Spark-SQL 概述
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块
Shark 是伯克利实验室 Spark 生态环境的组件之一,是基于 Hive 所开发的工具,它修改了内存管理、物理计划、执行三个模块,并使之能运行在 Spark 引擎上
Shark 的出现,使得 SQL-on-Hadoop 的性能比 Hive 有了 10-100 倍的提高
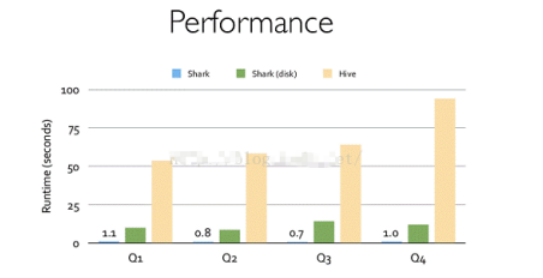
Spark 团队重新开发了SparkSQL代码;摆脱了对Hive的依赖性,SparkSQL 无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便
1.数据兼容方面 SparkSQL 不但兼容 Hive,还可以从 RDD、parquet 文件、JSON 文件中 获取数据,未来版本甚至支持获取 RDBMS 数据以及 cassandra 等 NOSQL 数据
2.性能优化方面 除了采取 In-Memory Columnar Storage、byte-code generation 等优化技术 外、将会引进 Cost Model 对查询进行动态评估、获取最佳物理计划等等
3.组件扩展方面无论是 SQL 的语法解析器、分析器还是优化器都可以重新定义,进行扩 展
Spark-SQL 特点
1.易整合。无缝的整合了 SQL 查询和 Spark 编程
2.统一的数据访问。使用相同的方式连接不同的数据源

3.兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL

4.标准数据连接。通过 JDBC 或者 ODBC 来连接

DataFrame
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中 的二维表格
DataFrame 与 RDD 的区别
主要区别在于,前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型

DataSet
DataSet 是分布式数据集合,是 DataFrame 的一个扩展,是 SparkSQL 最新的数据抽象。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter 等等)
Spark-SQL核心编程(一)
DataFrame
Spark SQL 的 DataFrame API 允许我们使用 DataFrame 而不用必须去注册临时表或者生成 SQL 表达式。DataFrame API 既有 transformation 操作也有 action 操作
创建 DataFrame
在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame
有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive
Table 进行查询返回
Spark-SQL支持的数据类型:
![]()
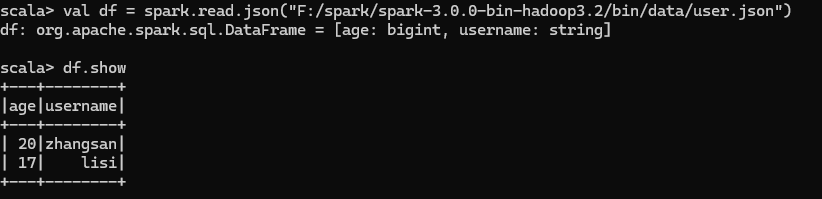
在 spark 的 bin/data 目录中创建 user.json 文件并在文件中添加数据

