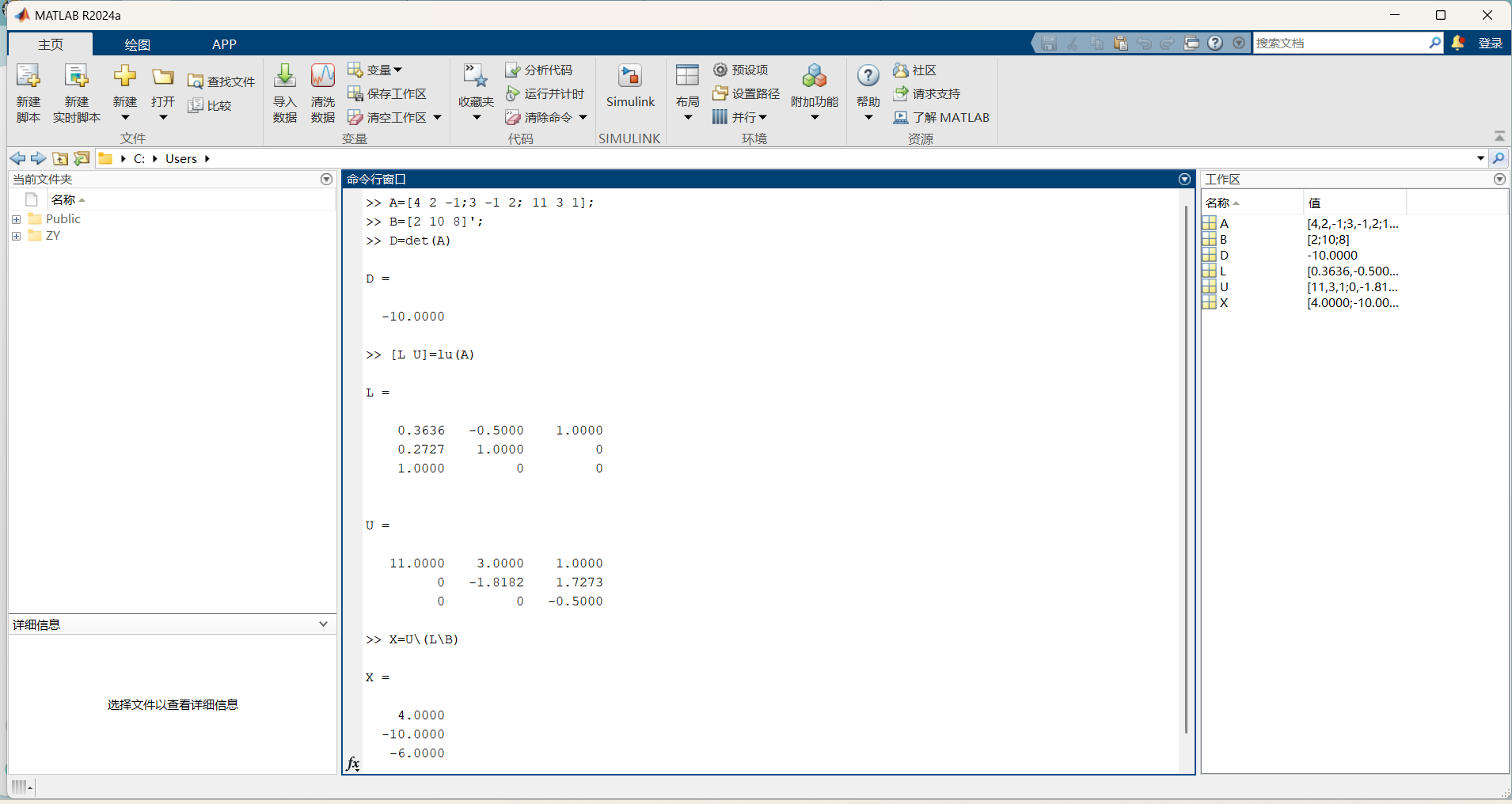
地址空间(Address Space)
一、物理地址空间(Physical Address Space)
物理地址空间 是指 RAM 和设备内存 在系统内存总线上所呈现的地址布局。
- 举例:在典型的
32
32
32 位 Intel 架构中,
- RAM(主内存)通常被映射在低地址段;
- 显卡内存或其他外设地址被映射在高地址段。
📌 解释:
- 所谓“物理地址”是指 CPU 实际访问主板、内存条等硬件资源的地址;
- 它由硬件总线决定,不受程序控制。
二、虚拟地址空间(Virtual Address Space)
虚拟地址空间(有时简称为“地址空间”)是指当系统开启虚拟内存管理模块(如分页机制、保护模式)后,CPU 所看到的地址空间。
- 这时,每个地址都是一个“虚拟地址”,必须通过页表(Page Table)映射到物理内存地址。
- 内核负责建立这种虚拟地址到物理地址的映射关系。
📌 常用术语解释:
- “分页开启”也叫做 Paging Enabled \text{Paging Enabled} Paging Enabled,即启用了 MMU;
- 操作系统通过页表控制不同虚拟地址段的访问权限和映射目标。
三、进程地址空间 vs 内核地址空间
1. 进程空间(Process Address Space)
这是指与每个用户态进程相关联的虚拟地址空间:
- 通常从地址 0 0 0 开始,呈现为一块连续内存区域;
- 包括代码段(text)、数据段(data)、堆(heap)和栈(stack)等;
- 不同进程之间的地址空间互相独立,彼此不可见。
2. 内核空间(Kernel Address Space)
这是内核模式代码看到的地址空间:
- 包含内核本身的代码和数据、驱动模块、内核栈等;
- 有更高的访问权限;
- 用户态程序不能直接访问这一空间。
四、用户空间与内核空间共享虚拟地址空间
在大多数操作系统中,用户空间和内核空间是共享同一个虚拟地址空间的:
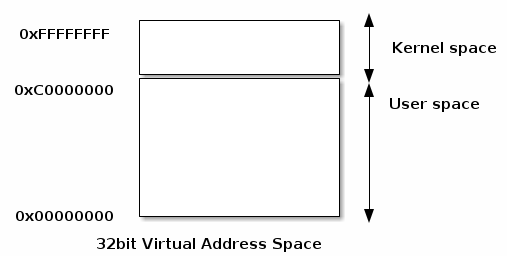
- 典型做法是:
- 用户空间占据虚拟地址空间的低地址部分;
- 内核空间占据虚拟地址空间的高地址部分;
- 为了防止用户程序访问内核区域,内核会在页表中设定访问权限。
📌 示意公式:
- 假设虚拟地址空间为 4 4 4 GB:
- 0 x 00000000 0x00000000 0x00000000 ~ 0 x B F F F F F F F 0xBFFFFFFF 0xBFFFFFFF 为用户空间;
- 0 x C 0000000 0xC0000000 0xC0000000 ~ 0 x F F F F F F F F 0xFFFFFFFF 0xFFFFFFFF 为内核空间(如 Linux 通常采用的布局)。
执行上下文(Execution Contexts)
操作系统内核最重要的任务之一是处理中断(Interrupt),而且必须非常高效地处理。因此,内核为此引入了一种特殊的执行上下文(execution context)。
一、中断上下文(Interrupt Context)
当内核因为硬件或软件中断而执行特定代码时,我们称之为运行在中断上下文中。
-
包括中断处理函数(Interrupt Handler)及其相关机制;
-
所有中断上下文的代码都运行在 内核态(Kernel Mode);
-
存在一些限制,内核开发者必须注意:
❌ 不能调用阻塞(blocking)函数,比如
sleep()或wait_event()
❌ 不能直接访问用户空间内存
📌 解释:
- 中断处理必须尽快完成,任何阻塞操作都会导致系统性能下降甚至死锁;
- 这是非抢占性环境non-preemptible中关键的执行上下文。
