文章目录
- 一、问题背景
- 1. 高并发连接的管理
- 2. 避免阻塞和延迟
- 3. 减少上下文切换开销
- 4. 高效的事件通知机制
- 5. 简化编程模型
- 6. 低延迟响应
- 本章小节
- 二、I/O多路复用高性能的本质
- 1. 避免无意义的轮询:O(1) 事件检测
- 2. 非阻塞 I/O + 零拷贝:最大化 CPU 利用率
- 3. 单线程事件循环:无锁、无上下文切换
- 4. 高效的系统调用:内核级优化
- 5. Reactor 模式:事件分发与业务逻辑解耦
- 6. 边缘触发(ET) vs 水平触发(LT)
- 性能对比:传统模型 vs 多路复用
- 为什么 Redis 能单线程扛住 10 万 QPS?
- 本章小节:I/O 多路复用快的本质
- 三、基于I/O多路复用的Redis高性能设计源码分析
- 1. 事件循环核心结构:`aeEventLoop`
- 2. 多路复用 API 的抽象层
- `aeApiCreate`:初始化多路复用实例
- `aeApiAddEvent`:注册事件到epoll
- 3. 事件循环主流程:`aeMain`
- 关键函数 `aeProcessEvents`
- 4. 文件事件处理:从连接建立到命令执行
- 步骤1:监听客户端连接(`acceptTcpHandler`)
- 步骤2:注册客户端读事件(`readQueryFromClient`)
- 步骤3:读取并解析命令(`readQueryFromClient`)
- 步骤4:执行命令并写回结果
- 5. 多路复用 API 的性能优化
- `epoll` 的边缘触发(ET) vs 水平触发(LT)
- `aeApiPoll` 的实现(以epoll为例)
- 6. 单线程模型与 I/O 多路复用的协同
- 本章小结:Redis I/O 多路复用的设计精髓
- 四、使用java实现I/O多路复用模型
- 关键设计解析
- 1. Selector 核心机制
- 2. Channel 注册与事件类型
- 3. ByteBuffer 状态管理
- 4. 事件处理流程
- 性能优化点
- 1. 零拷贝优化
- 2. 批量处理事件
- 3. 对象池化
- 对比传统BIO模型
- 运行测试
- 扩展方向
一、问题背景
Redis采用I/O多路复用技术(如epoll、kqueue或select)作为其高性能设计的核心机制,主要解决了以下关键问题:
1. 高并发连接的管理
- 问题:传统多线程/多进程模型中,每个连接需分配独立线程或进程,资源消耗大(内存、CPU上下文切换)。
- 解决:I/O多路复用允许单线程同时监听和管理成千上万的网络连接,通过事件驱动的方式处理请求,避免为每个连接创建独立线程,显著降低资源占用。
- 场景:适用于高并发场景(如10万+并发连接),如实时消息队列、高频访问的缓存服务。
2. 避免阻塞和延迟
- 问题:传统阻塞I/O中,线程在等待数据时会被挂起,导致吞吐量下降。
- 解决:结合非阻塞I/O,I/O多路复用仅在有数据到达或可写时通知线程处理,线程无需阻塞等待,最大化CPU利用率。
- 示例:客户端发送请求后,Redis线程无需阻塞等待数据,转而处理其他连接的请求,直到数据就绪。
3. 减少上下文切换开销
- 问题:多线程/进程模型中,频繁的上下文切换(Context Switching)会消耗大量CPU时间。
- 解决:单线程配合I/O多路复用,无需线程间切换,减少CPU浪费,提升整体吞吐量。
- 对比:多线程模型在并发1万连接时可能因切换开销导致性能骤降,而Redis仍能保持低延迟。
4. 高效的事件通知机制
- 问题:传统轮询(如
select)需遍历所有连接检查状态,时间复杂度为O(n),效率低下。 - 解决:采用
epoll(Linux)或kqueue(BSD)等高效多路复用器,仅关注活跃连接,时间复杂度为O(1)。epoll优势:通过事件回调机制直接获取就绪事件列表,避免无意义的遍历。- 性能提升:连接数越多,相比
select/poll的性能优势越明显。
