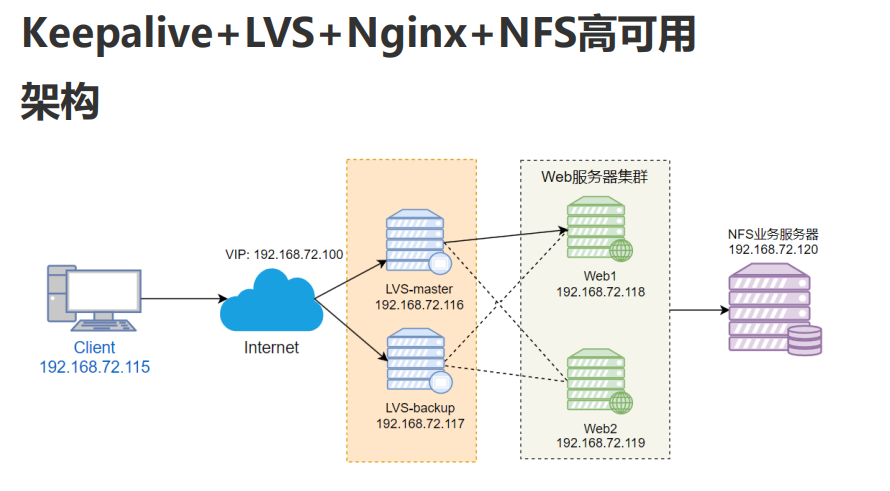
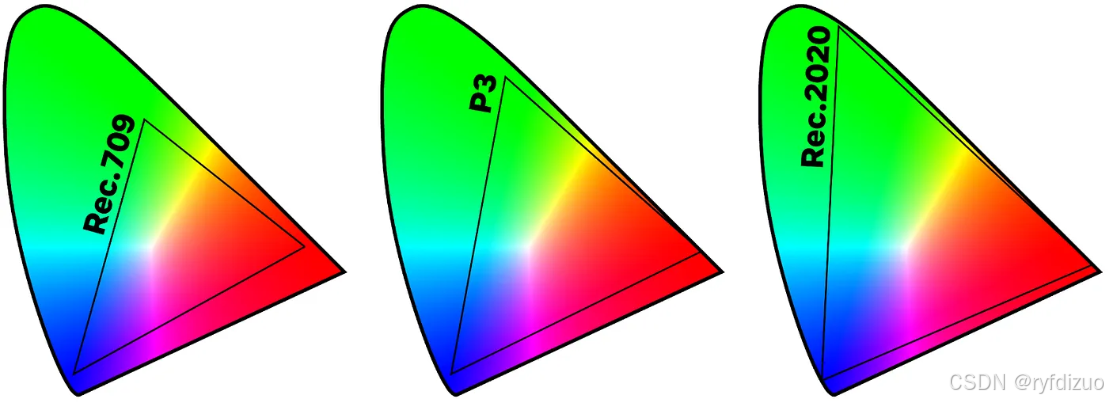
一、AI应用场景和发展历程
1.1行业应用
1、deepdream图像生成、yolo目标检测


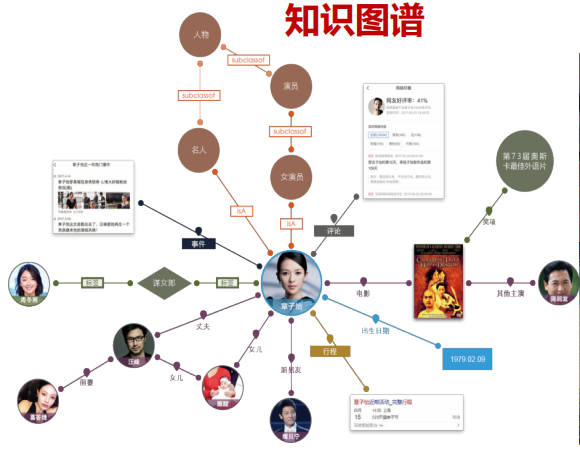
2、知识图谱、画风迁移

3、语音识别、计算机视觉

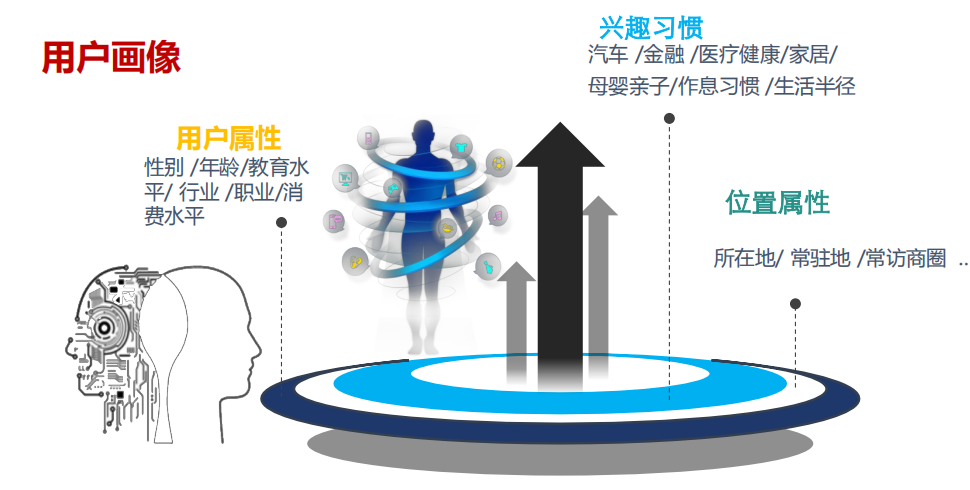
4、用户画像
5、百度人工智能布局

1.2发展历程
- 1980年代是正式成形期,尚不具备影响力。
- 1990-2010年代是蓬勃发展期,诞生了众多的理论和算法,真正走向了实用。
- 2012年之后是深度学习期,深度学习技术诞生并急速发展,较好的解决了现阶段AI的一些重点问题,并带来了产业界的快速发展。
