【云岚到家】-day10-2-冷热处理及统计
- 3.7 历史订单
- 3.7.1 冷热分离方案
- 1)冷热分离需求
- 2)分布式数据库
- 3)冷热分离方案
- 3.7.2 订单同步
- 1)创建历史订单数据库
- 2)订单同步
- 3)测试订单同步
- 4)小结
- 3.7.3 订单冷热分离
- 1)编写SQL
- 2)定义mapper映射及接口
- 3)定义service
- 4)定时任务
- 5)测试订单冷热分离
- 3.8 订单统计
- 3.8.1 订单统计方案
- 1)经营看板
- 2)需求分析
- 3)技术方案
- 3.8.2 订单统计
- 1)定义mapper
- 2)定义service
- 3)定时任务
- 4)测试
- 5)按小时统计
- 3.8.3 经营看板
- 1)需求分析
- 2)阅读代码
- 3)测试
- 3.9 统计结果导出
- 3.9.1 EasyExcel入门
- 1)需求分析
- 2)EasyExcel入门
- 3)小结
- 3.9.2 统计结果导出
- 1)阅读代码
- 2)测试
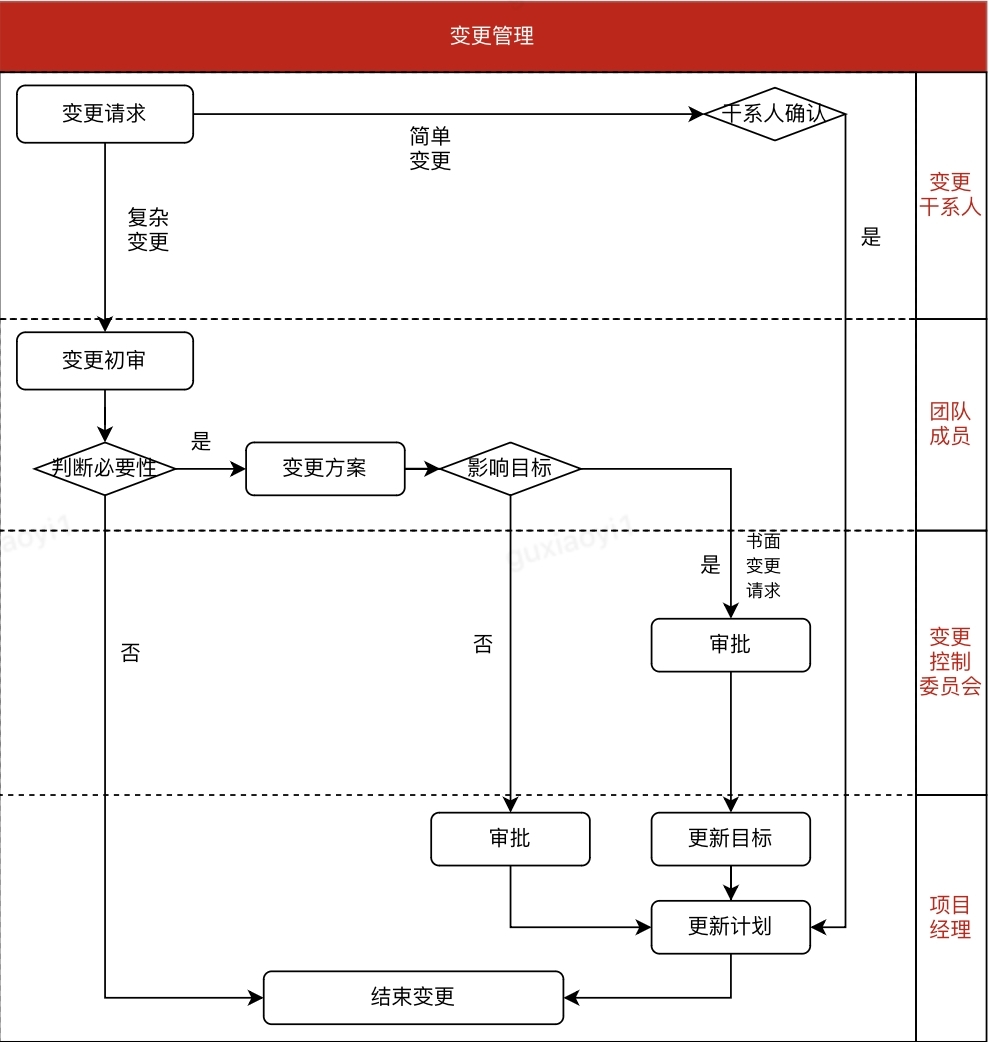
3.7 历史订单
3.7.1 冷热分离方案
目标:理解冷热分离的方案。
1)冷热分离需求
随着时间的推移,订单数据会逐渐增加,虽然对订单数据库进行分库分表,但是考虑用户对已完成的历史订单的操作热度远远低于未完成订单。
为了提高系统的性能我们对订单数据进行冷热分离。
冷数据是指那些很少被访问或者对访问时延迟要求较低的数据,而热数据则是经常被访问、对访问时延迟要求高的数据。
订单的冷热分离是指根据订单的特性和需求,将订单数据划分为冷数据和热数据,以便更有效地管理和优化数据存储、检索和处理的方式。这种分离有助于提高系统的性能和降低存储成本
根据需求,订单完成15日后将不允许对订单进行取消,我们可以将订单完成超过15日的订单归档到历史订单库,其它订单数据在订单数据库。订单数据库存储的是热数据,历史订单数据库存储冷数据。

