写在前面:
1. 本文中提到的“股票策略校验工具”的具体使用操作请查看该博文;
2. 文中知识内容来自书籍《同花顺炒股软件从入门到精通》
3. 本系列文章是用来学习技法,文中所得内容都仅仅只是作为演示功能使用
目录
解说
策略代码
结果
解说
布林线(BOLL)是金融市场常用的技术指标之一,属于价格路径指标。它利用统计原理,求出股价的标准差及其信赖区间,从而确定股价的波动范围及未来走势,利用波带显示股价的风险、安全的高低价位,因此也称之为布林带。
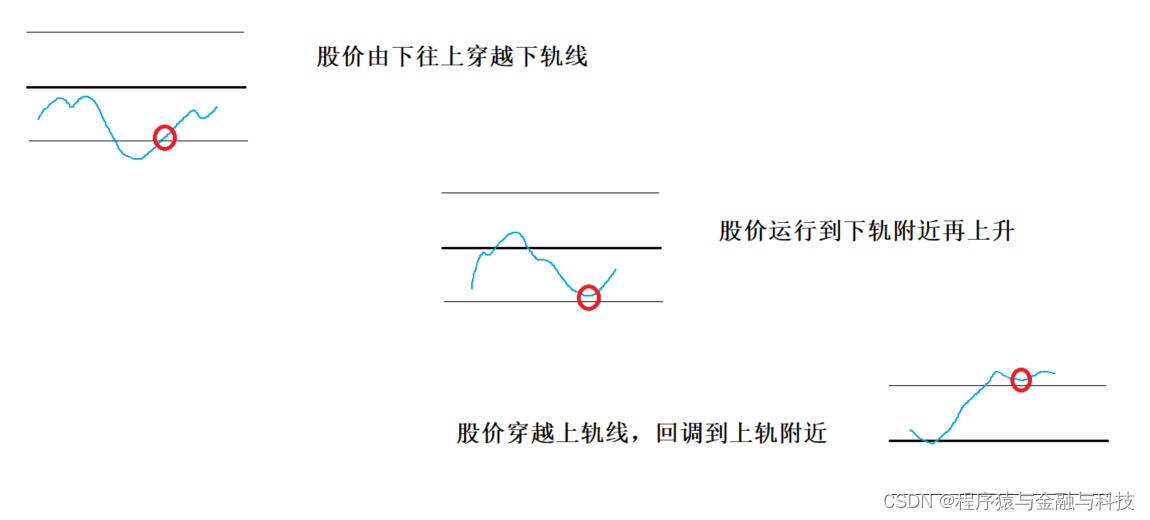
运用布林线指标选择买点的依据如下:
1)当股价穿越最外面的支撑线时,表示买点出现。
2)当股价沿着压力线(支撑线)上升,虽然股价并未穿越,但若回头突破支撑线(压力线)即是买点。
3)股价由下向上穿越下轨线(LOWER)时,可视为买进信号。
4)股价突破上轨,回探时仍在上轨线附近,表示后市上涨的机会增大,是加仓买进的信号。
5)波带如果开始收紧,表示股价将会发生变化,此时可结合多个技术参数进行分析,做出正确的判断。
策略代码
书籍中提交的买入点与网上查询到的有些出入,本文只考虑以下三种情况:
def excute_strategy(base_data,data_dir):
'''
指标买点分析技法 - 运用boll布林线指标选择买点
解析:
选择买点依据:
1. 当股价穿越最外面的支撑线时,表示买点出现
2. 当股价沿着压力线(支撑线)上升,虽然股价并未穿越,但若回头突破支撑线(压力线)即是买点。
3. 股价由下向上穿越下轨线(LOWER)时,可视为买进信号
4. 股价突破上轨,回探时仍在上轨线附近,表示后市上涨的机会增大,是加仓买进的信号。
5. 波带如果开始收紧,表示股价将会发生变化,此时可结合多个技术参数进行分析,做出正确的判断
PS: UPER 压力线;LOWER支撑线
自定义:
1. 靠近、附近 =》 数值差额小于0.5%
2. 买入时点 =》 走势确定后下一交易日
3. 胜 =》 买入后第三个交易日收盘价上升,为胜
只计算最近两年的数据
:param base_data:股票代码与股票简称 键值对
:param data_dir:股票日数据文件所在目录
:return:
'''
import pandas as pd
import numpy as np
import talib,os
from datetime import datetime
from dateutil.relativedelta import relativedelta
from tools import stock_factor_caculate
def res_pre_two_year_first_day():
pre_year_day = (datetime.now() - relativedelta(years=2)).strftime('%Y-%m-%d')
return pre_year_day
caculate_start_date_str = res_pre_two_year_first_day()
dailydata_file_list = os.listdir(data_dir)
total_count = 0
total_win = 0
check_count = 0
list_list = []
detail_map = {}
factor_list = ['BOLL']
ma_list = []
for item in dailydata_file_list:
item_arr = item.split('.')