5. 简化编程模型
- 问题:多线程同步(如锁、信号量)增加代码复杂度和调试难度。
- 解决:单线程事件循环模型避免了锁竞争,代码逻辑更简洁,降低并发编程的复杂度。
- Redis设计:单线程处理命令执行和网络I/O,通过异步机制(如后台线程处理持久化)平衡性能与功能。
6. 低延迟响应
- 问题:传统多线程模型中,线程调度和锁竞争可能导致请求处理延迟波动。
- 解决:单线程按事件顺序处理请求,无锁竞争,确保每个请求的响应时间更可预测。
- 适用场景:对延迟敏感的应用(如实时排行榜、会话存储)。
本章小节
通过I/O多路复用,Redis在单线程中实现了:
- 高并发连接管理
- 非阻塞I/O操作
- 低资源消耗与上下文切换
- 高效事件驱动处理
- 稳定低延迟响应
二、I/O多路复用高性能的本质
I/O 多路复用之所以能实现高性能,核心在于它通过一种高效的事件驱动机制,解决了传统阻塞 I/O 和多线程模型的根本性缺陷。以下是其速度快的本质原因:
1. 避免无意义的轮询:O(1) 事件检测
- 传统模型(如
select/poll):需要遍历所有文件描述符(FD)检查状态,时间复杂度为 O(n),连接数越大效率越低。 - 多路复用(如
epoll/kqueue):- 事件回调机制:内核直接维护一个“就绪队列”,仅返回已就绪的事件列表,时间复杂度 O(1)。
- 示例:10 万个连接中只有 100 个活跃时,
epoll直接返回这 100 个事件,而select需遍历全部 10 万个。
2. 非阻塞 I/O + 零拷贝:最大化 CPU 利用率
- 非阻塞 I/O:线程无需等待数据就绪,立即返回处理其他任务,避免 CPU 空转。
- 零拷贝技术:通过
sendfile或内存映射(mmap)减少数据在内核态和用户态之间的复制次数,降低 CPU 和内存开销。 - 对比:传统阻塞 I/O 下,线程在等待数据时完全挂起,浪费 CPU 周期。
3. 单线程事件循环:无锁、无上下文切换
- 单线程模型:所有 I/O 事件由单线程顺序处理,避免了多线程的锁竞争和上下文切换开销。
- 资源消耗极低:单线程管理数万连接,内存占用仅为多线程模型的 1/100 甚至更低。
- 适用场景:Redis 的单线程设计正是利用这一点,在 CPU 不是瓶颈时实现超高吞吐量。
4. 高效的系统调用:内核级优化
epoll的优势(Linux):- 红黑树管理 FD:快速插入、删除、查找,时间复杂度 O(log n)。
- 事件驱动回调:通过
epoll_ctl注册事件,内核直接通知就绪的 FD。
kqueue(BSD/MacOS):类似原理,支持更复杂的事件类型(如文件变化、信号)。
5. Reactor 模式:事件分发与业务逻辑解耦
- 核心思想:将 I/O 事件监听(Reactor)与事件处理(Handler)分离。
- 工作流程:
- Reactor 监听所有 I/O 事件(如可读、可写)。
- 事件就绪后,分发给对应的 Handler(如 Redis 的命令处理器)。
- Handler 处理完成后,将结果写回网络缓冲区。
- 优势:逻辑清晰,避免阻塞,适合高并发。
6. 边缘触发(ET) vs 水平触发(LT)
- 水平触发(LT):只要 FD 处于就绪状态,每次调用
epoll_wait都会返回该事件。 - 边缘触发(ET):仅在 FD 状态变化时(如从不可读变为可读)触发一次事件。
- ET 的优势:减少重复事件通知,强制开发者一次性处理完所有数据,避免饥饿问题,性能更高。
性能对比:传统模型 vs 多路复用
| 场景 | 多线程阻塞 I/O | I/O 多路复用 |
|---|---|---|
| 10 万并发空闲连接 | 10 万线程,内存爆炸 | 单线程,内存占用极低 |
| CPU 利用率 | 高(上下文切换) | 高(无阻塞) |
| 延迟稳定性 | 波动大(线程调度) | 稳定(单线程顺序处理) |
| 代码复杂度 | 高(锁、同步) | 低(事件驱动) |
为什么 Redis 能单线程扛住 10 万 QPS?
