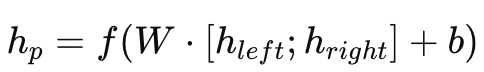Linux 下一切皆文件
* 统统抽象为文件,系统封装一层结构体之后,通过指针来访问
* 文章后面的 几个思考题都挺好的
* 后面涉及到的inode 机制,去年暑假的这篇文章,有详细的记录到过
【Linux】(26) 详解磁盘与文件系统:从物理结构到inode机制

prompt1
介绍 mmap的信息,这是一个Unix-like操作系统中的系统调用,用于将文件或设备映射到内存。
mmap(Memory Map)是一种内存映射技术,主要用于将文件或设备直接映射到进程的虚拟地址空间,使进程可以像操作内存一样读写文件,从而避免频繁的系统调用(如read/write)。以下是其核心要点:
1. 核心原理
- 虚拟内存映射:通过建立文件磁盘地址与进程虚拟地址的对应关系,实现文件内容与内存的直接交互。操作系统负责管理虚拟内存与物理存储的映射及数据同步(如脏页回写)CITE_
- 按需加载:文件内容并非一次性全部加载到物理内存,而是通过分页机制,仅在实际访问时加载所需部分
2. 主要用途
- 文件高效读写:减少数据拷贝次数(传统
read/write需两次拷贝,mmap只需一次),提升大文件或高频访问场景的性能 - 进程间通信(IPC):多个进程映射同一文件到内存,实现共享内存通信 。
- 内存管理优化:如MongoDB的MMAP存储引擎,将数据文件映射到内存,由操作系统管理内存换页
3. 工作模式
- 文件映射:将磁盘文件映射到内存,支持
MAP_SHARED(修改同步到文件)和MAP_PRIVATE(写时复制,修改不同步) - 匿名映射:创建初始化为零的内存区域,用于进程间共享数据(需指定
MAP_ANONYMOUS)
4. 函数原型
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);- 关键参数:
-
prot:内存保护(如PROT_READ/PROT_WRITE)。flags:映射类型(如MAP_SHARED/MAP_PRIVATE)。fd:文件描述符(匿名映射时设为-1)
5. 优势与场景
- 优势:减少用户态与内核态切换开销,提升IO效率;简化内存与文件的一致性管理。
- 典型场景:高频小数据读写、大文件处理、跨进程数据共享、数据库存储引擎
附:内存映射流程示意图
id: mmap-flow
name: mmap工作流程
type: mermaid
content: |-
graph LR
A[进程调用mmap] --> B[内核创建VMA映射]
B --> C[访问虚拟地址触发缺页中断]
C --> D[加载文件数据到物理内存]
D --> E[进程直接操作内存]
E --> F[内核同步脏页到文件]
prompt2:
在一个进程当中执行a.out程序,在映射共享区域的部分如果说a.out程序与共享对象链接,比如说标准C库当中的Libc,那么这些对象都是动态链接到这个库,然后在映射到用户虚拟地址空间当中的共享区域。我想问的是共享区域是指的相同的物理内存,那他们在共享LibC的时候,各个进程之间的虚拟地址可能也是不一样的,那这些不一样的虚拟地址它的分配机制是什么
在操作系统中,当多个进程通过动态链接共享标准C库(如libc)时,这些进程的虚拟地址空间中的共享区域映射到相同的物理内存,但各自的虚拟地址可能不同。这种机制通过以下关键点实现:
1. 动态链接与共享对象加载
- 动态链接器(ld.so):负责加载共享库(如
libc.so)到进程的虚拟地址空间。动态链接器会在进程启动时解析共享库的依赖关系,并通过mmap系统调用将共享库映射到进程的虚拟地址空间中的Memory Mapping Segment区域 - 地址空间布局随机化(ASLR):现代操作系统默认启用ASLR,共享库的虚拟地址在每次加载时会被随机化,以提高安全性。因此,不同进程中同一共享库的虚拟地址通常不同
2. 共享区域的物理内存映射
- 物理内存共享:共享库的代码段(
.text)和数据段(.data、.rodata)在物理内存中仅保留一份副本。所有进程的页表会将各自的虚拟地址映射到这些物理页,从而实现内存共享 - 写时复制(COW):对于可写的共享库数据段(如全局变量),初始时所有进程共享同一物理页。当某个进程尝试修改数据时,会触发COW机制,为该进程创建私有副本,但代码段仍保持共享
3. 虚拟地址分配机制
- 动态链接器的地址选择:动态链接器在加载共享库时,会根据进程虚拟地址空间的空闲区域选择合适的位置。例如,在32位Linux系统中,共享库通常映射到
0x40000000附近的区域;在64位系统中,可能映射到0x7f0000000000附近 - 位置无关代码(PIC):共享库编译为位置无关代码(通过
-fPIC选项),使得代码可以在任意虚拟地址运行,无需重定位绝对地址。这允许不同进程将同一共享库映射到不同的虚拟地址
4. 进程虚拟地址空间的管理
- 独立页表:每个进程维护独立的页表,记录虚拟地址到物理地址的映射关系。即使两个进程的共享库虚拟地址不同,页表也能将它们映射到相同的物理内存
