6.1 实验设置
测试平台。我们使用阿里云上的16-GPU集群(包含4个GPU虚拟机,类型为ecs.gn7i-c32g1.32xlarge)。每台虚拟机配备4个NVIDIA A10(24 GB)GPU(通过PCI-e 4.0连接)、128个vCPU、752 GB内存和64 Gb/s网络带宽。
模型。我们以流行的LLaMA模型族[57]为实验对象。测试两种规格:LLaMA-7B(单GPU运行)和LLaMA-30B(通过张量并行在单机4个GPU上运行)。模型采用常见的16位精度。我们基于的vLLM版本仅支持原始LLaMA(最大序列长度2k),但近期已有支持更长序列长度(4k至256k)的LLaMA变体[3,7,58,65]。由于这些变体的模型架构和推理性能与LLaMA基本相似,我们认为从系统角度而言,我们的结果能代表更多模型类型和更长序列长度范围。
请求轨迹。与先前工作[34, 35, 67]类似,我们通过合成请求轨迹评估Llumnix的在线服务性能。
| 分布 | 平均值 | P50 | P80 | P95 | P99 |
|---|---|---|---|---|---|
| 真实 | |||||
| ShareGPT 输入 | 306 | 74 | 348 | 1484 | 3388 |
| 输出 | 500 | 487 | 781 | 988 | 1234 |
| BurstGPT 输入 | 830 | 582 | 1427 | 2345 | 3549 |
| 输出 | 271 | 243 | 434 | 669 | 964 |
| 生成 | |||||
| 短(S) | 128 | 38 | 113 | 413 | 1464 |
| 中(M) | 256 | 32 | 173 | 1288 | 4208 |
| 长(L) | 512 | 55 | 582 | 3113 | 5166 |
| 表1:评估中使用的序列长度(token数量)真实分布与生成分布。真实分布包含输入(“In”)和输出(“Out”)的长度。我们使用不同请求率(每秒请求数)的泊松分布和伽马分布生成请求到达时间。对于伽马分布,我们调整变异系数(CV)以控制请求的突发性。每个轨迹包含10,000个请求。我们选择合适的请求率或CV范围,使负载保持在合理区间:使用Llumnix时,P50请求几乎无排队延迟和抢占,P99请求的排队延迟在几十秒内。 |
