Vanna 是一个开源的 Text-2-SQL 框架,主要用于通过自然语言生成 SQL 查询,它基于 RAG(Retrieval-Augmented Generation,检索增强生成)技术。Vanna 的核心功能是通过训练一个模型(基于数据库的元数据和用户提供的上下文),然后让用户通过自然语言提问来生成对应的 SQL 查询。它支持多种数据库和前端界面。
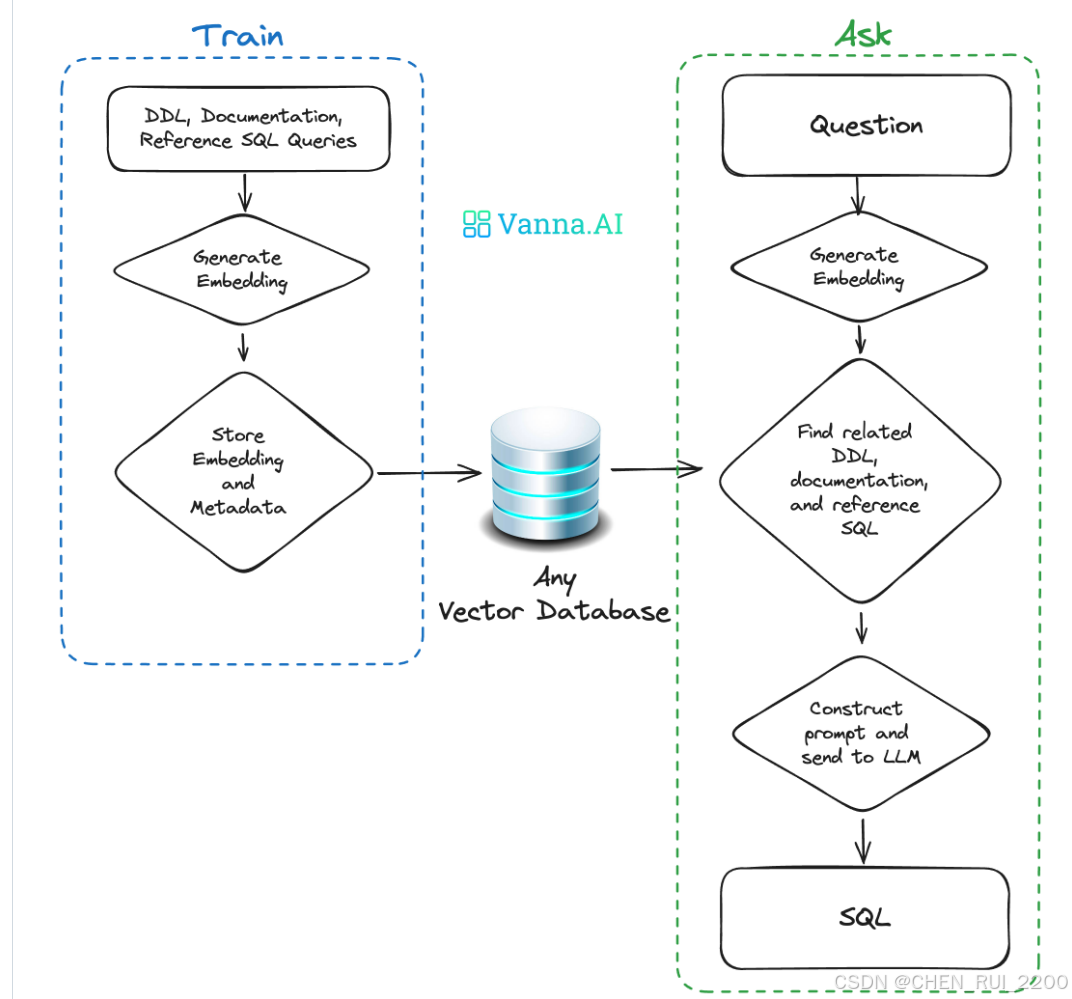
理解 Vanna 的工作原理
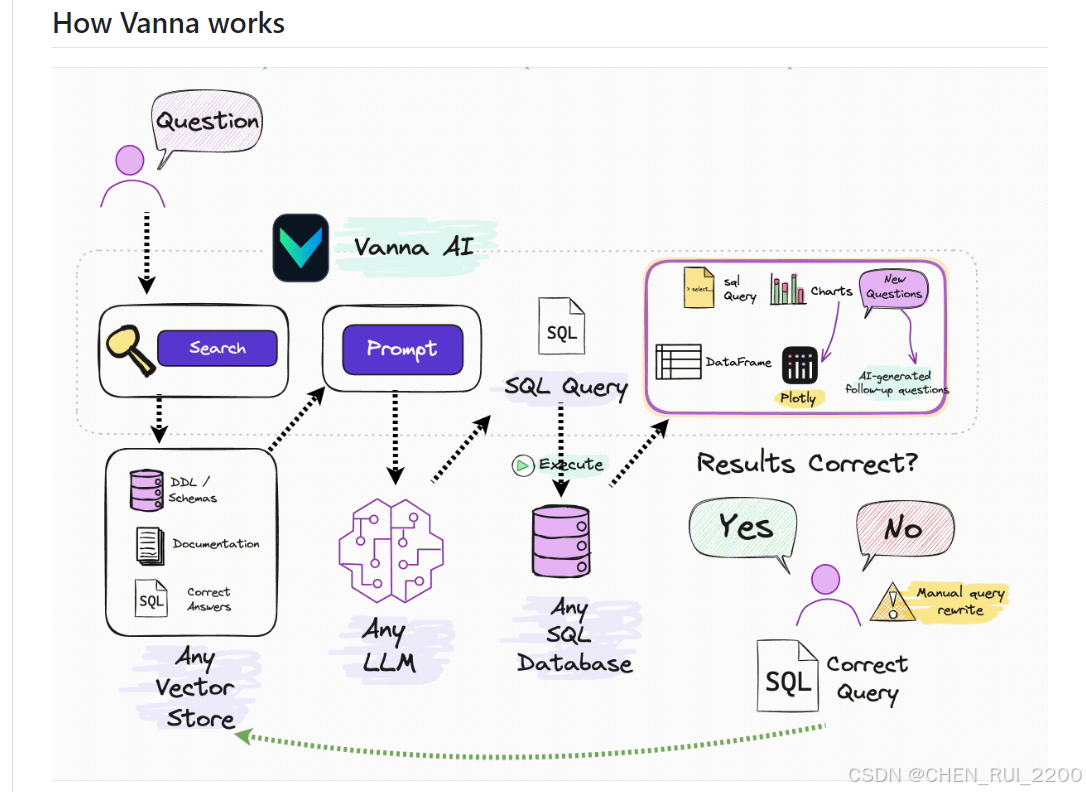
功能依赖于:
- 训练阶段: 输入数据库的 DDL(表结构定义)、文档或已有 SQL 查询,生成向量嵌入存储到向量数据库(如 ChromaDB)。
- 推理阶段: 用户输入自然语言问题,Vanna 从向量数据库检索相关上下文,结合 LLM 生成 SQL 查询。
工作流程
Vanna 的运行可以分为以下步骤:
- 初始化和连接数据库:
- 通过 vn.connect_to_sqlite(db_path)(或其他数据库连接方法)连接到目标数据库。
- 这允许 Vanna 了解数据库的实际结构和数据。
- 训练(Training):
- DDL 训练:
- 使用 vn.train(ddl=...) 输入数据库表结构(如 CREATE TABLE users (...)),让 Vanna 理解表的列名、类型等。
- SQL 示例训练:
- 使用 vn.train(sql=...) 输入示例 SQL 查询(如 SELECT name, age FROM users WHERE age > 30),教 Vanna 如何将问题映射到 SQL。