- 内存映射区域(Memory Mapping Segment):共享库、文件映射和匿名映射均位于此区域。该区域的虚拟地址范围通常在堆和栈之间,具体位置由操作系统动态分配
5. 示例:libc的加载过程
- 进程启动:执行
a.out时,动态链接器ld.so被加载到进程的虚拟地址空间。 - 加载
libc.so:ld.so通过mmap将libc.so的代码段和数据段映射到进程的Memory Mapping Segment区域。 - 地址分配:若ASLR启用,
libc.so的基地址随机化;否则使用默认地址。 - 符号解析:动态链接器解析
a.out中调用的libc函数(如printf),将其地址填入进程的全局偏移表(GOT)
6. 虚拟地址不一致的影响
- 进程独立性:虚拟地址不同不影响进程的正确性,因为进程通过页表访问物理内存,且共享库代码为位置无关。
- 性能开销:若共享库未编译为PIC,动态链接器需进行重定位,增加启动时间
总结
共享库的虚拟地址分配机制通过动态链接器的地址选择、位置无关代码和页表映射实现。尽管不同进程的虚拟地址可能不同,但共享库的物理内存仅保留一份副本,从而在保证进程独立性的同时节省内存资源。这一机制是操作系统高效管理内存和多进程资源共享的核心技术之一
prompt3:
我们可以知道mmap可以创建虚拟地址,那么创建的这个虚拟地址他所用的页表和物理地址是怎么来的呢
在Linux系统中,mmap通过虚拟地址映射将文件、设备或匿名内存区域映射到进程的虚拟地址空间。其核心机制涉及页表管理和物理地址分配,具体实现过程如下:
1. 虚拟地址的创建与页表管理
- 虚拟地址分配:
mmap通过内核的vm_area_struct结构为进程分配一段连续的虚拟地址空间(属于进程的Memory Mapping Segment区域)。该虚拟地址范围由内核动态选择,通常位于堆和栈之间 - 页表更新:
内核调用remap_pfn_range函数建立页表项,将虚拟地址映射到物理地址。每个进程的页表(由MMU管理)记录虚拟地址到物理地址的映射关系。例如,ARM架构的一级页表通过虚拟地址高位(如VA[31:20])索引页表项,获取物理地址高位(PA[31:20]),完成地址转换
2. 物理地址的来源
物理地址的分配取决于mmap的映射类型:
(1)文件映射
- 磁盘文件:
映射文件时,物理地址对应文件的磁盘块(通过文件系统inode定位)。初次访问时触发缺页异常,内核将文件内容加载到物理内存的页面缓存中,并更新页表项指向该物理页 - 共享物理页:
多个进程映射同一文件时,共享同一物理页(代码段只读,数据段通过COW机制私有化)
(2)匿名映射
- 物理内存分配:
匿名映射(如MAP_ANONYMOUS)的物理地址由内核动态分配空闲物理页。首次访问时触发缺页,内核分配物理页并清零初始化
(3)设备内存映射
- 硬件设备:
映射设备寄存器或DMA缓冲区时(如/dev/mem),物理地址直接来自设备的物理地址空间,需通过remap_pfn_range将设备物理页框号(PFN)映射到用户虚拟地址
3. 缺页异常与物理内存加载
mmap的映射过程分为两个阶段:
- 虚拟地址映射建立:
内核仅创建虚拟地址区域和页表项,但此时物理内存可能未分配(文件未加载或匿名页未初始化)- 首次访问触发缺页:
当进程访问虚拟地址时,MMU发现页表项无效,触发缺页异常。内核处理异常:
- 文件映射:从磁盘读取数据到物理内存,更新页表项指向该物理页
- 匿名映射:分配物理页并初始化为零
4. 页表与物理地址的动态管理
- 页表独立性:
每个进程拥有独立的页表,即使映射同一物理内存(如共享库),不同进程的虚拟地址可能不同,但页表项指向相同物理页 - 写时复制(COW):
对私有映射(MAP_PRIVATE)的写操作会触发COW,内核复制物理页并更新页表项指向新页,保持原始物理页不变
5. 用户态与内核态协作
- 用户态调用:
用户程序通过mmap系统调用指定映射参数(地址、长度、权限等)。 - 内核态实现:
内核验证参数合法性后,调用do_mmap分配虚拟地址区域,并通过文件操作或驱动程序的mmap方法(如remap_pfn_range)完成物理地址映射
总结
mmap通过以下机制实现虚拟地址到物理地址的映射:
- 虚拟地址分配:由内核动态选择进程的Memory Mapping Segment区域。
- 页表管理:通过
remap_pfn_range更新页表项,建立虚拟地址与物理地址的映射。 - 物理地址来源:文件映射从磁盘加载,匿名映射由内核分配,设备映射直接使用硬件地址。
- 按需加载:缺页异常机制延迟物理内存的分配与加载,提高资源利用率
prompt4
文件描述符 fd 究竟是什么?
fd 是什么?
fd 是 File descriptor 的缩写,中文名叫做:文件描述符。文件描述符是一个非负整数,本质上是一个索引值(这句话非常重要)。
什么时候拿到的 fd ?
当打开一个文件时,内核向进程返回一个文件描述符( open 系统调用得到 ),后续 read、write 这个文件时,则只需要用这个文件描述符来标识该文件,将其作为参数传入 read、write 。
fd 的值范围是什么?