ticker = item_arr[0]
secName = base_data[ticker]
file_path = data_dir + item
df = pd.read_csv(file_path,encoding='utf-8')
# 删除停牌的数据
df = df.loc[df['openPrice'] > 0].copy()
df['o_date'] = df['tradeDate']
df['o_date'] = pd.to_datetime(df['o_date'])
df = df.loc[df['o_date'] >= caculate_start_date_str].copy()
# 保存未复权收盘价数据
df['close'] = df['closePrice']
# 计算前复权数据
df['openPrice'] = df['openPrice'] * df['accumAdjFactor']
df['closePrice'] = df['closePrice'] * df['accumAdjFactor']
df['highestPrice'] = df['highestPrice'] * df['accumAdjFactor']
df['lowestPrice'] = df['lowestPrice'] * df['accumAdjFactor']
if len(df)<=0:
continue
# 开始计算
for item in factor_list:
df = stock_factor_caculate.caculate_factor(df,item)
for item in ma_list:
df = stock_factor_caculate.caculate_factor(df,item)
df.reset_index(inplace=True)
df['i_row'] = [i for i in range(len(df))]
df['three_chg'] = round(((df['close'].shift(-3) - df['close']) / df['close']) * 100, 4)
df['three_after_close'] = df['close'].shift(-3)
# upper mid lower
# 股价上穿上轨的点
df['up_close_up'] = 0
df.loc[(df['closePrice'].shift(1)<df['upper'].shift(1)) & (df['closePrice']>=df['upper']),'up_close_up'] = 1
df['up_close_down'] = 0
df.loc[(df['closePrice'].shift(1)>df['upper'].shift(1)) & (df['closePrice']<=df['upper']),'up_close_down'] = 1
up_point_rows_list = df.loc[(df['up_close_up']==1) | (df['up_close_down']==1)]['i_row'].values.tolist()
df['distance_upper'] = df['closePrice']-df['upper']
df['near_upper'] = 0
df.loc[(df['distance_upper']>0) & (df['distance_upper']/df['upper']<=0.005),'near_upper'] = 1
df['ext_0'] = df['near_upper'] - df['near_upper'].shift(1)
df['ext_1'] = df['near_upper'] - df['near_upper'].shift(-1)
start_i_row_list = df.loc[df['ext_0']==1]['i_row'].values.tolist()
end_i_row_list = df.loc[df['ext_1']==1]['i_row'].values.tolist()
nearest_upper_list = []
if start_i_row_list and end_i_row_list:
if start_i_row_list[0]>end_i_row_list[0]:
end_i_row_list = end_i_row_list[1:]
if start_i_row_list[-1]>end_i_row_list[-1]:
start_i_row_list = start_i_row_list[:-1]
near_upper_list = []
for i,item in enumerate(start_i_row_list):
start_node = item
end_node = end_i_row_list[i]
enter_yeah = True
for i00 in up_point_rows_list:
if i00>=start_node and i00 <=end_node:
enter_yeah = False
break
if enter_yeah:
near_upper_list.append([start_node,end_node])
pass
for item in near_upper_list:
min_val = None
min_i = None
for i in range(item[0],item[1]+1):
if min_val is None or min_val > df.iloc[i]['distance_upper']:
min_val = df.iloc[i]['distance_upper']
min_i = i
pass
if min_i:
nearest_upper_list.append(min_i)
# 股价上穿下轨的点
df['lower_close_up'] = 0
df.loc[(df['closePrice'].shift(1)<df['lower'].shift(1)) & (df['closePrice']>=df['lower']),'lower_close_up'] = 1
df['lower_close_down'] = 0
df.loc[(df['closePrice'].shift(1)>df['lower'].shift(1)) & (df['closePrice']<=df['lower']),'lower_close_down'] = 1
target_one_list = df.loc[df['lower_close_up']==1]['i_row'].values.tolist()
lower_point_rows_list = df.loc[(df['lower_close_up']==1) | (df['lower_close_down']==1)]['i_row'].values.tolist()
df['distance_lower'] = df['closePrice']-df['lower']
df['near_lower'] = 0
df.loc[(df['distance_lower']>0) & (df['distance_lower']/df['lower']<=0.005),'near_lower'] = 1
df['ext_2'] = df['near_lower'] - df['near_lower'].shift(1)
df['ext_3'] = df['near_lower'] - df['near_lower'].shift(-1)
start_i_row_list0 = df.loc[df['ext_2'] == 1]['i_row'].values.tolist()
end_i_row_list0 = df.loc[df['ext_3'] == 1]['i_row'].values.tolist()
nearest_lower_list = []
if start_i_row_list0 and end_i_row_list0:
if start_i_row_list0[0] > end_i_row_list0[0]:
end_i_row_list0 = end_i_row_list0[1:]
if start_i_row_list0[-1] > end_i_row_list0[-1]:
start_i_row_list0 = start_i_row_list0[:-1]
near_lower_list = []
for i, item in enumerate(start_i_row_list0):