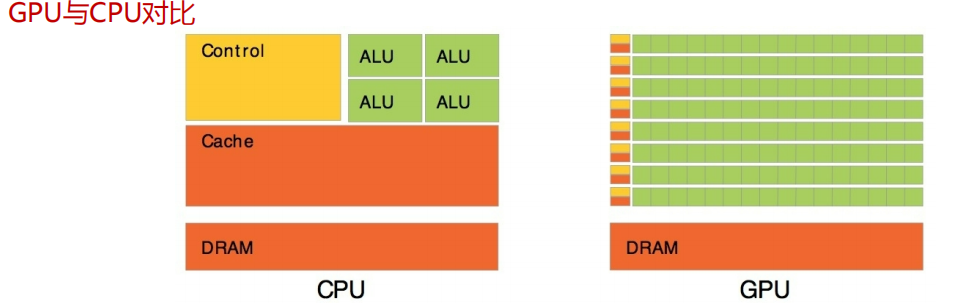
1.3GPU和CPU比较
二、人工智能主要分支
2.1 机器学习
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测
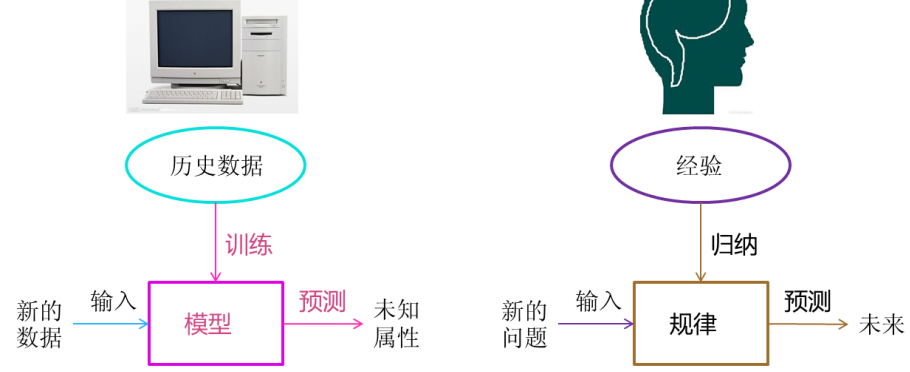
机器学习是从人工智能中产生的一个重要学科分支,是实现智能化的关键
经典定义:利用经验改善系统自身的性能
随着该领域的发展,目前主要研究智能数据分析的理论和算法,并已成为智能数据分析技术的源泉之一

2.2深度学习
深度学习通过组合低层特征形成更加抽象的高层表示属性类别,以发现数据的分布式特征表示。

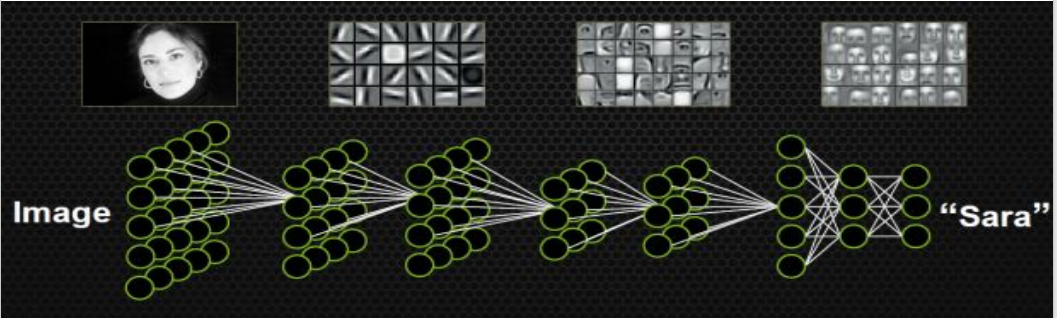
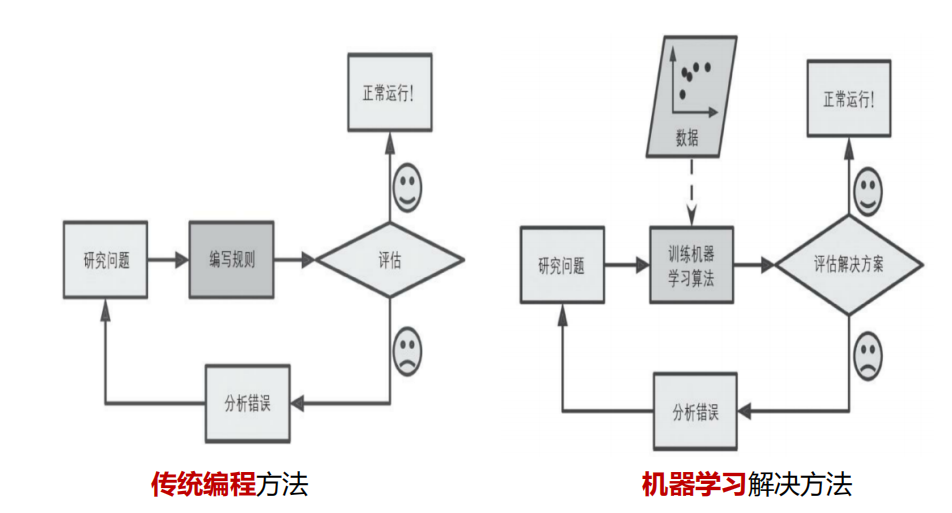
2.3机器学习vs深度学习
