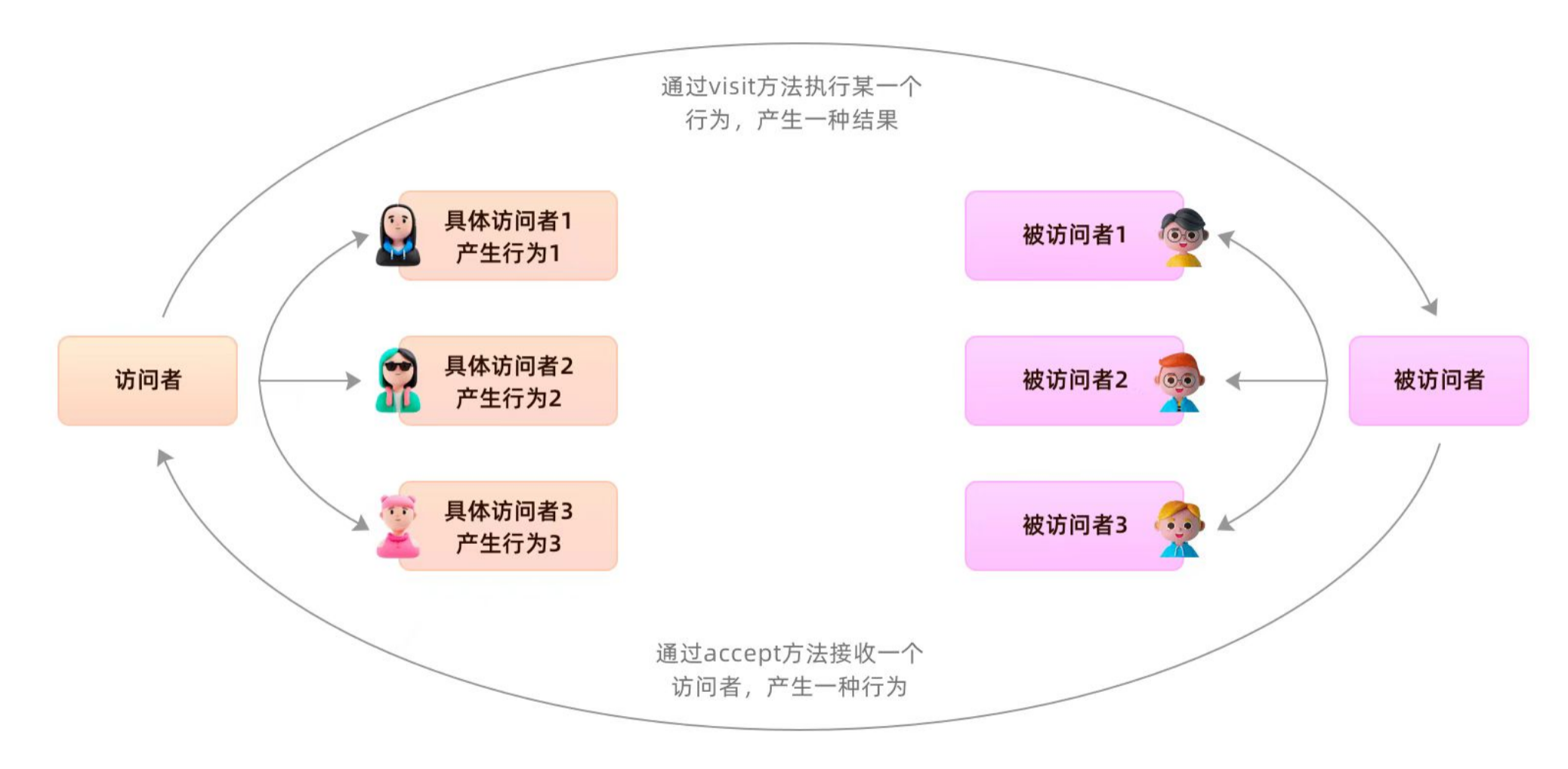
基于穿戴装备的身体活动监测
摘要
本研究基于加速度计采集的活动数据,旨在分析和统计100名志愿者在不同身体活动类别下的时长分布。通过对加速度数据的处理,活动被划分为睡眠、静态活动、低强度、中等强度和高强度五类,进而计算每个志愿者在各类活动中的总时长。研究结果揭示了不同个体在活动强度上的差异,为后续的个性化健康管理和运动干预提供了重要数据支持。此外,结合可视化分析,进一步揭示了志愿者的活动模式,帮助更好地理解个体行为差异及群体健康趋势。
本研究通过无监督学习方法,对志愿者的身体活动数据进行了聚类分析,旨在识别不同的活动模式。基于志愿者的加速度数据和MET 值,本文采用 KMeans 和高斯混合模型(GMM)两种聚类算法进行活动模式识别。通过聚类分析,成功将志愿者的活动模式划分为三类:睡眠模式三(深睡)、睡眠模式一(浅睡)和睡眠模式二(中度/REM)。这些活动模式的划分为进一步理解志愿者的行为模式和睡眠结构提供了依据。通过计算每个模式下的时长,本研究揭示了不同个体在活动强度和睡眠阶段上的差异,为后续的健康干预和个性化健康管理提供了数据支持。
本研究进一步对志愿者的久坐行为进行了识别和分析。通过滑动窗口方法,结合加速度数据和MET 值,我们成功识别出志愿者持续超过30分钟的静态行为,并计算了每位志愿者的总久坐时长。每个持续静态状态的行为段被标记为久坐行为,累计计算每位志愿者的久坐时长。通过随机森林算法、CNN+LSTM组合算法进行预测。研究结果表明,不同志愿者的久坐行为存在显著差异,某些个体表现出较高的久坐时长,提示可能需要更强的健康干预措施。通过这一分析,我们为个性化健康干预、久坐行为管理以及健康风险评估提供了有效的数据支持。
关键词:身体活动监测、随机森林、K-means聚类、GMM、滑动窗口
目录
基于穿戴装备的身体活动监测 1
摘要 1
一、 问题重述 3
1.1 问题背景 3
1.2 要解决的问题 3
二、 问题分析 5
2.1 任务一的分析 5
2.2 任务二的分析 5
2.3 任务三的分析 5
2.4 任务四的分析 5
三、 问题假设 7
四、 模型原理 8
4.1 随机森林模型 8
4.2 K-means聚类算法 9
4.3 GMM模型 11
五、 模型建立与求解 14
5.1 问题一建模与求解 14
5.2 问题二建模与求解 19
5.3 问题三建模与求解 24
5.4 问题四建模与求解 28
六、 模型评价与推广 31
6.1 模型的评价 31
6.1.1模型优点 31
6.1.2模型缺点 32
6.2 模型推广 33
附录【自行删减】 35
任务 主要技术 关键步骤
-
统计分析 数据处理、MET 分类 时间计算、分类统计
-
