Hugging Face Transformers 是一个基于 PyTorch 和 TensorFlow 的开源库,专注于 最先进的自然语言处理(NLP)模型,如 BERT、GPT、RoBERTa、T5 等。它提供了 预训练模型、微调工具和推理 API,广泛应用于文本分类、机器翻译、问答系统等任务。
1. Hugging Face Transformers 的特点
✅ 丰富的预训练模型:支持 500+ 种模型(如 BERT、GPT-3、Llama 2)。
✅ 跨框架支持:兼容 PyTorch、TensorFlow、JAX。
✅ 易用 API:提供 pipeline,几行代码即可实现 NLP 任务。
✅ 社区支持:Hugging Face Hub 提供 数千个公开模型和数据集。
✅ 支持自定义训练:可微调(Fine-tune)模型以适应特定任务。
2. 主要功能
(1) 开箱即用的 NLP 任务
-
文本分类(情感分析、垃圾邮件检测)
-
命名实体识别(NER)
-
问答系统(QA)
-
文本生成(如 GPT-3、Llama 2)
-
机器翻译
-
摘要生成
(2) 核心组件
-
pipeline:快速调用预训练模型进行推理。 -
AutoModel/AutoTokenizer:自动加载模型和分词器。 -
Trainer:简化模型训练和微调流程。 -
Datasets:高效加载和处理数据集。
3. 安装与基本使用
(1) 安装
pip install transformers(可选)安装 PyTorch / TensorFlow:
pip install torch # PyTorch
pip install tensorflow # TensorFlow注:此处我尝试了安装gpu版本的,因为我电脑安装的cuda版本较低,所以试了几个版本的tensorflow-gpu版本都和transformer版本不匹配。
(2) 使用 pipeline 快速体验
from transformers import pipeline
# 情感分析 将下载的模型存于multilingual-sentiment-analysis路径下
classifier=pipeline("text-classification",model="./multilingual-sentiment-analysis")
print(classifier("我很骄傲"))
# 文本生成
# 指定本地路径加载模型,将下载的模型存于gpt2路径下
generator = pipeline("text-generation",model="./gpt2")# 本地模型路径
result=generator("AI will change",max_length=50)
print(result[0]['generated_text'])因为模型在线下载会比较麻烦,建议离线下载好,放到指定的文件夹下,方便调用
通过网盘分享的文件:gpt2
链接: https://pan.baidu.com/s/1Z9MZQKyOQrLlvn_jh3bGOg 提取码: 8ihe
通过网盘分享的文件:multilingual-sentiment-analysis
链接: https://pan.baidu.com/s/16e6Jvo44vetMmTxrQcZZqQ 提取码: tv4e
(3) 加载自定义模型
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 加载模型和分词器
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 处理输入
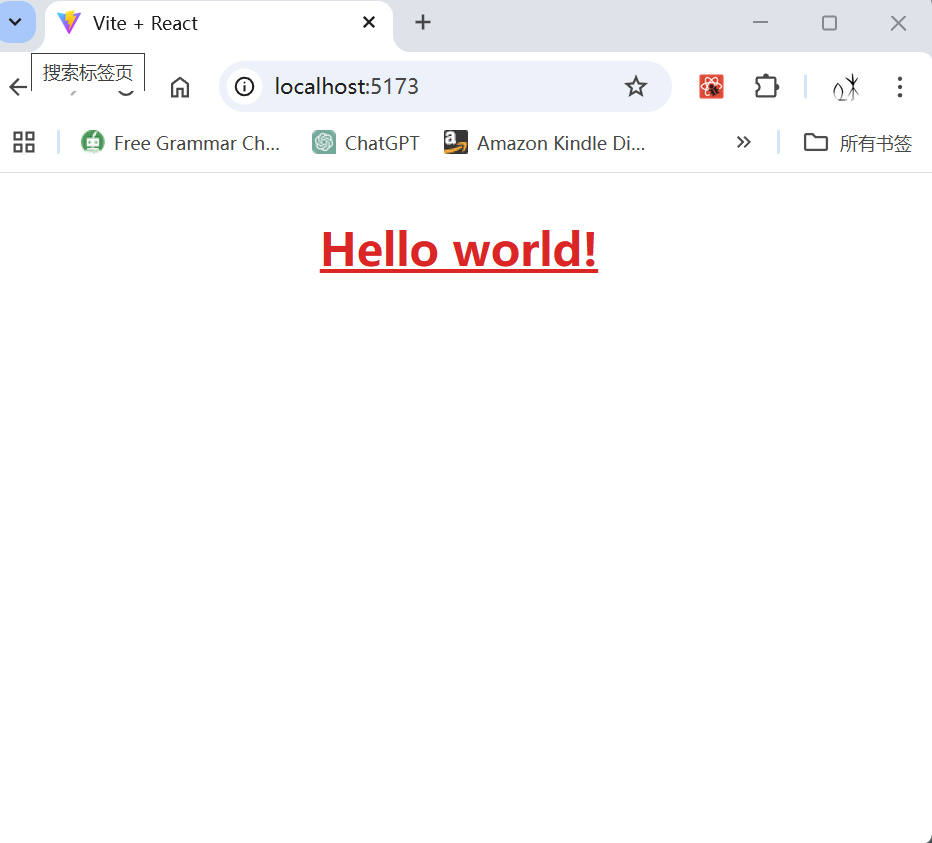
inputs = tokenizer("Hello, world!", return_tensors="pt")
outputs = model(**inputs)
print(outputs)4. 常用预训练模型
| 模型 | 用途 | 示例模型 ID |
|---|---|---|
| BERT | 文本分类、NER、问答 | bert-base-uncased |
| GPT-2 | 文本生成 | gpt2 |
| T5 | 文本摘要、翻译 | t5-small |
| RoBERTa | 更强大的 BERT 变体 | roberta-base |
| Llama 2 | Meta 开源的大语言模型 | meta-llama/Llama-2-7b |
5. 与 spaCy 的比较
| 特性 | Hugging Face Transformers | spaCy |
|---|---|---|
| 模型类型 | 深度学习(BERT、GPT) | 传统统计模型 + 部分 DL |
| 速度 | 较慢(依赖 GPU 加速) | ⚡ 极快(CPU 友好) |
| 适用任务 | 复杂 NLP(翻译、生成) | 基础 NLP(分词、NER) |
| 自定义训练 | ✅ 支持(微调 LLM) | ✅ 支持(但规模较小) |
| 易用性 | 中等(需了解深度学习) | 👍 非常简单 |
👉 推荐选择:
-
如果需要 最先进的 NLP(如 ChatGPT 类应用) → Hugging Face。
-
如果需要 快速处理结构化文本(如实体提取) → spaCy。
6. 实战案例
(1) 聊天机器人(使用 GPT-2)
from transformers import pipeline
chatbot = pipeline("text-generation", model="./gpt2")
response = chatbot("What is the future of AI?", max_length=50)
print(response[0]['generated_text'])(2) 自定义微调(Fine-tuning)
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=8,
num_train_epochs=3,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()(3)情感分析
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model_name = "./multilingual-sentiment-analysis"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
def predict_sentiment(texts):
inputs = tokenizer(texts, return_tensors="pt", truncation=True, padding=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)