- 纯内存操作:数据在内存中处理,速度极快(纳秒级)。
- I/O 多路复用:单线程高效管理所有网络事件。
- 无锁设计:避免线程竞争,保证原子性。
- 批量写入优化:通过缓冲区合并小数据包,减少系统调用次数。
本章小节:I/O 多路复用快的本质
- 事件驱动:只处理实际发生的 I/O 事件,避免无效轮询。
- 非阻塞 + 零拷贝:最大化 CPU 和内存效率。
- 单线程无锁:消除多线程开销,简化编程模型。
- 内核级优化:
epoll/kqueue等机制的高效实现。
这种设计在高并发、低延迟场景(如 Redis、Nginx)中表现尤为突出,成为现代高性能服务器的基石。
三、基于I/O多路复用的Redis高性能设计源码分析
Redis 的 I/O 多路复用实现是其高性能的核心设计之一,源码中通过 事件驱动模型(Event Loop)结合操作系统提供的多路复用 API(如 epoll、kqueue、select)来实现。以下是关键源码模块的分析,结合 Redis 6.0 源码(代码片段已简化)。
1. 事件循环核心结构:aeEventLoop
Redis 通过 aeEventLoop 结构体管理所有事件(文件事件和时间事件),定义在 ae.h 中:
typedef struct aeEventLoop {
int maxfd; // 当前注册的最大文件描述符
int setsize; // 最大监听的文件描述符数量
long long timeEventNextId; // 下一个时间事件的ID
aeFileEvent *events; // 注册的文件事件数组(每个fd对应一个事件)
aeFiredEvent *fired; // 已触发的文件事件数组
aeTimeEvent *timeEventHead; // 时间事件链表头
void *apidata; // 多路复用API的私有数据(如epoll实例)
// ...
} aeEventLoop;
events数组:记录每个文件描述符(如客户端 Socket)的读写事件及回调函数。fired数组:存储每次事件循环中触发的就绪事件。apidata:指向底层多路复用 API 的私有数据结构(如epoll的epoll_event列表)。
2. 多路复用 API 的抽象层
Redis 对不同操作系统的多路复用 API 进行了统一封装,代码在 ae_epoll.c、ae_kqueue.c、ae_select.c 中。以 epoll 为例:
aeApiCreate:初始化多路复用实例
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
state->epfd = epoll_create(1024); // 创建epoll实例
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
eventLoop->apidata = state; // 绑定到aeEventLoop
return 0;
}
aeApiAddEvent:注册事件到epoll
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee;
ee.events = 0;
if (mask & AE_READABLE) ee.events |= EPOLLIN; // 读事件
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT; // 写事件
epoll_ctl(state->epfd, EPOLL_CTL_ADD, fd, &ee); // 注册到epoll
return 0;
}
3. 事件循环主流程:aeMain
事件循环的核心逻辑在 aeMain 函数中,代码在 ae.c:
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 1. 处理时间事件(如过期键清理)
// 2. 处理文件事件(网络I/O)
aeProcessEvents(eventLoop, AE_ALL_EVENTS | AE_CALL_BEFORE_SLEEP);
}
}
关键函数 aeProcessEvents
int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
// 1. 计算最近的时间事件触发时间(决定epoll_wait的超时时间)
long long maxWait = calculateMaxWaitTime(eventLoop);
// 2. 调用多路复用API等待事件(如epoll_wait)
int numevents = aeApiPoll(eventLoop, maxWait);
// 3. 处理触发的文件事件
for (int j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
if (fe->mask & AE_READABLE) {
fe->rfileProc(eventLoop, eventLoop->fired[j].fd, fe->clientData, mask);
}
if (fe->mask & AE_WRITABLE) {
fe->wfileProc(eventLoop, eventLoop->fired[j].fd, fe->clientData, mask);
}
}
// 4. 处理时间事件(如定时任务)
processTimeEvents(eventLoop);
return numevents;
}
aeApiPoll:调用底层多路复用 API(如epoll_wait)等待事件,返回就绪事件数量。- 事件回调:根据事件类型(读/写)执行预先注册的回调函数(如
rfileProc和wfileProc)。
4. 文件事件处理:从连接建立到命令执行
Redis 的网络事件处理流程如下:
步骤1:监听客户端连接(acceptTcpHandler)
当监听 Socket(如 6379 端口)有新的连接到达时,触发读事件,执行 acceptTcpHandler:
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cfd, cport;
char cip[NET_IP_STR_LEN];
// 接受客户端连接
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
// 创建客户端对象
redisClient *client = createClient(cfd);
}
步骤2:注册客户端读事件(readQueryFromClient)
为新客户端 Socket 注册读事件,回调函数为 readQueryFromClient:
client *createClient(int fd) {
client *c = zmalloc(sizeof(client));
// 注册读事件到事件循环
aeCreateFileEvent(server.el, fd, AE_READABLE, readQueryFromClient, c);
// ...