- 文档训练(可选):
- 可输入额外文档(如业务规则),增强上下文理解。
- 训练数据被向量化并存储在向量数据库中,形成知识库。
- DDL 训练:
- 问题处理(Query Processing):
- 用户输入自然语言问题(例如 "列出所有年龄超过30岁的用户")。
- Vanna 将问题向量化,通过向量搜索从训练数据中检索相关上下文(如 DDL 和示例 SQL)。
- 检索到的上下文与用户问题一起组成提示(prompt),传递给 LLM。
- SQL 生成(SQL Generation):
- LLM 根据提示生成 SQL 查询。
- 在我们的代码中,submit_prompt 增强了提示(如 "Generate a SQLite query for: ..."),明确要求返回 SQL。
- 生成的响应可能包含多余内容,需清理(如提取从 "SELECT" 开始的部分)
关键机制
- 向量搜索:
- 使用 ChromaDB 等向量存储,通过嵌入相似性快速匹配用户问题与训练数据。
- 例如,问题 "列出年龄大于30的用户" 会匹配训练中的 SELECT ... WHERE age > 30。
- 提示工程(Prompt Engineering):
- 通过精心设计的提示,将问题、表结构和期望输出格式提供给 LLM。
- 例如:f"Generate a SQLite query for: {prompt}\nSchema: {ddl}\nReturn only the SQL."
