作者: 井轶
为什么要进行可观测性建设
可观测性并不是一个新词,该词来源于控制理论,是指系统可以由其外部输出推断其其内部状态的程度,随着 IT 行业几十年的发展,IT 系统的监控,告警,问题排查等领域的逐渐成熟,IT 行业也将其抽象形成了一整套可观测性工程体系。而之所以该词在这几年愈发火热,很大程度是因为云原生,微服务模式,DevOps 等技术的不断流行,对可观测性提出了更大的挑战。
云原生架构所倡导的微服务、DevOps 模式,同时带来了效率、可用性的提升, 但同时也极大程度增加了系统的复杂度, 也因此增强可观测性成了降低复杂度的唯一手段。
这里需要特别注意的是可观测性并不是监控,传统监控仅仅能够做到问题被动发现,可观测性的核心是基于对事先未定义的属性和模式的探索, 其不仅仅单纯是发现问题,更着重于对系统在运行时提供对其理解、探查以及调度的能力。
可观测性的基石指标、日志、事件、链路数据能够帮助我们更好的理解运行的系统,为事前预防、事中处理、事后复盘提供了重要决策依据, 同时可观测性体系也能够加速应用的持续交付,这就是为什么我们需要进行可观测性建设的原因。
如何针对网关场景进行可观察性建设
确定可观测性体系建设的目标
在没有监控或是监控混乱的状态下,开发者衡量系统的运行状态,都是靠一些不成体系的零散指标,盲人摸象,看不到全局。发生问题时,多是靠一些元老级开发者通过自己经验,从多个指标里模糊构建出业务全局状态,这个经验往往是不可复用的。
因此我们需要是通过技术手段建立系统的可观测性,可以清晰地“看见”系统运行的全面详细状态,降低经验门槛和不确定性,做出及时有效的决策。可观测性解决方案应当实现如下目标:
- 通过可观测性体系能够决定是否实施服务降级或者服务中断
- 当服务不可用、服务降级、失败时,能够快速发现。
- 在服务不可用,失败时,能够帮助调试。
- 确定容量规划和业务目标的长期趋势。
- 揭示更改或添加的功能的意外副作用。
构建网关通用可观测性指标
可观测性体系构建的目标是清晰的,但是仅仅只是使用了某些工具,加了某些监控并不足以实现目标,基于不同的业务场景需要有的放矢,不同经验的工程师可能会用不同类型的监控体系, 但核心是可观测性体系使用的监控体系能够正确反应系统的真实情况。
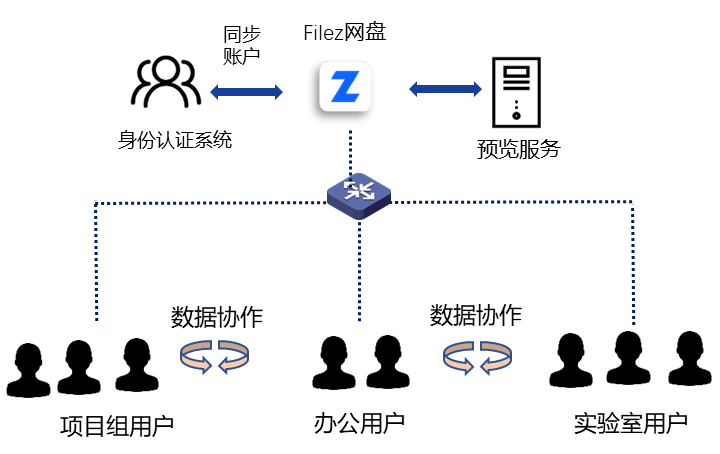
在网关可观测性体系的构建中,将主要的监控分为黑盒监控与白盒监控
-
黑盒监控: 一种基于采样的方法。黑盒系统将监控负责用户请求的同一系统。最常用的是使用拨测模拟用户正常请求来访问业务。
-
白盒监控: 监控和可观测性依赖于从处于监控的工作负载发送到监控系统中的信号。这通常可以采用三个最常见组件的形式:指标、日志和 trace

白盒监控中,指标的选择是件相对主观的事情,选择的指标能否准确体现系统的真实情况严重影响到整体可观测性体系目标的实现。
这里我们不妨回到网关最基础的功能,正是由于网关的代理功能,网关会天然沉淀通用逻辑如鉴权等,但本质仍然是对流量进行转发。

在这里我们将请求发起方称为网关的下游,请求转发的目的服务成为称为上游, 下游请求者是最能感知整体系统情况的,因此我们将网关服务类型指标的下游的成功率,请求量,RT 作为衡量整个网关的核心指标。
当然,这三个指标在多数系统中都是核心指标。在确定核心指标后,我们需要确定系统的路径指标, 即核心指标发生变化的时候,我们通过查看路径指标,能够快速定位问题的原因所,比如 CPU 占用百分比不断飙高时网关的耗时会同比增加,因此我们将系统指标(CPU, 内存,网络流量,连接数),服务指标中的上下游依赖(例如后端服务的端点变化情况)作为网关的二级指标。
通过上面的指标我们就基本确定了网关的可观测性指标,但是网关本身只是业务系统的一环,业务完整的可观测性需要结合业务场景去进行构建,例如使用网关日志记录业务侧状态码构建业务指标。

基于云原生网关的可观测性建设最佳实践
云原生网关是阿里云微服务引擎(MSE)下的一款托管类型网关产品,其将传统的流量网关与微服务网关进行了整合,作为云上产品他无缝支持来云上的可观测性产品 ARMS、SLS,力争对客户零门槛,同时立足开源,网关也兼容了 zipkin, skywalking, prometheus 等可观测开源产品。下面基于前文所讲述的可观测体系构建的思路,基于云上产品来构建可观测性体系,并以实际场景说明网关场景的可观测性使用。
灰度发布场景中的可观测性
我们以服务新版本发布的场景作为云原生网关可观测性的具体例子 。

