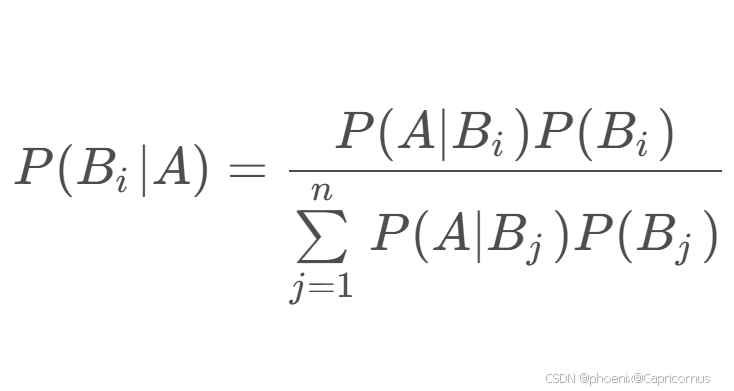1、现有工作的缺陷:
最近,出现了一种基于模块化航路点的方法的新兴趋势,该方法将复杂任务分为航路点生成、子目标规划和导航控制:
(1)在每个决策循环中,代理使用预训练的网络来预测附近的几个候选航路点,然后执行跨模态接地,从航路点中选择一个子目标;
(2)控制器通过低级操作驱动代理到达选定的子目标。
基于航路点的方法存在三个问题:
(1)预测的航路点仍然是局部的,并且局限于代理的附近区域,这不足以捕捉全局环境布局,并可能阻碍代理的长期规划能力;
(2)航路点预测的关键设计选择尚未得到很好的研究;
(3)针对航路点到达,提出了不同类型的控制器(启发式、基于地图、基于学习,但它们对障碍物的鲁棒性仍然未知。
2、本工作的主要贡献:
(1)提出了一种新的基于拓扑图的VLN-CE鲁棒导航规划方法。它可以有效地抽象连续环境,并促进代理的长期目标规划;
(2)通过综合实验研究了构建拓扑图的基本设计选择,证明了简洁的深度设计是航路点预测的最佳选择;
(3)提出了一种有效的试错控制器来解决避障问题。
一、模型整体框架
1.1 任务描述
在每个Eposide:
(1)文本输入:将L个单词的文本指令的嵌入表示为;
(2)视觉输入:在每个位置,接受全景RGB-D观察,即由12个RGB图像和12个深度图像组成。其中这些图像是在12个等距的水平航向角(即(0°、30°、…、330°)上捕获的。
1.2 模型介绍
模型的整体框架如下图所示,该模型利用基于高级拓扑图的规划和低级控制器来完成VLN-CE任务:
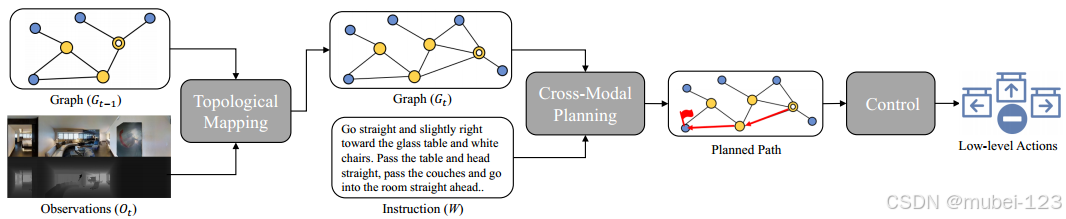
可以看出,主要包括三个模块:拓扑映射、跨模态规划和控制。
(1)拓扑映射:拓扑映射模块为每个Eposide维护一个拓扑图。在每个决策循环中,拓扑映射模块首先通过合并当前观测值来更新拓扑图;
(2)跨模态规划:跨模态规划模块对拓扑图和指令进行跨模态推理,以制定高级拓扑路径规划;
(3)控制:当跨模态规划模块指定完毕计划后,由控制模块负责执行,该模块通过一系列低级操作驱动代理。
二、难点
2.1 拓扑映射
2.1.1 拓扑图构建
拓扑图构建——总共分为已访问节点、当前节点和ghost节点(已观察但未探索):
(1)将遍历路径上访问或观察到的位置抽象为图形表示,在步骤 表示为
:
(2)每个节点()都包含在其位置观察到的视觉信息以及位置信息;
(3)如果两个节点的表示位置可以直接相互到达,则它们由边()连接,边存储两个节点之间的相对欧几里德距离。
拓扑图构建及更新整体流程如下图所示:

(1)在每个步骤 ,代理首先预测几个附近可能可访问位置的航路点,表示代理附近大概能访问的位置;
(2)当前节点也在代理的当前位置初始化,并连接到上次访问的节点(如果存在);
