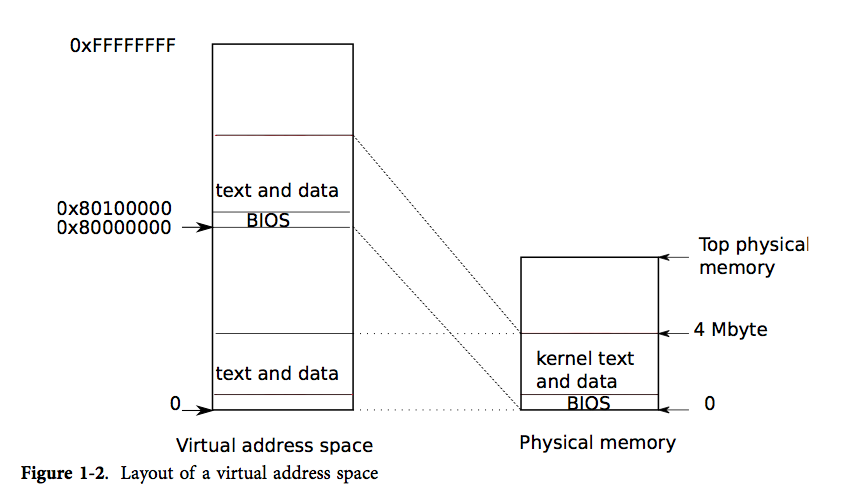
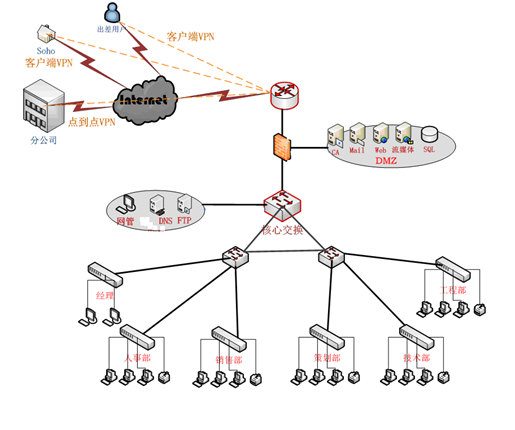
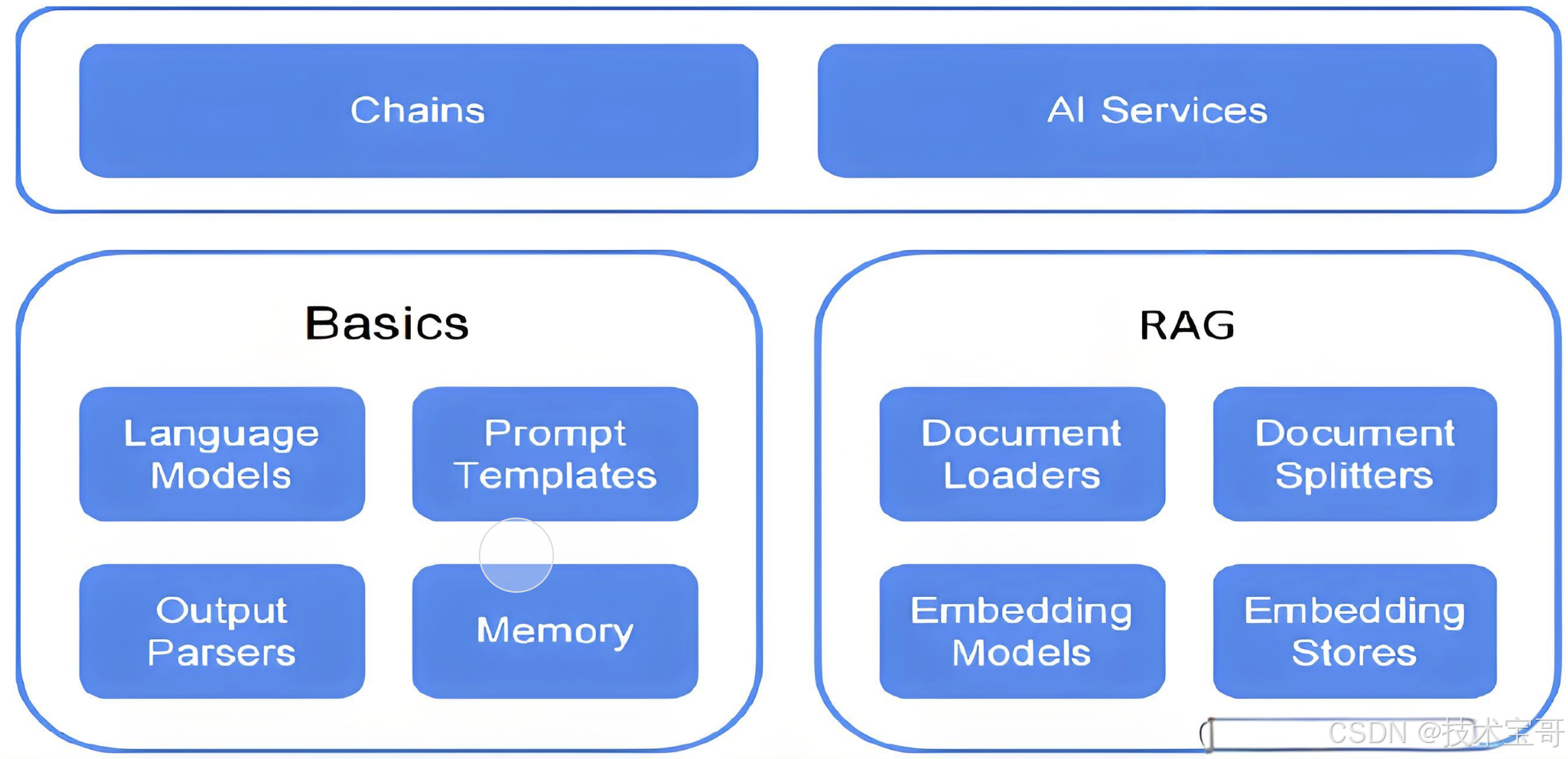
数组合并
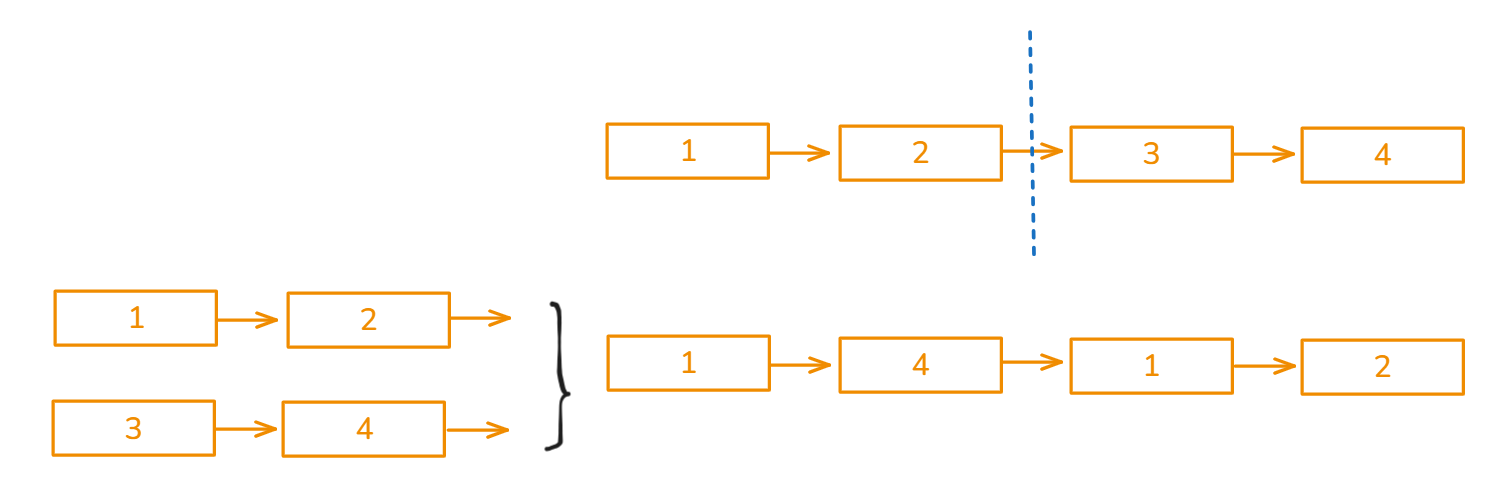
假设有 n 个长度为 k 的已排好序(升序)的数组,请设计数据结构和算法,将这 n 个数组合并到一个数组,且各元素按升序排列。即实现函数:
void merge_arrays(const int* arr, int n, int k, int* output);
其中 arr 为按行优先保存的 n 个长度都为 k 的数组,output 为合并后的按升序排列的数组,大小为 n×k。
时间要求(评分规则),当 n > k 时:
- 满分:时间复杂度不超过 O(n×k×log(n))
- 75分:时间复杂度不超过 O(n×k×log(n)×k)
- 59分:其它,如:时间复杂度为 O(n2×k2) 时。
#include<stdio.h>
#include<stdlib.h>
void max_heapify(int* p, int i, int size) {
int j = 2 * i + 1, t=p[i];
while (j <= size - 1) {
if (j + 1 <= size - 1 && p[j] < p[j + 1])j = j + 1;
if (p[j] > t) {
p[i] = p[j];
i = j;
j = 2 * i + 1;
}
else break;
}
p[i] = t;
}//假设i之后都是大根堆,调整i使从i开始都是大根堆
void merge_arrays(const int* arr, int n,int k,int* output) {
int size=n*k;
int x, i, *array;
array = (int*)malloc(size * sizeof(int));
for (i = 0; i <= size - 1; i++) {
array[i] = arr[i];
}
for (i=size/2-1; i >=0 ; i--) {
max_heapify(array, i, size);
}//将整个堆大根堆化
for (i = size-1; i >= 1; --i) {
x = array[0];
array[0] = array[i];
array[i] = x;
max_heapify(array, 0, i);
}
for (i = 0; i <= size - 1; i++) {
output[i] = array[i];
}
}
堆化
二叉堆一般用数组来表示。例如,根节点在数组中的位置是0,第n个位置的子节点分别在2n+1和 2n+2。 因此,第0个位置的子节点在1和2,1的子节点在3和4。以此类推。这种存储方式便于寻找父节点和子节点。在二叉堆上可以进行插入节点、删除节点、取出值最小的节点、减小节点的值等基本操作。