在 POSIX 语义中,0,1,2 这三个 fd 值已经被赋予特殊含义,分别是标准输入( STDIN_FILENO ),标准输出( STDOUT_FILENO ),标准错误( STDERR_FILENO )。
文件描述符是有一个范围的:0 ~ OPEN_MAX-1 ,最早期的 UNIX 系统中范围很小,现在的主流系统单就这个值来说,变化范围是几乎不受限制的,只受到系统硬件配置和系统管理员配置的约束。
你可以通过 ulimit 命令查看当前系统的配置:
➜ ulimit -n
4864如上,我系统上进程默认最多打开 4864 文件。
窥探 Linux 内核
fd究竟是什么?必须去 Linux 内核看一眼。
用户使用系统调用 open 或者 creat 来打开或创建一个文件,用户态得到的结果值就是 fd ,后续的 IO 操作全都是用 fd 来标识这个文件,可想而知内核做的操作并不简单,我们接下来就是要揭开这层面纱。
task_struct
首先,我们知道进程的抽象是基于 struct task_struct 结构体,这是 Linux 里面最复杂的结构体之一 ,成员字段非常多,我们今天不需要详解这个结构体,我稍微简化一下,只提取我们今天需要理解的字段如下:
struct task_struct {
// ...
/* Open file information: */
struct files_struct *files;
// ...
}files; 这个字段就是今天的主角之一,files 是一个指针,指向一个为 struct files_struct 的结构体。这个结构体就是用来管理该进程打开的所有文件的管理结构。
重点理解一个概念:
struct task_struct 是进程的抽象封装,标识一个进程,在 Linux 里面的进程各种抽象视角,都是这个结构体给到你的。当创建一个进程,其实也就是 new 一个 struct task_struct 出来;
files_struct
好,上面通过进程结构体引出了 struct files_struct 这个结构体。这个结构体管理某进程打开的所有文件的管理结构,这个结构体本身是比较简单的:
/*
* Open file table structure
*/
struct files_struct {
// 读相关字段
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
// 打开的文件管理结构
struct fdtable __rcu *fdt;
struct fdtable fdtab;
// 写相关字段
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file * fd_array[NR_OPEN_DEFAULT];
};files_struct 这个结构体我们说是用来管理所有打开的文件的。怎么管理?本质上就是数组管理的方式,所有打开的文件结构都在一个数组里。这可能会让你疑惑,数组在那里?有两个地方:
struct file * fd_array[NR_OPEN_DEFAULT]是一个静态数组,随着files_struct结构体分配出来的,在 64 位系统上,静态数组大小为 64;struct fdtable也是个数组管理结构,只不过这个是一个动态数组,数组边界是用字段描述的;
思考:为什么会有这种静态 + 动态的方式?
性能和资源的权衡 !大部分进程只会打开少量的文件,所以静态数组就够了,这样就不用另外分配内存。如果超过了静态数组的阈值,那么就动态扩展。
可以回忆下,这个是不是跟
inode的直接索引,一级索引的优化思路类似。
fdtable
简单介绍下 fdtable 结构体,这个结构体就是封装用来管理 fd 的结构体,fd 的秘密就在这个里面。简化结构体如下:
struct fdtable {
unsigned int max_fds;
struct file __rcu **fd; /* current fd array */
};注意到 fdtable.fd 这个字段是一个二级指针,什么意思?
- 就是指向
fdtable.fd是一个指针字段,指向的内存地址还是存储指针的(元素指针类型为struct file *)。换句话说,fdtable.fd指向一个数组,数组元素为指针(指针类型为struct file *)。 - 其中
max_fds指明数组边界。
files_struct 小结
file_struct 本质上是用来管理所有打开的文件的,内部的核心是由一个静态数组和动态数组管理结构实现。
还记得上面我们说文件描述符 fd 本质上就是索引吗?这里就把概念接上了,fd 就是这个数组的索引,也就是数组的槽位编号而已。 通过非负数 fd 就能拿到对应的 struct file 结构体的地址。
- 所以 fd 就是地址数组的索引标识,这样好给上层应用调用地址空间
我们把概念串起来(注意,这里为了突出 fd 的本质,把 fdtable 管理简化掉):
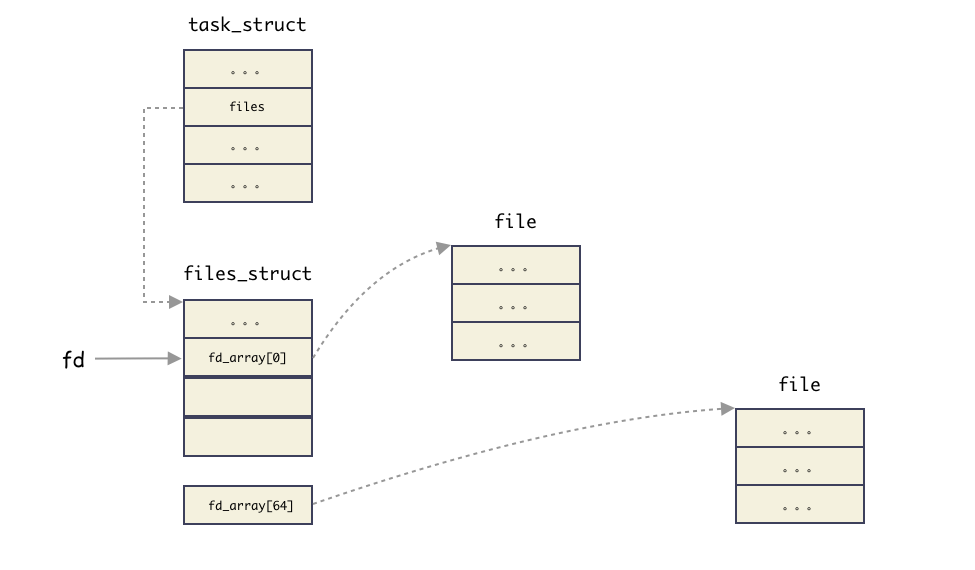
fd真的就是files这个字段指向的指针数组的索引而已(仅此而已)。通过files_struct能够找到对应文件的struct file结构体;
file
- 现在我们知道了
fd本质是数组索引,数组元素是struct file结构体的指针。那么这里就引出了一个struct file的结构体。这个结构体又是用来干什么的呢? - 这个结构体是用来表征进程打开的文件的。简化结构如下:
struct file {
// ...
struct path f_path;
struct inode *f_inode;
const struct file_operations *f_op;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
// ...
