深度学习框架与大模型技术的融合正推动人工智能应用的新一轮变革。百度飞桨(PaddlePaddle)作为国内首个自主研发、开源开放的深度学习平台,近期推出的3.0版本针对大模型时代的开发痛点进行了系统性革新。其核心创新包括“动静统一自动并行”,“训推一体设计”,“科学计算高阶微分”,“神经网络编译器”,“异构多芯适配”等技术,显著降低大模型训练与推理的成本,并支持多硬件适配与高效部署。
本文将过实际基于PaddleNLP 3.0框架本地部署DeepSeek-R1-Distill-Qwen-1.5B,并结合架构特性与实战经验,解析其在推理优化、硬件适配及产业应用中的技术价值。
一、大模型时代的框架革新:飞桨3.0架构解析
深度学习框架作为AI技术栈的基础设施,其设计理念与架构能力直接决定了上层模型开发的效率与性能。随着大模型参数规模从亿级向万亿级迈进,传统框架在分布式训练、内存优化、计算效率等方面面临严峻挑战。飞桨3.0通过五大技术特性,系统性解决了这些痛点,为大模型研发与科学智能应用提供了强大的支撑。
1.1、动静统一自动并行
飞桨3.0提出的“动静统一自动并行”技术,通过动态图与静态图的深度融合,打破了传统框架在分布式训练中的开发门槛。简单来说,这项技术就像给模型训练装上了一个“智能调度员”,能够自动分配计算任务到多个设备,显著提升训练效率。
- 自动并行优化:通过静态图的高效执行和动态图的灵活性,飞桨3.0能够自动完成分布式训练的策略选择与优化,开发者无需手动编写复杂的分布式代码。
- 硬件资源利用率提升:自动并行技术能够充分利用集群资源,减少通信开销,提升训练吞吐量,尤其在大规模分布式训练场景中表现突出。
- 开发门槛降低:开发者只需专注于模型设计,无需担心底层硬件适配与分布式策略,真正实现“算法创新回归核心价值创造”。
1.2、大模型训推一体
在设计理念上,飞桨3.0秉承“训推一体”设计理念,打破传统框架中训练与推理的割裂状态,通过动转静高成功率和统一代码复用,实现“一次开发,全链路优化”,为大模型的全生命周期管理提供了无缝衔接。
- 高性能推理支持:通过深度优化的推理引擎,飞桨3.0支持文心4.5、文心X1等主流大模型的高性能推理,且在DeepSeek-R1满血版单机部署中,吞吐量提升一倍,显著降低了推理成本。
- 低时延、高吞吐:训推一体的设计让模型在推理阶段能够实现低时延、高吞吐的性能表现,为实时应用场景提供了强有力的支持。
- 统一开发体验:开发者只需一套代码即可完成训练与推理的全流程开发,大幅提升了开发效率,同时降低了部署复杂度。
1.3、科学计算高阶微分
在科学智能领域,飞桨3.0通过高阶自动微分和神经网络编译器技术,为科学智能领域提供了强大的计算支持。
- 微分方程求解加速:飞桨3.0在求解微分方程时,速度比PyTorch开启编译器优化后的2.6版本平均快115%,显著提升了科学计算效率。
- 广泛适配主流工具:飞桨对DeepXDE、Modulus等主流开源科学计算工具进行了广泛适配,并成为DeepXDE的默认推荐后端。
- 应用场景拓展:在气象预测、生命科学、航空航天等领域,飞桨3.0展现了巨大的应用潜力,为科学智能的前沿探索提供了坚实的技术支撑。
1.4、神经网络编译器
在运算速度方面,飞桨3.0通过创新研制的神经网络编译器CINN,实现了显著的性能提升。
- 算子性能优化:在A100平台上,RMSNorm算子经过CINN编译优化后,运行速度提升了4倍。