“最小堆”的定义如下:
typedef struct _otherInfo
{
int i;
int j;
}OtherInfo;
typedef struct _minHeapNode
{
int value;
OtherInfo otherInfo;
}MinHeapNode, *PMinHeapNode;
typedef struct _minPQ {
PMinHeapNode heap_array; // 指向堆元素数组
int heap_size; // 当前堆中的元素个数
int capacity; //堆数组的大小
}MinHeap, *PMinHeap;
请实现最小堆的“堆化”函数:
void min_heapify(PMinHeap pq, int i);
其中 pq指向堆,i 为堆元素在数组中的下标。该函数假设元素i对应的子树都已经是最小堆(符合最小堆的要求),但元素i为根的子树并不是最小堆,min_heapify将对元素i及其子树的各结点进行调整,使其为一个最小堆。
(注:假设辅助函数 left、right、parent 和 swap_node 已正确实现,min_heapify 函数可直接使用。)
#include <stdio.h>
#include <stdlib.h>
#include "minbinheap.h"
void min_heapify(PMinHeap pq, int i){
int j = 2 * i + 1;
MinHeapNode* p = pq->heap_array;
while (j <= pq->heap_size - 1){
//j为最小值的堆
if (p[j + 1].value < p[j].value)
j = j + 1;
if (p[j].value < p[i].value) {
swap_node(&p[j], &p[i]);
i = j;
j = 2 * i + 1;
}
else return;
}
}堆元素插入
二叉堆一般用数组来表示。例如,根节点在数组中的位置是0,第n个位置的子节点分别在2n+1和 2n+2。 因此,第0个位置的子节点在1和2,1的子节点在3和4。以此类推。这种存储方式便于寻找父节点和子节点。在二叉堆上可以进行插入节点、删除节点、取出值最小的节点、减小节点的值等基本操作。
“最小堆”的定义如下:
typedef struct _otherInfo
{
int i;
int j;
}OtherInfo;
typedef struct _minHeapNode
{
int value;
OtherInfo otherInfo;
}MinHeapNode, *PMinHeapNode;
typedef struct _minPQ {
PMinHeapNode heap_array; // 指向堆元素数组
int heap_size; // 当前堆中的元素个数