2)分布式数据库
历史订单(冷数据)存储到哪里呢?
通常通过以下方式存储冷数据
将冷数据从主要的数据库中归档到较为廉价的存储介质,例如使用固态硬盘(SSD)存储热数据,而将冷数据存储在传统磁盘或云存储中,也可以使用低成本的云存储服务。
使用数据库分区或分片技术,将冷数据和热数据存储在不同的物理或逻辑分区。
使用云服务进行存储,比如:阿里云的对象存储OSS,腾讯云对象存储COS,这些都是比较廉价的。
根据本项目的需求,需要给用户和运营人员提供历史订单的查询接口,并且还需要对历史订单进行一些统计分析处理。
OSS不符合需求,因为OSS只能存储文件、图片、视频等,不能提供类似数据库的查询接口。
所以我们需要选择数据库存储,存储海量数据用关系数据库不合适,关系数据库可伸缩性相对有限,为了解决这个问题我们使用分布式数据库。
分布式数据库是指将数据库系统中的数据存储和处理分布在多个计算机节点上,这些节点可以位于不同的物理位置或在同一物理位置上。分布式数据库旨在通过分布数据和查询负载,提高系统的可伸缩性、性能和容错性。

常见的分布式数据库:
Apache Cassandra: 高度可伸缩、分布式、面向列的NoSQL数据库。
MongoDB: 面向文档的NoSQL数据库,支持分布式架构。
HBase: 是一个开源的、分布式的、面向列的NoSQL数据库系统,建立在Hadoop分布式文件系统(HDFS)之上。
还有一些国内常用的分布式数据库:
阿里云 PolarDB:
阿里云的PolarDB是一种支持MySQL和PostgreSQL的分布式关系型数据库服务。它具有高性能、可伸缩性和自动容灾的特性。
腾讯云 TDSQL-C(TiDB):
TDSQL-C是腾讯云推出的一种云原生分布式数据库服务,基于TiDB开源项目,支持水平扩展、强一致性和分布式事务。