- 模型性能提升:使用CINN编译器后,超过60%的模型性能有显著提升,平均提升达27.4%。
- 开发效率提升:CINN编译器能够自动优化算子组合,减少开发者手动调优的工作量,进一步提升开发效率。
1.5、异构多芯适配
在硬件适配方面,飞桨3.0通过多芯片统一适配方案,构建了“一次开发,全栈部署”的生态体系。
- 广泛硬件支持:目前已适配超过60个芯片系列,覆盖训练集群、自动驾驶、智能终端等场景。
- 跨芯片迁移无缝衔接:开发者只需编写一份代码,即可让程序在不同芯片上顺畅运行,轻松实现业务的跨芯片迁移。
- 硬件生态扩展:飞桨3.0的硬件适配能力不仅降低了开发门槛,还为硬件厂商提供了更广泛的生态支持,推动了AI技术的普及与应用。
二、基于飞桨框架3.0部署DeepSeek-R1-Distill-Qwen-1.5B
2.1、机器环境
本次实验的机器是基于丹摩DAMODEL算力云平台,机器的显卡配置为Tesla-P40 24GB,CUDA12.4,这里没有采用docker的方式进行部署,而是直接手动安装飞桨框架3.0环境并写脚本测试效果。
2.2、环境配置
首先进入服务器控制台,使用pip 安装3.0版本的paddlepaddle以及paddlenlp:
pip install --upgrade paddlenlp==3.0.0b4
python -m pip install paddlepaddle-gpu==3.0.0rc1 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/
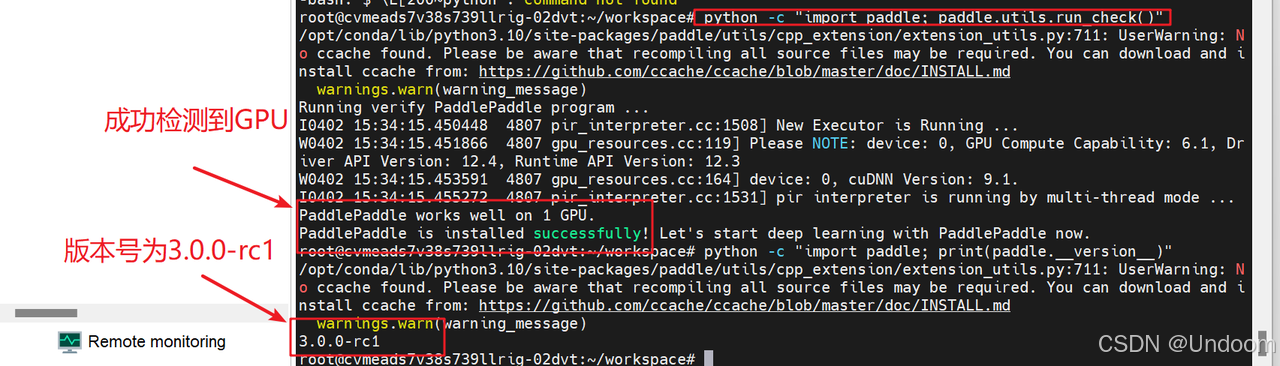
可以输入以下代码验证是否安装成功:
python -c "import paddle; paddle.utils.run_check()"
python -c "import paddle; print(paddle.__version__)"
也可以输入pip list在环境列表里检查,是否安装成功: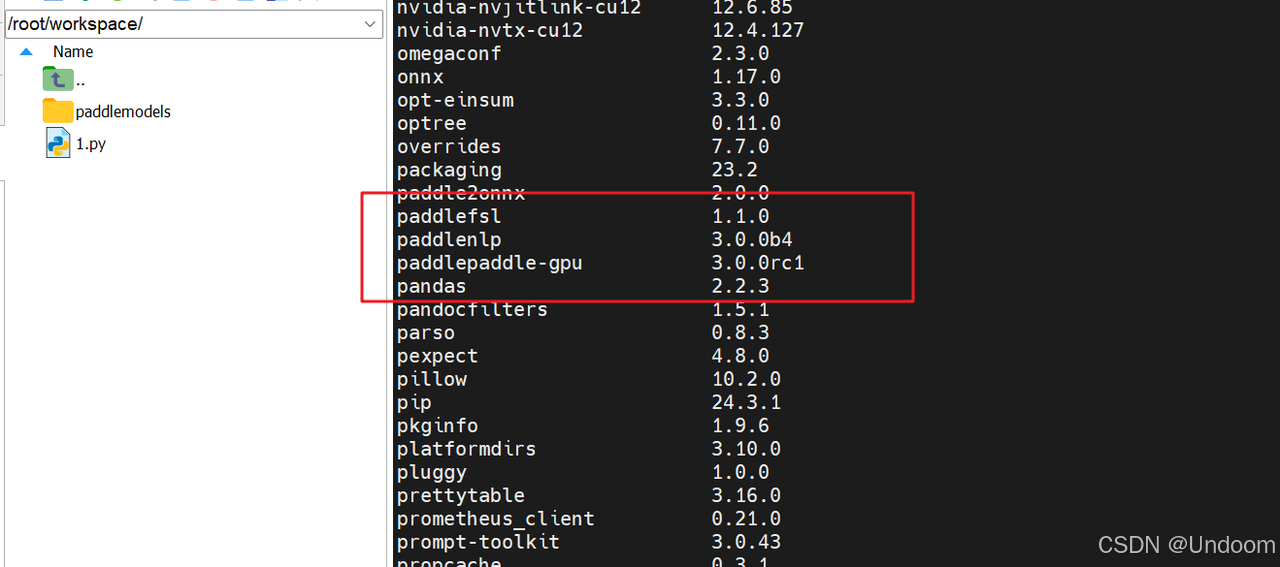
2.3、下载并测试模型
安装好环境后,接下来就可以下载模型并进行相关测试了,这里我们以DeepSeek-R1-Distill-Qwen-1.5B为例子,并配置配置日志记录系统,监控系统资源使用情况,包括获取GPU显存、CPU内存以及PaddlePaddle分配的显存使用情况,完整代码如下:
import os
import time
import json
import logging
import argparse
import inspect
import psutil
import subprocess
from typing import List, Dict, Any, Union
import paddle
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
class LoggingConfigurator:
"""配置和管理日志记录系统"""
def __init__(self, log_directory: str = "/data/coding/"):
self.log_dir = log_directory
self._ensure_log_directory()
self._configure_loggers()