MET 值预测 机器学习(XGBoost/LSTM) 特征提取、回归建模
-
睡眠分析 深度学习(CNN/LSTM) 睡眠阶段分类
-
久坐预警 滑动窗口分析 连续静态行为检测
-
统计分析志愿者的活动情况
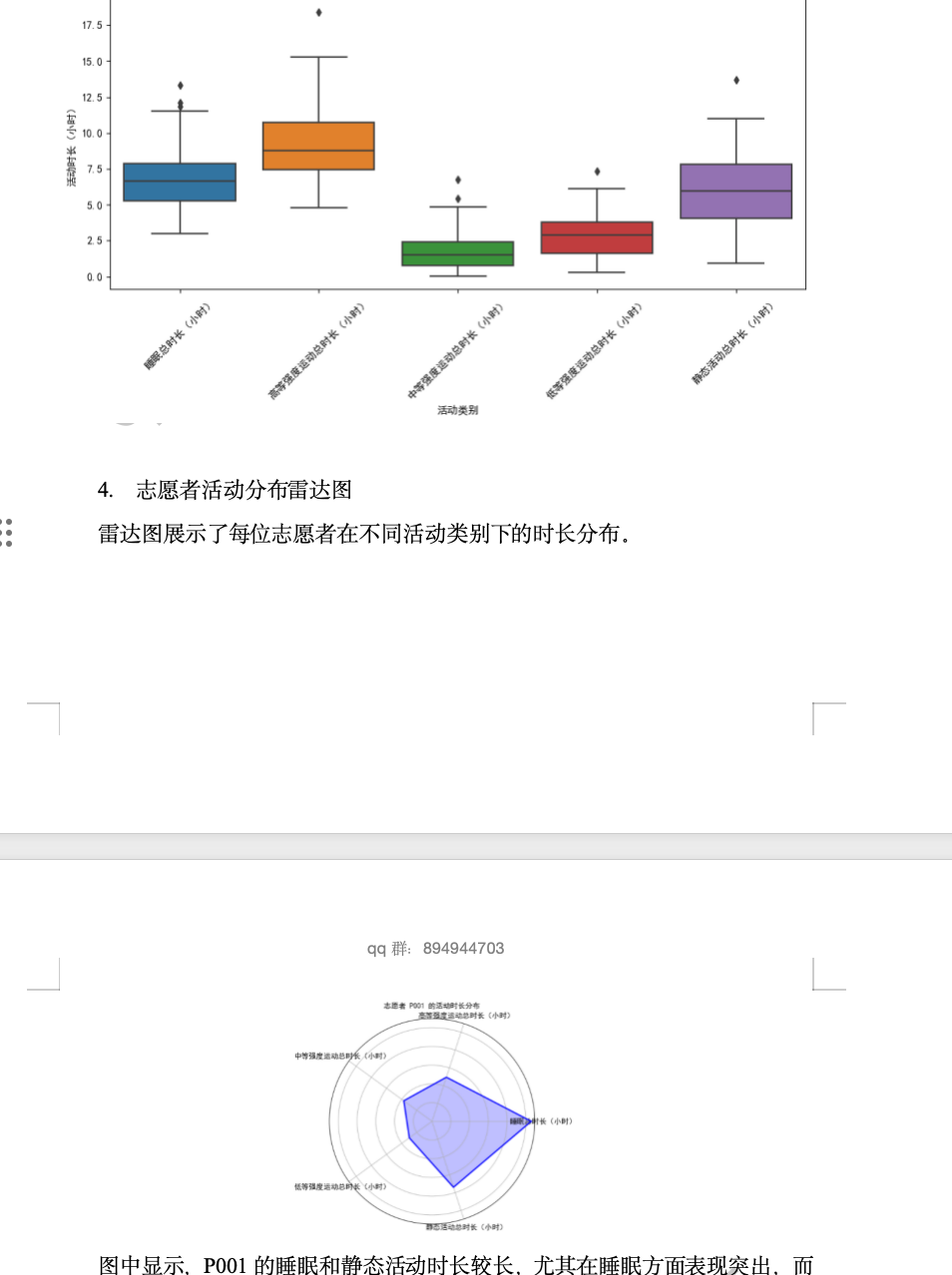
目标:
根据 100 位志愿者的加速度数据,计算各项活动时长,并进行统计汇总。
数据说明:
数据存储在 P[ID].csv 文件,每行包含:
时间戳(毫秒)
X/Y/Z 方向加速度(g)
活动标签(MET 值)
Metadata1.csv 提供志愿者的性别和年龄信息。
解题思路:
数据读取:
读取 P[ID].csv 文件,解析时间戳转换为小时级别。
读取 Metadata1.csv,合并志愿者元数据。
计算各项时长:
计算 总记录时长:时间戳转换为小时后求总时长。
根据 MET 值分类:
MET ≥ 6.0 → 高强度运动
3.0 ≤ MET < 6.0 → 中等强度运动
1.6 ≤ MET < 3.0 → 低强度运动
1.0 ≤ MET < 1.6 → 静态行为
MET < 1.0 → 睡眠
统计每种 MET 分类下的时间总量。
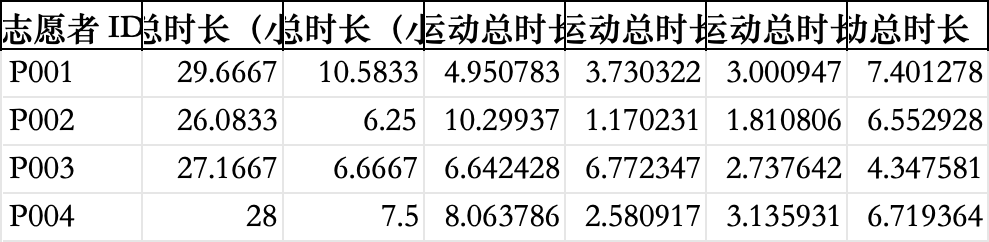
生成表格 result_1.xlsx,列格式: | 志愿者ID | 总时长 | 睡眠时长 | 高强度运动 | 中等强度 | 低强度 | 静态活动 |
导出 Excel 文件。
遍历每个志愿者文件
for pid in pids:
file_path = f'{pid}.csv' # 假设文件名为P001.csv格式
# 读取数据文件
df = pd.read_csv(file_path, parse_dates=['time'])
# 计算时间间隔(转换为小时)
df['duration'] = df['time'].diff().dt.total_seconds().fillna(0) / 3600
# 提取MET值
df['MET'] = df['annotation'].str.extract(r'MET (\d+\.?\d*)').astype(float)
# 分类活动类型
df['activity'] = df['MET'].apply(classify_activity)
# 按活动类型汇总时长
activity_duration = df.groupby('activity')['duration'].sum()
# 构建结果行
result = {
'志愿者 ID': pid,
'记录总时长(小时)': df['duration'].sum().round(4),
'睡眠总时长(小时)': activity_duration.get('sleep', 0).round(4),