读取 json 文件创建 DataFrame,展示数据
SQL 语法
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要
有临时视图或者全局视图来辅助
实例:
读取 JSON 文件创建 DataFrame
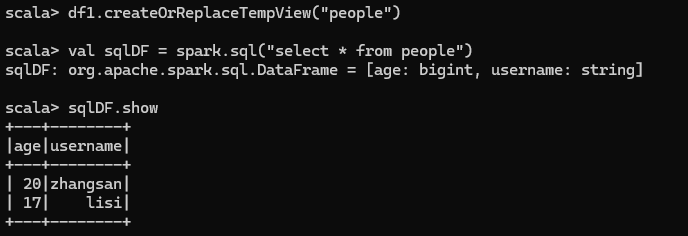
 对 DataFrame 创建一个临时表,通过 SQL 语句实现查询全表,结果展示
对 DataFrame 创建一个临时表,通过 SQL 语句实现查询全表,结果展示
Spark-SQL核心编程(二)
DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据
可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格
实例:
创建一个 DataFrame
![]()
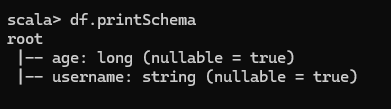
查看 DataFrame 的 Schema 信息
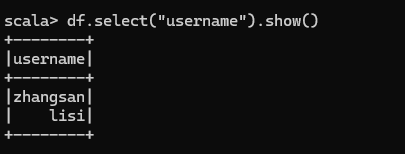
只查看"username"列数据
查看"username"列数据以及"age+1"数据
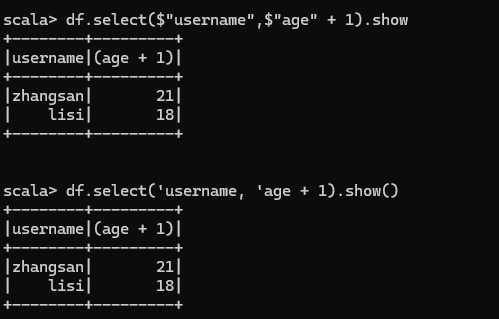
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
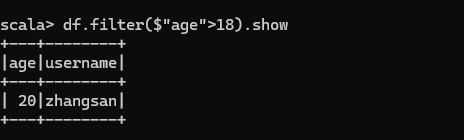
查看"age"大于"18"的数据
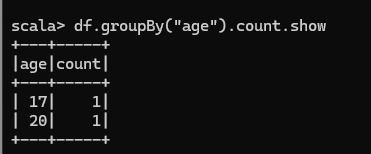
按照"age"分组,查看数据条数
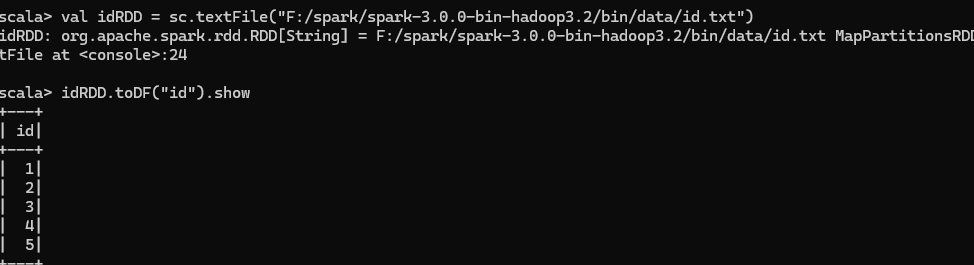
RDD 转换为 DataFrame
创建id.txt,并添加数据
将数据导入并查询
实际开发中,一般通过样例类将 RDD 转换为 DataFrame
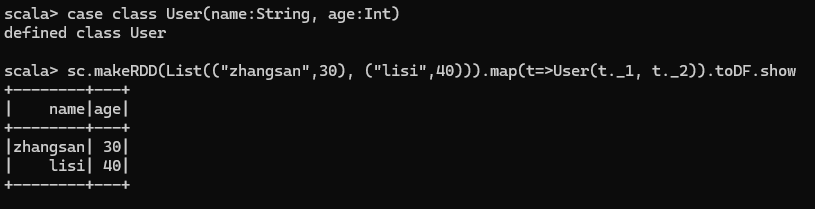
DataFrame 转换为 RDD
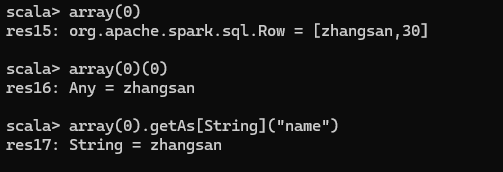
DataFrame 其实就是对 RDD 的封装,所以可以直接获取内部的 RDD
实例:

注意:此时得到的 RDD 存储类型为 Row
Spark-SQL核心编程(三)
DataSet
创建 DataSet
实例:
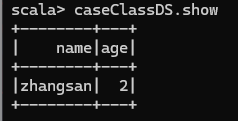
使用样例类序列创建 DataSet