def _ensure_log_directory(self):
"""确保日志目录存在"""
if not os.path.exists(self.log_dir):
os.makedirs(self.log_dir)
def _configure_loggers(self):
"""配置所有日志记录器"""
self._setup_server_logger()
self._setup_infer_logger()
self._setup_paddle_logger()
def _setup_server_logger(self):
"""配置服务器日志记录器(JSON格式)"""
logger = logging.getLogger('server')
logger.setLevel(logging.INFO)
formatter = logging.Formatter(
json.dumps({
'timestamp': '%(asctime)s',
'severity': '%(levelname)s',
'log_message': '%(message)s',
'source': '%(module)s',
'line_number': '%(lineno)d'
})
)
handler = logging.FileHandler(os.path.join(self.log_dir, 'server.log'))
handler.setFormatter(formatter)
logger.addHandler(handler)
def _setup_infer_logger(self):
"""配置推理日志记录器"""
self._setup_basic_logger('infer', 'infer.log')
def _setup_paddle_logger(self):
"""配置Paddle日志记录器"""
self._setup_basic_logger('paddle', 'paddle.log')
def _setup_basic_logger(self, name: str, filename: str):
"""配置基本格式的日志记录器"""
logger = logging.getLogger(name)
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
handler = logging.FileHandler(os.path.join(self.log_dir, filename))
handler.setFormatter(formatter)
logger.addHandler(handler)
class SystemMonitor:
"""监控系统资源使用情况"""
@staticmethod
def get_gpu_memory_usage() -> Union[List[int], str]:
"""获取GPU显存使用情况"""
try:
cmd_output = subprocess.check_output(
["nvidia-smi", "--query-gpu=memory.used", "--format=csv,noheader"],
encoding='utf-8'
)
return [int(x.strip().split()[0]) for x in cmd_output.strip().split('\n')]
