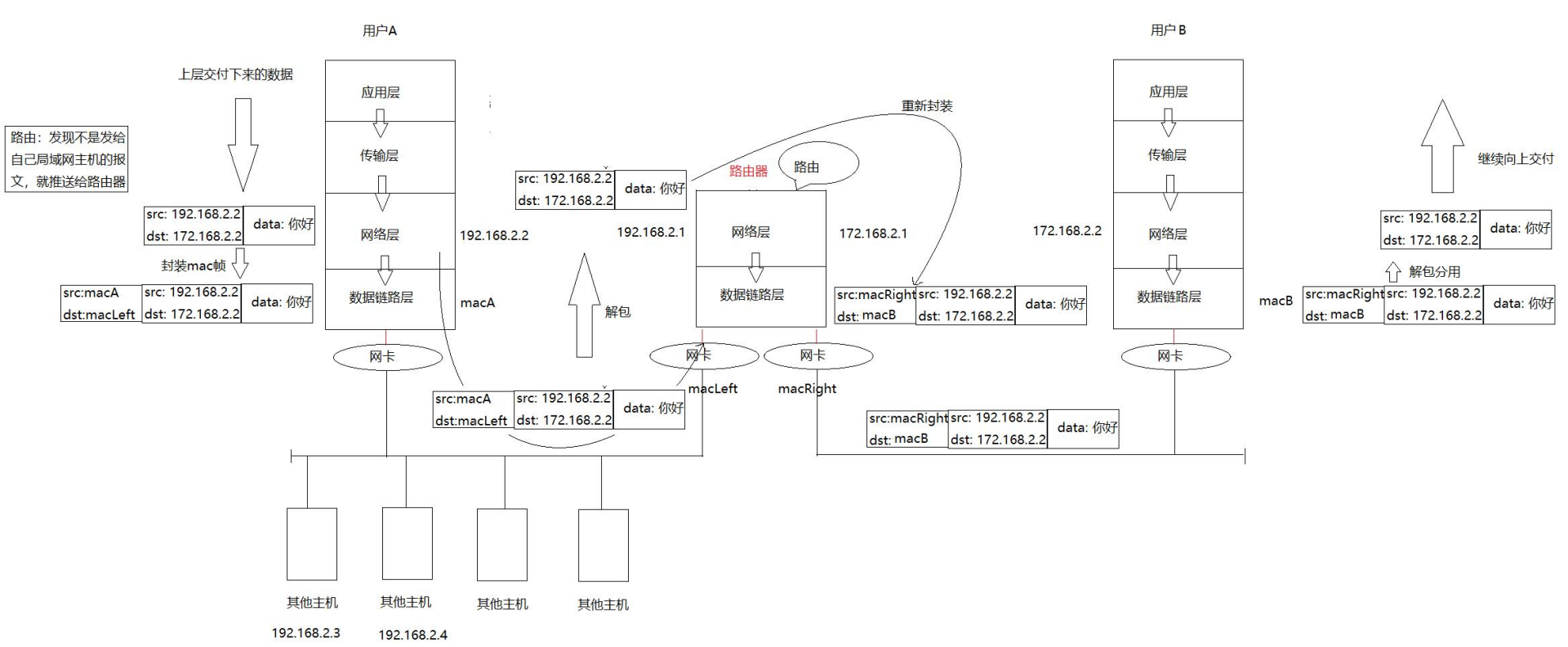
主机A是可以和路由器直接通信的(在封装的时候,添加数据链路层的报头信息的目的MAC地址是路由器其中对应的一张网卡的MAC地址信息)。然后泛红就找到了相应的路由器主机了。路由器就将收到的报文进行解包和分用,数据帧解包了,分用向上传递,还剩下IP信息,这时候在网络层,网络层具有路由功能,判断是否是目标主机的IP地址的对应子网。
发现就是之后,路由器就需要将报文转发给主机B,怎么转?
不能从路由器的网络层直接到主机B的网络层,需要将此时的报文继续向下交付,通过网卡发送,最终,主机B就可以接收到该报文了!
经过路由器,数据帧的信息就发生改变了(源MAC地址变为路由器的),但是该过程的源IP和目的IP一直都不变!所以在路由的过程之中IP信息不变,MAC信息一直在变。MAC地址只会在本局域网内有效!!
其实以太网,无线LIN,令牌环网,自定义局域网通信原理.......这些已经都不重要了,因为在网络层往下才是数据帧(MAC地址信息)的变更替换,往上所有的报头都是一样的,所以网络层+IP的本质意义就是给网络提供了一层虚拟化层,让世界上所有的网络都叫做IP网络!!!(任何一个问题,都可以添加一层软件层来解决,这就话更凸显了!!!)
那么我们可不可以只要IP呢?IP也可以体现唯一性啊???
其实只用IP的话,在技术上也是可以实现的。但是没必要,不然会导致强耦合,就不好维护了! 兼容性也就差了!!!