小编注:上期详细讲了Airtest启动器的原理,以及在最后给出了2个实现方案。本次是第2个方案的另一个实现案例,供大家学习参考。
Python v3.7.0 / Airtest: 1.1.1 / PocoUI: 1.0.78
自定义的启动器主要实现了以下功能:
将一些公共参数和方法添加到全局变量中,在各业务脚本中无需声明,可直接使用,如语句超时时间 TIMEOUT,就在此进行统一设置;
设置Airtest全局属性值,对所有脚本生效,如下所示:
# 图像识别精确度阈值 [0,1]
ST.THRESHOLD = 0.80
# assert语句里图像识别时使用的高要求阈值 [0,1]
ST.THRESHOLD_STRICT = 0.85
# 每一步操作后等待多长时间再进行下一步操作
ST.OPDELAY = 1
# 图像查找超时时间,默认为20s
ST.FIND_TIMEOUT = 10
# 修改图像识别算法顺序,只要成功匹配任意一个符合设定阙值的结果,程序就会认为识别成功
ST.CVSTRATEGY = ["tpl", "sift", "brisk"]
在正式脚本运行前后,添加子脚本的运行,使得运行各个业务脚本时,初始页面都将为小程序首页,不需要再添加额外的环境判断代码;
setup.air:在每个脚本运行前,都会首先运行此脚本。此脚本会判断当前页面是否位于小程序首页,若不是,则会重启微信,进入小程序首页;
teardown.air:在每个脚本运行结束后,都会运行此脚本。此脚本会点击页面顶部的HOME图标,返回到小程序首页。若成功返回到小程序首页,则会尝试关闭首页遮罩广告(注意:遮罩广告样式不能改变),若未能成功返回首页,则会重启微信,再进入小程序首页。
通过配置config.csv中的内容,实现批量运行脚本;
在运行脚本时,会先迭代查找suite/目录下所有以.air结尾的目录,自动忽略setup.air和teardown.air,然后读取config.csv中所配置的 Label 为 "Y"的脚本名称,二者做交集运算,其结果作为本次实际要运行的脚本集合。
批量运行脚本结束后,支持生成聚合报告,与Jenkins进行持续集成时,此报告会作为附件进行发送。点击聚合报告中模块名称,会跳转到Airtest Project自带的测试报告页面。

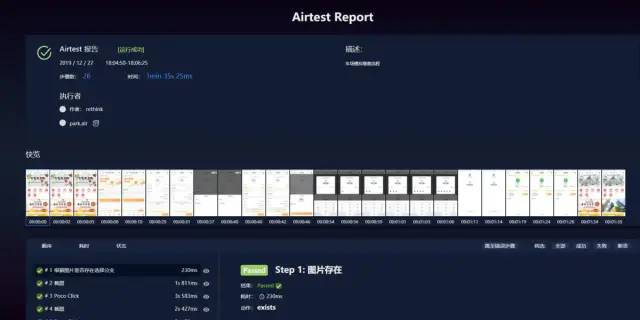
Airtest Project自带的测试报告中,引用了很多静态资源,如js/css文件、页面截图等,这里通过使用Nginx来搭建静态资源服务器,使测试报告可以正常加载。
兼容在AirtestIDE中使用自定义启动器
持续集成时,必然要通过命令行来运行业务脚本,需要手动传入一些参数如设备号,脚本名等,而使用AirtesIDE运行脚本时,这些参数会自动传入。源码中使用argparse的方法来解析命令行传入的参数,为了兼容在AirtestIDE中使用自定义的启动器,此处不能使用和源码相同的方法来解析命令行参数,否则AirtestIDE中会无法识别参数,而导致报错;
import sys
if len(sys.argv) == 1: # 如果没有传入任何命令行参数,则批量执行脚本
main()
quit()
else: # 在AirtestIDE中单个运行脚本时,会传入script、log、device等参数,则调用以下原始方法;
ap = runner_parser()
args = ap.parse_args()
run_script(args, McCustomAirtestCase)
直接贴项目原始代码,注释已经写得很详细了。
#!/usr/bin/env python
# -*- coding:utf8 -*-
"""
@File : mc_launcher.py
@Author: Rethink
@Date : 2019/12/20 10:49
@Desc :
"""
import csv
import datetime
import os
import shutil
import sys
import time
from argparse import *
from pathlib import Path
from typing import List
import airtest.report.report as report
import jinja2
from airtest.cli.parser import runner_parser
from airtest.cli.runner import run_script
from airtest.core.settings import Settings as ST
# 若脚本在IDE中运行,IDE会自动帮忙加载AirtestCase;若用命令行运行脚本,则需要导入 AirtestCase
if not globals().get("AirtestCase"):
from airtest.cli.runner import AirtestCase
AIRTEST_EXPORT_DIR = os.getenv('AIRTEST_EXPORT_DIR') # 测试报告相关资源打包后的导出路径,目录不存在会自动创建
AUTOLINE_HOST = os.getenv('AUTOLINE_HOST') # 静态资源文件服务器 格式:Scheme://IP:Port
if Path(AIRTEST_EXPORT_DIR).is_dir():
pass
else:
os.makedirs(AIRTEST_EXPORT_DIR)
class McCustomAirtestCase(AirtestCase):
"""
Aietest Project自定义启动器,参考文档:http://airtest.netease.com/docs/cn/7_settings/3_script_record_features.html
"""
PROJECT_ROOT = os.getenv("AIRTEST_PROJECT_ROOT", r"E:\treasure\Airtest\suite") # 设置子脚本存放的根目录
def setUp(self):
print("----------Custom Setup [Hook method]----------")
# 将自定义的公共变量加入到`self.scope`中,在脚本代码中就可以直接使用
self.scope["SLEEPTIME"] = 1 # 睡眠时间
self.scope["TIMEOUT"] = 5 # 超时时间
# 设置`Airtest`全局属性值
ST.THRESHOLD = 0.80 # 图像识别精确度阈值 [0,1]
ST.THRESHOLD_STRICT = 0.85 # assert语句里图像识别时使用的高要求阈值 [0,1]
ST.OPDELAY = 2 # 每一步操作后等待多长时间进行下一步操作, 只针对Airtest语句有效, 默认0.1s