}
步骤3:读取并解析命令(readQueryFromClient)
当客户端发送数据时,触发读事件回调:
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
client *c = privdata;
// 从Socket读取数据到客户端缓冲区
nread = read(fd, c->querybuf + qblen, readlen);
// 解析命令(如SET/GET)
processInputBuffer(c);
}
步骤4:执行命令并写回结果
命令解析完成后,执行命令并将结果写入客户端输出缓冲区,注册写事件:
void processCommand(client *c) {
// 查找命令并执行(如dictFind(server.commands, c->cmd->name))
call(c, CMD_CALL_FULL);
// 将响应写入客户端缓冲区
if (clientHasPendingReplies(c)) {
// 注册写事件,回调函数sendReplyToClient
aeCreateFileEvent(server.el, c->fd, AE_WRITABLE, sendReplyToClient, c);
}
}
5. 多路复用 API 的性能优化
epoll 的边缘触发(ET) vs 水平触发(LT)
Redis 默认使用 水平触发(LT) 模式:
- 水平触发:只要 Socket 可读/可写,事件会持续触发,直到数据被处理完。
- 边缘触发(ET):仅在 Socket 状态变化时触发一次,需一次性读取所有数据(可能需循环读取)。
Redis 选择 LT 的原因:
- 代码简洁性:避免处理 ET 模式下的“饥饿”问题(需循环读取直到
EAGAIN)。 - 兼容性:LT 模式在所有多路复用 API(如
select、poll)中行为一致。
aeApiPoll 的实现(以epoll为例)
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval;
// 调用epoll_wait,等待事件(最大阻塞时间由tvp决定)
retval = epoll_wait(state->epfd, state->events, eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
// 将就绪事件填充到eventLoop->fired数组中
for (int j = 0; j < retval; j++) {
struct epoll_event *e = state->events + j;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = e->events;
}
return retval; // 返回就绪事件数量
}
6. 单线程模型与 I/O 多路复用的协同
Redis 的单线程模型通过以下方式与 I/O 多路复用协同工作:
- 事件顺序处理:所有网络事件由单线程按顺序处理,避免锁竞争。
- 非阻塞 I/O:Socket 设置为非阻塞模式,确保
read/write不会阻塞线程。 - 批量处理:通过一次
epoll_wait获取所有就绪事件,批量处理。
本章小结:Redis I/O 多路复用的设计精髓
- 统一抽象层:封装不同操作系统的多路复用 API,保证跨平台兼容性。
- 事件驱动模型:通过
aeEventLoop管理所有事件,实现高效调度。 - 非阻塞 + 回调:最大化 CPU 利用率,避免线程阻塞。
- 单线程无锁:消除多线程上下文切换和锁竞争的开销。
通过这种设计,Redis 在单线程中轻松支持数万甚至数十万的并发连接,成为高性能内存数据库的标杆。
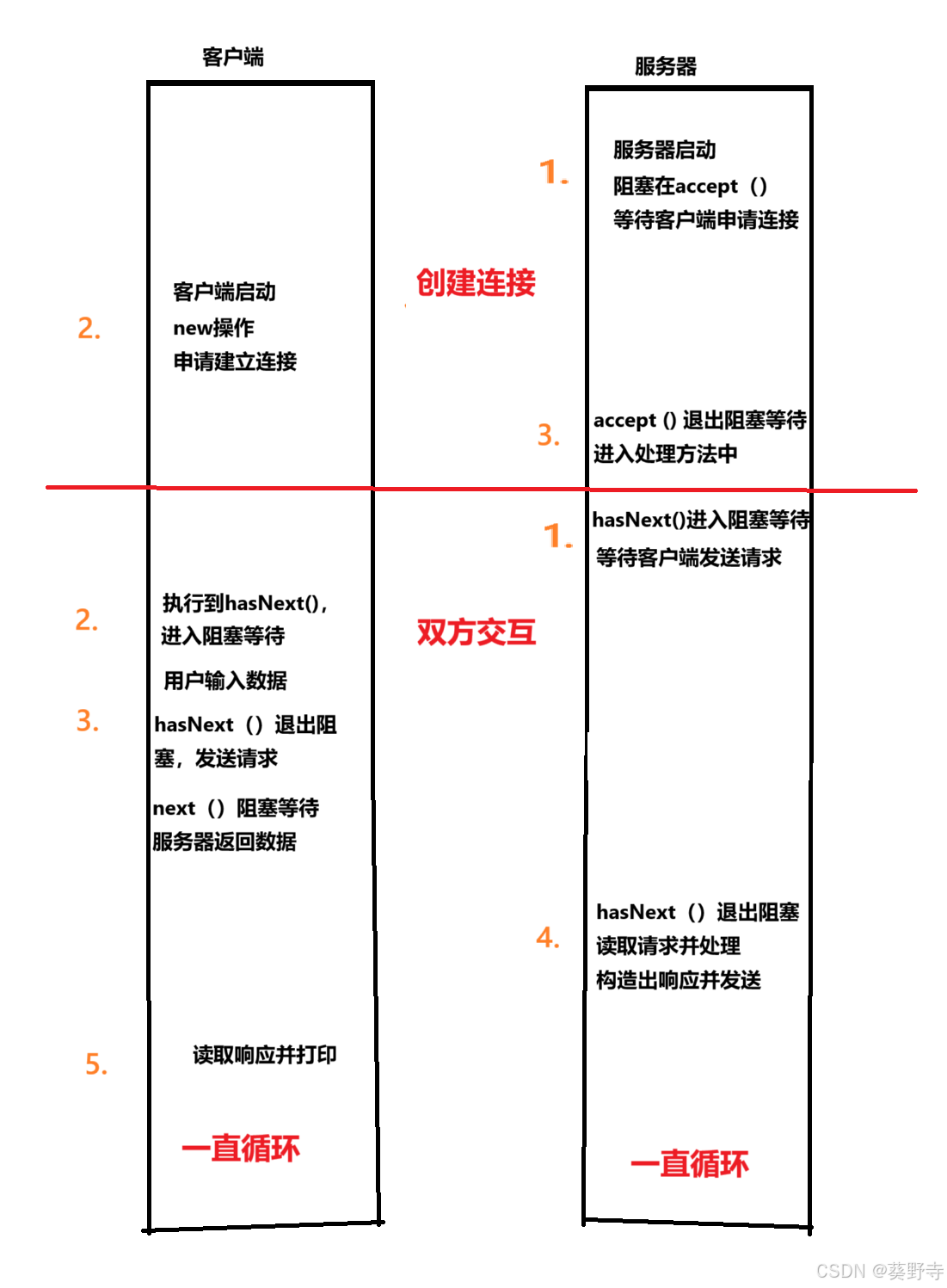
四、使用java实现I/O多路复用模型
以下是一个基于 Java NIO 的 I/O 多路复用模型的完整实现示例。该示例将创建一个简单的 Echo 服务器,使用 Selector 实现单线程管理多个客户端连接。
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
public class NIOMultiplexingServer {
private static final int PORT = 8080;