start_node = item
end_node = end_i_row_list0[i]
enter_yeah = True
for i00 in lower_point_rows_list:
if i00 >= start_node and i00 <= end_node:
enter_yeah = False
break
if enter_yeah:
near_lower_list.append([start_node, end_node])
pass
for item in near_lower_list:
min_val = None
min_i = None
for i in range(item[0], item[1] + 1):
if min_val is None or min_val > df.iloc[i]['distance_lower']:
min_val = df.iloc[i]['distance_lower']
min_i = i
pass
if min_i:
nearest_lower_list.append(min_i)
i_row_list = nearest_upper_list + target_one_list + nearest_lower_list
# 临时 start
# df.to_csv('D:/temp006/'+ticker + '.csv',encoding='utf-8')
# 临时 end
node_count = 0
node_win = 0
duration_list = []
table_list = []
for i,row0 in enumerate(i_row_list):
row = row0 + 1
if row >= len(df):
continue
date_str = df.iloc[row]['tradeDate']
cur_close = df.iloc[row]['close']
three_after_close = df.iloc[row]['three_after_close']
three_chg = df.iloc[row]['three_chg']
table_list.append([
i,date_str,cur_close,three_after_close,three_chg
])
duration_list.append([row-2,row+3])
node_count += 1
if three_chg<0:
node_win +=1
pass
list_list.append({
'ticker':ticker,
'secName':secName,
'count':node_count,
'win':0 if node_count<=0 else round((node_win/node_count)*100,2)
})
detail_map[ticker] = {
'table_list': table_list,
'duration_list': duration_list
}
total_count += node_count
total_win += node_win
check_count += 1
pass
df = pd.DataFrame(list_list)
results_data = {
'check_count':check_count,
'total_count':total_count,
'total_win':0 if total_count<=0 else round((total_win/total_count)*100,2),
'start_date_str':caculate_start_date_str,
'df':df,
'detail_map':detail_map,
'factor_list':factor_list,
'ma_list':ma_list
}
return results_data结果


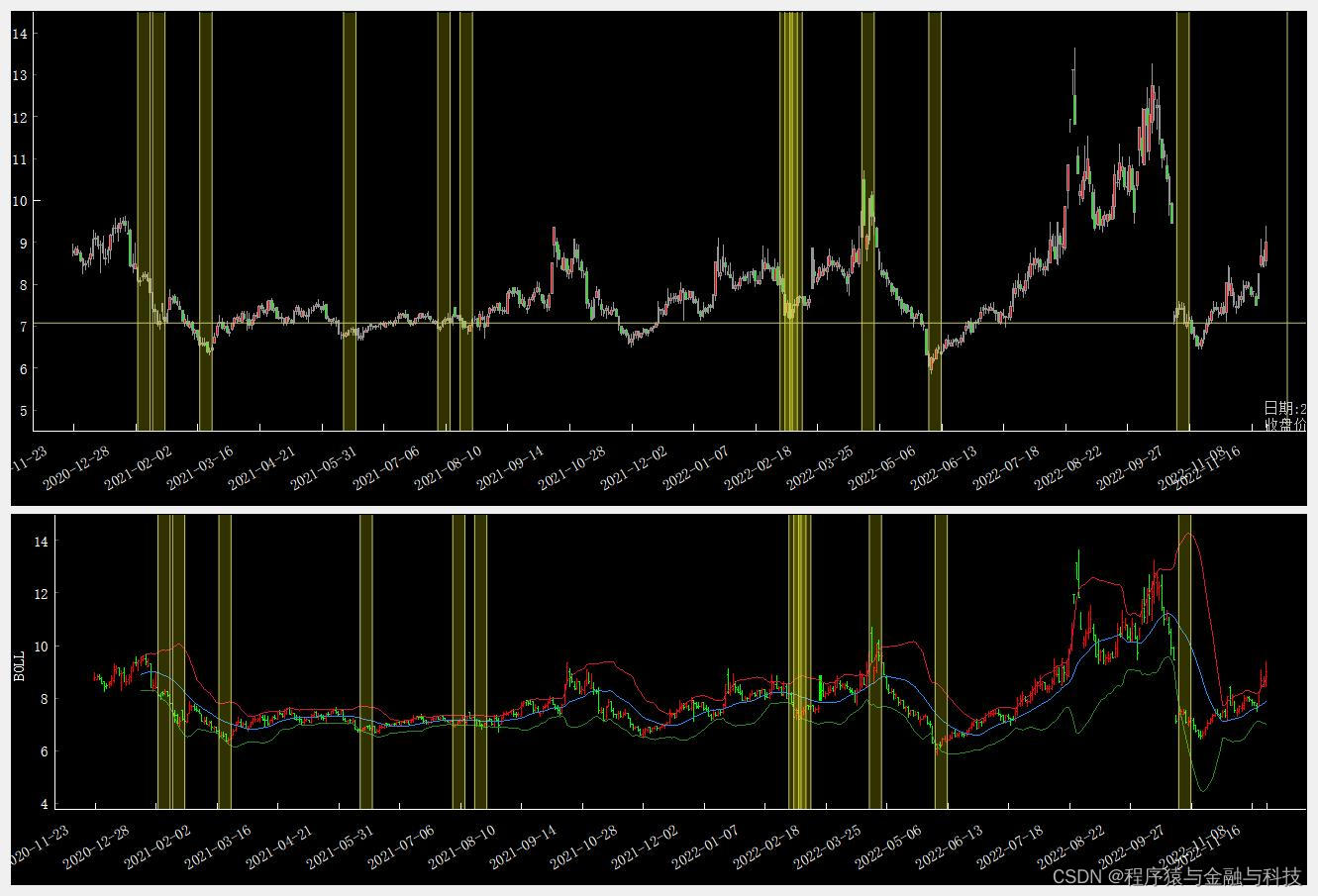
本文校验的数据是随机抽取的81个股票





![[附源码]java毕业设计小型银行贷款管理系统](https://img-blog.csdnimg.cn/ad3e83b6a3d947baa7440e846055785b.png)