在上图的发布过程中,最前端的流量会在服务 v1 和 v2 之间进行切换,在这个场景中,我们的核心是可观测性能够及时保证应用发布过程中应用发布导致的异常能够及时被观测到。
在新应用部署前,我们应当首先将网关默认提供的可观测性能力开启, 首先开启网关的基础指标监控(cpu, 内存, 整体成功率), 并针对该场景在告警配置中开启服务级别监控,以便在 httpbin 服务的成功率下降时能够及时发现。

在开始之前我们已经部署了 httpbin v1 版本。
之后我们开始正式在阿里云 ACK 集群中部署 httpbin v2 版本的应用,该集群之前已经部署过 httpbin v1 的应用。

并在网关的服务详情中,为 go-httpbin 服务增加 v2 的子版本。

并通过修改路由配置将 go-httpbin 服务 v2 的流量切为 10%,此时使用 http 请求调用网关,可以查看到网关流量在版本之间的分布。



云原生网关路由界面内置的监控能够有效帮助我们观测新版本与旧版本的运行状态,告警也能够在新服务发布有问题时及时发现异常。
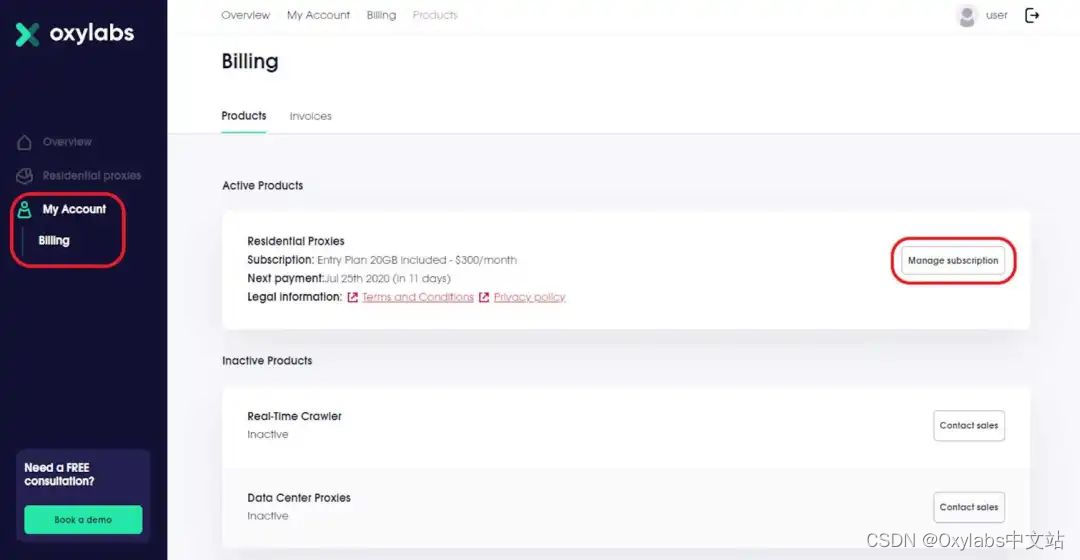
使用 ARMS 拨测来检验真实环境下的业务
在真实的环境中,网关自身的运行指标并不能完全确认整个业务的运行状态,DNS 劫持,网络故障等问题很有可能造成部分用户的完全无法使用,在这种情况下我们需要完全模拟用户使用黑盒指标来验证系统的稳定性,在这里我们使用 ARMS 提供的云拨测产品用来观测业务的真实情况。
在阿里云创建定时拨测任务, 通过设置不同的观测点来观测不同地域的用户访问业务的真实情况。

间隔一段时间后,我们就可以得到拨测的结果详情。

结合网关的可观测性体系构造业务的可观测性体系
由于不同业务区别的区别,网关只能提供了网关自身的可观测能力,但通过网关提供的拓展能力,我们可以将网关的可观测能力与业务的结合起来,用来构建业务自身的可观测性体系。
例如一个书城服务,我们在网关层去监控不同用户的访问呢?这里我们可以利用结构化日志和 SLS 提供的日志消费来实现。网关可以通过自定义请求头将必要的信息提取出来,并投递到日志服务。

在实际应用中,我们最常见的就是将在请求 header 中的用户 id 提取到日志中,从而实现 userId 和网关请求的关联,在开启自定义日志个时候,我们可以对投递的日志使用日志服务的数据加工对原始日志进行提取。

通过该方式我们不仅能够将有意义的业务信息与网关进行关联,同时可以将不必要的访问信息进行丢弃,从而减少成本
总结与展望
本文主要介绍了基于云原生网关构造可观测性能力的最佳实践,并通过介绍的三种实践覆盖了白盒观测,黑盒观测,基于网关构造业务可观测性等方面,针对可观测,虽然目前用户可以基于目前的可观测体系来快速发现,定位问题, 但我们目前能做的还有很多。

配合业界的发展方向,接下来云原生网关在可观测领域主要有如下规划:
- 就可观测性的三大数据支柱来说,为了解决部署上的跨平台方案冗杂以及数据不互通问题,Metrics、Logs、Traces 大一统的可观测性采集框架发展是大势所趋,支持 opentelemetry 等统一的可观测性框架是接下来的首要工作
- 在根因分析方面我们也在关注行业最先进算法的动态,持续的探索进行智能根因分析的实践。
MSE 云原生网关预付费、MSE 注册配置预付费首购 8 折,首购 1 年及以上 7 折。点击此处,即享优惠!




![[附源码]java毕业设计小型银行贷款管理系统](https://img-blog.csdnimg.cn/ad3e83b6a3d947baa7440e846055785b.png)