private static final int BUFFER_SIZE = 1024;
public static void main(String[] args) throws IOException {
// 1. 创建Selector(多路复用器)
Selector selector = Selector.open();
// 2. 创建ServerSocketChannel并配置为非阻塞模式
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(PORT));
serverSocketChannel.configureBlocking(false);
// 3. 将ServerSocketChannel注册到Selector,监听ACCEPT事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("Server started on port " + PORT);
// 4. 事件循环
while (true) {
// 阻塞等待就绪的事件(支持超时参数)
int readyChannels = selector.select();
if (readyChannels == 0) continue;
// 获取所有就绪的SelectionKey集合
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
keyIterator.remove(); // 必须手动移除已处理的key
try {
if (key.isAcceptable()) {
handleAccept(key, selector);
} else if (key.isReadable()) {
handleRead(key);
} else if (key.isWritable()) {
handleWrite(key);
}
} catch (IOException e) {
// 处理客户端异常断开
key.cancel();
key.channel().close();
System.out.println("Client disconnected abnormally");
}
}
}
}
// 处理新连接
private static void handleAccept(SelectionKey key, Selector selector) throws IOException {
ServerSocketChannel serverChannel = (ServerSocketChannel) key.channel();
SocketChannel clientChannel = serverChannel.accept();
clientChannel.configureBlocking(false);
// 注册读事件,并附加一个Buffer用于数据读写
clientChannel.register(selector, SelectionKey.OP_READ, ByteBuffer.allocate(BUFFER_SIZE));
System.out.println("New client connected: " + clientChannel.getRemoteAddress());
}
// 处理读事件
private static void handleRead(SelectionKey key) throws IOException {
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer buffer = (ByteBuffer) key.attachment();
int bytesRead = channel.read(buffer);
if (bytesRead == -1) { // 客户端正常关闭
System.out.println("Client closed connection: " + channel.getRemoteAddress());
channel.close();
return;
}
// 切换为读模式
buffer.flip();
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
String message = new String(data);
System.out.println("Received: " + message);
