一、引言:大数据时代的数据处理挑战
全球数据量正以指数级增长。据 Statista 统计,2010 年全球数据量仅 2ZB,2025 年预计达 175ZB。企业面临的核心挑战已从“如何存储数据”转向“如何快速分析数据”。传统架构在处理海量数据时暴露明显瓶颈:单点资源争用导致查询延迟激增,垂直扩展成本高昂(如某金融机构单台服务器扩容费用超百万美元),且难以支持实时分析需求。
MPP 架构的历史演进
MPP 架构并非新生事物,其发展历程可追溯至 1980 年代:
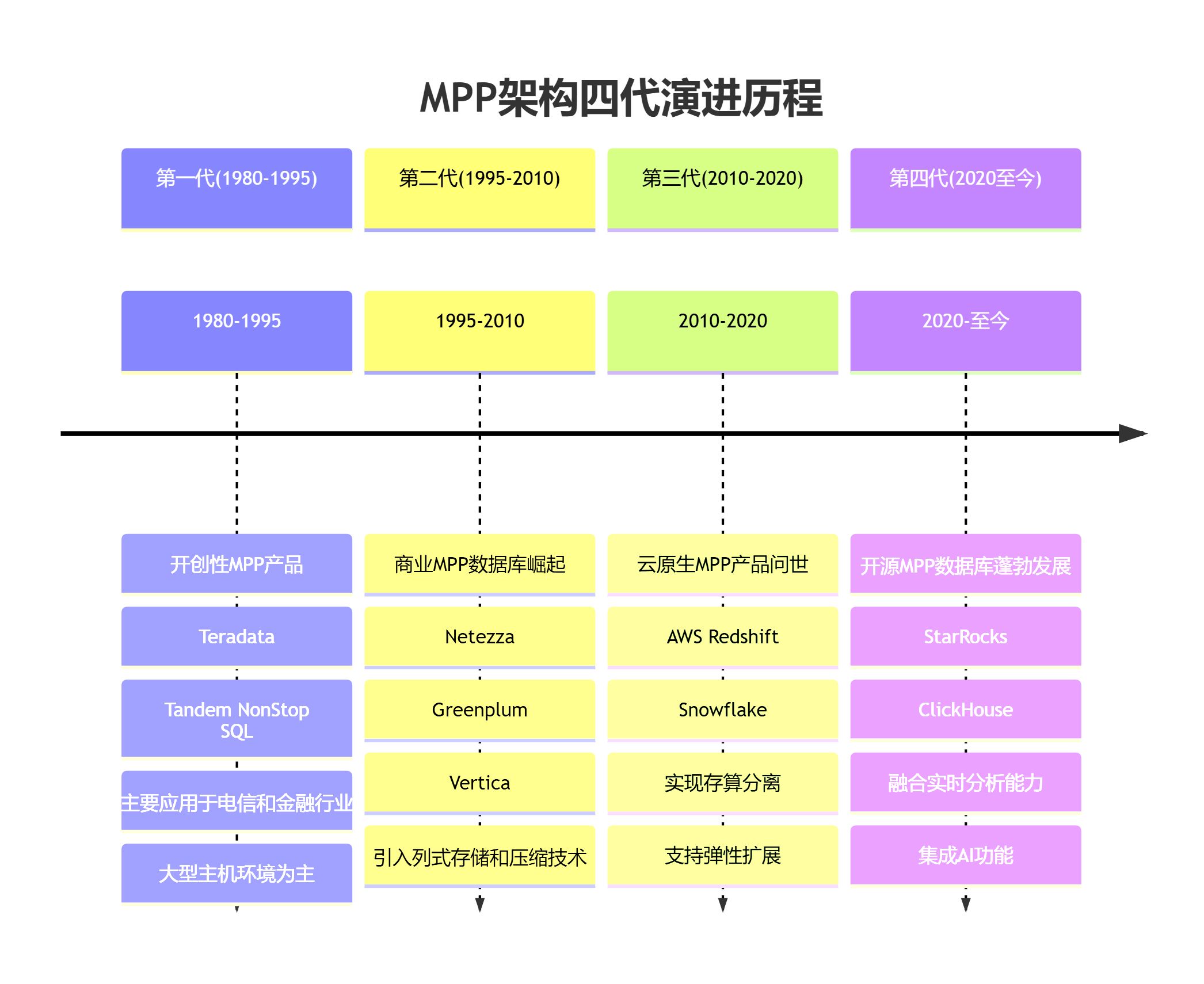
- 第一代(1980-1995):Teradata、Tandem NonStop SQL 等开创性产品出现,主要服务于电信和金融行业的大型主机环境
- 第二代(1995-2010):Netezza、Greenplum、Vertica 等商业 MPP 数据库崛起,引入列式存储、压缩等创新
- 第三代(2010-2020):AWS Redshift、Snowflake 等云原生 MPP 产品问世,实现存算分离与弹性扩展
- 第四代(2020 至今):以 StarRocks、ClickHouse 为代表的开源 MPP 数据库蓬勃发展,融合实时分析与 AI 能力
MPP(大规模并行处理)架构凭借其分布式计算能力,成为破解大数据处理难题的“效率引擎”。
二、MPP 架构的核心原理与组件
1. 定义与基本原理
MPP 架构(Massively Parallel Processing,大规模并行处理)是一种分布式计算架构,通过将数据和计算任务分散到多个独立节点,实现高性能数据处理。其三大核心特征:
-