'高等强度运动总时长(小时)': activity_duration.get('high', 0),
'中等强度运动总时长(小时)': activity_duration.get('medium', 0),
'低等强度运动总时长(小时)': activity_duration.get('low', 0),
'静态活动总时长(小时)': activity_duration.get('static', 0)
}
results.append(result)
2.构建 MET 值估计模型
目标:
利用 100 名志愿者的数据,构建 机器学习模型,预测新的 20 名志愿者的 MET 值。
数据说明:
P[ID].csv:包含加速度计数据及 MET 值(用于训练)。
Metadata1.csv:包含志愿者的性别、年龄信息。
T[ID].csv:20 位新志愿者的加速度计数据(用于预测)。
Metadata2.csv:包含 20 位新志愿者的性别、年龄信息。
解题思路:
数据预处理
解析加速度数据(X/Y/Z)。
计算时序特征:
时域特征(均值、标准差、最大值、最小值等)
频域特征(FFT 分析)
结合年龄、性别数据,标准化特征。
特征工程
采用 滑动窗口(如 1 秒、5 秒窗口)进行特征提取:
平均加速度、方差、均方根(RMS)
瞬时速度估计
频谱能量
目标变量为 MET 值。
模型选择
回归模型(目标变量为连续值):
XGBoost / LightGBM
随机森林
LSTM / GRU(处理时序数据)
CNN+LSTM 组合模型
选择 均方误差(MSE)以及 平均绝对误差(MAE) 作为损失函数。
模型训练
划分训练集与验证集(80% 训练 / 20% 验证)。
调参优化(交叉验证)。
评估模型泛化能力。
预测新志愿者 MET 值
使用训练好的模型预测 T[ID].csv 20 位志愿者的数据。
保存预测结果 result_2.xlsx。
5.2.2 特征工程与数据处理
1.时间窗口构造
将原始加速度数据按 5 秒为单位划分为多个不重叠的时间窗口。设某志愿者的加速度数据为三维时间序列 ,时间窗口长度为 秒,则第 个窗口内包含的数据为:
在每个时间窗口中提取统计特征和频域特征,构成特征向量 。
2.特征提取基本原理
在每个窗口 内,提取以下特征:
时域特征:对每个轴向的加速度数据 ,计算其均值(mean)、标准差(std)、最大值(max)、最小值(min):
加速度幅值(Magnitude)特征:定义三轴加速度的合成加速度为:
并提取其均值与标准差:
频域特征:对加速度幅值序列 进行离散傅里叶变换(DFT):

======================
数据准备
======================
def extract_features(accel_data):