对于请求的输入/输出长度,我们使用两个公开的ChatGPT-4对话数据集——ShareGPT (GPT4)[10]和BurstGPT (GPT4-Conversation)[62]——评估真实工作负载。考虑到Llumnix面向更多样化的应用场景,我们还使用生成的幂律长度分布模拟长尾工作负载,混合高频短序列(如聊天机器人、个人助手等交互式应用)和低频长序列(如摘要或文章生成)。我们生成多个不同长尾程度和平均长度(128、256、512)的分布,如表1中的短(S)、中(M)、长(L)分布。这些分布的最大长度为6k,因此请求的总序列长度(输入+输出)在运行LLaMA-7B时不会超过A10 GPU的容量(13,616 tokens)。为观察不同工作负载特征的性能,我们通过组合输入和输出的长度分布构建轨迹,包括S-S、M-M、L-L、S-L和L-S。
基线。我们将Llumnix与以下调度器对比。所有基线和Llumnix均使用vLLM作为底层推理引擎,以聚焦实例间请求调度的对比。
• 轮询调度:一种均衡分发请求的简单策略,是生产级服务系统的典型行为[4, 9, 47]。
• INFaaS++:优化版的INFaaS[53],一种先进的多实例服务调度器。我们评估其负载均衡调度和负载感知自动扩缩容策略。我们通过使其专注于LLM服务中的主导资源——GPU内存(包括排队请求占用的内存以反映队列压力)对其进行改进。
• Llumnix-base:Llumnix的基础版本,不区分优先级(所有请求视为同优先级),但启用迁移等其他功能。
关键指标。我们重点关注请求延迟,包括端到端延迟、预填充延迟(首个生成token的延迟)和解码延迟(自首个生成token至最后一个的平均延迟)。我们报告平均值和P99值。
6.2 迁移效率
我们首先评估Llumnix迁移机制的性能,包括对迁移请求引入的停机时间和对运行中请求的额外开销。我们测试了1-GPU的LLaMA-7B和4-GPU的LLaMA-30B模型。针对每种模型,我们在两台不同机器上部署两个实例。使用不同序列长度时,我们分别在两个实例上运行总长度为8k的同一批请求。随后将其中一个实例上的请求迁移至另一实例,并测量其停机时间及迁移期间两个实例上运行批次的解码速度。
我们比较了迁移期间的停机时间与两种简单方法:重新计算和使用Gloo阻塞式拷贝KV缓存(其他请求非阻塞)。如图10(左)所示,迁移的停机时间随序列长度增加几乎保持恒定(约20-30毫秒),甚至短于单次解码步骤。相比之下,基线方法的停机时间随序列长度增加而增长,最高达到迁移的111倍。例如,对LLaMA-30B重新计算8k序列需3.5秒,相当于54个解码步骤的服务停滞。我们还观察到,所有序列长度的迁移仅需两个阶段,这是最小值。这是因为数据拷贝速度足够快,且第一阶段生成的新token数量较少。
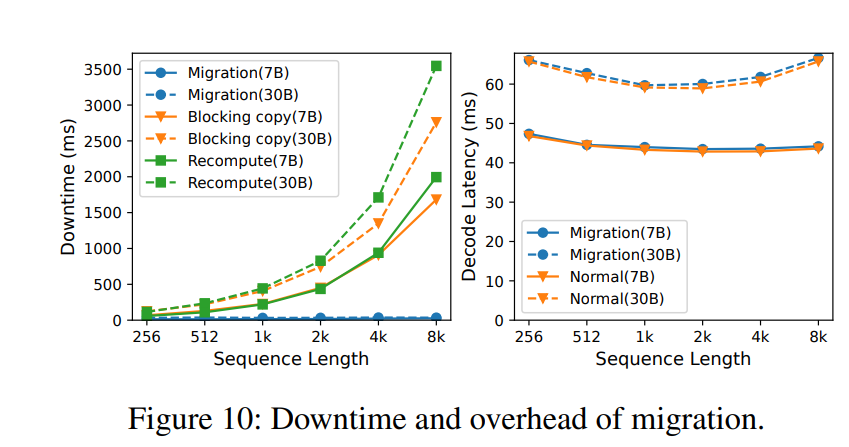
图10(右)进一步比较了源实例在迁移期间与正常执行时的单步解码时间(目标实例结果类似)。对于LLaMA-7B和LLaMA-30B,性能差异均不超过1%,表明迁移额外开销可忽略不计。此外,此类额外开销仅在实例上有请求被迁移(入或出)时存在。我们发现,在后续所有服务实验中,每个实例上正在进行迁移的时间跨度平均占比仅为约10%。这意味着实际额外开销更小,而迁移带来的调度收益显著,这一权衡是值得的。