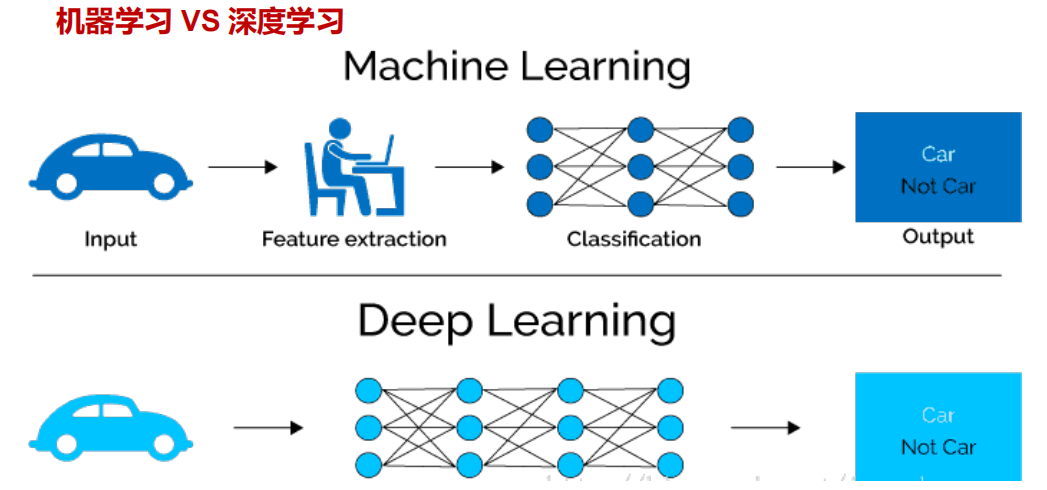
三、机器学习工作流程
1.获取数据 2.数据预处理 3.特征工程 4.机器学习(模型训练) 5.模型评估
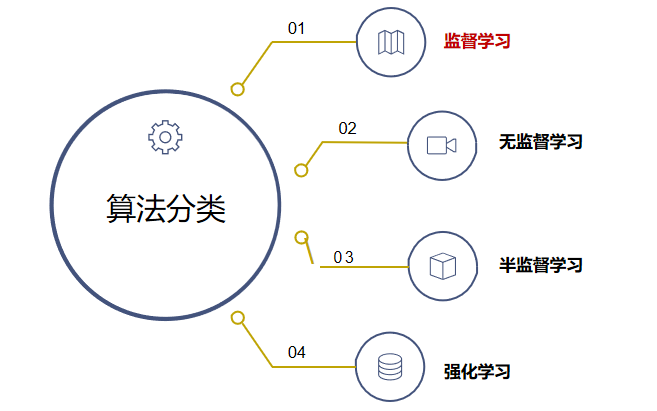
四、机器学习算法分类
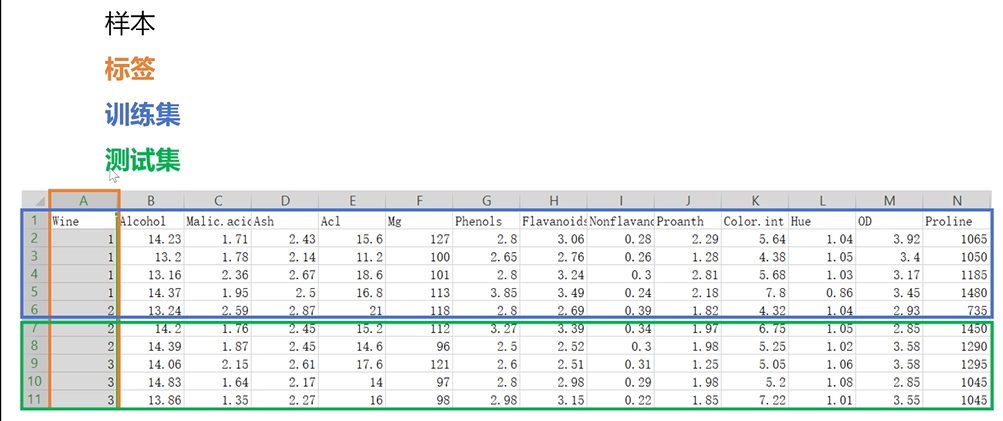
第一列叫标签,每一列叫特征,每一行叫样本
训练集就是指历史数据,可以理解为课堂作业,既能看到特征数据也能看到标签,通过训练集学习内在规律
测试集就是考试,只能看到特征数据,看不到标签,通过考试预测标签
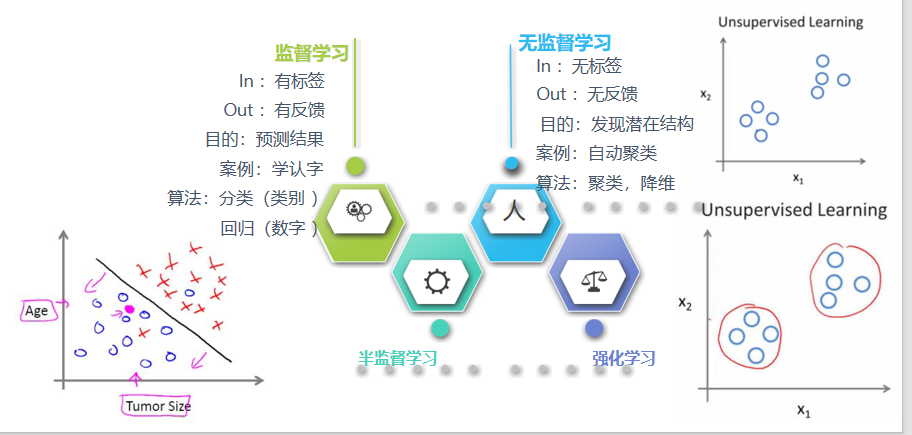
4.1有监督学习
1.监督学习:有标签,监督就是指有标签,有标准答案
有监督定义:输入数据是由输入特征值和目标值所组成,即输入的训练数据 为有标签的。