如果去选择分布式数据库,通常从OLTP、OLAP、HTAP、NOSQL这几个方面去选择:
OLTP(Online Transaction Processing): OLTP是指在线事务处理系统。
OLAP(Online Analytical Processing): OLAP是指在线分析处理系统。
**HTAP(Hybrid Transactional/Analytical Processing):**HTAP是OLTP和OLAP的结合,旨在使一个数据库系统能够同时支持事务处理和分析处理。
本项目选择HTAP分布式数据库,TiDB(分布式数据库系统)属于HTAP范畴。TiDB设计为一个支持事务处理(OLTP)和复杂分析查询(OLAP)的分布式数据库系统。TiDB采用分布式架构,支持水平扩展,具有高可用性和强一致性的特性。TiDB支持MySQL协议,使用 MySQL 驱动(MySQL Client)来连接和与 TiDB 进行交。TiDB 开源,开源数据库不仅不影响学习和使用还可以节省成本。
下边列出了TiDB的优势 :
- 分布式架构:
- TiDB采用分布式架构,可以水平扩展以处理大规模的数据和请求。它将数据分散存储在多个节点上,支持高并发和高吞吐量。
- 兼容 MySQL 协议:
- TiDB 兼容 MySQL 协议,可以直接使用 MySQL 客户端工具和驱动,使得迁移现有的 MySQL 应用程序到 TiDB 变得相对容易。
- 水平可伸缩性:
- TiDB 支持水平扩展,可以轻松地增加节点以提高存储和查询能力,而不需要修改应用程序代码。
- 分布式事务支持:
- TiDB 提供强一致性的分布式事务支持,确保在分布式环境中的数据一致性和可靠性。
- 自动负载均衡:
- TiDB 具有自动负载均衡的功能,能够动态调整数据在集群中的分布,以保持各节点的负载均衡。
- 分布式查询优化:
- TiDB 提供分布式查询优化,可以在多个节点上并行执行查询,提高查询性能。同时,TiDB 优化器支持将查询计划分发到各节点执行。
- 实时分析:
- TiDB 支持实时分析查询,适用于OLAP(在线分析处理)场景,允许在不影响在线事务的情况下执行复杂的分析操作。
- 在线扩容和缩容:
- TiDB 支持在线扩容和缩容,可以根据需要动态调整集群的规模,而不需要停机。
- 弹性扩展:
- TiDB 提供了弹性扩展的能力,可以根据实际需求调整存储引擎,支持多种存储引擎,包括 TiKV、RocksDB 等。
- 开源社区支持:
- TiDB 是一个开源项目,拥有活跃的社区支持,用户可以获取到丰富的文档、社区资源和技术支持。
- 云原生:
- 利用云计算环境的弹性、可伸缩性和分布式特性在云环境中构建、部署、管理和扩展应用程序。
- iDB 支持云原生架构,可以轻松部署在云服务提供商(如阿里云、腾讯云、华为云)上,并集成到云服务的生态系统中。
3)冷热分离方案
如何进行冷热分离?
本项目除了将订单完成15日的订单迁移到历史订单数据库,还需要对订单数据进行分析,所以通过Canal+MQ将完成的订单(完成、取消、关闭)迁移到历史订单数据库,在历史订单服务对订单数据进行统计分析,并通过定时任务迁移冷数据。
方案如下:

流程如下:
当订单完成,取消、关闭时将订单信息写入同步表。
通过Canal+MQ将同步表的订单数据同步到历史订单数据库的待迁移表中,具体过程如下:
Canal读取binlog将写入同步表的数据写入MQ。
历史订单服务监听MQ,获得同步表的订单数据。
历史订单服务将订单数据写入待迁移表。
历史订单服务启动定时任务,每天凌晨将昨天0点到昨天24点之间完成15日后的订单信息迁移到历史订单表。
每次迁移完成将迁移完成的历史订单从待迁移表删除。
数据流:

3.7.2 订单同步
根据冷热分离方案,首先将完成、取消、关闭的订单同步到历史订单库。
本节目标:将完成、取消、关闭的订单同步到历史订单数据库。
1)创建历史订单数据库
根据冷热分离方案我们需要安装TiDB 分布式数据库,TiDB 分布式数据库安装过程复杂,在企业中通常由运维或数据库管理人员维护,TiDB数据库 支持MySQL协议,在开发中可以使用 MySQL 的 JDBC 驱动进行连接,为了节省学习成本我们在MySQL数据库创建历史订单数据库进行使用。
创建jzo2o-orders-history数据库,导入jzo2o-orders-history.sql脚本:

history_orders:用于存储历史订单数据。
history_orders_serve: 用于存储历史服务单数据。
history_orders_serve_sync:用于存储待迁移的已完成的服务单数据。
history_orders_sync: 用于存储待迁移的订单数据(包括已完成,取消、关闭的订单)。
stat_day:存储按天统计数据
stat_hour:存储按小时统计数据。
数据库创建完成注意修改nacos上数据库的连接地址:shared-tidb.yaml
2)订单同步
根据冷热分离方案,当订单完成,取消、关闭时将订单信息写入同步表,再通过Canal+MQ同步到历史订单数据库的待迁移表,Canal+MQ同步的代码我们之前做过,这里我们阅读代码理解订单同步的过程。
在订单数据库创建订单同步表和服务单的同步表:

- 当订单完成、取消、关闭时向同步表写入记录。
此部分的代码在订单状态机OrderStateMachine 类中实现,阅读下边的代码:
package com.jzo2o.orders.base.config;
import cn.hutool.core.util.*;
import com.jzo2o.common.utils.CollUtils;
import com.jzo2o.common.utils.ObjectUtils;
import com.jzo2o.orders.base.enums.OrderStatusEnum;
import com.jzo2o.orders.base.model.dto.OrderSnapshotDTO;
import com.jzo2o.orders.base.service.IHistoryOrdersSyncCommonService;
import com.jzo2o.redis.helper.CacheHelper;
import com.jzo2o.statemachine.AbstractStateMachine;
import com.jzo2o.statemachine.persist.StateMachinePersister;
import com.jzo2o.statemachine.snapshot.BizSnapshotService;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import static com.jzo2o.orders.base.constants.RedisConstants.RedisKey.ORDERS;
@Component
public class OrderStateMachine extends AbstractStateMachine<OrderSnapshotDTO> {
...
@Override
protected void postProcessor(OrderSnapshotDTO orderSnapshotDTO) {
...
/***************************完成、关闭、取消订单写历史订单同步表*******************************/
//取出订单的新状态
Integer ordersStatus = orderSnapshotDTO.getOrdersStatus();
if(OrderStatusEnum.FINISHED.getStatus().equals(ordersStatus) ||
OrderStatusEnum.CLOSED.getStatus().equals(ordersStatus) ||
OrderStatusEnum.CANCELED.getStatus().equals(ordersStatus) ){
historyOrdersSyncService.writeHistorySync(orderSnapshotDTO.getId());
}
}
通过historyOrdersSyncService.writeHistorySync(orderSnapshotDTO.getId());方法将订单数据同步上边两张同步表当中。
- Canal+MQ将同步表数据同步到历史订单数据库的待迁移表
首先进入RabbitMQ,配置exchange.canal-jzo2o交换机绑定下边红框的队列。

找到历史订单服务中的数据同步类

代码如下:
package com.jzo2o.orders.history.handler;
import com.jzo2o.canal.listeners.AbstractCanalRabbitMqMsgListener;
import com.jzo2o.orders.history.model.domain.HistoryOrdersSync;
import com.jzo2o.orders.history.service.IHistoryOrdersSyncService;
import org.springframework.amqp.core.ExchangeTypes;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
@Component
public class HistoryOrdersSyncHandler extends AbstractCanalRabbitMqMsgListener<HistoryOrdersSync> {
@Resource
private IHistoryOrdersSyncService historyOrdersSyncService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "canal-mq-jzo2o-orders-history", durable = "true"),
exchange = @Exchange(name = "exchange.canal-jzo2o", type = ExchangeTypes.TOPIC),
key = "canal-mq-jzo2o-orders-history"),
concurrency = "1"
)
public void onMessage(Message message) throws Exception {
parseMsg(message);
}
@Override
public void batchSave(List<HistoryOrdersSync> historyOrdersSyncs) {
historyOrdersSyncService.saveOrUpdateBatch(historyOrdersSyncs);
}
@Override
public void batchDelete(List<Long> ids) {
}
}
通过historyOrdersSyncService.saveOrUpdateBatch(historyOrdersSyncs);将订单数据写入历史订单数据库的待迁移表history_orders_sync中。
服务单同步类HistoryOrdersServeSyncHandler请自行查询源码。
3)测试订单同步
启动网关
启动jzo2o-customer
启动jzo2o-fundations
启动jzo2o-publics
启动jzo2o-orders-manager
启动jzo2o-orders-history
启动服务端(前端工程)
服务人员登录服务端,进入我的订单
开始服务
完成服务
预期结果:
完成服务后向同步表添加成功:

通过canal将完成订单同步到历史库

测试时注意:保证Canal工作正常,数据不同的问题参考:“配置搜索及数据同步环境v1.0” 进行处理。
4)小结
本节将完成、取消、关闭的订单使用Canal+MQ同步到历史订单数据库,流程如下:
- 订单完成、取消、关闭后在写入订单同步表。
- Canal读取同步表的binlog,解析数据发送至MQ
- 历史订单服务监听MQ,获取到订单信息后写入待迁移表(history_orders_sync和history_orders_serve_sync表)。
3.7.3 订单冷热分离
根据需求,订单完成15日后迁移到历史订单表和历史服务单表。
下边完成订单迁移:
1)编写SQL
insert into history_orders (id, user_id, serve_type_id, serve_provider_id, serve_provider_type, serve_item_id, serve_id,
city_code, serve_type_name, serve_item_name, serve_item_img, unit, orders_status,
pay_status, refund_status, trade_finish_time, trading_channel, third_order_id,
dispatch_time, price, pur_num, total_amount, real_pay_amount, third_refund_order_id,
canceler_name, discount_amount, serve_address, contacts_phone, contacts_name,
serve_provider_staff_name, serve_provider_staff_phone, institution_name, place_order_time,
serve_start_time, serve_end_time, real_serve_start_time, real_serve_end_time,
serve_before_imgs, serve_before_illustrate, serve_after_imgs, serve_after_illustrate,
payment_timeout, lon, lat, pay_time, cancel_time, cancel_reason, year, month, day, hour,
sort_time)
select hos.id,
hos.user_id,
hos.serve_type_id,
hos.serve_provider_id,
hos.serve_provider_type,
hos.serve_item_id,
hos.serve_id,
hos.city_code,
hos.serve_type_name,
hos.serve_item_name,
hos.serve_item_img,
hos.unit,
hos.orders_status,
hos.pay_status,
hos.refund_status,
hos.trade_finish_time,
hos.trading_channel,
hos.third_order_id,
hos.dispatch_time,
hos.price,
hos.pur_num,
hos.total_amount,
hos.real_pay_amount,
hos.third_refund_order_id,
hos.canceler_name,
hos.discount_amount,
hos.serve_address,
hos.contacts_phone,
hos.contacts_name,
hos.serve_provider_staff_name,
hos.serve_provider_staff_phone,
hos.institution_name,
hos.place_order_time,
hos.serve_start_time,
hos.serve_end_time,
hos.real_serve_start_time,
hos.real_serve_end_time,
hos.serve_before_imgs,
hos.serve_before_illustrate,
hos.serve_after_imgs,
hos.serve_after_illustrate,
hos.payment_timeout,
hos.lon,
hos.lat,
hos.pay_time,
hos.cancel_time,
hos.cancel_reason,
hos.year,
hos.month,
hos.day,
hos.hour,
hos.sort_time
from history_orders_sync hos
LEFT JOIN history_orders ho on hos.id = ho.id
where hos.sort_time >= '2023-12-05 0:0:0'
and hos.sort_time <= '2023-12-05 23:59:59'
and ho.id is null
limit 0,1000
2)定义mapper映射及接口
编写mapper映射文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jzo2o.orders.history.mapper.HistoryOrdersMapper">
<insert id="migrate" parameterType="java.util.Map">
insert into history_orders (id, user_id, serve_type_id, serve_provider_id, serve_provider_type, serve_item_id, serve_id, city_code, serve_type_name, serve_item_name, serve_item_img, unit, orders_status, pay_status, refund_status, trade_finish_time, trading_channel, third_order_id, dispatch_time, price, pur_num, total_amount, real_pay_amount, third_refund_order_id, canceler_name, discount_amount, serve_address, contacts_phone, contacts_name, serve_provider_staff_name, serve_provider_staff_phone, institution_name, place_order_time, serve_start_time, serve_end_time, real_serve_start_time, real_serve_end_time, serve_before_imgs, serve_before_illustrate, serve_after_imgs, serve_after_illustrate, payment_timeout, lon, lat, pay_time, cancel_time, cancel_reason, year, month, day, hour, sort_time)
(