6.3 服务性能
我们评估Llumnix在在线服务中的调度性能,使用16个LLaMA-7B实例(自动扩缩容功能仅在§6.5实验中启用)。
真实数据集。我们首先使用ShareGPT和BurstGPT轨迹(图11的前两行),
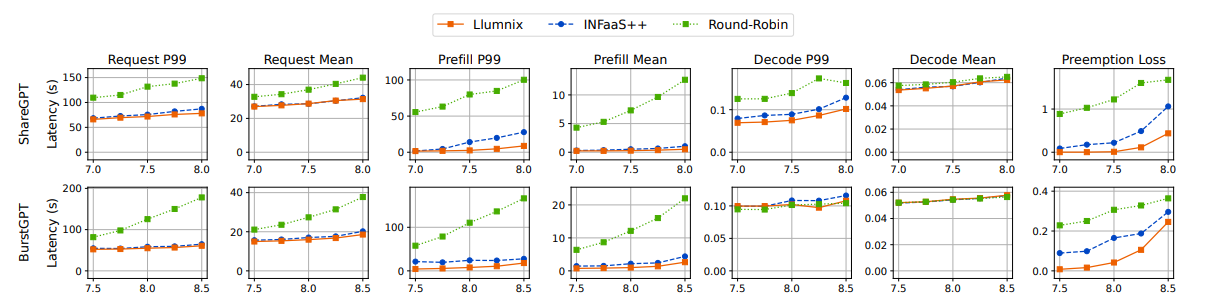
比较Llumnix与轮询及INFaaS++的性能。Llumnix在端到端请求延迟上显著优于基线方法,平均延迟最高提升2倍,P99延迟最高提升2.9倍。尤其值得注意的是,轮询策略的性能始终远低于INFaaS++和Llumnix:由于序列长度方差较大,单纯均匀分发请求仍会导致负载不均衡,从而影响预填充和解码延迟。
Llumnix在预填充延迟上相比轮询实现显著提升,平均延迟最高达26.6倍,P99延迟最高达34.4倍。这是由于轮询可能将新请求分发至过载实例,导致较长的排队延迟。通过负载均衡减少抢占,Llumnix将P99解码延迟最高降低2倍。由于抢占导致的延迟惩罚被所有生成token分摊,这一提升幅度看似较小。然而,每次抢占发生时,都会造成突发性服务停滞,影响用户体验。图11(最右侧列)报告了抢占损失(所有请求的额外排队和重计算时间均值)。Llumnix相比轮询平均减少84%的抢占损失。这些结果凸显了负载均衡在LLM服务中的重要性。在后续使用更高方差生成分布的实验中,轮询的延迟表现恶化至基线的两个数量级。因此,为保持图表清晰,后续实验将省略轮询,仅对比INFaaS++与Llumnix。
Llumnix在平均预填充延迟上超越INFaaS++最高达2.2倍,P99延迟最高达5.5倍,在P99解码延迟上最高提升1.3倍,证明迁移机制在调度时负载均衡之外的额外收益。接下来,我们通过更多不同特征的轨迹进一步评估两者的性能差异。
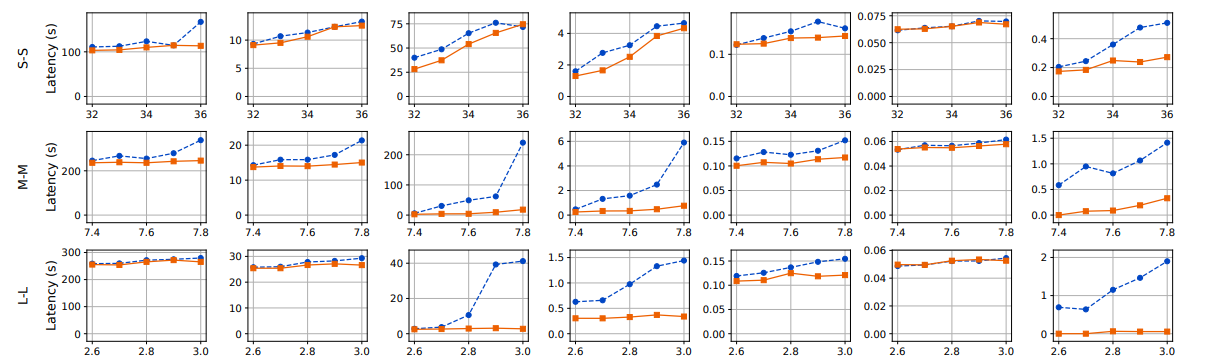
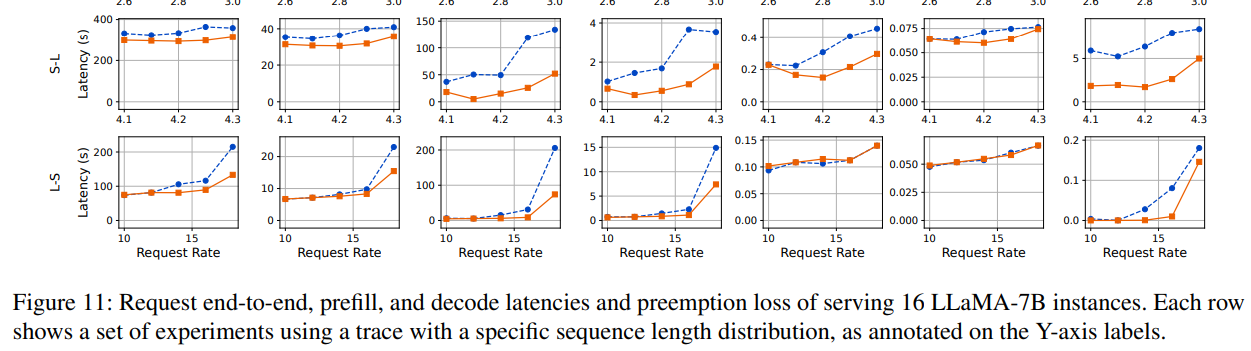
生成分布。我们使用多个生成分布(图11的底部五行)比较Llumnix与INFaaS++。Llumnix在所有轨迹的端到端请求延迟上均表现更优,平均延迟最高提升1.5倍,P99延迟最高提升1.6倍。预填充延迟的改进更为显著,平均延迟最高达7.7倍,P99延迟最高达14.8倍。尽管INFaaS++将请求分发至负载最低的实例,但由于碎片化问题(尤其是输入较长的长尾请求),仍会出现较长的排队延迟。Llumnix通过迁移实现碎片整理,从而减少此类排队延迟,在输入较长的轨迹中表现更优。
