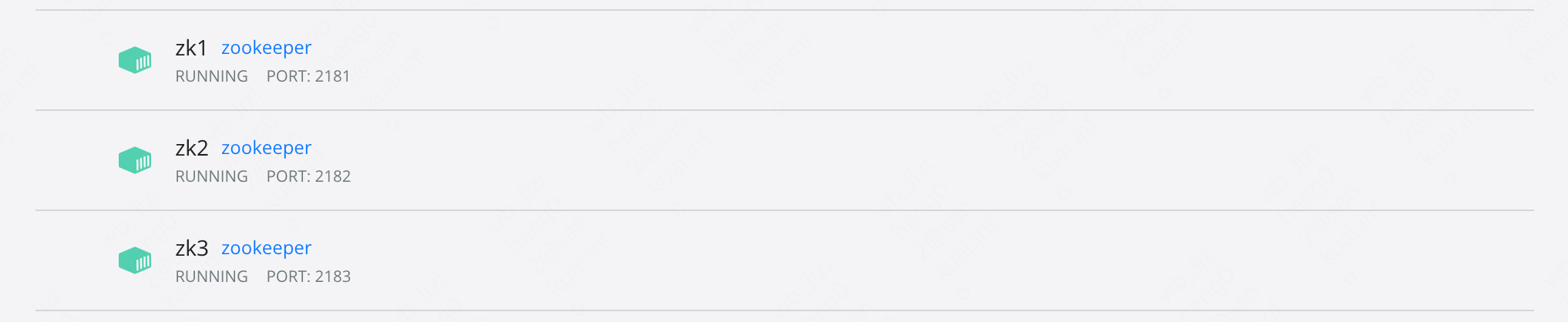
Shuffle
MapReduce的Map阶段与Reduce阶段之间有一个Shuffle的过程,包括分区、排序等内容。数据从Map阶段出来后,会进入一个环形缓冲区(默认100M),环形缓冲区中会同时记录数据和索引,当使用了80%的时候,会进行反向写,已有的数据会进行溢写,写到文件中,在溢写之前,会进行排序,对数据的索引按照字典序进行快排。溢写文件的过程包括分区、排序、Combine、归并排序等过程,溢写完成之后,ReduceTask会主动拉取文件进行处理。
默认分区HashPartitioner
MpaReduce默认1个分区,分区规则是key的哈希值对ReduceTask的数量取余,用户没法控制哪个key存在哪个分区:

自定义Partitioner
继承Partitioner抽象类,实现getPartition方法:
 自定义Partioner类的泛型跟MapTask的出参的key、value类型一致,getPartition方法返回的是整数(分区号从0开始),表示哪个分区。然后还需在job中设置Partitioner的class:
自定义Partioner类的泛型跟MapTask的出参的key、value类型一致,getPartition方法返回的是整数(分区号从0开始),表示哪个分区。然后还需在job中设置Partitioner的class:

还要设置ReduceTask的个数,一般与分区数一致:
 如果设置的ReduceTask的个数(1除外)小于分区数,则会报错,抛IO异常。但是ReduceTask的个数设为1是可以的,因为根据源码,分区数设为1,不会走自定义Partitioner:
如果设置的ReduceTask的个数(1除外)小于分区数,则会报错,抛IO异常。但是ReduceTask的个数设为1是可以的,因为根据源码,分区数设为1,不会走自定义Partitioner:

如果设置的ReduceTask的个数大于分区数,也不会报错,但会产生空文件。
如果设置的ReduceTask的个数为0,则不会有ReduceTask执行,最终输出的文件仅仅是MapTask产生的输出文件。
MapReduce排序
排序是MapReduce中的一个重要的操作,MapTask和ReduceTask都会根据key进行排序,属于默认行为,不管逻辑上是否真的需要排序。默认是按照字典序排序。
自定义排序:实现WritableCompatable接口,实现其compareTo方法,根据业务逻辑需要自定义排序规则,一般是实现在自定义的可序列化的bean上。
Combiner
Combiner是MapReduce中Mapper和Reducer之外的一种组件,父类是Reducer,相当于在ReduceTask之前提前做了一些汇总工作,减轻ReduceTask的工作量,他与Reducer的区别在于Combiner是在MapTask节点运行,而ReduceTask是接受所有的MapTask的结果。应用Combiner时应确保不影响正确的业务逻辑,而且Combiner输出的key、value类型要与ReduceTask的输入的key、value类型对应。
例如不使用Combiner,会使得(a,1)、(a,1)、(a,1)这种数据想ReduceTask传三次,使用了Combiner,可以直接传(a,3)。
自定义Combiner
实现Reducer方法,实现reduce方法,然后再job中设置Combiner的class。如果Combiner的实现逻辑和自定义的Reducer逻辑一致,可以不用自定义Combiner实现类,直接在job中设置Combiner的类为自定义的Reducer类。







![[附源码]SSM计算机毕业设计高校教师教学助手系统的设计与实现JAVA](https://img-blog.csdnimg.cn/9da2adb4bf4e40769fe87c8e40b73e2b.png)