}这个结构体非常重要,它标识一个进程打开的文件,下面解释 IO 相关的几个最重要的字段:
f_path:标识文件名f_inode:非常重要的一个字段,inode这个是 vfs 的inode类型,是基于具体文件系统之上的抽象封装;f_pos:这个字段非常重要,偏移,对,就是当前文件偏移。还记得上一篇 IO 基础里也提过偏移对吧,指的就是这个,f_pos在open的时候会设置成默认值seek的时候可以更改,从而影响到write/read的位置;
思考问题
思考问题一:
files_struct结构体只会属于一个进程,那么struct file这个结构体呢,是只会属于某一个进程?还是可能被多个进程共享?
划重点:struct file 是属于系统级别的结构,换句话说是可以共享与多个不同的进程。
思考问题二:什么时候会出现多个进程的
fd指向同一个file结构体?
比如 fork 的时候,父进程打开了文件,后面 fork 出一个子进程。这种情况就会出现共享 file 的场景。如图:
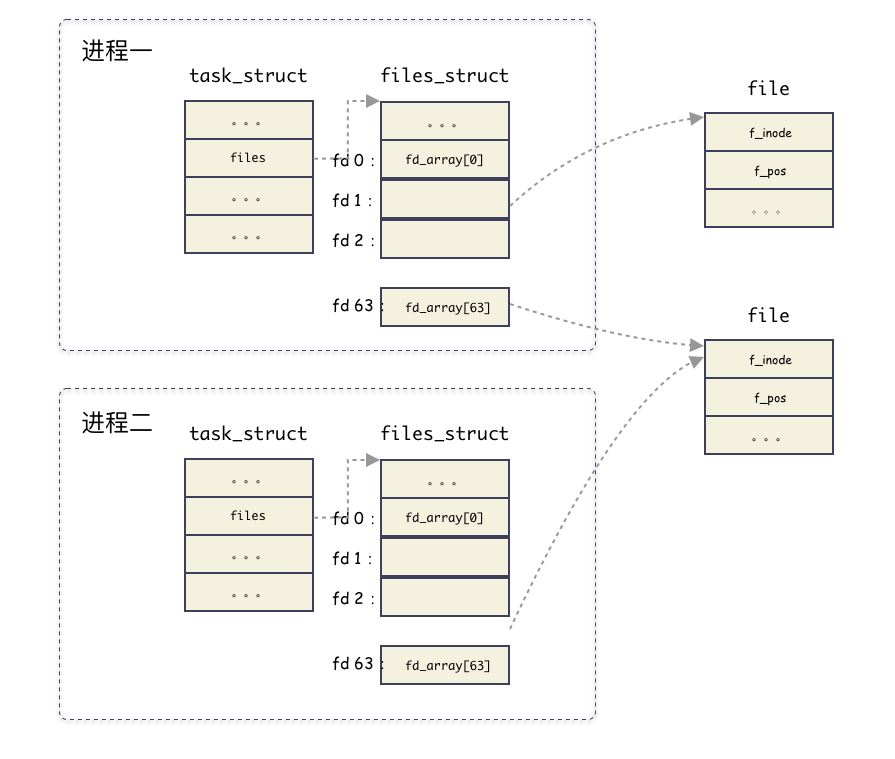
思考问题三:在同一个进程中,多个
fd可能指向同一个 file 结构吗?