为了更深入地研究内存碎片化问题,我们进一步以请求速率为7.5的M-M跟踪实验为例进行案例研究。我们将每个时刻的碎片化内存定义为:在无碎片化情况下,集群空闲内存中能够满足所有实例队首阻塞请求需求的那部分内存。例如,若总空闲内存为8GB,存在三个各需3GB的队首阻塞请求,则碎片化内存计为6GB,即若无碎片化时这6GB内存可满足两个排队请求的需求。该指标反映了因碎片化导致的内存浪费程度。我们统计了碎片化内存在集群总内存中的占比。在上述示例中,若总内存为16GB,则占比为37.5%(6/16)。
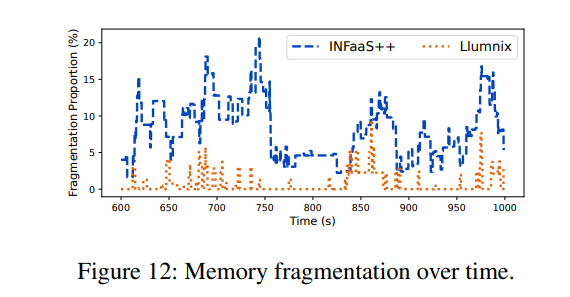
图12展示了实验期间繁忙时段的碎片化比例。我们观察到INFaaS++的碎片化比例经常超过10%,造成大量集群内存浪费。相比之下,Llumnix的碎片化比例通常为0。在该时段内,Llumnix和INFaaS++的平均碎片化比例分别为0.7%和7.9%(降低92%),突显了通过迁移进行碎片整理的效果。
通过减少抢占,Llumnix还将P99解码延迟最高提升了2倍。尽管INFaaS++已通过调度负载均衡来减少抢占,但迁移通过响应实际序列长度(请求到达时未知)对此进行了补充。如图11所示,Llumnix显著降低了抢占损失,在多数情况下接近零。所有实验的平均降幅为70.4%,相当于端到端请求延迟平均减少了1.3秒。
6.4 优先级支持
我们通过随机选取10%的请求并为其分配高调度优先级和执行优先级,评估了Llumnix对优先级的支持能力。实验采用短-短序列长度分布和Gamma到达分布的跟踪数据。通过调整变异系数(CV)参数,展示突发工作负载和负载峰值对高优先级请求的干扰程度。我们根据经验为高优先级请求设定1,600个token的目标内存负载,因为观察到该负载可维持接近理想的解码速度(参见图4)。Llumnix将此目标负载转换为高优先级请求对应的内存预留空间。我们将Llumnix与Llumnix-base进行对比,后者将所有请求视为相同优先级。
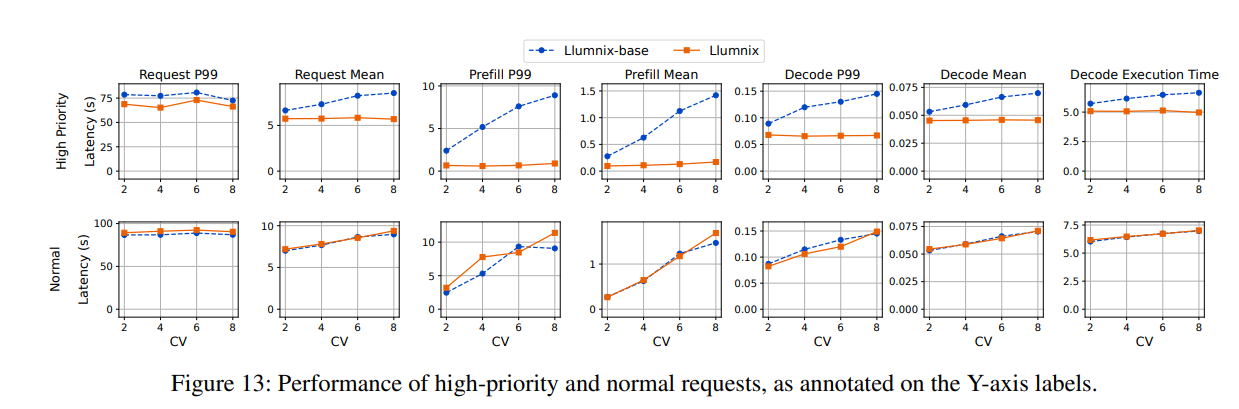
如图13第一行所示,随着CV值增加,Llumnix将高优先级请求的平均延迟改善了1.2倍至1.5倍。更高的CV值会导致更多高负载时段,若缺乏保护机制,高优先级请求可能遭受更严重的干扰。即使在更高CV值下,Llumnix仍能为高优先级请求提供稳定的延迟表现,体现了其对此类请求的隔离能力。这是因为Llumnix能通过动态为其腾出空间来应对变化的高优先级负载,而静态资源预留等方法难以实现这一点。对于预填充延迟,Llumnix的平均延迟改善达2.9倍至8.6倍,P99延迟改善达3.6倍至10倍。这通过高调度优先级减少排队延迟实现。Llumnix还将解码延迟的平均值改善了1.2倍至1.5倍,P99延迟改善了1.3倍至2.2倍。这种提升源于通过降低实例负载和干扰加速解码计算(最右侧列显示平均解码计算时间有类似提升)。我们还注意到Llumnix保持了普通请求的性能(图13第二行):Llumnix对普通请求的平均请求、预填充和解码延迟分别最多增加4.5%、13%和2%。