(3)预测的航路点和当前节点由当前观测值 的特征嵌入表示。这些航路点将被组织起来,以更新之前的地形图
并获得当前的地图
。
2.1.2 视觉输入处理
给定当前步骤的RGB-D观测值,使用两个不同的预训练视觉编码器分别提取RGB特征向量
和深度特征向量
。为了区分从全景的不同视图捕获的特征,我们还应用了方向特征
,其中
表示偏航角。两个视觉编码器的参数是固定的。
2.1.3 航路点预测
采用基于Transformer的航路点预测器来生成附近的航路点。预测器采用深度特征向量 和方向特征向量
来预测航路点的相对位姿:
(1)使用线性层融合 和
中的特征向量;
(2)融合后的向量被馈送到两层Transformer中,以进行视图间交互并获得上下文深度嵌入;
(3)将这些嵌入输入多层感知器,以获得表示空间中附近航路点概率的热图;
(4)使用非最大抑制(NMS)从热图中采样K个航路点 ,其中
表示与无人机的相对位姿。
需要注意的是:
(1)预测器只将深度图像作为输入,而不是全部使用RGBD图像。这种深度设计的动机是,航路点只代表空间可达性,而语义级RGB信息可能没有帮助,甚至是有害的;
(2)预测器在MP3D图形数据集上进行了预训练,它的参数是固定的。
2.1.4 航路点和当前节点的视觉表示
对当前观测值 进行特征映射,以表示预测的航路点和当前节点:
(1)RGB特征 、深度特征
和方向特征
使用线性层进行融合,然后馈送到全景编码器中,全景编码器使用多层Transformer来执行视图间交互,并输出上下文视觉嵌入
;
(2)当前节点可以访问全景观测,因此表示为 的平均值;
(3)预测的航路点是部分观察到的航路点,由可以观察到它们的视图的嵌入表示。例如,如果航路点与代理的相对偏航角在0°~30°以内,则航路点由第一个视图嵌入 表示;
(4)航路点表示将被合并以更新ghost节点的表示。
2.1.5 拓扑图更新
根据预测的航路点与图中现有节点的空间关系更新拓扑图。该过程利用航路点定位(FL)功能来定位图中的航路点——FL将航路点的位置作为输入,并计算其与图中所有节点的欧几里德距离。如果最小距离小于阈值γ,FL将相应的节点作为局部节点返回。主要分为三类:
(1)如果已访问节点被定位,删除输入航路点,并在当前节点和本地化的访问节点之间添加一条边;
(2)如果ghost节点被定位,则将输入航路点的位置视觉表示累积到定位的ghost节点,同时删除输入航路点。局部ghost节点的新位置和表示被更新为其累积的航路点位置和表示的平均值;
(3)如果没有节点被定位,将输入的航路点视为新的ghost节点。
2.2 跨模态规划
跨模态规划模块由文本编码器和跨模态图编码器组成,如下图所示:
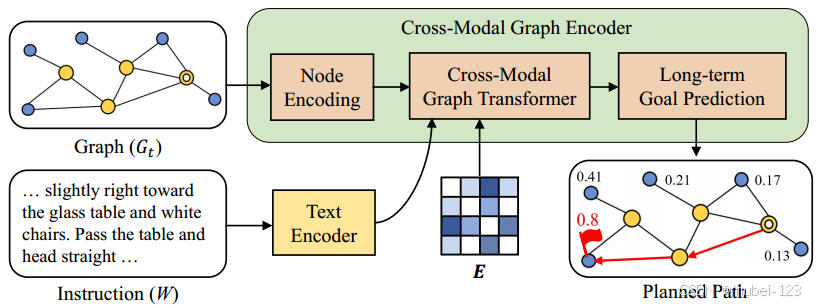
当前Episode的指令由文本编码器编码,然后,跨模态图编码器对编码的拓扑图和编码的指令进行推理,以预测长期目标节点,输出是到达目标的规划拓扑路径。