ST.FIND_TIMEOUT = 10 # 图像查找超时时间,默认为20s
ST.CVSTRATEGY = ["tpl", "sift", "brisk"] # 修改图像识别算法顺序,只要成功匹配任意一个符合设定阙值的结果,程序就会认为识别成功
# 可以将一些通用的操作进行封装,然后在其他脚本中 import;
# Airtest 提供了 using 接口,能够将需要引用的脚本加入 sys.path 里,其中包含的图片文件也会被加入 Template 的搜索路径中
# using("common.air") # 相对于PROJECT_ROOT的路径
self.exec_other_script("setup.air")
super(McCustomAirtestCase, self).setUp()
def tearDown(self):
print("----------Custom Teardown [Hook method]----------")
self.exec_other_script("teardown.air")
super(McCustomAirtestCase, self).tearDown()
def find_all_scripts(suite_dir: str = "") -> list:
"""
遍历suite目录,取出所有的测试脚本
"""
suite = []
if not suite_dir:
suite_dir = McCustomAirtestCase.PROJECT_ROOT
for fpath in Path(suite_dir).iterdir():
tmp = Path(suite_dir, fpath)
if not tmp.is_dir():
pass
else:
if fpath.suffix == '.air' and fpath.stem not in ["setup", "teardown"]: # 这里会排除掉初始化脚本
suite.append(fpath.name)
else:
deep_scripts = find_all_scripts(tmp) # 递归遍历
suite += deep_scripts
return suite
def allow_run_scripts() -> List[str]:
"""
读取配置文件,返回允许运行的脚本名称
"""
config_allow_run = []
with open("config.csv", "r") as f:
f_csv = csv.DictReader(f)
for row in f_csv:
if row["Label"].upper() == "Y":
config_allow_run.append(row["Script"].strip())
return config_allow_run
def run_airtest(script, log_root, device=""):
"""
运行单个脚本,并生成测试报告,返回运行结果
:param script: *.air, 要运行的脚本
:param device: 设备字符串
:param log_root: 脚本日志存放目录
"""
if log_root.is_dir():
shutil.rmtree(log_root)
else:
os.makedirs(log_root)
print(str(log_root) + '>>> is created')
# 组装运行参数
args = Namespace(device=device, # 设备字符串
log=log_root, # log目录
recording=None, # 禁止录屏
script=script # *.air
)
run_script(args, McCustomAirtestCase)
def generate_report(script, *, log_root, export_root):
"""
生成测试报告
:param script: 运行名称
:param log_root: 脚本log目录
:return: export_root 测试报告输出目录
"""
# 测试报告导出目录
if not export_root.is_dir():
os.makedirs(export_root)
print(str(export_root) + '>>> is created')
output_file = Path(export_root, script.replace('.air', '.log'), 'log.html') # 测试报告`log.html`存放路径
# 生成测试报告
rpt = report.LogToHtml(script_root=script, # *.air
log_root=log_root, # log目录
export_dir=export_root, # 设置此参数后,生成的报告内资源引用均使用相对路径
lang='zh', # 设置语言, 默认"en"
script_name=script.replace(".air", ".py"), # *.air/*.py
static_root=AUTOLINE_HOST + '/static', # 设置此参数后,打包后的资源目录中不会包含样式资源
plugins=['poco.utils.airtest.report'] # 使报告支持poco语句
)
rpt.report(template_name="log_template.html", output_file=output_file)
# 提取脚本运行结果
result = rpt.test_result # True or False
return result
def summary_html(results: list, output_dir: str, template_dir: str, elapsed_time):
"""
生成自定义的聚合报告
:param results: 用例执行结果
:param output_dir: html输出目录
:param template_parent: jinja2模板所在目录
"""
env = jinja2.Environment(
loader=jinja2.FileSystemLoader(template_dir),
extensions=(),
autoescape=True,
)
template = env.get_template("summary_template.html", template_dir)
html = template.render({"results": results, # 运行结果
"now": datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), # 当前时间
"elapsed_time": elapsed_time, # 脚本运行时长
})