二、进程上下文(Process Context)
与中断上下文相对的是进程上下文。
- 当内核为某个进程或线程服务时,就处于进程上下文中;
- 可以运行在:
- 用户态(执行应用代码)
- 内核态(执行系统调用)
📌 好处:
- 在进程上下文中可以执行阻塞操作;
- 也可以安全访问用户空间数据。
多任务(Multitasking)
多任务处理指的是操作系统“同时”执行多个程序的能力。
- 实际上是通过快速切换context switch在多个进程之间实现的。
1. 协作式多任务(Cooperative Multitasking)
- 每个程序主动将 CPU 控制权交还给操作系统;
- 如果程序不主动释放,系统就无法切换任务。
❗ 容易出现“独占 CPU”的问题。
2. 抢占式多任务(Preemptive Multitasking)
- 内核设定时间片time slice限制每个进程的运行时间;
- 例如一个进程最多运行 100 m s 100ms 100ms,超时后会被强制切换。
📌 更加公平,不会因一个程序出问题而拖慢整个系统。
抢占式内核(Preemptive Kernel)
抢占式多任务(preemptive multitasking) ≠ 抢占式内核(preemptive kernel)
- 抢占式内核指的是:即便处于内核态,运行中的进程也可以被中断并切换;
- 而某些操作系统虽然支持抢占式多任务,但其内核本身却是不可抢占的。
✅ 抢占式内核提高系统响应性
❌ 但增加了同步复杂度,如锁管理
可分页的内核内存(Pageable Kernel Memory)
- 如果内核支持将某些内核空间的数据(如代码段、数据段、内核堆栈等)换出到磁盘,则称之为支持分页内核内存(pageable kernel memory)。
📌 优点:节省 RAM
📌 缺点:换入换出开销,必须避免在中断上下文中访问
内核栈(Kernel Stack)
每个进程在内核态下执行时,会使用一个私有的内核栈。
-
该栈用于:
- 保存函数调用链
- 存储内核函数中的局部变量
-
大小通常很小: 4 K B 4KB 4KB ~ 12 K B 12KB 12KB(依平台架构而异)
⚠️ 避免:
- 在栈上分配大型数据结构
- 递归调用层级太深
可移植性(Portability)
为了让操作系统能在不同硬件平台上运行,现代内核采用以下顶层结构设计:
-
架构相关代码(Architecture-specific)
- 包含平台相关的 C 和汇编代码(如中断向量表、启动流程等)
-
架构无关代码(Architecture-independent)
- 包括:
- 内核核心(Kernel Core):调度器、内存管理、IPC 等子系统
- 设备驱动(Device Drivers)
- 包括:
📌 优点:
- 实现代码复用
- 同一套内核可以在多种硬件上运行(如 x86、ARM、RISC-V 等)
非对称多处理Asymmetric MultiProcessing(ASMP)与对称多处理Symmetric MultiProcessing(SMP)
现代操作系统内核在多核处理器环境下运行时,通常采用以下两种调度和执行架构:
一、ASMP(Asymmetric MultiProcessing,非对称多处理)
在 非对称多处理(ASMP) 模式中:
- 一个处理器(核心)专门用于运行内核代码(如系统调用、驱动中断处理);
- 其余处理器仅用于运行用户空间程序。
📌 例子:
- 核心 0:专门运行内核任务
- 核心 1、2、3:只运行用户进程
✅ 优点:
- 实现简单:没有并发内核执行,不需担心并发访问内存的冲突问题。
❌ 缺点:
- 内核吞吐量不随核心数扩展:
- 所有系统调用、中断处理等都压在一个内核核心上;