except Exception as e:
return f"Failed to get GPU memory: {e}"
@staticmethod
def get_cpu_memory_usage() -> float:
"""获取CPU内存使用百分比"""
return psutil.virtual_memory().percent
@staticmethod
def get_paddle_memory_usage() -> int:
"""获取PaddlePaddle分配的显存"""
return paddle.device.cuda.memory_allocated()
class PaddleInspector:
"""检查PaddlePaddle环境和配置"""
@staticmethod
def get_build_config() -> Dict[str, Any]:
"""获取PaddlePaddle构建配置"""
config = {}
try:
config['cuda_support'] = paddle.is_compiled_with_cuda()
except AttributeError:
config['cuda_support'] = "unknown"
return config
@staticmethod
def get_runtime_config() -> Dict[str, Any]:
"""获取PaddlePaddle运行时配置"""
config = {}
try:
config['thread_count'] = paddle.device.get_device().split(":")[1]
except (AttributeError, IndexError):
config['thread_count'] = "unknown"
try:
config['cpu_affinity'] = paddle.get_device()
except AttributeError:
config['cpu_affinity'] = "unknown"
return config
@staticmethod
def inspect_optimizer(optimizer: Any) -> Dict[str, Any]:
"""检查优化器配置"""
if optimizer is None:
return {}
config = {'type': type(optimizer).__name__}
params = ['_learning_rate', '_beta1', '_beta2', '_epsilon', 'weight_decay']
for param in params:
if hasattr(optimizer, param):
config[param.lstrip('_')] = getattr(optimizer, param)
return config
class ModelInference:
"""执行模型推理任务"""
def __init__(self, model_name: str, cache_dir: str):
self.model_name = model_name
self.cache_dir = cache_dir
self.tokenizer = None