"""从三轴加速度数据中提取特征"""
features = {}
# 时域特征
for axis in ['x', 'y', 'z']:
# 基本统计量
features[f'{axis}_mean'] = accel_data[axis].mean()
features[f'{axis}_std'] = accel_data[axis].std()
features[f'{axis}_max'] = accel_data[axis].max()
features[f'{axis}_min'] = accel_data[axis].min()
#features[f'{axis}_mad'] = accel_data[axis].mad() # 平均绝对偏差
# 幅值特征
magnitude = np.sqrt(accel_data[['x', 'y', 'z']].pow(2).sum(axis=1))
features['magnitude_mean'] = magnitude.mean()
features['magnitude_std'] = magnitude.std()
# 频域特征
fft = np.fft.fft(magnitude)
features['dominant_freq'] = np.argmax(np.abs(fft)) # 主频率
return pd.Series(features)
遍历每个志愿者文件
for _, row in tqdm(metadata.iterrows(), total=len(metadata)):
pid = row['pid']
file_path = f'{pid}.csv'
# 读取加速度数据
df = pd.read_csv(file_path)
df['MET'] = df['annotation'].str.extract(r'MET (\d+\.?\d*)').astype(float)
# 按时间窗口处理(5秒窗口)
window_size = '5S'
df['time'] = pd.to_datetime(df['time'])
grouped = df.set_index('time').groupby(pd.Grouper(freq=window_size))
# 窗口特征提取
for _, window in grouped:
if len(window) > 0:
features = extract_features(window[['x', 'y', 'z']])
features['age'] = row['age']
features['sex'] = row['sex']
all_features.append(features)