文本编码器为多层Transformer,此处不再赘述,重点分析跨模态图编码器。
2.2.1 节点编码
该模块采用拓扑图 和编码指令
来预测拓扑图中的长期目标节点。节点
中的视觉特征添加了位姿编码和导航步骤编码:
(1)位姿编码嵌入了节点相对于代理当前位置的全局相对位姿信息,包括其方向和相对于当前节点的欧几里德距离;
(2)导航步骤编码为访问过的节点嵌入了最新访问的时间步,为ghost节点嵌入了0,这种方式允许用不同的历史对访问过的节点进行编码,以捕获导航依赖关系并促进与指令的对齐。
的编码表示为
。为了表示STOP操作,在图中添加一个“STOP”节点,并将其与所有其他节点连接。
2.2.2 跨模态图Transformer
编码的节点和词嵌入被馈送到多层Transformer中,以进行跨模态交互。Transformer的结构类似于LXMERT,每一层由一个双向交叉注意力子层、两个自注意力子层和两个前馈子层组成。;
(1)首先计算节点和文本的交叉注意力;
(2)然后对编码的节点计算自注意力(GASA)。对于节点编码,标准的注意力层只考虑节点之间的视觉相似性,这可能会忽略比远处节点更相关的附近节点。为此,本工作设计了一种图感知自注意力(GASA),在计算节点编码的节点间注意时进一步考虑了图拓扑:
![]()
其中X表示所有节点编码的堆栈,E是由从图边 获得的所有对最短距离构造的空间矩阵。生成的节点视觉文本关联表示
。
(3)再通过前馈层。
2.2.3 长期目标预测
拓扑图 中每个节点
的导航目标预测得分计算如下:
![]()
需要注意的是:
(1)得分 计算的是“stop”节点的得分,表示“停止”动作的概率;
(2)为了避免对已访问节点进行不必要的重复访问,屏蔽已访问节点和当前节点的得分,只从ghost节点或“停止”节点中选择长期目标;
(3)代理根据预测的目标分数选择一个长期目标(即分数最大的那个),通过在图上执行Dikjstra算法来计算到目标的最短路径,此路径由一系列子目标节点 组成。
2.3 控制
控制模块负责将拓扑计划 转换为一系列低级动作,以引导代理实现目标。控制模块的输入包括子目标节点规划
的序列,以及无人机在每个时间步长的位姿。导航控制的输出动作空间是由VLN-CE任务定义的一组参数化低级动作,例如前进(0.25m)、左、右旋转(15°)和停止。
主要实施过程采用旋转然后向前控制器(RF):
(1)为了到达子目标节点,RF首先访问代理的当前位姿并计算其与
的相对方向和距离
;
(2)然后, 被量化并转化为一系列旋转(15°)动作,然后是前进(0.25m)动作序列。RF按顺序执行这些转换后的动作;
(3)当前子目标完成, 中的后续节点成为新的子目标。循环重复,直到
中不再有节点。
三、总结
(1)航路点预测器的结论(只采用深度图像信息)能否应用到目标预测器上?
(2)之前那片文章没有很好地利用已访问节点(位置)的信息?