使用基本类型的序列创建 DataSet

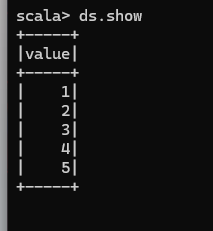
注意:在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet
RDD 转换为 DataSet
parkSQL 能够自动将包含有 case 类的 RDD 转换成 DataSet,case 类定义了 table 的结 构,case 类属性通过反射变成了表的列名
实例:

DataSet 转换为 RDD
DataSet 其实也是对 RDD 的封装,所以可以直接获取内部的 RDD
实例:

此处报错原因是 res3 并不存在(从前面代码看没有定义过 res3 ),而且即使存在,如果它的类型不是包含 rdd 成员的类型(比如不是 Dataset 等相关类型)
DataFrame 和 DataSet 转换
DataFrame 其实是 DataSet 的特例,所以它们之间是可以互相转换的
DataFrame 转换为 DataSet
实例
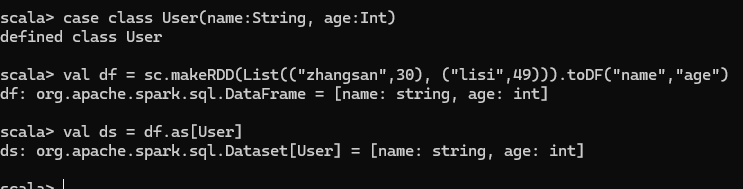
DataSet 转换为 DataFrame
实例
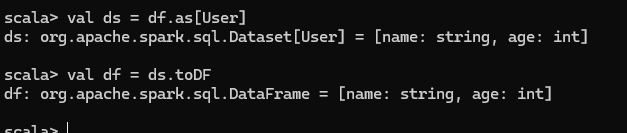
RDD、DataFrame、DataSet 三者的关系
从版本的产生上来看:
Spark1.0 => RDD
Spark1.3 => DataFrame
Spark1.6 => Dataset
同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不
同是的他们的执行效率和执行方式。在后期的 Spark 版本中,DataSet 有可能会逐步取代 RDD和 DataFrame 成为唯一的 API 接口
三者的共性
1)RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数
据提供便利;
2)三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到
Action 如 foreach 时,三者才会开始遍历运算;
3)三者有许多共同的函数,如 filter,排序等;
4)在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:
import spark.implicits._(在创建好 SparkSession 对象后尽量直接导入)
5)三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会
内存溢出
6)三者都有分区(partition)的概念
7)DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
三者的区别
1) RDD
➢ RDD 一般和 spark mllib 同时使用
➢ RDD 不支持 sparksql 操作
2) DataFrame
➢ 与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为Row,每一列的值没法直
接访问,只有通过解析才能获取各个字段的值
➢ DataFrame 与 DataSet 一般不与 spark mllib 同时使用
➢ DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能
注册临时表/视窗,进行 sql 语句操作
➢ DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表
头,这样每一列的字段名一目了然
3) DataSet
➢ Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
➢ DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪
些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性里提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息
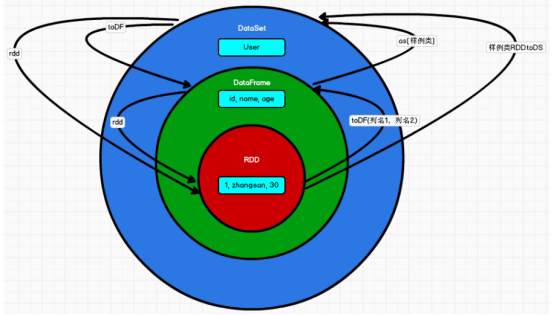
三者可以通过上图的方式进行相互转换







![AndroidTV D贝桌面-v3.2.5-[支持文件传输]](https://i-blog.csdnimg.cn/direct/d2e809f1129045b882f0be97c7d2ef24.png)