可以。dup 函数就是做这个的。
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);inode
我们看到 struct file 结构体里面有一个 inode 的指针,也就自然引出了 inode 的概念。
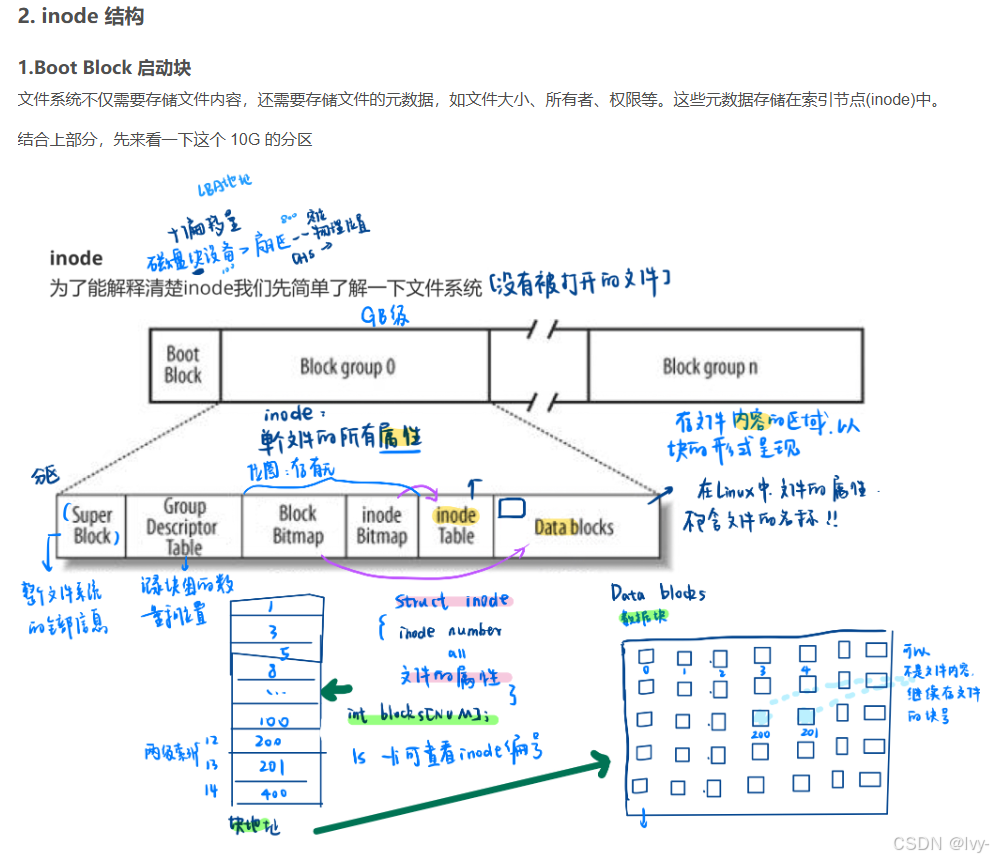
这个指向的 inode 并没有直接指向具体文件系统的 inode ,而是操作系统抽象出来的一层虚拟文件系统,叫做 VFS ( Virtual File System )
然后在 VFS 之下才是真正的文件系统,比如 ext4 之类的。
完整架构图如下:
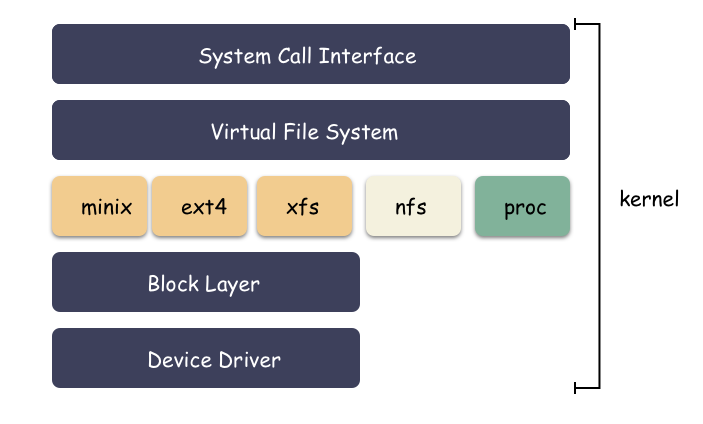
思考:为什么会有这一层vfs封装呢?
其实很容里理解,就是解耦。
- 如果让
struct file直接和struct ext4_inode这样的文件系统对接,那么会导致struct file的处理逻辑非常复杂,因为每对接一个具体的文件系统,就要考虑一种实现。 - 所以操作系统必须把底下文件系统屏蔽掉,对外提供统一的
inode概念,通过VFS,对下定义好接口进行回调注册。这样让inode的概念得以统一,Unix 一切皆文件的基础就来源于此。
再来看一样 VFS 的 inode 的结构:
struct inode {
// 文件相关的基本信息(权限,模式,uid,gid等)
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
// 回调函数
const struct inode_operations *i_op;
struct super_block *i_sb;
struct address_space *i_mapping;
// 文件大小,atime,ctime,mtime等
loff_t i_size;
struct timespec64 i_atime;
struct timespec64 i_mtime;
struct timespec64 i_ctime;
// 回调函数
const struct file_operations *i_fop;
struct address_space i_data;
// 指向后端具体文件系统的特殊数据
void *i_private; /* fs or device private pointer */
};- 其中包括了一些基本的文件信息,包括 uid,gid,大小,模式,类型,时间等等。
- 一个 vfs 和 后端具体文件系统的纽带:
i_private字段。**用来传递一些具体文件系统使用的数据结构。 - 至于
i_op回调函数在构造inode的时候,就注册成了后端的文件系统函数,比如 ext4 等等。
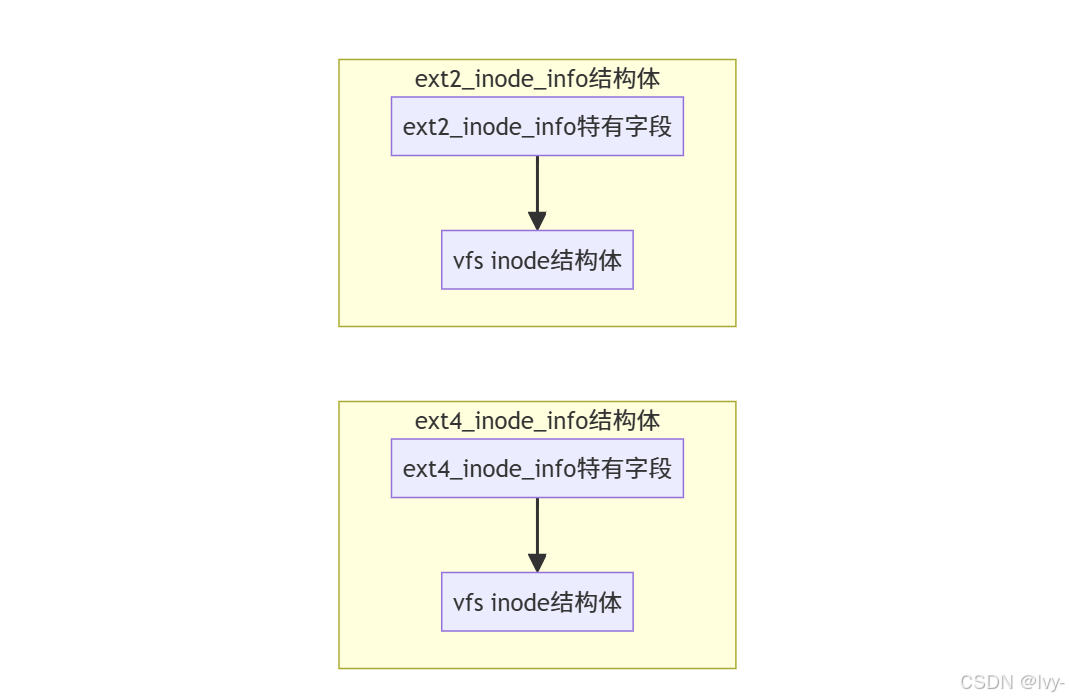
思考问题:通用的 VFS 层,定义了所有文件系统通用的 inode,叫做 vfs inode,而后端文件系统也有自身特殊的 inode 格式,该格式是在 vfs inode 之上进行扩展的,怎么通过 vfs inode 怎么得到具体文件系统的 inode 呢?