分布式计算:单条 SQL 查询被智能拆解为多个子任务,由不同节点并行执行。例如,一个涉及 10 亿条记录的聚合查询,在 100 节点 MPP 集群中,每个节点仅需处理 1000 万条记录,实现 “分而治之”。
-
无共享架构(Shared-Nothing):每个计算节点拥有专属 CPU、内存和存储资源,节点间通过高速互联网络协作,避免资源竞争。这与共享存储架构(如 Oracle RAC)形成鲜明对比。
-
数据分片与本地化处理:采用哈希、范围或混合分片策略,确保数据均匀分布,并优先在数据所在节点执行计算(数据亲和性原则),最小化网络数据移动。
2. 核心组件协同机制
协调节点(Coordinator)负责接收客户端请求、解析 SQL、生成执行计划并协调分布式执行。 计算节点(Worker)执行实际数据处理任务。存储层采用高效数据组织方式,优化 IO 性能。
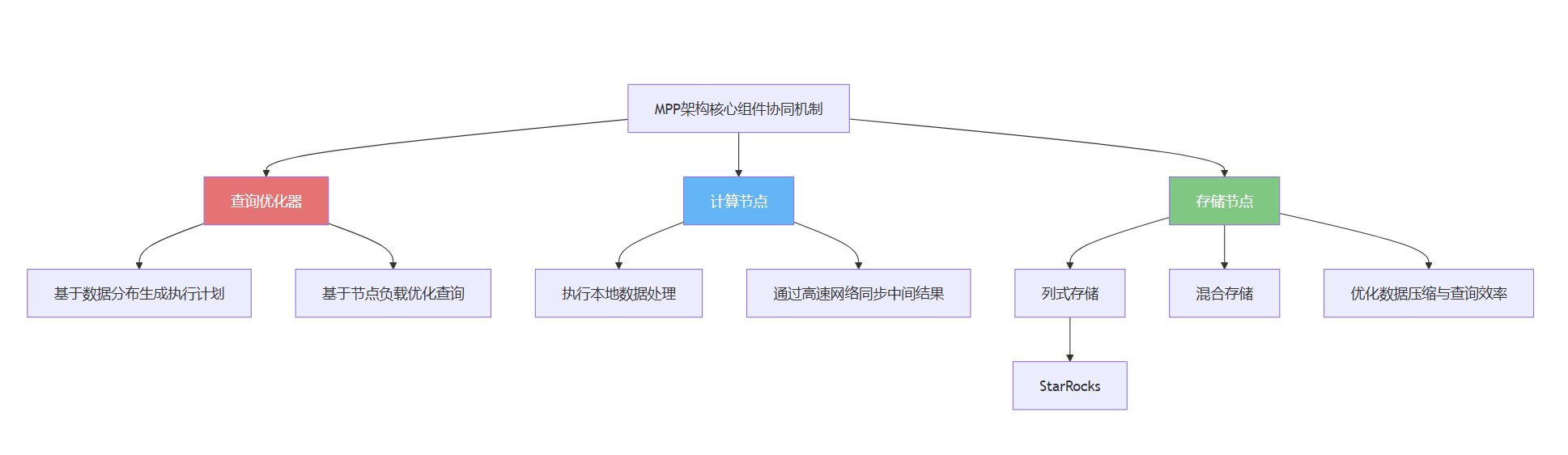
- 查询优化器:自动生成分布式执行计划。例如,AWS Redshift 的优化器会根据数据分布动态调整 JOIN 顺序,降低网络传输开销。
- 计算节点:采用向量化引擎(如 StarRocks)或 LLVM 编译优化(如 ClickHouse)提升单节点处理效率。
- 存储节点:列式存储(Parquet/ORC 格式)结合数据分区(Partitioning)与分桶(Bucketing),实现高效压缩与快速过滤。
三、MPP 架构的四大核心优势
1. 高性能:线性扩展能力
MPP 架构最显著优势在于通过增加节点实现近乎线性的性能提升。
这种线性扩展特性使 MPP 架构能够应对 “大促” 等突发流量场景。菜鸟物流分析平台在 “双 11” 期间,通过动态扩展 StarRocks 集群从 30 节点至 120 节点,平均查询响应时间保持在 1.2 秒以内,确保实时物流决策。