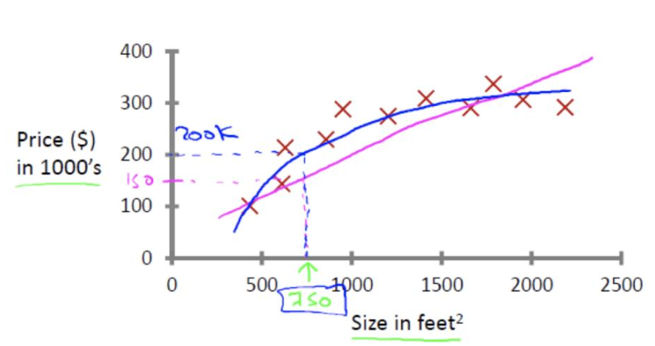
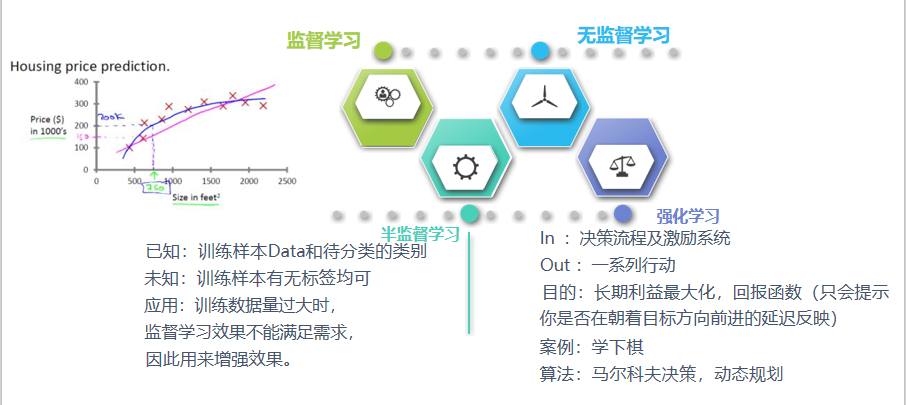
- 有监督学习1:回归问题
回归问题:给定D维输入变量x ,并且每一个输入矢量x都有对应的值y,要求对于新来的数据预测它对应的连续的目 标值t。 例如:预测房价,根据样本集拟合出一条连续曲线
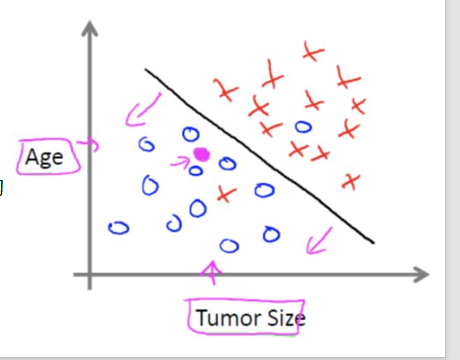
- 有监督学习2:分类问题
回归问题和分类问题的本质一样,都是针对输入做出输出预测,其区别在于输出预测的类型。 分类问题:给定一个新的模式,根据训练集推断它所 对应的类别(如:+1 ,-1 ),是一种定性输出,也叫离散变量预测,而回归问题,给定一个新的模式,根据训练集推断它所对应的输出值(实数)是多少,是一种定量输出,也叫连续变量预测。 