- 模型推理:
- LLM(本地 qwq_32B 或远程 GPT)根据训练数据和提示推理出 SQL。
- 本地模型可能需要量化(如 4-bit)或 CPU Offloading 以适配硬件。
动手尝试
准备点测试数据
# 初始化 SQLite 数据库
def init_sqlite_db():
db_path = "/opt/chenrui/my_database.db"
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER
)
""")
cursor.execute("INSERT OR IGNORE INTO users (id, name, age) VALUES (1, 'Alice', 25)")
cursor.execute("INSERT OR IGNORE INTO users (id, name, age) VALUES (2, 'Bob', 35)")
conn.commit()
conn.close()
logger.info(f"SQLite 数据库已创建并初始化: {db_path}")
return db_pathpip install vanna 安装下该组件
def setup_vanna(db_path):
vn = MyVanna()
vn.connect_to_sqlite(db_path)
# 添加更多训练数据
vn.train(ddl="""
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER
)
""")
vn.train(sql="SELECT name, age FROM users WHERE age > 30")
logger.info("Vanna 初始化完成并添加了 DDL 和 SQL 示例训练数据")
return vn构建下MyVanna对象,它包含向量数据库和LLM, 在提供ddl和sql做为训练数据
代码如下
import sqlite3
import streamlit as st
from vanna.chromadb import ChromaDB_VectorStore
from vanna.base import VannaBase
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import logging
# 设置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# 查看 SQLite 数据库结构和数据
def show_db_structure(db_path):
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
st.write("数据库中的表:", tables)
cursor.execute("PRAGMA table_info(users);")
schema = cursor.fetchall()
st.write("users 表结构:")
st.table(schema)
cursor.execute("SELECT * FROM users;")
data = cursor.fetchall()
st.write("users 表数据:")
st.table(data)
conn.close()
logger.info("数据库结构和数据已显示")
# 自定义本地 qwq_32B 的 LLM 类
class Qwq32bLLM(VannaBase):
def __init__(self, config=None):
super().__init__(config)
model_path = "./base_model/qwq_32b"
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.model = AutoModelForCausalLM.from_pretrained(model_path)
self.generator = pipeline("text-generation", model=self.model, tokenizer=self.tokenizer, device=-1)
logger.info("qwq_32B 模型已加载")
def generate(self, prompt):
response = self.generator(prompt, max_length=500, num_return_sequences=1)[0]['generated_text']
logger.info(f"生成响应: {response}")
return response
def submit_prompt(self, prompt, **kwargs):
logger.info(f"提交提示: {prompt}")
return self.generate(prompt)
def system_message(self, message):
return f"System: {message}"
def user_message(self, message):
return f"User: {message}"
def assistant_message(self, message):
return f"Assistant: {message}"
# 定义自定义 Vanna 类
class MyVanna(ChromaDB_VectorStore, Qwq32bLLM):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
Qwq32bLLM.__init__(self, config=config)
# 使用 Streamlit 的缓存机制初始化 Vanna
@st.cache_resource(ttl=3600)
def setup_vanna(db_path):
vn = MyVanna()
vn.connect_to_sqlite(db_path)
vn.train(ddl="""
