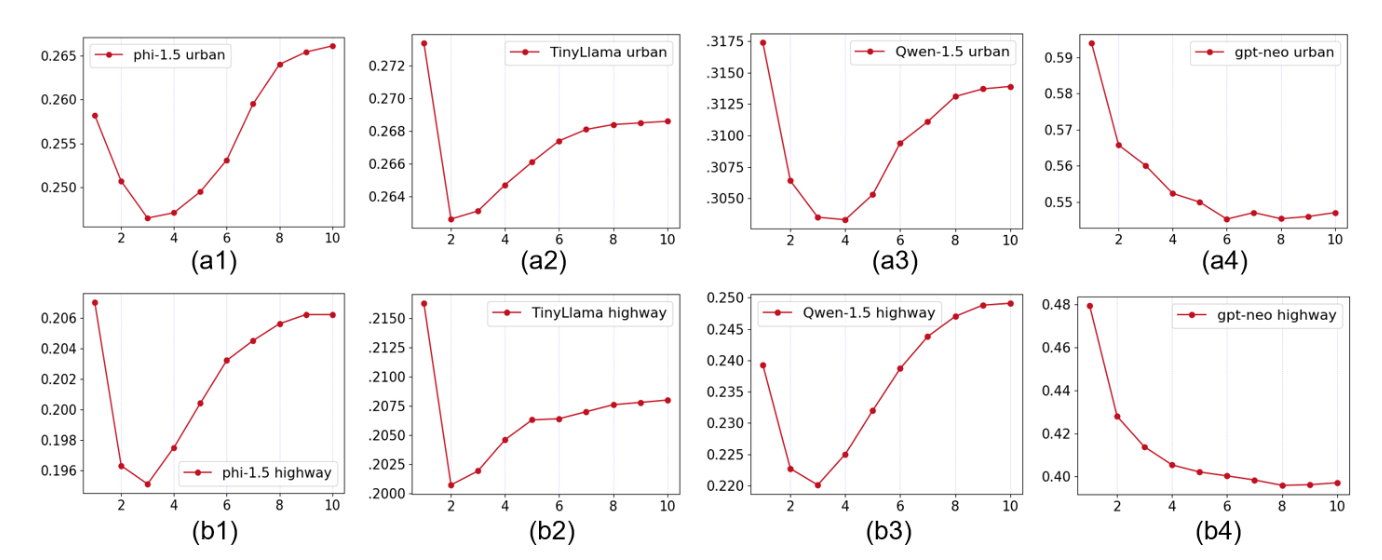
在RAG系统中,识别相关上下文的检索器组件的性能与语言模型在生成有效响应方面的性能同样重要,甚至更为重要。因此,一些改进RAG系统的努力将重点放在优化检索过程上。
从检索方面提高RAG系统性能的一些常见方法。通过实施高级检索技术,如混合搜索与重排序、选择性检索和查询转换,RAG系统能更好地应对诸如上下文无关和信息过载等常见挑战。每种策略都针对检索过程的不同方面,以确保生成更准确和相关的响应,并且它们都有助于缩小检索数据,以确定最相关和高质量的上下文片段,从而提高准确性和效率,尤其是在长上下文或专业RAG应用中。
常见的检索优化策略
在 RAG 系统中,广泛实施的优化检索器性能的方法包括以下三种。
1.混合搜索和重新排名
混合搜索结合两种检索标准来获取一组相关文档(或文档块)。一种常见的方法是结合稀疏检索和密集检索。稀疏检索使用基于关键词的方法(例如 TF-IDF)来匹配精确词条,这使得它能够有效地进行精准词条匹配。相比之下,密集检索利用嵌入(文本的数值表示)来捕捉语义相似性,当精确词条不同但含义相似时,这种方法非常理想。当这种混合搜索机制的目标是根据相关性优化检索到的文档的排名时,我们会应用重排序来对文档进行优先排序,以更好地适应原始用户查询的意图。
2.查询转换
查询转换包括调整或扩展查询,以便将检索到的文档集纳入更广泛或更具体的范围。例如,可以通过在原始查询中合并术语的同义词,或重新表述部分内容来实现。查询转换可以提高捕获高质量上下文的几率,从而帮助优化检索器的效率,尤其是在精确术语可能存在显著差异的情况下。
3. 上下文相关性过滤
一旦检索到相关文档,这种简单但通常有效的方法就会根据上下文元数据(例如日期和时间、地点和作者)对其进行过滤。这有助于根据用户的上下文和意图确定内容的优先级。
高级检索优化技术
以下三种技术是更专业的方法,需要额外的设置,但建议用于高风险 RAG 用例。
1. 针对具体案例的优化
案例特定优化的理念是针对特定领域(例如医疗、金融等)调整或定制检索流程,并对其进行微调,以更好地捕捉目标领域的细微差别。一个具体解决方案是通过特定领域的权重和排名指标,根据特定术语或实体在目标领域内的相关性对其进行优先排序。另一种方法是使用特定领域的数据集来训练或微调检索器。
2. 具有反馈循环的主动学习
带有反馈循环的主动学习是一种交互式方法,它结合用户反馈,不断调整和改进检索结果,从而不断提升模型的检索准确率。与其他 RAG 检索器优化策略不同,该方法通过整合实时反馈来调整检索过程,使其与用户偏好或不断变化的需求保持一致。
3.语义哈希
语义哈希专注于提高检索效率,通过将文档编码为哈希码(通常是紧凑的二进制向量),从而实现更快的基于相似度的检索。当 RAG 效率至关重要时,语义哈希是一种首选解决方案,并且可以与上述其他专注于基于相关性的检索结果质量的策略结合使用。
| 技术 | 概括 |
|---|---|
| 混合搜索和重新排名 | 结合稀疏(基于关键词)和密集(基于嵌入)检索方法来获取相关文档,然后应用重新排序来优先考虑最符合查询意图的结果。 |
| 查询转换 | 通过合并同义词或改述来调整或扩展查询,以捕获更广泛或更精确的文档集,从而提高检索高质量上下文的机会。 |
| 上下文相关性过滤 | 根据上下文元数据(例如日期、位置、作者)过滤检索到的文档,以确保所选内容与用户的需求紧密一致。 |
| 针对具体案例的优化 | 通过特定领域的加权和对专门数据集的微调来定制特定领域(例如医疗、金融)的检索过程,从而提高利基环境中的相关性。 |
| 具有反馈循环的主动学习 | 结合用户反馈来迭代改进检索结果,动态地调整流程以适应不断变化的用户偏好并确保随着时间的推移获得更准确的结果。 |
| 语义哈希 | 将文档编码为紧凑的二进制向量,以便快速进行基于相似性的检索,显著提高效率,尤其是在高需求的 RAG 场景中。 |
总结
本文探讨了六种旨在提升 RAG 系统检索过程性能的策略。每种技术的复杂程度各不相同,并侧重于不同的优化方面。了解这些策略对于选择适合您特定 RAG 实现的最佳方法(无论是单一技术还是多种技术的组合)至关重要。