如果预测的结果为连续的值,是回归问题; 如为离散的值,是分类问题 例如:根据肿瘤特征判断良性还是恶性,得到的是结 果是“ 良性”或者“恶性” ,是离散的;温度是连续的值,所以是回归。
总结:训练结果跟数据集质量,分布有关。俗话说,"垃圾进垃圾出"
分类问题,结果是固定的,比如良性、恶性等;回归问题是预测一个数值。、
- 监督学习:有标签
- 任务:分类任务和回归任务
4.2无监督学习
无监督定义:输入数据没有被标记,也没有确定的结果,即样本数据类别未知,没有标签,需要根据样本间的相似性对样本集进行聚类,以发现事物内部结构及相互关系。
第一类:基于样本间相似性度量的聚类方法:设法 定出不同类别的核心或初始内核,然后依 据样本与核心之间的相似性度量将样本聚 集成不同的类别。
第二类:基于概率密度函数估计的直接方法:指 设法找到各类别在特征空间的分布参数, 再进行分类。
无监督学习是在寻找数据集中的规律性,这种规律性并不一定要达到划分数据集 的目的,也就是说不一定要“分类”。 这一点是比有监督学习方法的用途要广。譬如分析一堆数据的主分量,或分析数 据集有什么特点都可以归于非监督学习方法的范畴。
4.3半监督学习
半监督学习:训练集数据一部分有标签而其余部分无标签,即训练集同时包含有标记样 本和无标记样本。
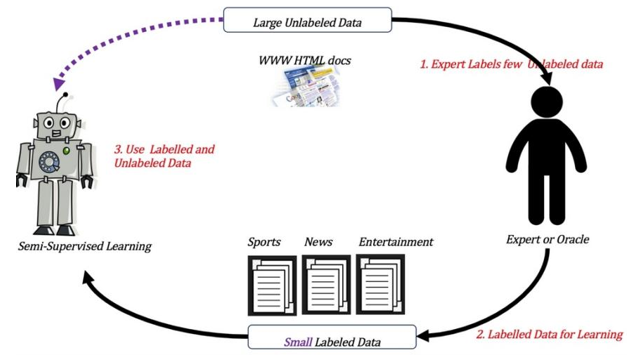

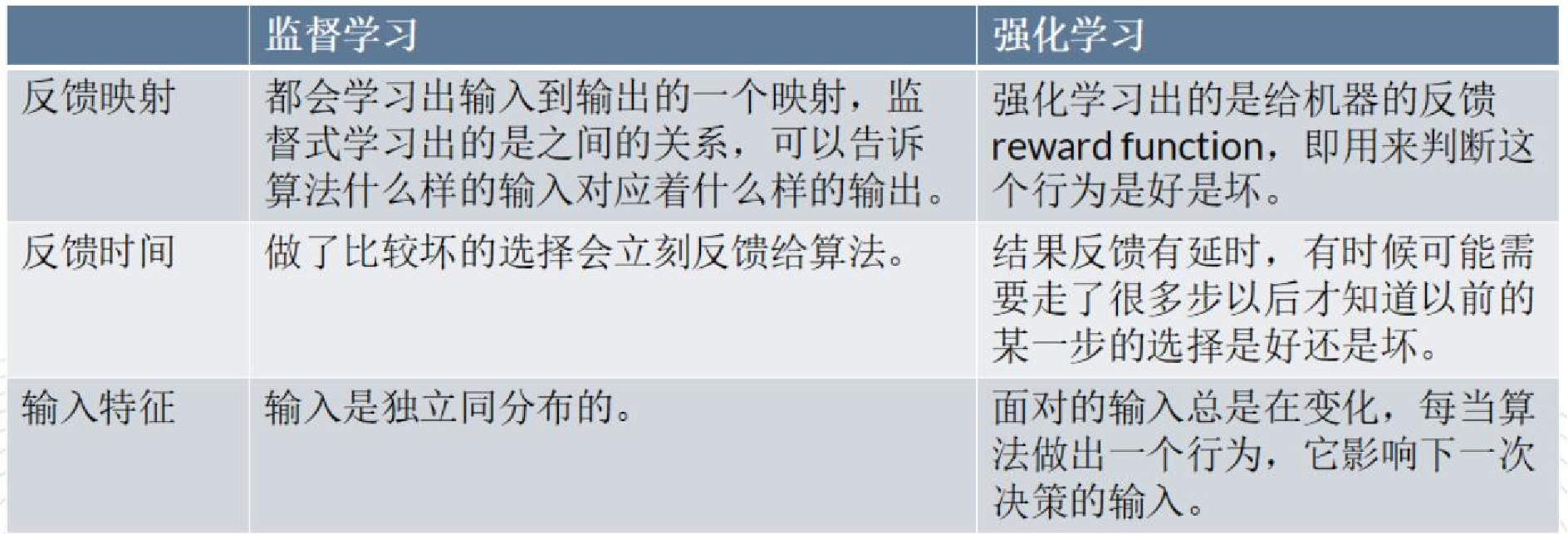
4.4强化学习
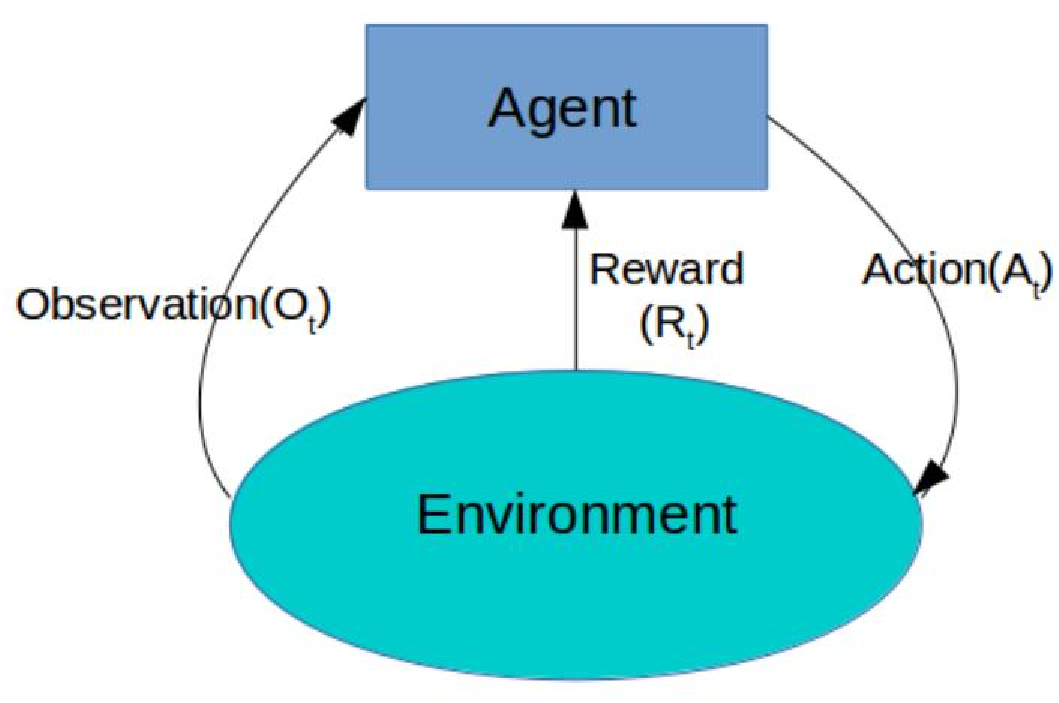
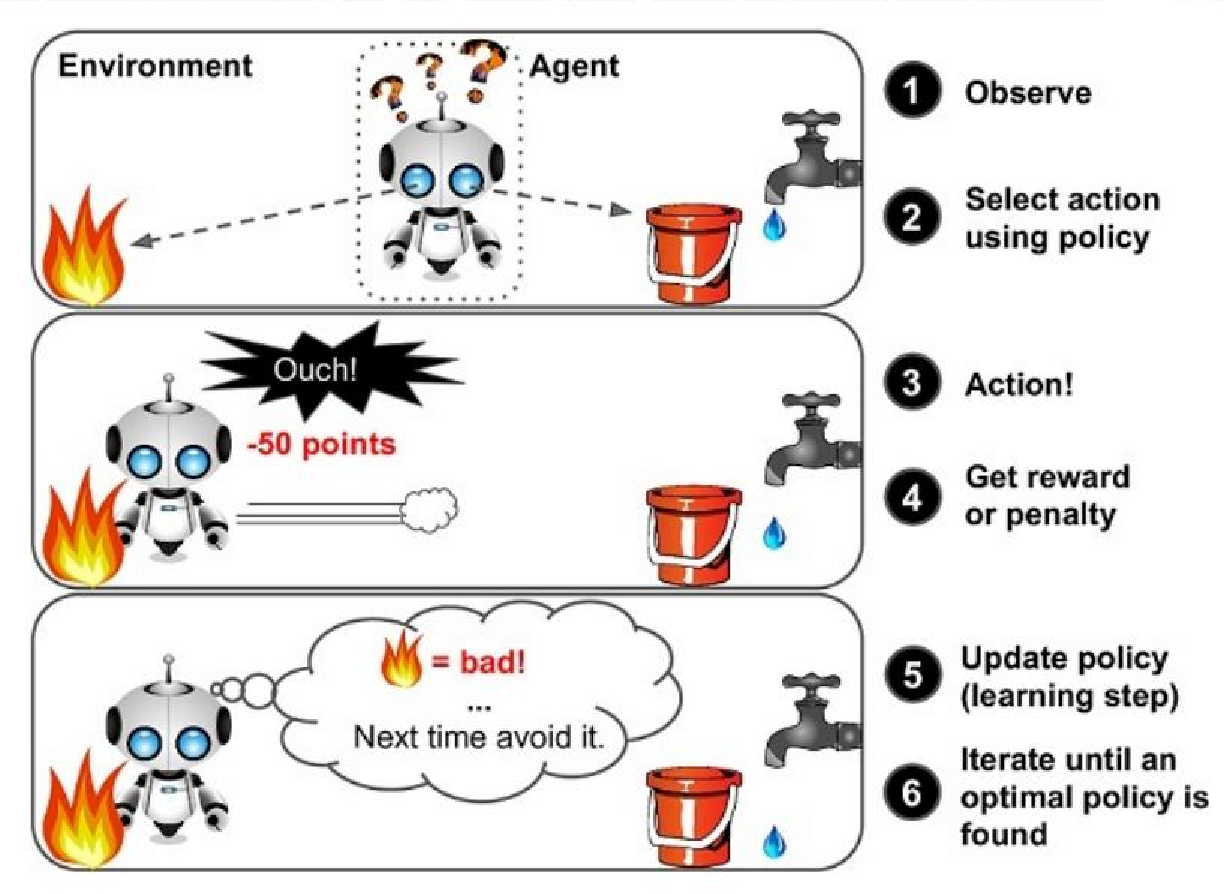
强化学习定义:实质是make decisions 问题,即自动进行决策,并且可以做连续决策希望一段时间后获得最多的累计奖励。 主要包含四个要素 :agent ,环境状态,行动,奖励;