// 注册写事件(准备回写数据)
key.interestOps(SelectionKey.OP_WRITE);
buffer.rewind(); // 重置position以便重新读取数据
}
// 处理写事件
private static void handleWrite(SelectionKey key) throws IOException {
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer buffer = (ByteBuffer) key.attachment();
channel.write(buffer);
if (!buffer.hasRemaining()) { // 数据已全部写入
// 重新注册读事件
key.interestOps(SelectionKey.OP_READ);
buffer.clear(); // 重置Buffer
}
}
}
关键设计解析
1. Selector 核心机制
Selector.open():创建多路复用器(底层使用操作系统提供的epoll/kqueue)select():阻塞等待就绪事件(可设置超时时间)selectedKeys():获取所有就绪的事件集合
2. Channel 注册与事件类型
- 注册事件类型:
SelectionKey.OP_ACCEPT:新连接事件SelectionKey.OP_READ:数据可读事件SelectionKey.OP_WRITE:数据可写事件
- 非阻塞模式:
configureBlocking(false)是必须的
3. ByteBuffer 状态管理
flip():切换为读模式(position=0, limit=原position)clear():重置Buffer(position=0, limit=capacity)rewind():重置position为0(用于重复读取数据)
4. 事件处理流程
性能优化点
1. 零拷贝优化
// 使用FileChannel直接传输文件(无需用户态内存拷贝)
FileChannel fileChannel = new FileInputStream("largefile.txt").getChannel();
fileChannel.transferTo(0, fileChannel.size(), socketChannel);
2. 批量处理事件
// 使用selectedKeys迭代器快速处理所有事件
Iterator<SelectionKey> keyIterator = selector.selectedKeys().iterator();
while (keyIterator.hasNext()) {
// ...处理每个key...
}
3. 对象池化
// 复用ByteBuffer对象(避免频繁GC)
private static final ThreadLocal<ByteBuffer> bufferCache = ThreadLocal.withInitial(
() -> ByteBuffer.allocateDirect(1024) // 直接内存更高效
);
对比传统BIO模型
| 特性 | BIO(阻塞I/O) | NIO(多路复用) |
|---|---|---|
| 线程模型 | 1连接1线程 | 单线程管理所有连接 |
| 资源消耗 | 高(线程内存、上下文切换) | 低(单线程+事件驱动) |
| 吞吐量 | 低(受限于线程数) | 高(万级并发) |
| 编程复杂度 | 简单 | 较高(需处理事件状态机) |
运行测试
-
编译运行服务端:
javac NIOMultiplexingServer.java java NIOMultiplexingServer -
使用
telnet或nc测试:telnet localhost 8080 > Hello # 输入任意内容,服务器会原样返回
扩展方向
- 多线程优化:将业务处理与I/O线程分离(如使用线程池处理复杂逻辑)
- 协议解析:实现HTTP等复杂协议(需处理半包/粘包问题)
- 心跳机制:添加空闲连接检测(通过
IdleStateHandler类似机制)
通过这种方式,你可以用 Java 原生 NIO 实现一个高性能的 I/O 多路复用服务端,支撑高并发网络请求。
注意:本文章不适合初级人员使用,建议先了解NIO、BIO和Netty的前提之下进行学习