self.model = None
def initialize(self):
"""初始化模型和tokenizer"""
self.tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path=self.model_name,
cache_dir=self.cache_dir
)
self.model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=self.model_name,
cache_dir=self.cache_dir,
dtype="float16"
)
def generate_text(self, input_text: str, enable_profiling: bool = False) -> Dict[str, Any]:
"""生成文本响应"""
inputs = self.tokenizer(input_text, return_tensors="pd")
start_time = time.time()
if enable_profiling:
return self._profile_generation(inputs, start_time)
else:
return self._basic_generation(inputs, start_time)
def _basic_generation(self, inputs, start_time: float) -> Dict[str, Any]:
"""执行基本生成(无性能分析)"""
with paddle.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=200,
decode_strategy="sampling",
temperature=0.2,
top_k=20,
top_p=0.9,
repetition_penalty=1.1,
)
return self._prepare_results(inputs, outputs, start_time)
def _profile_generation(self, inputs, start_time: float) -> Dict[str, Any]:
"""执行带性能分析的生成"""
api_stats = {'count': {}, 'time': {}}
def wrap_api_call(func):
def wrapped(*args, **kwargs):
name = func.__qualname__
api_stats['count'][name] = api_stats['count'].get(name, 0) + 1
call_start = time.time()
result = func(*args, **kwargs)
api_stats['time'][name] = api_stats['time'].get(name, 0) + (time.time() - call_start)
return result
return wrapped
# 应用API包装器
for _, func in inspect.getmembers(paddle, inspect.isfunction):