下面以 ext4 文件系统举例(因为所有的文件系统套路一样),ext4 的 inode 类型是 struct ext4_inode_info 。
划重点:方法其实很简单,这个是属于 c 语言一种常见的(也是特有)编程手法:强转类型。vfs inode 出生就和 ext4_inode_info 结构体分配在一起的,直接通过 vfs inode 结构体的地址强转类型就能得到 ext4_inode_info 结构体。
struct ext4_inode_info {
// ext4 inode 特色字段
// ...
// 重要!!!
struct inode vfs_inode;
};举个例子,现已知 inode 地址和 vfs_inode 字段的内偏移如下:
- inode 的地址为 0xa89be0;
ext4_inode_info里有个内嵌字段 vfs_inode,类型为struct inode,该字段在结构体内偏移为 64 字节;
则可以得到:
ext4_inode_info 的地址为
- (struct ext4_inode_info *)(0xa89be0 - 64)
强转方法使用了一个叫做 container_of 的宏,如下:
// 强转函数
static inline struct ext4_inode_info *EXT4_I(struct inode *inode)
{
return container_of(inode, struct ext4_inode_info, vfs_inode);
}
// 强转实际封装
#define container_of(ptr, type, member) \
(type *)((char *)(ptr) - (char *) &((type *)0)->member)
#endif所以,你懂了吗?
分配 inode 的时候,其实分配的是 ext4_inode_info 结构体,包含了 vfs inode,然后对外给出去 vfs_inode 字段的地址即可。VFS 层拿 inode 的地址使用,底下文件系统强转类型后,取外层的 inode 地址使用。
举个 ext4 文件系统的例子:
static struct inode *ext4_alloc_inode(struct super_block *sb)
{
struct ext4_inode_info *ei;
// 内存分配,分配 ext4_inode_info 的地址
ei = kmem_cache_alloc(ext4_inode_cachep, GFP_NOFS);
// ext4_inode_info 结构体初始化
// 返回 vfs_inode 字段的地址
return &ei->vfs_inode;
}vfs 拿到的就是这个 inode 地址。
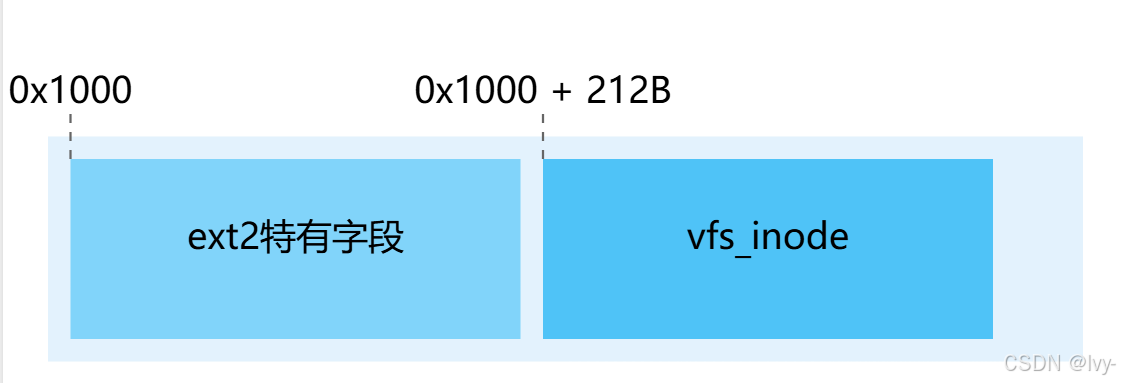
三步转换过程(以ext2为例):
- 已知指针:
struct inode *vfs_inode_ptr = 0x1000 + 212(指向vfs_inode) - 计算偏移量:
offsetof(struct ext2_inode_info, vfs_inode) = 212 - 反向计算:
(char *)vfs_inode_ptr - 212 = 0x1000(得到ext2_inode_info起始地址)
抽象出了一个统一的
vfs_inode_ptr,然后通过不同的偏移量,来实现对不同文件系统接口的访问划分,例如说ext2(212B) 和ext4(64B) 他们的偏移量是不一样的可以理解为通过
vfs_inode_ptr这一个基类,减去不同的偏移量,来实现访问不同文件系统的是一个多态的过程
划重点:inode 的内存由后端文件系统分配,vfs inode 结构体内嵌在不同的文件系统的 inode 之中。不同的层次用不同的地址,ext4 文件系统用
ext4_inode_info的结构体的地址,vfs 层用ext4_inode_info.vfs_inode字段的地址。
这种用法在 C 语言编程中很常见,算是 C 的特色了(仔细想想,这种用法和面向对象的多态的实现异曲同工)。
思考问题:怎么理解 vfs
inode和ext2_inode_info,ext4_inode_info等结构体的区别?