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER
)
""")
logger.info("Vanna 初始化完成并训练了 DDL")
return vn
# 主程序
def main():
db_path = init_sqlite_db()
vn = setup_vanna(db_path)
st.title("本地 Vanna Seq2SQL 示例")
st.subheader("SQLite 数据库结构和数据")
show_db_structure(db_path)
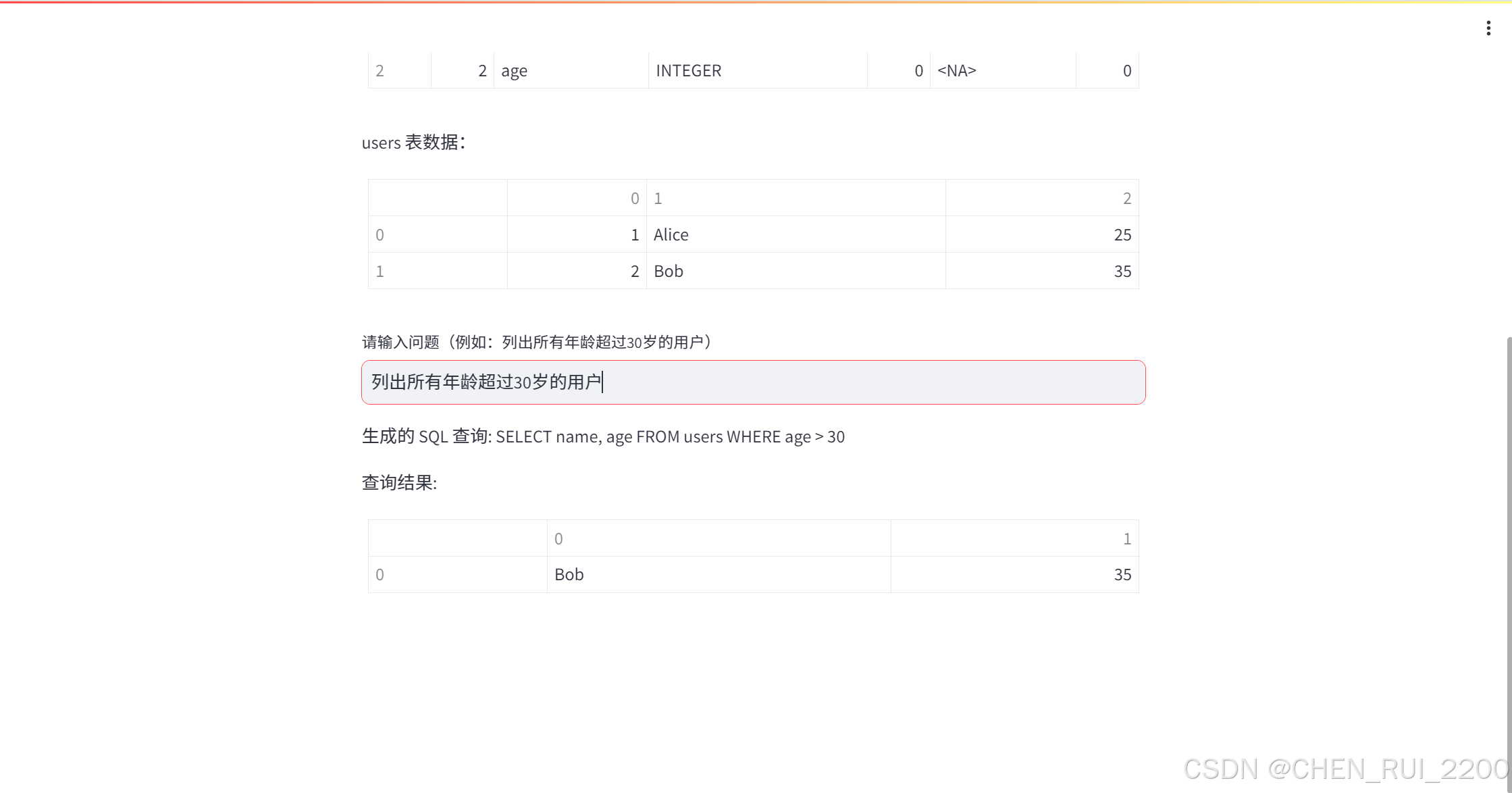
question = st.text_input("请输入问题(例如:列出所有年龄超过30岁的用户)")
if question:
with st.spinner("正在生成 SQL 查询,请稍候..."):
result = vn.ask(question)
logger.info(f"vn.ask 返回结果: {result}")
# 检查返回值类型并提取 SQL 字符串
if isinstance(result, tuple):
sql_query = result[0] # 假设 SQL 在元组的第一个元素
else:
sql_query = result
st.write(f"生成的 SQL 查询: {sql_query}")
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
try:
cursor.execute(sql_query)
results = cursor.fetchall()
st.write("查询结果:")
st.table(results)
logger.info(f"SQL 查询执行成功,结果: {results}")
except sqlite3.Error as e:
st.error(f"SQL 执行错误: {e}")
logger.error(f"SQL 执行失败: {e}")
finally:
conn.close()
if __name__ == "__main__":
main()streamlit 启动下,在问题窗口填上 “列出所有年龄超过30岁的用户”

执行报错了
vn.ask 返回结果: (None, None, None)
2025-04-10 17:32:14.486 Uncaught app exception
Traceback (most recent call last):
File "/opt/miniconda3/envs/spatiallm/lib/python3.11/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 535, in _run_script
exec(code, module.__dict__)
File "/opt/chenrui/qwq32b/test_vanna_1.py", line 148, in <module>
main()
File "/opt/chenrui/qwq32b/test_vanna_1.py", line 135, in main
cursor.execute(sql_query)
TypeError: execute() argument 1 must be str, not None问题分析
- 为什么 vn.ask() 返回 (None, None, None):
- Vanna 的 ask 方法依赖于训练数据(DDL、SQL 示例等)和底层语言模型(这里是 qwq_32B)的能力。
- 当前训练数据可能不足,或者模型未能正确理解问题并生成 SQL。
- 日志显示 vn.ask 返回结果: (None, None, None),说明生成过程完全失败,没有返回有效的 SQL。
- 是否需要增加训练:
- 是的,Vanna 需要足够的训练数据来理解数据库结构和生成正确的 SQL。如果训练数据不足(例如只有 DDL 而没有 SQL 示例),模型可能无法将自然语言问题映射到正确的查询。
- 另外,本地 qwq_32B 模型的性能可能不如 GPT-3.5/GPT-4,可能需要更多上下文或微调才能生成有效 SQL。
修改思路
- 增加训练数据:添加更多的 DDL(表结构)和 SQL 示例,帮助 Vanna 理解数据库和常见查询模式。在setup_vanna 方法了增加训练用例
vn.train(sql="SELECT name, age FROM users WHERE age > 30")
vn.train(sql="SELECT * FROM users WHERE name = 'Alice'")- 处理 None 返回值:在代码中检查 sql_query 是否为 None,避免直接传递给 execute()。
- 优化提示:在 submit_prompt 中增强提示(prompt),明确要求生成 SQL。
运行训练输出日志
**Step-by-Step Explanation:**
1. **Identify Columns Selected**: The query selects 'name' and 'age', so the question must ask for these two pieces of information.
2. **Determine the Table Context**: The 'FROM users' clause indicates the data comes from a user/employee table, so the question likely refers to employees or users.
3. **Analyze the WHERE Clause**: The condition 'age > 30' filters for individuals older than 30, which must be included in the question.