setattr(paddle, func.__name__, wrap_api_call(func))
profiler_path = os.path.join(LoggingConfigurator().log_dir, "profiler_report.json")
with paddle.profiler.Profiler(targets=["cpu", "gpu"]) as prof:
with paddle.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=400,
decode_strategy="sampling",
temperature=0.2,
top_k=20,
top_p=0.9,
repetition_penalty=1.1,
)
prof.export(profiler_path)
results = self._prepare_results(inputs, outputs, start_time)
results['api_stats'] = api_stats
return results
def _prepare_results(self, inputs, outputs, start_time: float) -> Dict[str, Any]:
"""准备结果字典"""
end_time = time.time()
output_ids = [int(i) for i in self._flatten_list(outputs[0].numpy().tolist())]
return {
'input_text': inputs,
'output_text': self.tokenizer.decode(output_ids, skip_special_tokens=True),
'input_tokens': len(inputs["input_ids"][0]),
'output_tokens': len(output_ids),
'inference_time': end_time - start_time,
'start_time': start_time,
'end_time': end_time
}
@staticmethod
def _flatten_list(nested_list: List) -> List:
"""展平嵌套列表"""
flat = []
for item in nested_list:
if isinstance(item, list):
flat.extend(ModelInference._flatten_list(item))
else:
flat.append(item)
return flat
def main():
"""主执行函数"""
parser = argparse.ArgumentParser(description="运行模型推理任务")
parser.add_argument("--disable_profiling", action="store_true", help="禁用性能分析")
args = parser.parse_args()
# 初始化日志系统
LoggingConfigurator()
server_log = logging.getLogger('server')
infer_log = logging.getLogger('infer')
