hgfhfg
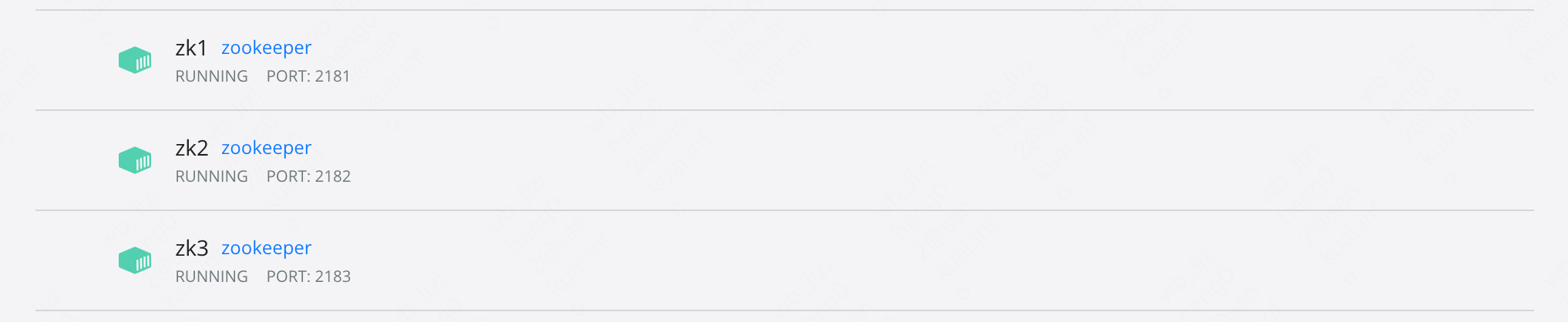
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:Apache Hadoop
一、本地运行模式
官方Grep案例
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹
mkdir input
2. 将Hadoop的xml配置文件复制到input
cp etc/hadoop/*.xml input
3. 执行share目录下的MapReduce程序
bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
4. 查看输出结果
cat output/*
二、完全分布式运行模式
1、编写集群分发脚本xsync
将三台服务器都放入hadoop和jdk
hadoop103删除文件 hadoop102通过rsync同步数据
(第一次拷贝推荐用scp,之后用sync)
cd /opt/module/
将本地文件推发送给局域网服务器
scp -r jdk1.8.0_212/ root@hadoop103:/opt/module/
输入yes
输入密码
拉取局域网的文件
scp -r root@hadoop102:/opt/module/hadoop-3.1.3 ./
将102服务器的工具拷贝到104
scp -r root@hadoop102:/opt/module/* root@hadoop104:/opt/module/
rm -rf wcinput
rsync -av hadoop-3.1.3/ root@hadoop103:/opt/module/hadoop-3.1.3/
创建脚本并执行,然后输入其他两个服务器的密码
cd /usr/local/
mkdir bin
vim xsync
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
xsync /usr/local/bin配置环境变量
102服务器
xsync /etc/profile.d/my_env.sh
103服务器、104服务器都执行
source /etc/profile2、SSH无密登录配置

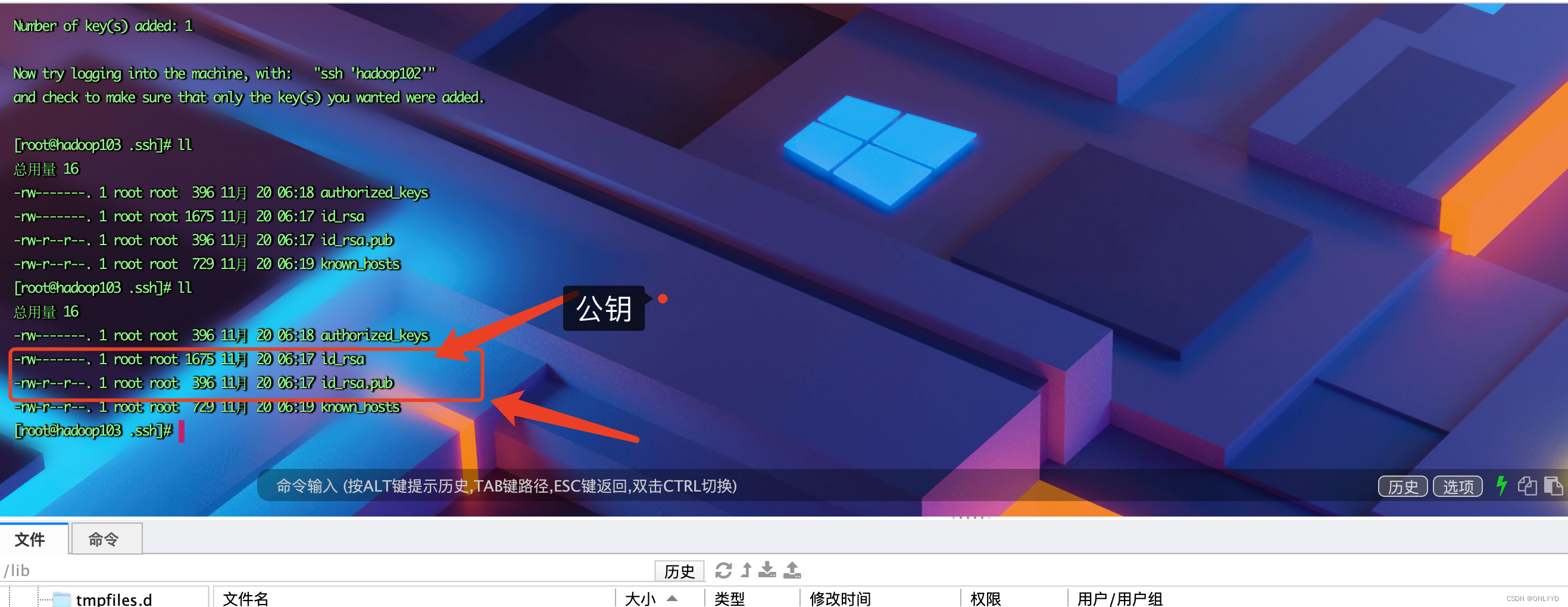
① 进入用户目录,输入 ls -al查看隐藏目录,如果没有ssh文件 连接自己建立ssh文件
ssh localhost②跟103和104建立连接,实现免密登录
按三下enter,建立自己的密钥
ssh-keygen -t rsa
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104





![[附源码]SSM计算机毕业设计高校教师教学助手系统的设计与实现JAVA](https://img-blog.csdnimg.cn/9da2adb4bf4e40769fe87c8e40b73e2b.png)