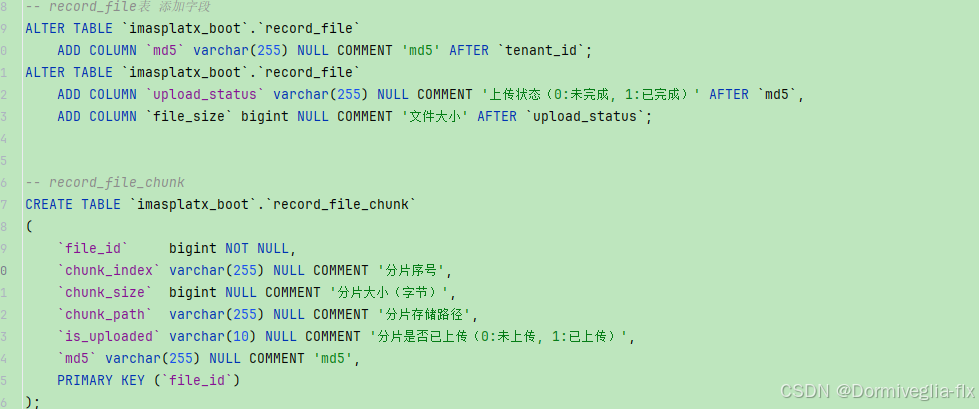
在 Kubernetes 集群中,容器状态为 CrashLoopBackOff 通常意味着容器启动失败,并且 Kubernetes 正在不断尝试重启它。这种状态表明容器内可能存在严重错误,如应用异常、依赖服务不可用、配置错误等。本文将分享一次实际排障过程,并说明如何通过删除异常 Pod 并触发自动重建来解决问题。
一、什么是 CrashLoopBackOff?
CrashLoopBackOff 是 Kubernetes 中的一种常见状态,表示容器启动失败并反复重启。每次失败后,Kubernetes 会按指数退避(Exponential Backoff)策略延长下一次重启的时间,以避免资源浪费和系统雪崩。
二、问题背景
在一次例行的集群巡检中,我们发现某个 Pod 的状态异常:
NAME READY STATUS RESTARTS AGE
channel-cabin-index-api-pre-k8s-26870-boot-0 0/1 CrashLoopBackOff 2715 (2m4s ago) 10d
该容器已经重启了 2715 次,说明始终无法正常启动,已经进入严重的崩溃循环。
三、排查与处理步骤
1. 查看 Pod 详情
首先查看 Pod 的详细描述和事件信息,判断是否有明显的错误提示:
kubectl -n prd00528 describe pod channel-cabin-index-api-pre-k8s-26870-boot-0
2. 查看容器日志
容器日志是排查启动失败的关键线索:
kubectl -n prd00528 logs channel-cabin-index-api-pre-k8s-26870-boot-0 -c boot
日志中出现如下错误:
${idata.permession.funcCode} can't be replace
这表明代码中存在未被正确渲染的模板变量,而实际代码中并没有 idata.permession.funcCode,因此我们怀疑部署的镜像并未更新成功,容器仍运行着旧版本代码。
3. 删除异常 Pod
由于 Kubernetes 中 Deployment 控制器会自动重建被删除的 Pod,我们决定删除该异常 Pod,触发一次重新部署:
kubectl -n prd00528 delete pod channel-cabin-index-api-pre-k8s-26870-boot-0
4. 观察新 Pod 状态
Kubernetes 会立即基于 Deployment 的配置重新调度一个新的 Pod:
kubectl -n prd00528 get pods
刚创建时状态为 PodInitializing,随后应过渡为 Running。
5. 再次验证日志
确认新 Pod 正常运行并查看容器日志是否已修复异常:
kubectl -n prd00528 logs channel-cabin-index-api-pre-k8s-26870-boot-0 -c boot
问题不再出现,说明新部署的代码已生效,问题解决。
四、总结与建议
当容器进入 CrashLoopBackOff 状态时,最关键的是排查失败原因,而不是盲目重启或删除。此次问题的根本原因是容器实际运行的镜像未更新成功,导致旧代码中的模板变量未被替换,最终触发启动失败。
✅ 关键点回顾:
CrashLoopBackOff表示容器启动失败并进入无限重启循环。- 查看容器日志可快速定位失败原因。
- 删除 Pod 会触发 Kubernetes 自动重新调度。
- 若怀疑镜像未更新,可通过重新部署验证问题是否修复。
⚠️ 注意事项:
- 删除 Pod 前务必确认问题不在配置、环境变量或依赖服务上。
- 如使用 CI/CD 工具发布,请确保镜像构建和推送流程无误。
- 可通过为镜像打唯一版本号(Tag)来避免镜像缓存导致的问题。
通过本次实战,我们不仅解决了 CrashLoopBackOff 问题,还复盘了镜像部署流程中的潜在风险,进一步保障了服务的稳定性。