所有文件系统共性的东西抽象到 vfs inode ,不同文件系统差异的东西放在各自的 inode 结构体中。
小结梳理
当用户打开一个文件,用户只得到了一个 fd 句柄,但内核做了很多事情,梳理下来,我们得到几个关键的数据结构,这几个数据结构是有层次递进关系的,我们简单梳理下:
- 进程结构
task_struct:表征进程实体,每一个进程都和一个task_struct结构体对应,其中task_struct.files指向一个管理打开文件的结构体fiels_struct; - 文件表项管理结构
files_struct:用于管理进程打开的 open 文件列表,内部以数组的方式实现(静态数组和动态数组结合)。返回给用户的fd就是这个数组的编号索引而已,索引元素为file结构;
files_struct只从属于某进程;- 文件
file结构:表征一个打开的文件,内部包含关键的字段有:当前文件偏移,inode 结构地址;
-
- 该结构虽然由进程触发创建,但是
file结构可以在进程间共享;
- 该结构虽然由进程触发创建,但是
- vfs
inode结构体:文件file结构指向 的是 vfs 的inode,这个是操作系统抽象出来的一层,用于屏蔽后端各种各样的文件系统的inode差异;
-
- inode 这个具体进程无关,是文件系统级别的资源;
- ext4
inode结构体(指代具体文件系统 inode ):后端文件系统的inode结构,不同文件系统自定义的结构体,ext2 有ext2_inode_info,ext4 有ext4_inode_info,minix 有minix_inode_info,这些结构里都是内嵌了一个 vfsinode结构体,原理相同;
完整的架构图:
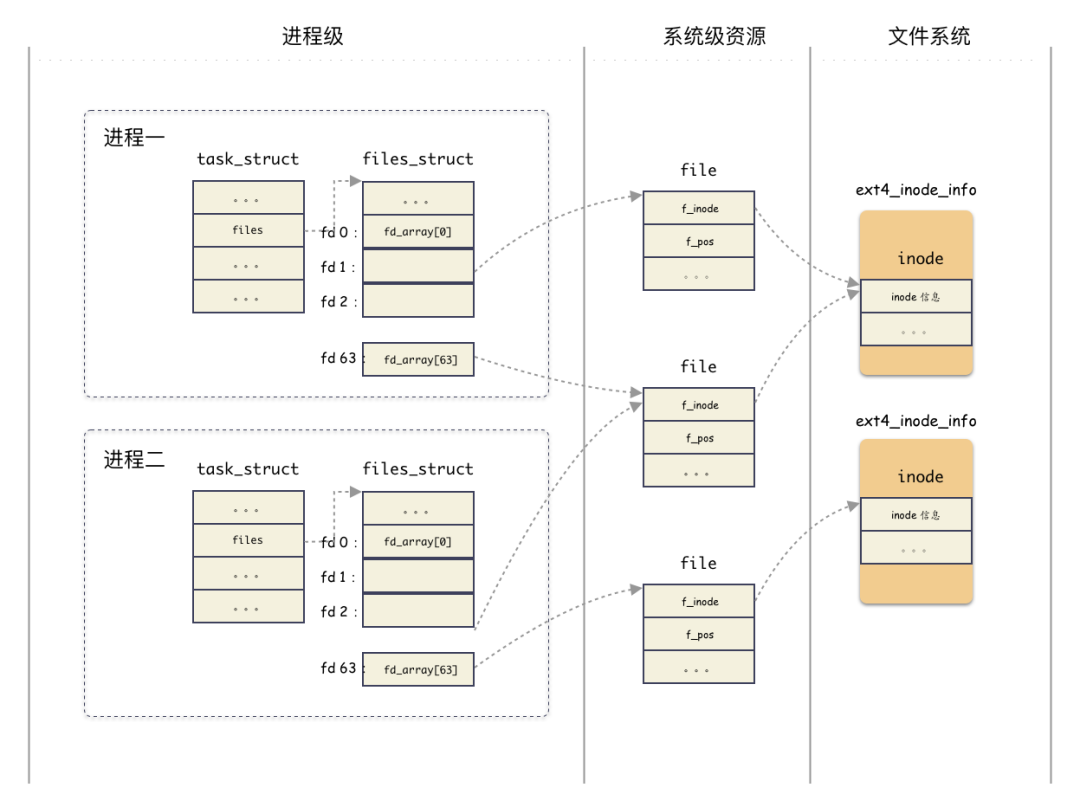
思考实验
现在我们已经彻底了解 fd 这个所谓的非负整数代表的深层含义了,我们可以准备一些 IO 的思考举一反三。
文件读写( IO )的时候会发生什么?