6.5 自动扩展
我们通过使用更大范围的请求速率和Gamma变异系数(CVs)来评估Llumnix的自动扩展能力,以展示其对负载变化的适应性。默认情况下,Llumnix使用[10, 60]的扩展阈值范围,即当平均空闲度(freeness)低于10或高于60时,Llumnix会扩展或缩减实例;需注意,该指标表示在当前批次下实例仍可运行的最大解码步数。我们让INFaaS++使用相同的扩展策略,因此Llumnix和INFaaS++的实例扩展激进程度一致。实验中最大实例数设为16,并采用长-长序列长度分布。
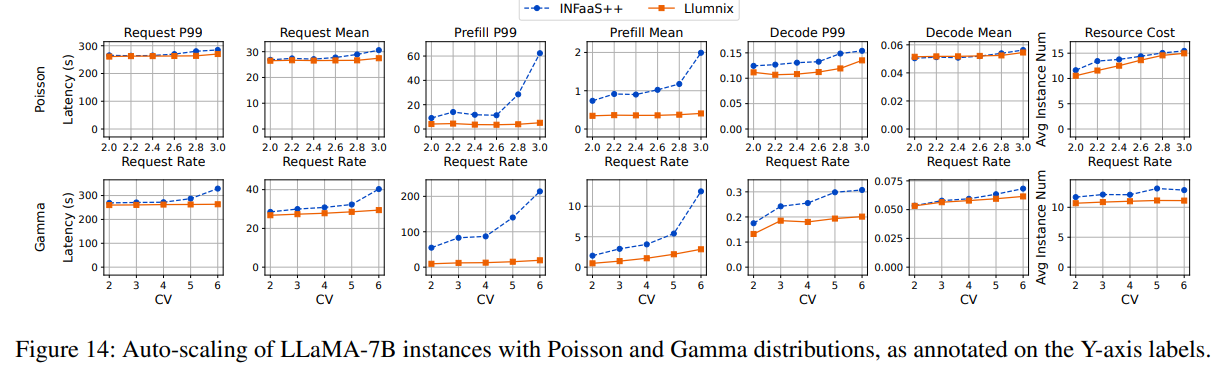
我们首先基于泊松分布调整请求速率。如图14第一行所示,Llumnix在所有请求速率下均实现了延迟改善,例如P99预填充延迟最高提升12.2倍。我们还以平均使用实例数衡量资源成本(见最右侧列)。Llumnix通过更快速地饱和或释放实例来提高自动扩展效率,从而节省高达16%的成本。此外,我们通过Gamma分布的不同变异系数测试了不同工作负载突发性(请求速率=2)。如第二行所示,Llumnix在延迟和成本方面表现类似改进,例如P99预填充延迟最高提升11倍,成本节省18%。
最后,我们通过分析Llumnix需要多激进地扩展实例以维持特定延迟目标(如给定的P99预填充延迟)来评估其成本效率。我们调整扩展阈值t,扩展范围设为[t, t+50]。t值越高,表示Llumnix倾向于使用更多实例。
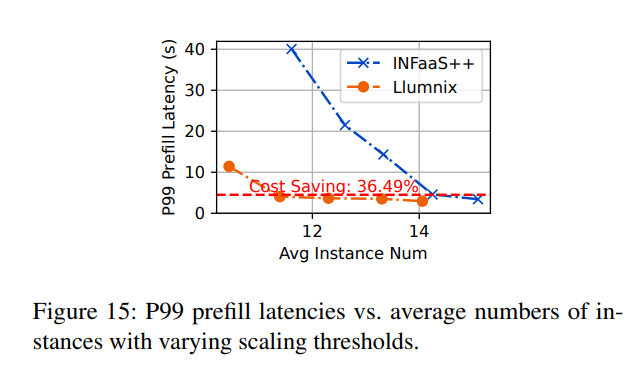
图15展示了不同扩展阈值下的P99预填充延迟和成本。观察发现,由于迁移减少排队延迟的能力与更高的自动扩展效率的结合,Llumnix在实现相似P99预填充延迟(约5秒,红色虚线)的同时,相比INFaaS++节省了36%的成本。
6.6 调度可扩展性
我们通过调度压力测试评估Llumnix在64个LLaMA-7B实例下的可扩展性,测试使用更高的请求速率。由于该集群规模超过我们的测试平台容量,我们通过离线测量A10 GPU在不同序列长度和批量大小下的表现,将vLLM中的真实GPU执行替换为简单的休眠命令(sleep command)。我们通过扩展vLLM调度器以集中管理所有实例的请求,构建了一个简单的集中式调度器作为基线。测试中,请求的输入和输出长度均为64个token,且请求速率逐步增加。