int capacity; //堆数组的大小
}MinHeap, *PMinHeap;
请实现最小堆的元素插入函数:
bool heap_insert_value(PMinHeap pq, int value);
其中 pq指向堆,value 为要插入的堆元素。
(注:假设辅助函数 parent 和 swap_node 已正确实现,heap_insert_value 函数可直接使用。)
#include <stdio.h>
#include <stdlib.h>
#include "minbinheap.h"
#define H pq->heap_array
bool heap_insert_value(PMinHeap pq, int value){
if(pq->heap_size==pq->capacity)return false;
int i=pq->heap_size;
H[i].value=value;
while(i!=0&&H[i].value<H[parent(i)].value){
swap_node(&H[i],&H[parent(i)]);
i=parent(i);
}
pq->heap_size++;
return true;
}堆初始化
二叉堆一般用数组来表示。例如,根节点在数组中的位置是0,第n个位置的子节点分别在2n+1和 2n+2。 因此,第0个位置的子节点在1和2,1的子节点在3和4。以此类推。这种存储方式便于寻找父节点和子节点。在二叉堆上可以进行插入节点、删除节点、取出值最小的节点、减小节点的值等基本操作。
“最小堆”的定义如下:
typedef struct _otherInfo
{
int i;
int j;
}OtherInfo;
typedef struct _minHeapNode
{
int value;
OtherInfo otherInfo;
}MinHeapNode, *PMinHeapNode;
typedef struct _minPQ {
PMinHeapNode heap_array; // 指向堆元素数组
int heap_size; // 当前堆中的元素个数
int capacity; //堆数组的大小
}MinHeap, *PMinHeap;
请实现最小堆的初始化函数:
void init_min_heap(PMinHeap pq, int capacity);
其中 pq指向堆,capacity为堆元素数组的初始化大小。
#include <stdio.h>
#include <stdlib.h>
#include "minbinheap.h"
//pq指向堆,capacity为堆元素数组的初始化大小
void init_min_heap(PMinHeap pq, int capacity){
pq->capacity = capacity;
pq->heap_size = 0;
pq->heap_array = (PMinHeapNode)malloc(sizeof(MinHeapNode) * pq->capacity);