output_file = Path(output_dir, "summary.html") # 聚合报告路径
with open(output_file, 'w', encoding="utf-8") as f:
f.write(html)
def copy_lastest_report(source):
"""
复制最新生成的测试报告到 lastest/
"""
latest = Path(AIRTEST_EXPORT_DIR, 'latest')
if latest.is_dir():
shutil.rmtree(latest) # dst 目录必须不能存在,否则copytree报错
shutil.copytree(os.path.abspath(source),
os.path.abspath(latest)) # 目录内文件不能正在使用 否则无法复制成功PermissionError: [WinError 5] 拒绝访问
def print_message(*message):
print("*" * 50)
mes = " ".join(map(str, message))
print(mes)
print("*" * 50)
def clear_history_report(report_dir, critical_day):
"""
清除生成的历史测试报告
:param report_dir: 测试报告目录
:param critical_day:
"""
root = Path(report_dir)
reports = [report for report in root.iterdir() if report.is_dir() and report.name != 'latest']
for report in reports:
dt = datetime.datetime.strptime(report.name, '%Y%m%d%H%M%S')
delta = datetime.datetime.now() - dt
if delta.days > int(critical_day):
shutil.rmtree(os.path.abspath(report))
def main():
start_time = int(time.time())
all_scripts = find_all_scripts()
config_allow_run = allow_run_scripts()
suite: set = set(all_scripts).intersection(config_allow_run)
print_message("本次要运行的用例集合为:", suite)
results = [] # 脚本运行结果汇总
dt = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
export_root = Path(AIRTEST_EXPORT_DIR, dt) # 测试报告导出目录
for script in suite:
print_message("正在运行的用例名称:" + script)
log_root = Path(McCustomAirtestCase.PROJECT_ROOT, 'log', script.replace('.air', '.log')) # 脚本日志目录
run_airtest(script, log_root) # 运行脚本
result = generate_report(script, log_root=log_root, export_root=export_root) # 生成测试报告
results.append((script, result))
if not result:
print_message("用例执行失败: " + script)
else:
print_message("用例执行成功:" + script)
print_message("用例运行结果汇总:", results)
end_time = int(time.time())
elapsed_time = end_time - start_time
summary_html(results, output_dir=export_root, template_dir=McCustomAirtestCase.PROJECT_ROOT,
elapsed_time=elapsed_time)
copy_lastest_report(source=export_root)
clear_history_report(AIRTEST_EXPORT_DIR, 3)
if __name__ == '__main__':
"""
通过命令行来启动air脚本时,需要传入一些参数如设备号,脚本名等,而使用AirtesIDE运行脚本时,这些参数会自动传入;
源码中使用argparse的方法来解析命令行参数,此处不能使用和源码相同的方法,否则AirtestIDE中会无法识别参数,而导致报错;
具体源码,详见runner_parser、parse_args和run_script三个方法
"""
# parser = argparse.ArgumentParser()
# parser.add_argument("-b", "--Batch", type=str, help="是否启用批量运行脚本功能,为了支持在AirtestIDE中使用自定义的启动器,此项默认不启用")
# args = parser.parse_args()
#
# # 如果传入Batch参数且其值为true, 则表示开启批量运行脚本功能
# if args.Batch and args.Batch.lower() == "true":
# main()
# else:
# # AirtestIDE中运行脚本时, 会自动带入script, --device, --log, --recording参数;
# ap = runner_parser()
# args = ap.parse_args()
# run_script(args, McCustomAirtestCase)
if len(sys.argv) == 1: # 如果没有传入任何命令行参数,则批量执行脚本
main()
quit()
else: # 在AirtestIDE中运行脚本时,会传入script、log、device等参数,则调用以下方法;
ap = runner_parser()
args = ap.parse_args()
run_script(args, McCustomAirtestCase)
如果你不想一个人野蛮生长,找不到系统的资料,问题得不到帮助,坚持几天便放弃的感受的话,可以加入我们的QQ群:746506216,大家可以一起讨论交流,里面会有各种软件测试资料和技术交流。
资源分享
下方这份完整的软件测试视频学习教程已经上传CSDN官方认证的二维码,朋友们如果需要可以自行免费领取 【保证100%免费】