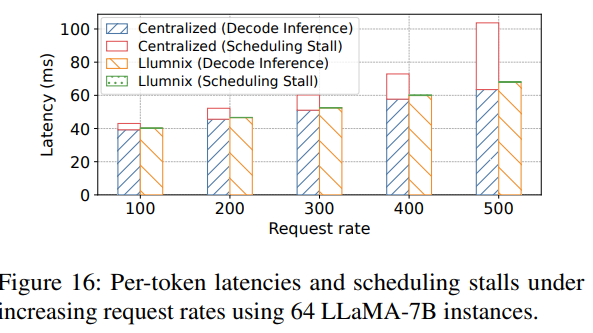
如图16所示,随着请求速率提升,基线方案在每次迭代的推理计算期间遭遇长达40毫秒的调度停滞,导致整体速度下降1.7倍。此类停滞源于实例与集中式调度器之间的通信——同步请求状态和调度决策的过程在高负载下成为瓶颈。相比之下,Llumnix即使在高请求速率下仍表现出接近零的调度停滞,展现了其分布式调度架构的可扩展性。Llumnix将实例内的调度逻辑卸载并分布到各个"llumlet"中,使其与全局调度并行且异步执行。此外,llumlet仅上报实例级指标,而非每个请求的精确状态,从而进一步提升了通信效率。
7 相关工作
LLM推理。随着Transformer模型在模型服务中的重要性日益凸显,近期工作如FasterTransformer[46]、TurboTransformer[25]、LightSeq[61]和FlashAttention[21, 22]通过优化GPU内核以提升推理性能。SpotServe[41]利用可抢占实例支持LLM推理,以提高成本效率。FastServe[63]采用抢占式时间切片方法优化请求完成时间。AlpaServe[35]通过流水线并行技术降低突发工作负载的服务延迟。为进一步提升GPU利用率和服务吞吐量,Orca[67]提出迭代级调度(在近期研究及本文中被称为连续批处理)和选择性批处理,而vLLM[34]则通过PageAttention优化内存使用。[55]提出在LLM实例上对请求进行公平调度。先前工作主要聚焦于单实例服务,因此与Llumnix形成互补。Llumnix探索了部署多实例LLM服务的挑战与机遇。KV缓存的关键追加-only特性被用于在推理引擎中实现请求迁移能力。该机制开辟了广阔的策略设计空间,以提供优先级和性能隔离、提升内存效率,并支持实例自动扩展。我们还计划探索跨实例全局调度与实例内本地调度技术(如抢占式[63]和公平[55]调度)之间的相互作用,作为未来工作。
请求调度。为支持深度学习模型部署,已提出多种系统(如Clipper[19]、Nexus[54]、DVABatch[20]和TritonServer[47])以优化DNN推理服务的请求调度。为满足DNN推理请求的服务等级目标(SLO),Clockwork[29]利用传统DNN的执行可预测性,而Reef[33]和Shepherd[68]通过抢占机制优先处理高优先级请求。AlpaServe[35]采用基于队列长度的简单负载均衡分发策略。这些工作主要针对传统DNN模型服务,其中单个请求仅需对模型进行一次性推理。然而,LLM推理服务需要对模型进行不可预测迭代次数的自回归计算,并引入中间状态(即KV缓存),展现出全新特性。DeepSpeed-MII[4]虽针对多实例LLM服务,但采用忽略LLM特性的简单轮询分发策略。Llumnix更进一步,通过整合请求迁移确保高吞吐量和低延迟,为优先级请求提供SLO,并通过统一的负载感知动态调度策略实现资源效率的实例自动扩展。