4. **Formulate the Question**: Combine these elements into a natural question asking for names and ages of those over 30 without mentioning the table name.Thus, the derived business question is: **"What are the names and ages of employees older than 30?"**
**Answer**
The business question this SQL query answers is:
\boxed{What are the names and ages of employees older than 30?}---
**Final Answer**
\boxed{What are the names and ages of
Adding SQL...
2025-04-10 17:50:24,333 - INFO - 提交增强提示: Generate a valid SQL query for the following question based on the database schema: ['System: The user will give you SQL and you will try to guess what the business question this query is answering. Return just the question without any additional explanation. Do not reference the table name in the question.', "User: SELECT * FROM users WHERE name = 'Alice'"]
Return only the SQL query.
vanna 会自己去匹配一个相似的问题,比如上面训练的vn.train(sql="SELECT name, age FROM users WHERE age > 30") 对应的问题是 What are the names and ages of employees older than 30,所以vanna的训练是无监督
测试下生成sql的能力
代码优化下
GPU 显存有限,无法完整加载 32B 模型,以下是几种可行的修改方案:
1. 使用模型量化(4-bit 或 8-bit)
- 使用 bitsandbytes 库将模型量化为 4-bit 或 8-bit,显著降低显存需求(例如 4-bit 下约 16 GB)。
- 需要安装 bitsandbytes 和调整代码。
2. 启用 CPU Offloading
- 将部分模型卸载到 CPU 和内存,利用 GPU 和 CPU 协同计算。
3. 调整 max_new_tokens
- 减少生成 token 数量,降低推理时的显存占用(临时缓解,但不解决根本问题)。
4. 设置 PYTORCH_CUDA_ALLOC_CONF
- 按错误提示设置环境变量,避免内存碎片化。
import sqlite3
import streamlit as st
from vanna.chromadb import ChromaDB_VectorStore
from vanna.base import VannaBase
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
import logging
import os
# 设置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# 设置 PyTorch 内存管理环境变量
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# 检查 CUDA 是否可用
if not torch.cuda.is_available():
logger.error("CUDA 不可用,将回退到 CPU")
device = -1 # CPU
else:
logger.info(f"CUDA 可用,使用 GPU: {torch.cuda.get_device_name(0)}")
device = 0 # 默认 GPU
# 初始化 SQLite 数据库
def init_sqlite_db():
db_path = "/opt/chenrui/my_database.db"
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER
)
""")
cursor.execute("INSERT OR IGNORE INTO users (id, name, age) VALUES (1, 'Alice', 25)")
cursor.execute("INSERT OR IGNORE INTO users (id, name, age) VALUES (2, 'Bob', 35)")
conn.commit()
conn.close()
logger.info(f"SQLite 数据库已创建并初始化: {db_path}")
return db_path
# 查看 SQLite 数据库结构和数据
def show_db_structure(db_path):
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
st.write("数据库中的表:", tables)
cursor.execute("PRAGMA table_info(users);")
schema = cursor.fetchall()
st.write("users 表结构:")
st.table(schema)
cursor.execute("SELECT * FROM users;")
data = cursor.fetchall()
st.write("users 表数据:")
st.table(data)
conn.close()
logger.info("数据库结构和数据已显示")