强化学习案例1 : 小孩想要走路,但在这之前,他需要先站起来,站起来 之后还要保持平衡,接下来还要先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。 小孩就是 agent ,他试图通过采取行动 (即行走)来操 纵环境 (行走的表面),并且从一个状态转变到另一个 状态 (即他走的每一步),当他完成任务的子任务(即走了几步)时,孩子得到奖励 (给巧克力吃),并且当他不能走路时,就不会给巧克力。
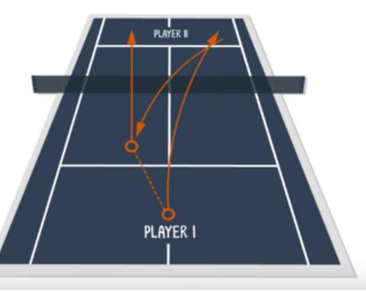
强化学习案例2 : 一个 autonomous agent 要学习如何打 tennis(网球)比赛,它需要考虑这些动作: serves, returns, and volleys ,这些行为会影响谁赢谁输。 执行每一个动作都是在一个激励下进行的,就是要赢得比赛。 为了实现比分最大化,它需要遵循一个策略。
强化学习案例3 : Manufacturing 一家日本公司 Fanuc(发那科) ,工厂机器人 在拿起一个物体时,会捕捉这个过程的视频,记住它每次操作的行动, 操作成功还是失败了,积累经验,下一次可以更快更准地采取行动。
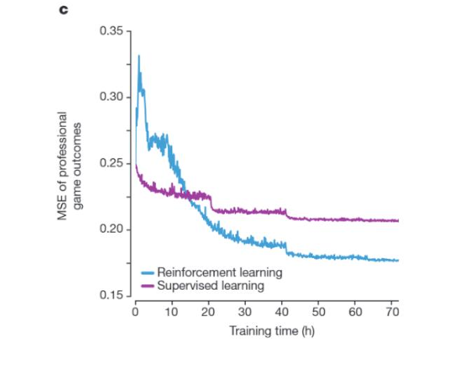
强化学习与监督学习的区别:
蓝色代表强化学习,紫红色代表监督学习,纵轴代表错误率的下降趋势
4.5 总结:

4.6 扩展
批量学习和在线学习
在线学习:需要接收持续的数据流 (例如股票价格)同时对数据流的 变化做出快速或自主的反应。
如果你的计算资源有限,在线学习 系统同样也是一个很好的选择:新的数据实例一旦经过系统的学习, 就不再需要,你可以将其丢弃(除 非你想要回滚到前一个状态,再“ 重新学习”数据),这可以节省大 量的空间。 挑战:学习率,不良数据。