除多模型实例外,INFaaS[53]进一步支持跨多模型类型/变体的调度,综合考量不同应用场景的性能与精度需求。这也是LLM的典型场景:例如针对特定任务的微调模型(如代码生成[3, 13, 30]);或基座LLM不同规模或精度的变体([26,37,39])。我们计划在后续工作中扩展Llumnix以支持多模型类型,综合考量延迟/吞吐量与精度间的更大权衡空间。
隔离与碎片化。隔离与碎片化之间的权衡,或工作负载打包与分散之间的权衡,一直是经典的调度挑战。具体而言,工作负载打包可提升资源利用率,但可能引发共置工作负载间的干扰;而分散工作负载虽提供更好隔离性,却会增加资源碎片化。已有大量研究致力于在数据中心中更好地平衡大数椐作业和虚拟机的隔离与碎片化问题,通过识别工作负载的干扰敏感性并优化调度策略([16,18,23,24,27,31,32,40,60,66])。这一挑战在深度学习工作负载的GPU集群中同样存在。Amaral等提出了一种拓扑感知的放置算法,以解决多GPU服务器上深度学习训练作业打包与分散的权衡[12]。Gandiva[64]则通过内省式作业迁移,应对不同作业对打包/分散的异构敏感性。由于不可预测的自回归执行,LLM服务使这一挑战更为复杂。Llumnix通过运行时请求迁移响应工作负载动态,以更好地协调这两个目标。
迁移。Gandiva[64]在调度期间为深度学习训练作业启用内省式迁移。其利用深度学习固有的迭代特性,在最小工作集(即小批量边界)上执行检查点-恢复方法以迁移模型权重。尽管LLM推理同样具有迭代性,但直接迁移请求的完整状态不可接受,因为推理请求的延迟SLO至关重要。此外,每个请求的工作集与序列长度呈线性关系,而随着上下文长度增加趋势[49, 50],这一开销可能显著。Llumnix的迁移方法受虚拟机实时迁移[17]启发:通过在LLM请求持续解码时执行大部分迁移操作,Llumnix将迁移停机时间最小化,使成本不受序列长度影响而可忽略。
8 结论
Llumnix这一名称蕴含了我们的愿景——以类Unix方式服务LLM。这一愿景源于观察到LLM与现代操作系统具有共性,例如普适性、多租户特性和动态性,因而面临相似的需求与挑战。本文通过借鉴传统操作系统的经典设计理念,在LLM服务新场景中迈出重要一步:重新定义隔离性、优先级等经典抽象概念;通过推理请求迁移实现"上下文切换"这一核心方法;并利用迁移能力实现持续动态的请求重调度。这些设计的结合使Llumnix实现了更低的延迟、更高的成本效益以及差异化SLO支持,为LLM服务指明了新方向。