all_targets.append(window['MET'].mean())
- 睡眠阶段智能识别
目标:
设计睡眠阶段分类算法,基于加速度数据识别不同的睡眠状态。
数据说明:
P[ID].csv(训练数据,包含 MET 值)。
T[ID].csv(测试数据,无 MET 值,需要进行预测)。
解题思路:
数据预处理
选取 睡眠数据(MET < 1.0) 作为分析对象。
计算 睡眠时段的加速度特征:
运动量(X/Y/Z 方向变化率)
姿态变化(角度计算)
低频信号分析(检测深度睡眠)
特征提取
使用 滑动窗口法(如 30s、60s 窗口)提取特征:
加速度均值、标准差
突发运动频率
睡眠稳定性指标(基于 FFT 低频功率)
模型选择 分类模型:
传统机器学习(Random Forest, SVM)
深度学习(LSTM、CNN)
目标:划分 不同睡眠阶段(如浅睡、深睡、REM)。
模型训练与预测
训练模型,调整超参数。
预测 20 名志愿者的睡眠阶段,输出 result_3.xlsx。
聚类结果的解释与活动模式识别
为了评估不同聚类算法在本问题中的适用性与有效性,本文计算了
KMeans
与高斯混合模型(
GMM
)两种聚类方法在标准化特征空间上的轮廓系数(
Silhouette Coefficient
)。轮廓系数是一种常用的无监督聚类性能评估指标,综合衡量了簇内紧密度和簇间分离度。其取值范围为
[
−
1,1][-1, 1][
−
1,1]
,值越接近
1
表示聚类结果越合理,聚类边界越清晰;值接近
0
表示簇之间重叠较多,聚类效果模糊;若为负值,则可能存在簇划分错误的情况。
本实验结果如下:
KMeans 聚类轮廓系数:0.2296
GMM 聚类轮廓系数:0.0277
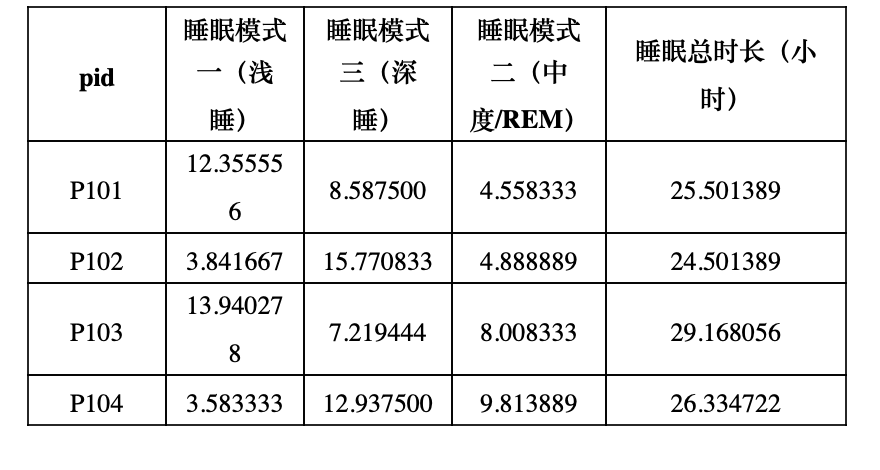
大多数志愿者的睡眠时长主要集中在
“睡眠模式三(深睡)”和“睡眠模式一(浅睡)”之间,表明深度睡眠和浅睡是大多数志愿者的主要睡眠阶段。而“睡眠模式二(中度
/REM
)”的时间占比相对较低,但在一些志愿者中,可能由于特定生理特征或生活习惯,表现出较为明显的中度睡眠模式。
- 久坐行为健康预警
目标:
检测志愿者 久坐行为(单次静态时间超过 30 分钟,MET < 1.6)。
解题思路:
数据解析
解析时间戳,转换为分钟级别时间轴。
计算连续静态行为(MET < 1.6)。
久坐检测
采用 滑动窗口分析:
若 连续 30 分钟以上 处于 MET < 1.6,则标记为久坐行为。
计算 久坐持续时间 及 久坐次数。
预警策略
若 单次久坐超过 1 小时 → 预警等级 1
若 每日久坐总时长 > 6 小时 → 预警等级 2
若 久坐超过 10 小时 → 预警等级 3(高风险)
生成结果
输出每位志愿者的久坐时间及预警信息。