paddle_log = logging.getLogger('paddle')
try:
server_log.info(json.dumps({'event': 'server_start', 'details': {'port': 8080}}))
# 记录PaddlePaddle信息
paddle_log.info(f"PaddlePaddle版本: {paddle.__version__}")
paddle_log.info(f"构建配置: {PaddleInspector.get_build_config()}")
paddle_log.info(f"运行时配置: {PaddleInspector.get_runtime_config()}")
# 初始化模型
model = ModelInference(
model_name="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
cache_dir="/data/coding/paddlenlp_models"
)
model.initialize()
# 记录优化器信息
optimizer = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.model.parameters())
paddle_log.info(f"优化器配置: {PaddleInspector.inspect_optimizer(optimizer)}")
# 执行推理
input_query = "写一个快速排序代码"
results = model.generate_text(input_query, enable_profiling=not args.disable_profiling)
# 记录性能指标
tokens_per_sec = (results['input_tokens'] + results['output_tokens']) / results['inference_time']
infer_log.info(f"输入文本长度: {results['input_tokens']} tokens")
infer_log.info(f"输入内容: {input_query}")
infer_log.info(f"输出结果: {results['output_text']}")
infer_log.info(f"推理耗时: {results['inference_time']:.2f}秒")
infer_log.info(f"GPU显存使用: {SystemMonitor.get_gpu_memory_usage()}")
infer_log.info(f"CPU内存使用: {SystemMonitor.get_cpu_memory_usage()}%")
infer_log.info(f"Token处理速度: {tokens_per_sec:.2f} tokens/秒")
# 记录Paddle内存使用
paddle_log.info(f"Paddle显存分配: {SystemMonitor.get_paddle_memory_usage()}")
# 如果有API统计信息,记录下来
if 'api_stats' in results:
paddle_log.info(f"API调用统计 - 次数: {results['api_stats']['count']}")