sentiment_map = {0: "Very Negative", 1: "Negative", 2: "Neutral", 3: "Positive", 4: "Very Positive"}
return [sentiment_map[p] for p in torch.argmax(probabilities, dim=-1).tolist()]
texts = [
# English
"I absolutely love the new design of this app!", "The customer service was disappointing.", "The weather is fine, nothing special.",
# Chinese
"这家餐厅的菜味道非常棒!", "我对他的回答很失望。", "天气今天一般。",
# Spanish
"¡Me encanta cómo quedó la decoración!", "El servicio fue terrible y muy lento.", "El libro estuvo más o menos.",
# Arabic
"الخدمة في هذا الفندق رائعة جدًا!", "لم يعجبني الطعام في هذا المطعم.", "كانت الرحلة عادية。",
# Ukrainian
"Мені дуже сподобалася ця вистава!", "Обслуговування було жахливим.", "Книга була посередньою。",
# Hindi
"यह जगह सच में अद्भुत है!", "यह अनुभव बहुत खराब था।", "फिल्म ठीक-ठाक थी।",
# Bengali
"এখানকার পরিবেশ অসাধারণ!", "সেবার মান একেবারেই খারাপ।", "খাবারটা মোটামুটি ছিল।",
# Portuguese
"Este livro é fantástico! Eu aprendi muitas coisas novas e inspiradoras.",
"Não gostei do produto, veio quebrado.", "O filme foi ok, nada de especial.",
# Japanese
"このレストランの料理は本当に美味しいです!", "このホテルのサービスはがっかりしました。", "天気はまあまあです。",
# Russian
"Я в восторге от этого нового гаджета!", "Этот сервис оставил у меня только разочарование.", "Встреча была обычной, ничего особенного.",
# French
"J'adore ce restaurant, c'est excellent !", "L'attente était trop longue et frustrante.", "Le film était moyen, sans plus.",
# Turkish
"Bu otelin manzarasına bayıldım!", "Ürün tam bir hayal kırıklığıydı.", "Konser fena değildi, ortalamaydı.",
# Italian
"Adoro questo posto, è fantastico!", "Il servizio clienti è stato pessimo.", "La cena era nella media.",
# Polish
"Uwielbiam tę restaurację, jedzenie jest świetne!", "Obsługa klienta była rozczarowująca.", "Pogoda jest w porządku, nic szczególnego.",
# Tagalog
"Ang ganda ng lugar na ito, sobrang aliwalas!", "Hindi maganda ang serbisyo nila dito.", "Maayos lang ang palabas, walang espesyal.",
# Dutch
"Ik ben echt blij met mijn nieuwe aankoop!", "De klantenservice was echt slecht.", "De presentatie was gewoon oké, niet bijzonder.",
# Malay
"Saya suka makanan di sini, sangat sedap!", "Pengalaman ini sangat mengecewakan.", "Hari ini cuacanya biasa sahaja.",
# Korean
"이 가게의 케이크는 정말 맛있어요!", "서비스가 너무 별로였어요.", "날씨가 그저 그렇네요.",
# Swiss German
"Ich find dä Service i de Beiz mega guet!", "Däs Esä het mir nöd gfalle.", "D Wätter hüt isch so naja."
]
for text, sentiment in zip(texts, predict_sentiment(texts)):
print(f"Text: {text}\nSentiment: {sentiment}\n")7. 学习资源
-
官方文档: huggingface.co/docs/transformers
-
Hugging Face 课程: huggingface.co/course(免费 NLP 课程)
-
模型库: huggingface.co/models
总结
Hugging Face Transformers 是 当今最强大的 NLP 库之一,适用于:
-
前沿 AI 研究(如 LLM、ChatGPT 类应用)
-
企业级 NLP 解决方案(如智能客服、自动摘要)
-
快速实验 SOTA 模型
🚀 推荐下一步:
-
尝试
pipeline()运行不同任务(如"text-generation")。 -
在 Hugging Face Hub 上探索开源模型(如
bert-base-uncased)。 -
学习 微调(Fine-tuning) 以适应自定义数据集。








![AndroidTV D贝桌面-v3.2.5-[支持文件传输]](https://i-blog.csdnimg.cn/direct/d2e809f1129045b882f0be97c7d2ef24.png)