return;
}堆辅助函数
二叉堆是完全二叉树或者是近似完全二叉树。二叉堆有两种:最大堆和最小堆。
- 最大堆(大顶堆):父结点的键值总是大于或等于任何一个子节点的键值,即最大的元素在顶端;
- 最小堆(小顶堆):父结点的键值总是小于或等于任何一个子节点的键值,即最小的元素在顶端。
- 二叉堆子结点的大小与其左右位置无关。
二叉堆一般用数组来表示。例如,根节点在数组中的位置是0,第n个位置的子节点分别在2n+1和 2n+2。 因此,第0个位置的子节点在1和2,1的子节点在3和4。以此类推。这种存储方式便于寻找父节点和子节点。在二叉堆上可以进行插入节点、删除节点、取出值最小的节点、减小节点的值等基本操作。
“最小堆”的定义如下:
typedef struct _otherInfo
{
int i;
int j;
}OtherInfo;
typedef struct _minHeapNode
{
int value;
OtherInfo otherInfo;
}MinHeapNode, *PMinHeapNode;
typedef struct _minPQ {
PMinHeapNode heap_array; // 指向堆元素数组
int heap_size; // 当前堆中的元素个数
int capacity; //堆数组的大小
}MinHeap, *PMinHeap;
请实现最小堆的四个辅助函数:
int parent(int i); //返回堆元素数组下标为 i 的结点的父结点下标
int left(int i); //返回堆元素数组下标为 i 的结点的左子结点下标
int right(int i); //返回堆元素数组下标为 i 的结点的右子结点下标
void swap_node(MinHeapNode *x, MinHeapNode *y); //交换两个堆元素的值#include <stdio.h>
#include <stdlib.h>
#include "minbinheap.h" // 请不要删除,否则检查不通过
int parent(int i) {
return (i-1) / 2;
}
int left(int i){
return 2 * i + 1;
}
int right(int j) {
return 2 * j + 2;
}
void swap_node(MinHeapNode* x, MinHeapNode* y) {
int value;
int i, j;
value = y->value;
i = y->otherInfo.i;
j = y->otherInfo.j;
y->value = x->value;
y->otherInfo.i = x->otherInfo.i;
y->otherInfo.j = x->otherInfo.j;
x->value = value;
x->otherInfo.i = i;
x->otherInfo.j = j;
}