关键技术支撑:
-
分布式执行优化:自动识别并优化数据倾斜
-
并行度动态调整:根据数据分布和节点负载自适应调整任务并行度
-
分布式操作符:特殊设计的 Hash-Join、分布式聚合算法,确保扩展效率
2. 高扩展性:存算分离实践
云原生 MPP 数据库(如 Snowflake、StarRocks 等)基于存算分离架构,实现三大灵活性:
-
计算资源弹性:可在秒级动态调整计算节点数量,适应负载变化。某亚洲电商平台采用 “潮汐型” 资源调度策略,白天维持 64 节点集群支撑业务查询,夜间自动缩减至 16 节点执行 ETL 作业,计算成本降低 52%。
-
存储无限扩展:基于对象存储(S3、OSS、GCS)构建无限容量数据湖。Netflix 将超过 100PB 媒体分析数据存储于 S3,通过 Snowflake 实现按需查询,存储成本较传统 SAN 降低 87%。
-
多租户隔离:支持为不同业务部门分配独立计算资源,避免各业务场景下资源利用率不足问题。
3. 高兼容性:标准 SQL 与生态集成
现代 MPP 数据库普遍提供高度兼容的 SQL 接口,高兼容性降低了技术迁移风险。
同时,现代 MPP 平台提供丰富的连接器和 API,实现与数据科学工具等 生态系统的无缝集成。
-
Snowflake Snowpark 支持 Python/Java/Scala UDF 直接在 MPP 环境执行;
-
Redshift 与 SageMaker 集成,支持 ML 模型训练和推理;
-
StarRocks 与开源 Iceberg/Hudi/Delta Lake 湖仓一体化,统一分析入口;
4. 高可用性:多副本与自动修复
企业级 MPP 架构通过多层次可靠性保障,确保业务连续性:
-