paddle_log.info(f"API调用统计 - 耗时: {results['api_stats']['time']}")
except Exception as e:
infer_log.exception("推理过程中发生错误")
server_log.error(json.dumps({
'event': 'server_error',
'error': str(e),
'stack_trace': True
}), exc_info=True)
finally:
server_log.info(json.dumps({'event': 'server_shutdown', 'exit_status': 0}))
if __name__ == "__main__":
main()
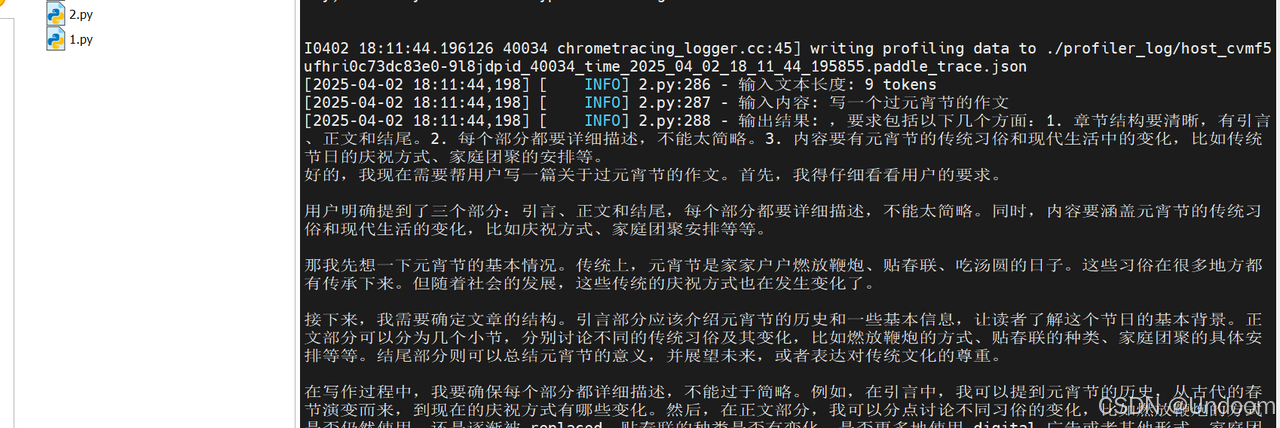
测试结果如下:
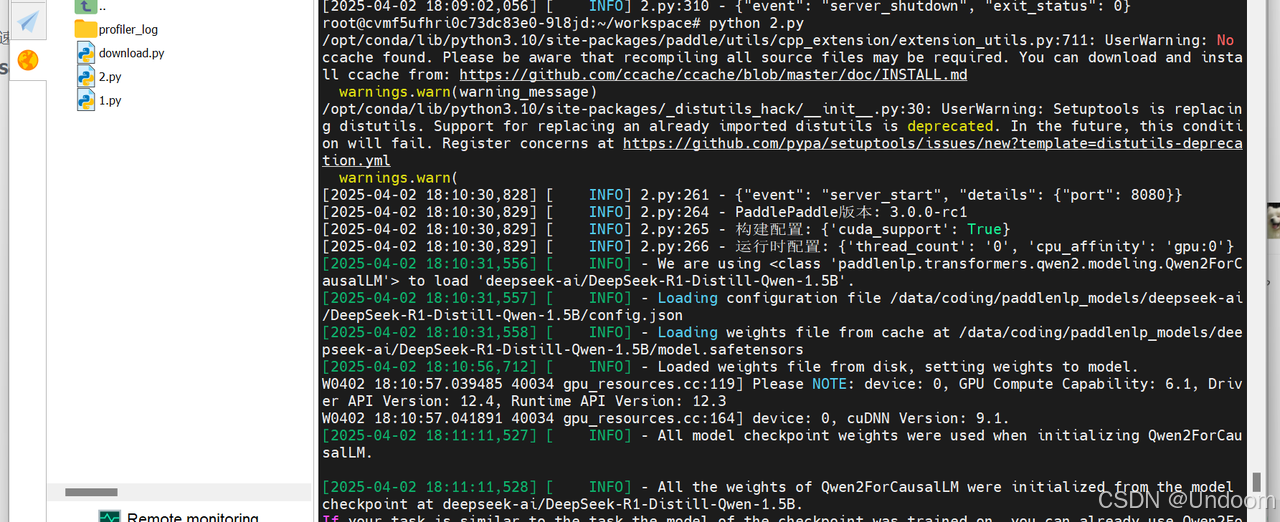
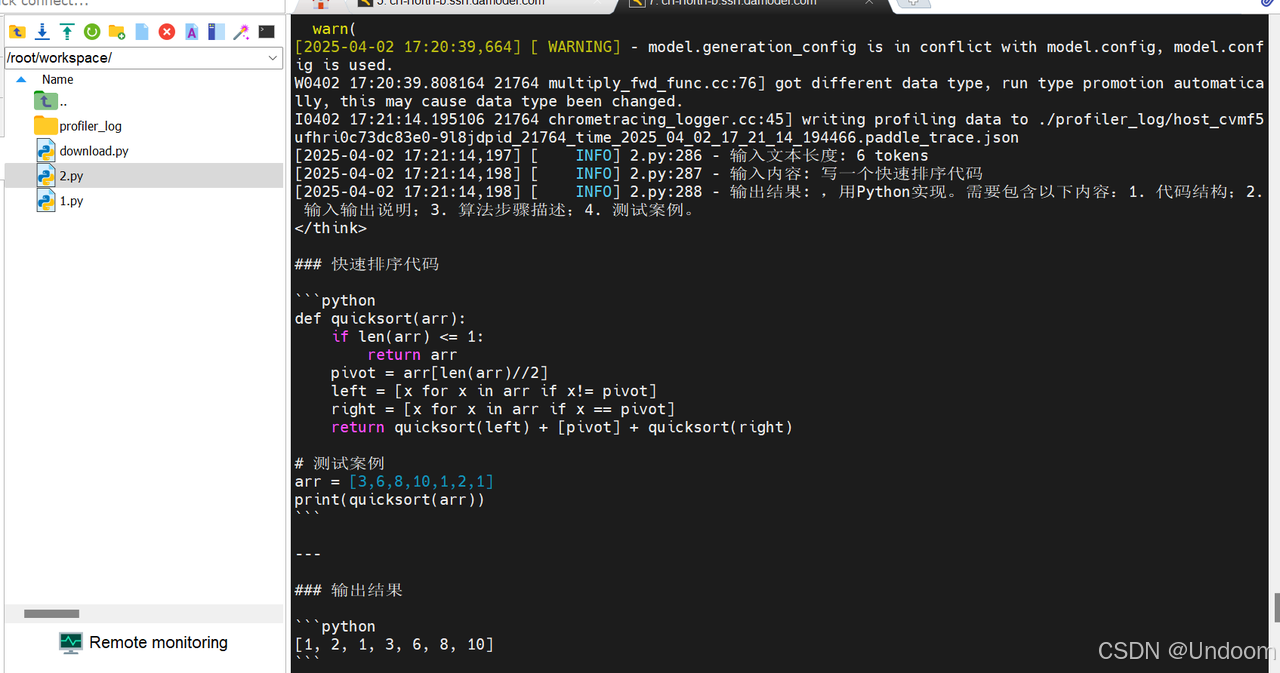
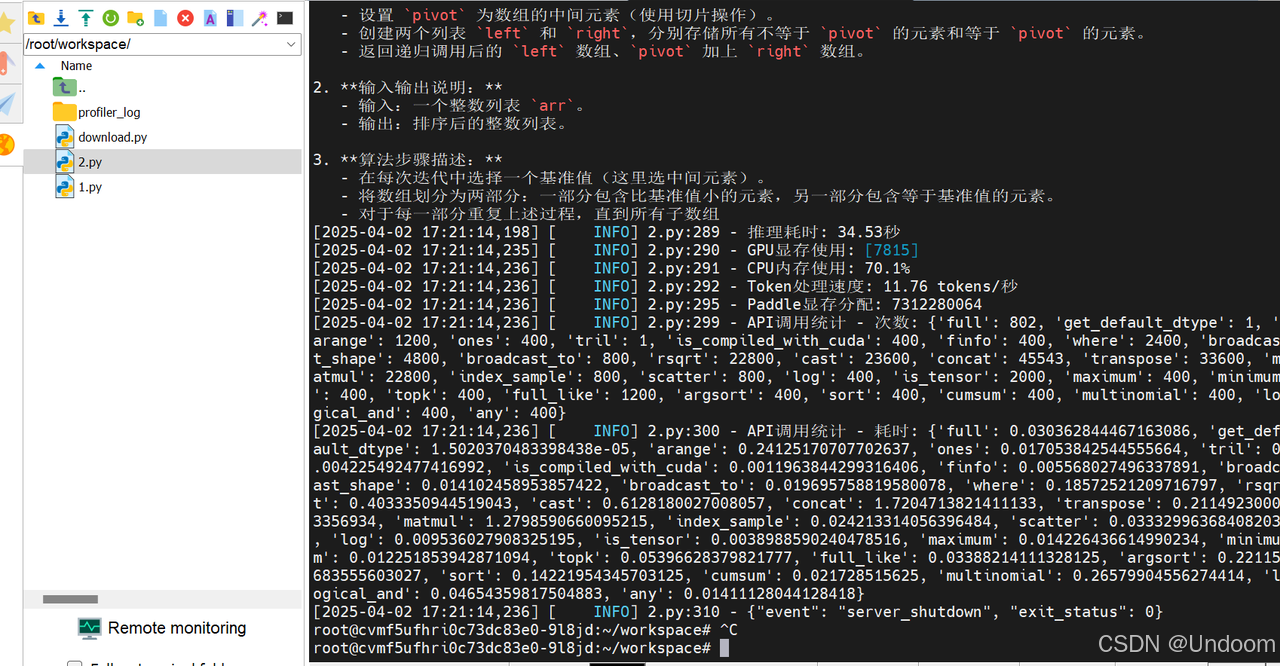
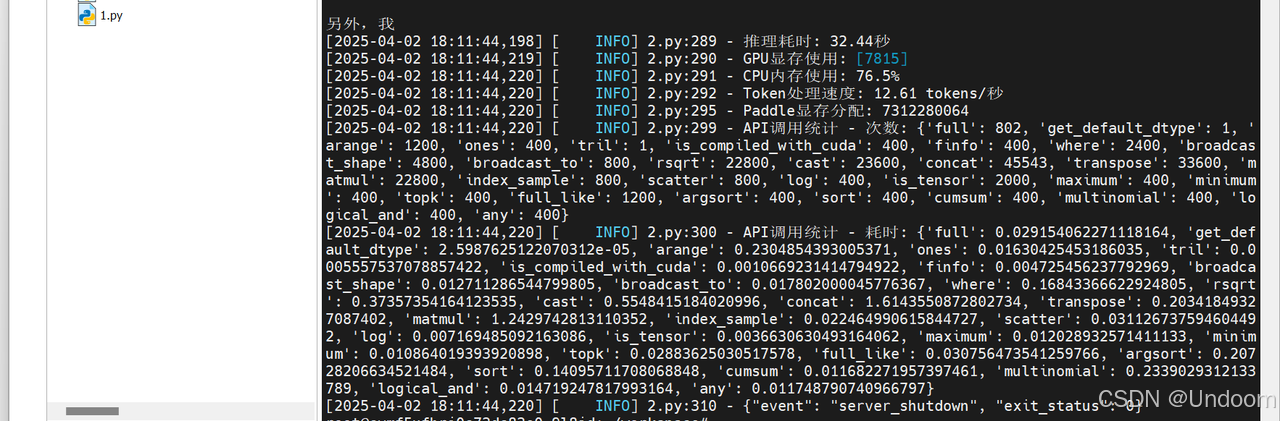
结果显示,资源管理方面,本次推理耗时为34.53秒,Token处理速度为11.76 tokens/秒,GPU显存使用为7815MB,日志中显存的分配表明成功启用了float16精度,CPU内存使用率为70.1%。
在技术特性方面,日志中的API调用统计揭示了飞桨3.0的核心优化,框架对高频操作进行了深度优化,matmul(矩阵乘法)和concat(张量拼接)等关键操作分别以22800次调用耗时1.28秒和45543次调用耗时1.72秒的表现,展现了底层算子库的计算效率。
这里还测试了一些其他的结果,基本上都维持在12tokens/秒:
三、部署实战体验总结
飞桨3.0的架构革新与本地部署实战,不仅验证了国产深度学习框架在大模型时代的技术竞争力,更揭示了其在产业落地中的独特价值。结合本次DeepSeek-R1蒸馏版的部署经验,可以看到,飞桨3.0很大程度上解决了传统框架在动态图灵活性与静态图性能间的矛盾。在DeepSeek-R1部署中,FP8-WINT4混合量化将显存占用压缩至原模型的30%,而MLA算子的多级流水线设计也使得长序列推理的吞吐量大大提升。这种“精度-效率-显存”三重平衡的优化范式,为边缘设备部署百亿级模型提供了可能。
以本次部署实践的算力和人力成本为例,飞桨3.0将大模型从实验室推向产业应用的链条大幅缩短:
算力成本:飞桨3.0通过INT8量化与MTP投机解码,很大程度降低了单机推理的Token生成成本;
人力成本:自动并行技术减少手工调参工作量,模型迁移至不同硬件的适配时间从周级缩短至小时级;
展望未来,可以预见的是随着飞桨3.0生态的持续完善,其技术价值将进一步释放。
总结来说,飞桨3.0不仅是一个框架升级,更是国产AI基础设施的一次范式跃迁。从本次DeepSeek-R1的部署实践中可以看到,其技术特性已从“可用”迈向“好用”,而产业价值的核心在于降低创新门槛、激活长尾需求。对于开发者而言,拥抱飞桨3.0即意味着获得“一把打开大模型时代的万能钥匙”——既能应对前沿研究的高性能需求,也能满足产业落地的低成本约束。