# 自定义本地 qwq_32B 的 LLM 类
class Qwq32bLLM(VannaBase):
def __init__(self, config=None):
super().__init__(config)
model_path = "/opt/chenrui/qwq32b/base_model/qwq_32b"
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
# 使用 4-bit 量化加载模型,并启用 CPU Offloading
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto", # 自动分配到 GPU 和 CPU
load_in_4bit=True, # 4-bit 量化
torch_dtype=torch.float16, # 使用 FP16 精度
offload_folder="offload", # 指定卸载目录
)
# 使用 pipeline,指定 device_map
self.generator = pipeline(
"text-generation",
model=self.model,
tokenizer=self.tokenizer,
device_map="auto" # 自动分配设备
)
logger.info(f"qwq_32B 模型已加载(4-bit 量化,device_map=auto)")
def generate(self, prompt):
response = self.generator(prompt, max_new_tokens=100, num_return_sequences=1)[0]['generated_text']
logger.info(f"生成原始响应: {response}")
sql_start = response.find("SELECT")
if sql_start != -1:
sql_query = response[sql_start:].strip()
logger.info(f"提取的 SQL: {sql_query}")
return sql_query
return response.strip()
def submit_prompt(self, prompt, **kwargs):
enhanced_prompt = f"Generate a SQLite query for: {prompt}\nSchema: CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT NOT NULL, age INTEGER)\nReturn only the SQL."
logger.info(f"提交增强提示: {enhanced_prompt}")
return self.generate(enhanced_prompt)
def system_message(self, message):
return f"System: {message}"
def user_message(self, message):
return f"User: {message}"
def assistant_message(self, message):
return f"Assistant: {message}"
# 定义自定义 Vanna 类
class MyVanna(ChromaDB_VectorStore, Qwq32bLLM):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
Qwq32bLLM.__init__(self, config=config)
# 使用 Streamlit 的缓存机制初始化 Vanna
@st.cache_resource(ttl=3600)
def setup_vanna(db_path):
vn = MyVanna()
vn.connect_to_sqlite(db_path)
vn.train(ddl="""
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER
)
""")
vn.train(sql="SELECT name, age FROM users WHERE age > 30")
vn.train(sql="SELECT * FROM users WHERE name = 'Alice'")
vn.train(sql="SELECT id, name FROM users WHERE age < 40")
logger.info("Vanna 初始化完成并添加了 DDL 和 SQL 示例训练数据")
return vn
# 主程序
def main():
db_path = init_sqlite_db()
vn = setup_vanna(db_path)
st.title("本地 Vanna Seq2SQL 示例 (CUDA with 4-bit)")
st.subheader("SQLite 数据库结构和数据")
show_db_structure(db_path)
question = st.text_input("请输入问题(例如:列出所有年龄超过30岁的用户)")
if question:
with st.spinner("正在生成 SQL 查询,请稍候..."):
result = vn.ask(question)
logger.info(f"vn.ask 返回结果: {result}")
if isinstance(result, tuple):
sql_query = result[0]
else:
sql_query = result
if sql_query is None or not isinstance(sql_query, str):
st.error




![python manimgl数学动画演示_微积分_线性代数原理_ubuntu安装问题[已解决]](https://i-blog.csdnimg.cn/direct/91cbb2b855cc414281f519f33a4e280a.png)