-
- 在完成 write 操作后,在文件
file中的当前文件偏移量会增加所写入的字节数,如果这导致当前文件偏移量超处了当前文件长度,则会把 inode 的当前长度设置为当前文件偏移量(也就是文件变长) O_APPEND标志打开一个文件,则相应的标识会被设置到文件file状态的标识中,每次对这种具有追加写标识的文件执行write操作的时候,file的当前文件偏移量首先会被设置成inode结构体中的文件长度,这就使得每次写入的数据都追加到文件的当前尾端处(该操作对用户态提供原子语义);- 若一个文件
seek定位到文件当前的尾端,则file中的当前文件偏移量设置成inode的当前文件长度; seek函数值修改file中的当前文件偏移量,不进行任何I/O操作;- 每个进程对有它自己的
file,其中包含了当前文件偏移,当多个进程写同一个文件的时候,由于一个文件 IO 最终只会是落到全局的一个inode上,这种并发场景则可能产生用户不可预期的结果;
- 在完成 write 操作后,在文件
总结
回到初心,理解 fd 的概念有什么用?
一切 IO 的行为到系统层面都是以 fd 的形式进行。无论是 C/C++,Go,Python,JAVA 都是一样,任何语言都是一样,这才是最本源的东西,理解了 fd 关联的一系列结构,才能对 IO 游刃有余。
简要的总结:
-
- 从姿势上来讲,用户
open文件得到一个非负数句柄fd,之后针对该文件的 IO 操作都是基于这个fd; - 文件描述符
fd本质上来讲就是数组索引,fd等于 5 ,那对应数组的第 5 个元素而已,该数组是进程打开的所有文件的数组,数组元素类型为struct file; - 结构体
task_struct对应一个抽象的进程,files_struct是这个进程管理该进程打开的文件数组管理器。fd则对应了这个数组的编号,每一个打开的文件用file结构体表示,内含当前偏移等信息; file结构体可以为进程间共享,属于系统级资源,同一个文件可能对应多个file结构体,file内部有个inode指针,指向文件系统的inode;inode是文件系统级别的概念,只由文件系统管理维护,不因进程改变(file是进程出发创建的,进程open同一个文件会导致多个file,指向同一个inode);
- 从姿势上来讲,用户
回顾一眼架构图:
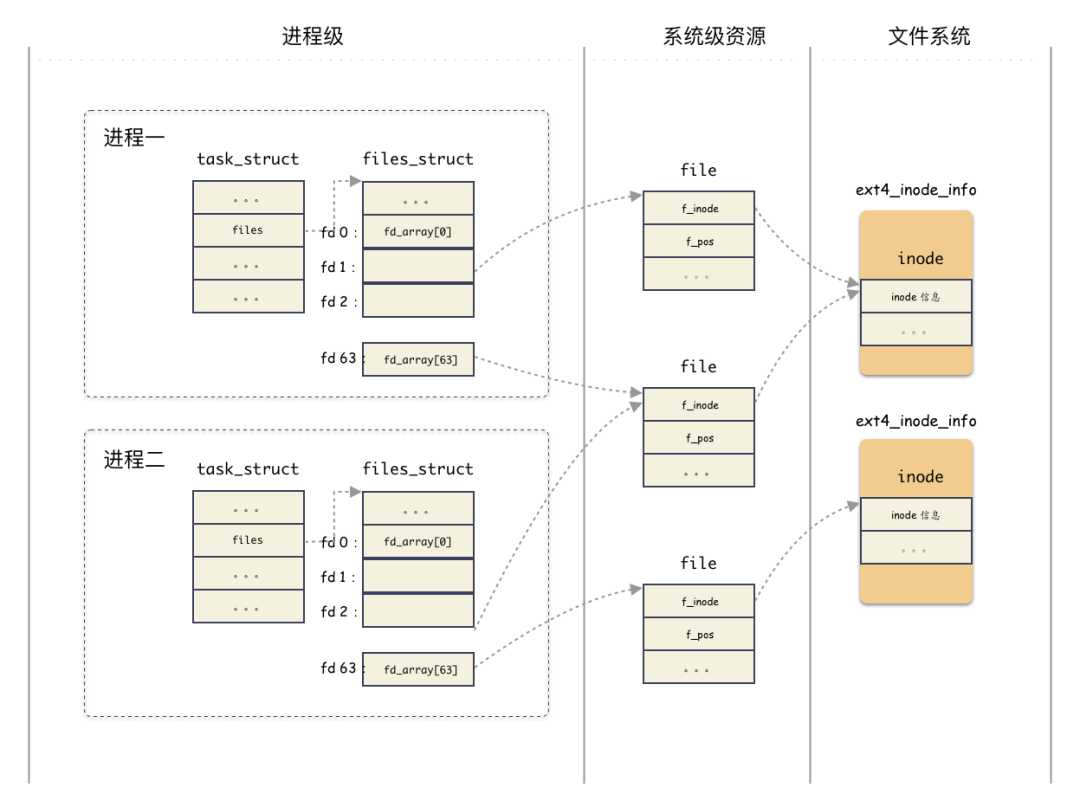
~完~
后记
内核把最复杂的活干了,只暴露给我们最简单的一个非负整数
fd。所以,绝大部分场景会用
fd就行,倒不用想太多。当然如果能再深入看一眼知其所以然是最好不过。本文分享是基础准备篇,希望能给你带来不一样的 IO 视角。