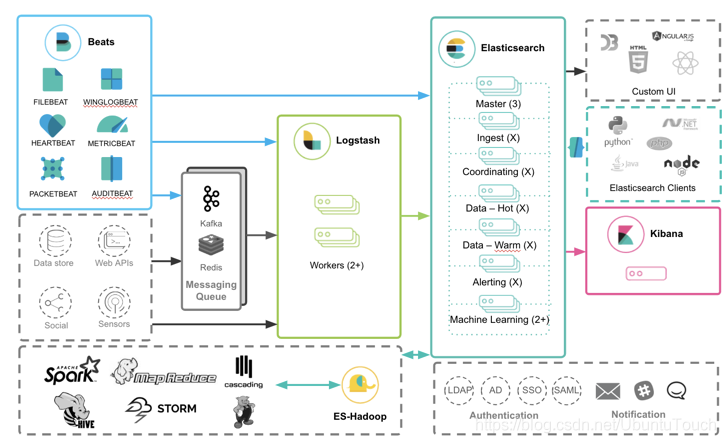
到目前为止,我们看到有很多中不同的方法来收集日志。甚至,我们针对同样的一个日志,有好多种方法来进行采集。在今天的这篇文章中,我来简单里回顾一下。
通过 Filebeat 采集
Filebeat 是最为常用的一种采集日志的方法。使用 Filebeat,我们也有如下的几种方法:
通过模块进行采集
为了能够使用 Filebeat 更加方便地进行对数据的采集, Elastic 提供了模块进行使用:

我们可以通过如下的命令来获得被支持的模块:
./filebeat modules list
通过模块的运用,我们可以生成相应的 ingest pipeline,dashboard,index patterns,index templates,ILM 等。这些模块是我们经常会使用的模块。提供了开箱即用的工具。
这种方法的途径是 Filebeat => Elasticsearch。有关模块的使用,我们可以参考文章 “Beats:Beats 入门教程 (一)”。
使用 Filebeat 的 input logs 来进行收集
即使对于上面所述的通过模块的方法采集的日志,我们也可以采用这个方法来实现。只不过,我们需要自己创建 dashboard,ingest pipeline,index template,生命周期管理策略等。事实上这个是一种更为普及的收据采集方式,特别是针对那些不在模块支持范围里的定制日志。
这种数据的采集方式是:Filebeat => Elasticsearch。我们可以阅读之前的文章 “Beats:通过 Filebeat 把日志传入到 Elasticsearch”。
通过 Filebeat 及 Logstash 来完成
我们知道 Logstash 可以被用来对数据进行清洗,并且可以通过 Logstash 来对数据和外部数据库进行丰富等操作。Logstash 的使用另外一方面提供了一个缓冲的作用,特别是针对大量生成日志的情况。
这种方法采集的路径是:Filebeat => Logstash => Elasticsearch。我们可以通过阅读我之前的文章 “Logstash:Logstash 入门教程 (二)”,或者文章 “Logstash:把 Apache 日志导入到 Elasticsearch”。
通过 Kafaka 来收集数据
针对大量的数据 Kafaka 是一个比较常用的解决方法。它可以起到缓冲的作用:

详细阅读,请参考文章 “Elastic:使用 Kafka 部署 Elastic Stack”。
通过 Logstash 来进行采集
在有些情况下,我们甚至直接可以使用 Logstash 来对日志数据进行采集。有关 Logstash 及 Filebeat 的区别,我们可以阅读文章 “Beats:Elastic Beats 介绍 及和 Logstash 的比较”。
这种方法的采集路径为:Logstash => Elasticsearch。我们可以通过阅读文章 “Logstash:Data 转换,分析,提取,丰富及核心操作”。
通过 Elastic Agent 来进行采集
随着 Elastic Stack 的开发,Elastic 在最新的发布版中更为推崇使用 Elastic Agent 来收集日志。

关于使用 Elastic Agent 的日志采集方法,我们也有两个类别:
被支持的集成(integration)
为了方便大家的使用,Elastic 也提供了类似开箱即用的模块那种方案。在最新的发布中,我们使用已经提供的集成来完成日志的采集。

我们可以阅读如下的文章来进行了解:
- Observability:使用 Elastic Agent 来摄入日志及指标 - Elastic Stack 8.0
-
Observability:运用 Fleet 来轻松地导入 Nginx 日志及指标
定制的日志
在很多的情况下,我们的日志可能并不属于 Elastic 已经提供的 integration 范畴。那么我们该如何收集这些日志到 Elasticsearch 中呢?事实上,Elastic 提供了一个叫做 Custom Logs 的集成来专门处理这累需求。如果你想了解这个方面的知识,请详细阅读文章 “Observability:如何使用 Elastic Agents 把定制的日志摄入到 Elasticsearch 中”。
在客户端中直接写日志到 Elasticsearch 中
我们也可以通过编程的方式直接在客户端中把日志写入到 Elasticsearch 中。请阅读文章:
-
Elasticsearch:运用 Python 实时通过 Logstash 写入日志到 Elasticsearch
使用其它非 Elastic Stack 方案
事实上,有很多其它的方案结合 Elastic Stack 来完成,比如:
-
Elastic:Fluentd 在 Elastic Stack 中的运用
-
Elastic:使用 Fluentd 及 Elastic Stack 进行应用日志采集
-
Elasticsearch:Apache spark 大数据集成
在上面,我们列举了上面我能想到的方法。在实际的使用中,开发者可能有更多的方法。如果有更多,请告诉我。我会把这写都记录下来。