- 这对依赖频繁内核交互的程序是个性能瓶颈。
📌 适用场景:
- 主要用于一些特定用途系统(如嵌入式或科学计算应用),这些系统内核调用较少,用户程序计算密集。
二、SMP(Symmetric MultiProcessing,对称多处理)
在 对称多处理(SMP) 模式中:
- 所有核心都可以运行内核代码或用户代码;
- 任意一个核心都可以处理系统调用、中断或调度任务。
📌 更加灵活、高效,可实现多核并行加速内核功能。
❗ 实现难点:
- 存在竞争条件(Race Conditions):
- 当多个核心同时运行内核函数并访问相同的内存区域,可能会导致冲突或数据破坏;
- 因此必须使用同步原语Synchronization Primitives来保护关键区域。
🛠 常用的同步机制包括:
- 自旋锁(Spin Locks)
- 互斥锁(Mutexes)
- 原子操作(Atomic Operations)
📌 关键公式:
若多个处理器访问临界区:Only one CPU can execute critical section at a time \text{Only one CPU can execute critical section at a time} Only one CPU can execute critical section at a time
CPU 可扩展性(CPU Scalability)
CPU 可扩展性是指:当系统中处理器核心数量增加时,整体性能是否也能线性或接近线性增长。
📈 理想情况下, n n n 个核心应该能提供接近 n × n \times n× 单核性能。
一、尽量使用无锁算法(Lock-Free Algorithms)
无锁算法是指在多核环境下,不依赖传统加锁机制(如互斥锁)的并发控制算法。
✅ 优点:
- 避免了线程之间的锁竞争;
- 避免了死锁和优先级反转等问题;
- 提高了在多核下的并发吞吐量。
📌 常用技术:
- 原子操作(如 compare_and_swap \text{compare\_and\_swap} compare_and_swap)
- 循环 CAS(spin CAS loops)
- 内存屏障(memory barriers)
二、热点区域使用细粒度锁(Fine-Grained Locking)
在高并发访问的临界区域(high contention areas)中,使用更细粒度的锁可以提升扩展性。
对比:
| 锁粒度类型 | 描述 | 扩展性影响 |
|---|---|---|
| 粗粒度锁 | 用一个锁保护多个资源 | ❌ 容易产生锁竞争,影响性能 |
| 细粒度锁 | 每个资源或资源组使用独立锁 | ✅ 并发性更高,锁冲突减少 |
📌 示例:
- 使用 per-CPU 数据结构,减少跨核心访问;
- 将一个全局队列拆分为多个局部队列,每个队列单独加锁。
三、关注算法复杂度(Algorithm Complexity)
即使没有锁竞争,如果算法本身的复杂度太高,也会成为扩展性能的瓶颈。
建议:
- 优化常用路径(hot path)的时间复杂度;
- 避免在线程间频繁拷贝数据或创建临时结构;
- 使用更适合并行的算法(例如基于数组的并行查找替代链表遍历)。
📌 记住:
O(1) ≫ O(log N) ≫ O(N) \text{O(1)} \gg \text{O(log N)} \gg \text{O(N)} O(1)≫O(log N)≫O(N)
💡 良好的 CPU 可扩展性 = 更低锁冲突 + 更短临界区 + 更高并发度 + 更优算法设计
![AndroidTV D贝桌面-v3.2.5-[支持文件传输]](https://i-blog.csdnimg.cn/direct/d2e809f1129045b882f0be97c7d2ef24.png)