数据冗余与自愈:自动维护多副本(通常 3 副本),节点故障时自动重建。
-
故障检测与自动恢复:心跳机制快速识别故障节点(通常 < 10 秒),重新分配任务。
-
地理分布式部署:支持跨区域同步复制。
-
渐进式恢复:故障后优先恢复关键业务查询能力,实现业务分级可用。
四、MPP 架构与其他架构对比
1. 架构特性与性能比较
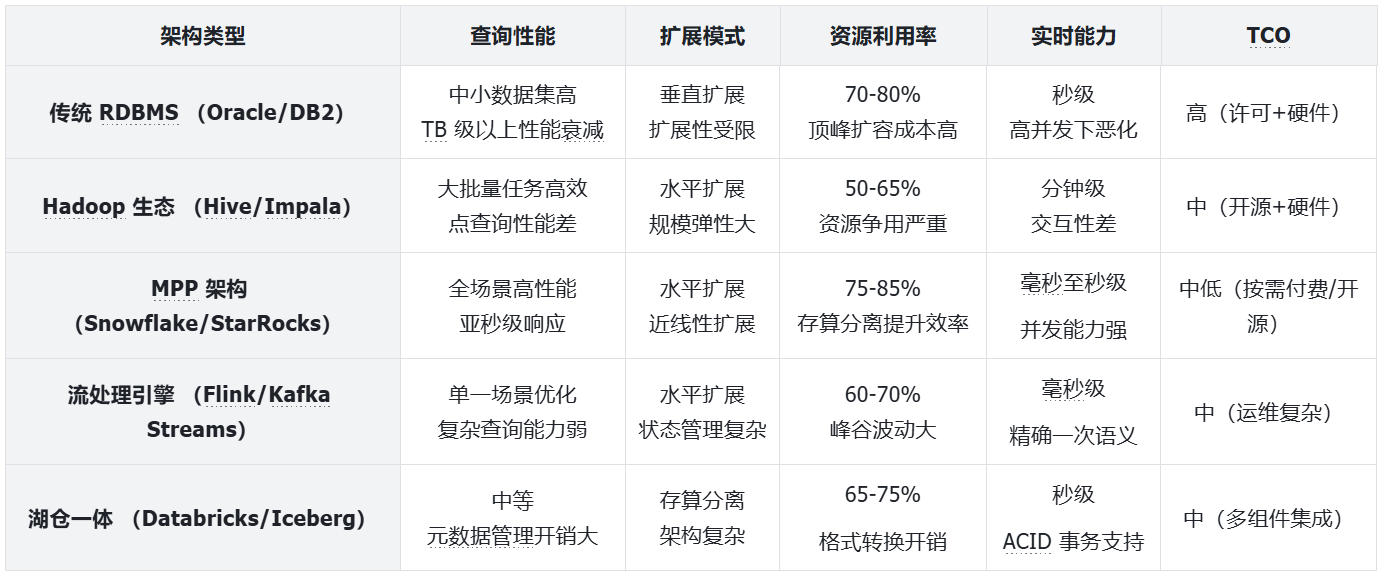
2. 不同架构的最佳适用场景
-
传统 RDBMS:事务密集型应用、结构化数据管理、中小规模分析(<1TB);
-
Hadoop 生态:非结构化数据处理、批量 ETL 作业、廉价存储海量历史数据;
-
MPP 架构:交互式分析、实时仪表盘、高并发 BI 报表、复杂多表关联分析;
-
流处理引擎:事件流处理、实时监控告警、连续查询场景;
-
湖仓一体:统一数据平台、混合工作负载、数据科学与 AI/ML 场景;
不过,近年来各架构边界日益模糊,呈现融合发展趋势:
-
MPP + 流处理:StarRocks 支持 Flink 实时入湖,实现秒级数据可查询;
-
MPP+AI 加速:Snowflake Cortex、BigQuery ML 提供内置机器学习能力;
-
MPP + 湖仓一体:Databricks Photon、StarRocks 实现统一查询层;
结语
MPP 架构正在重塑企业数据分析范式。从金融实时风控到广告效果归因,其价值已在全球头部企业中得到验证。随着云原生技术的成熟,未来 MPP 数据库将进一步融合弹性计算、智能优化等能力,成为企业解锁数据价值的核心基础设施。对于技术选型者而言,需紧扣业务场景,在性能、成本、扩展性之间找到最佳平衡点,让 MPP 架构真正成为驱动业务增长的“数据引擎”。