select hos.id,hos.user_id,hos.serve_type_id,hos.serve_provider_id,hos.serve_provider_type,hos.serve_item_id,hos.serve_id,hos.city_code,hos.serve_type_name,hos.serve_item_name,hos.serve_item_img,hos.unit,hos.orders_status,hos.pay_status,hos.refund_status,hos.trade_finish_time,hos.trading_channel,hos.third_order_id,hos.dispatch_time,hos.price,hos.pur_num,hos.total_amount,hos.real_pay_amount,hos.third_refund_order_id,hos.canceler_name,hos.discount_amount,hos.serve_address,hos.contacts_phone,hos.contacts_name,hos.serve_provider_staff_name,hos.serve_provider_staff_phone,hos.institution_name,hos.place_order_time,hos.serve_start_time,hos.serve_end_time,hos.real_serve_start_time,hos.real_serve_end_time,hos.serve_before_imgs,hos.serve_before_illustrate,hos.serve_after_imgs,hos.serve_after_illustrate,hos.payment_timeout,hos.lon,hos.lat,hos.pay_time,hos.cancel_time,hos.cancel_reason,hos.year,hos.month,hos.day,hos.hour,hos.sort_time
from history_orders_sync hos
LEFT JOIN history_orders ho on hos.id=ho.id
where <![CDATA[ hos.sort_time >= #{yesterDayStartTime}]]> and <![CDATA[ hos.sort_time <= #{yesterDayEndTime} ]]>
and ho.id is null
limit #{offset},#{perNum}
)
</insert>
</mapper>
定义mapper接口:
package com.jzo2o.orders.history.mapper;
import com.jzo2o.orders.history.model.domain.HistoryOrders;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Param;
import java.time.LocalDateTime;
public interface HistoryOrdersMapper extends BaseMapper<HistoryOrders> {
Integer migrate(@Param("yesterDayStartTime") LocalDateTime yesterDayStartTime,
@Param("yesterDayEndTime") LocalDateTime yesterDayEndTime,
@Param("offset") Integer offset,
@Param("perNum") Integer perNum);
}
3)定义service
package com.jzo2o.orders.history.service;
import com.jzo2o.common.model.PageResult;
import com.jzo2o.orders.history.model.domain.HistoryOrders;
import com.baomidou.mybatisplus.extension.service.IService;
import com.jzo2o.orders.history.model.dto.request.HistoryOrdersListQueryReqDTO;
import com.jzo2o.orders.history.model.dto.request.HistoryOrdersPageQueryReqDTO;
import com.jzo2o.orders.history.model.dto.response.HistoryOrdersDetailResDTO;
import com.jzo2o.orders.history.model.dto.response.HistoryOrdersListResDTO;
import com.jzo2o.orders.history.model.dto.response.HistoryOrdersPageResDTO;
import java.util.List;
public interface IHistoryOrdersService extends IService<HistoryOrders> {
/**
* 迁移历史订单
*/
void migrate();
实现类:
@Override
public void migrate() {
log.debug("历史订单迁移开始...");
// 查询时间开始坐标
int offset = 0;
int perNum = 1000;
// 昨天开始时间
LocalDateTime yesterDayStartTime = DateUtils.getDayStartTime(DateUtils.now().minusDays(1));
// 昨天结束时间
LocalDateTime yesterDayEndTime = DateUtils.getDayEndTime(DateUtils.now().minusDays(1));
// 统计迁移数据数量
Integer total = historyOrdersSyncService.countBySortTime(yesterDayStartTime, yesterDayEndTime);
if(total <= 0){
return;
}
// 分批次迁移
while (offset < total) {
baseMapper.migrate(yesterDayStartTime, yesterDayEndTime, offset, perNum);
offset += perNum;
}
log.debug("历史订单迁移结束。");
}
4)定时任务
阅读下边的代码:
package com.jzo2o.orders.history.handler;
import com.jzo2o.orders.history.service.IHistoryOrdersServeService;
import com.jzo2o.orders.history.service.IHistoryOrdersService;
import com.jzo2o.orders.history.service.IStatDayService;
import com.jzo2o.orders.history.service.IStatHourService;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
@Component
public class XxlJobHandler {
/**
* 迁移HistoryOrdersSync同步表的数据到HistoryOrders历史订单表
* 迁移HistoryOrdersServeSync同步表的数据到HistoryOrdersServe历史订单表
* 规则:
* 每天凌晨执行,迁移截止到昨日已完成15天的订单到历史订单
*
*/
@XxlJob("migrateHistoryOrders")
public void migrateHistoryOrders(){
//迁移HistoryOrdersSync同步表的数据到HistoryOrders历史订单表
historyOrdersService.migrate();
//删除迁移完成的数据
historyOrdersService.deleteMigrated();
//迁移HistoryOrdersServeSync同步表的数据到HistoryOrdersServe历史订单表
historyOrdersServeService.migrate();
//删除迁移完成的数据
historyOrdersServeService.deleteMigrated();
}
...
自定义阅读以下代码:
//删除迁移完成的数据
historyOrdersService.deleteMigrated();
//迁移HistoryOrdersServeSync同步表的数据到HistoryOrdersServe历史订单表
historyOrdersServeService.migrate();
//删除迁移完成的数据
historyOrdersServeService.deleteMigrated();
5)测试订单冷热分离
添加执行器:

添加任务并启动任务:

订单完成15个工作日后迁移到历史订单。
在测试时修改history_orders_sync和history_orders_serve_sync中sort_time字段值小于等于昨天日期。
预期结果:
数据由 history_orders_sync和history_orders_serve_sync迁移到history_orders和history_orders_serve表。
运营人员登录运营端,查询历史订单:

3.8 订单统计
3.8.1 订单统计方案
1)经营看板
本项目在运营端工作台页面展示系统经营看板,内容包括订单分析、用户分析等,如下图:
经营看板是一种用于实时监控关键业务指标的工具,它不仅帮助团队保持敏捷、透明和高效,还促进了团队的协作和创新。

软件中经营看板的应用场景非常多,下图显示了公司销售分析周报:

双11销售统计:

通过学习本节的内容掌握看板功能 的开发方法。
2)需求分析
下边梳理本项目运营端经营看板的功能。
首先选择一个时间区间(不能大于365天),统计在此时间区间内的订单数据,只统计已取消、已关闭、已完成的订单数据。

订单分析内容如下:
- 有效订单数:在统计时间内,订单状态为已完成的订单数。(订单被取消、退款、关闭状态均不属于有效订单)
- 取消订单数:在统计时间内,提交订单后被取消订总量
- 关闭订单数:在统计时间内,提交订单后被关闭订总量
- 有效订单总额:在统计时间内,有效订单的总订单交易总额
- 实付单均价:在统计时间内,平均每单实际支付额(不包含失效订单)
实付单均价=有效订单总额/有效订单数

订单趋势:
订单趋势的显示分两种情况:
- 如果统计时间区间 大于1天,订单趋势显示时间区间内每天的下单总数。
- 如果统计时间区间小于等于1天,订单趋势显示当天每小时的下单总数。
3)技术方案
根据需求,我们要统计一个时间区间的订单总数、订单均价等指标。统计出结果后通过接口将数据返回给前端,前端在界面展示即可。
基于什么平台进行统计分析?
通常统计分析要借助大数据平台进行,流程如下:

说明:
大数据统计系统对数据进行统计,并统计结果存入MySQL。
Java程序根据看板的需求提供查询接口,从统计结果表查询数据。这里使用缓存,将看板需要的数据存入Redis,提高查询性能。
如果数据量不大在千万级别可以基于数据库进行统计。
本项目通过分布式数据库存储历史订单数据,可以满足统计分析的需求。
本项目对订单的统计基于数据库进行统计。
如何基于数据库进行统计呢?
当用户进入看板页面面向全部数据 进行实时统计其统计速度较慢。
为了提高统计效率可以分层次聚合,再基于分层聚合的统计结果进行二次统计。
举例:
我们要统计2023年10月1日 到2023年11月30日的订单总数等指标,我们可以提前按天把每天的订单总数等指标统计出来,当用户去统计2023年10月1日 到2023年11月30日的订单总数时基于按天统计的结果进行二次统计。
按天统计结果:
| 日期 | 订单总数 | 有效订单数 | 取消订单数 | … | 订单均价 |
|---|---|---|---|---|---|
| 20231001 | 100 | 100 | 0 | … | |
| 20231002 | 200 | 199 | 1 | … | |
| … |
统计数据的分层次聚合需要根据需求确定统计的维度,例如除了按照时间,还可能按地区、产品类别等进行聚合。
根据需求在订单趋势图上除了显示每天的订单总数以外还会按小时进行显示,所以还需要按小时进行统计。
本项目采用滚动式统计,每次统计近15天的数据(如果数据量大可减少统计时段长度),采用滚动式统计的好处是防止统计任务执行失败漏掉统计数据,如下图:
15日统计1到15日的订单。
16日统计2到16日的订单。
依此类推。

分层聚合的粒度有两种:
按天统计,将统计结果存储至按天统计表。
按小时,将统计结果存储至按小时统计表。
有了分层聚合的统计结果,根据用户需求基于分层聚合的统计结果进行二次统计,其统计效率会大大提高,并且有此需求无需进行二次统计直接查询分层聚合结果表即可。
数据流如下:

3.8.2 订单统计
下边实现按天统计订单。
1)定义mapper
首先编写SQL:
select day as id,
day as statTime,
sum(if(orders_status=500,1,0)) effective_order_num,
sum(if(orders_status=600,1,0)) cancel_order_num,
sum(if(orders_status=700,1,0)) close_order_num,
sum(if(orders_status=500,total_amount,0)) effective_order_total_amount
from history_orders_sync where day >= 20231120
GROUP BY day
在HistoryOrdersSyncMapper.xml.xml添加mapper映射,如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jzo2o.orders.history.mapper.HistoryOrdersSyncMapper">
<select id="statForDay" parameterType="java.util.Map" resultType="com.jzo2o.orders.history.model.domain.StatDay">
select day as id,
day as statTime,
sum(if(orders_status=500,1,0)) effective_order_num,
sum(if(orders_status=600,1,0)) cancel_order_num,
sum(if(orders_status=700,1,0)) close_order_num,
sum(if(orders_status=500,total_amount,0)) effective_order_total_amount
from history_orders_sync where day >= #{queryDay}
GROUP BY day
</select>
...
定义mapper接口
package com.jzo2o.orders.history.mapper;
import com.jzo2o.orders.history.model.domain.HistoryOrdersSync;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jzo2o.orders.history.model.domain.StatDay;
import com.jzo2o.orders.history.model.domain.StatHour;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface HistoryOrdersSyncMapper extends BaseMapper<HistoryOrdersSync> {
List<StatDay> statForDay(@Param("queryDay") Integer queryDay);
...
2)定义service
package com.jzo2o.orders.history.service;
public interface IHistoryOrdersSyncService extends IService<HistoryOrdersSync> {
List<StatDay> statForDay(Integer statDay);
...
实现类如下:
package com.jzo2o.orders.history.service.impl;
@Service
@Slf4j
public class HistoryOrdersSyncServiceImpl extends ServiceImpl<HistoryOrdersSyncMapper, HistoryOrdersSync> implements IHistoryOrdersSyncService {
@Override
public List<StatDay> statForDay(Integer statDay) {
//统计15天以内的订单
List<StatDay> statForDay = baseMapper.statForDay(statDay);
if(CollUtils.isEmpty(statForDay)) {
return Collections.emptyList();
}
// 按天统计订单,计算订单总数、均价等信息
List<StatDay> collect = statForDay.stream().peek(sd -> {
// 订单总数
sd.setTotalOrderNum(NumberUtils.add(sd.getEffectiveOrderNum(), sd.getCloseOrderNum(), sd.getCancelOrderNum()).intValue());
// 实付订单均价
if (sd.getEffectiveOrderNum().compareTo(0) == 0) {
sd.setRealPayAveragePrice(BigDecimal.ZERO);
} else {
//RoundingMode.HALF_DOWN 表示四舍五入 向下舍弃,如2.345,保留两位小数为2.34
BigDecimal realPayAveragePrice = sd.getEffectiveOrderTotalAmount().divide(new BigDecimal(sd.getEffectiveOrderNum()), 2, RoundingMode.HALF_DOWN);
sd.setRealPayAveragePrice(realPayAveragePrice);
}
}).collect(Collectors.toList());
return collect;
}
...
3)定时任务
定义service:
package com.jzo2o.orders.history.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.jzo2o.common.utils.DateUtils;
import com.jzo2o.orders.history.model.domain.StatDay;
import com.jzo2o.orders.history.mapper.StatDayMapper;
import com.jzo2o.orders.history.service.IHistoryOrdersService;
import com.jzo2o.orders.history.service.IHistoryOrdersSyncService;
import com.jzo2o.orders.history.service.IStatDayService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.jzo2o.orders.history.mapper.StatDayMapper;
import com.jzo2o.orders.history.model.domain.StatDay;
import com.jzo2o.orders.history.model.domain.StatHour;
import com.jzo2o.orders.history.service.IStatDayService;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.util.List;
@Service
public class StatDayServiceImpl extends ServiceImpl<StatDayMapper, StatDay> implements IStatDayService {
@Override
public void statAndSaveData() {
// 1.数据统计
// 15天前时间
LocalDateTime statDayLocalDateTime = DateUtils.now().minusDays(15);
long statDayTime = DateUtils.getFormatDate(statDayLocalDateTime, "yyyMMdd");
// 统计数据
List<StatDay> statDays = historyOrdersSyncService.statForDay((int) statDayTime);
if(ObjectUtils.isEmpty(statDays)){
return ;
}
// 2.数据保存至按天统计表
saveOrUpdateBatch(statDays);
}
定义xxl-job定时任务,在历史订单服务通过定时任务完成数据统计。
package com.jzo2o.orders.history.handler;
import com.jzo2o.orders.history.service.IHistoryOrdersServeService;
import com.jzo2o.orders.history.service.IHistoryOrdersService;
import com.jzo2o.orders.history.service.IStatDayService;
import com.jzo2o.orders.history.service.IStatHourService;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
@Component
public class XxlJobHandler {
/**
* 按天统计保存15天内的订单数据
* 按小时统计保存15天内的订单数据
*/
@XxlJob("statAndSaveData")
public void statAndSaveDataForDay() {
//按天统计保存15天内的订单数据
statDayService.statAndSaveData();
//按小时统计保存15天内的订单数据
statHourService.statAndSaveData();
}
...
4)测试
添加订单统计任务

保证history_orders_sync和history_orders_serve_sync有要统计的数据,按订单完成时间统计15天以内的订单
统计完成写入stat_day和stat_hour两张表,stat_day存储按天统计数据,stat_hour存储按小时统计数据。
5)按小时统计
自行阅读按小时统计代码。
3.8.3 经营看板
1)需求分析
目前我们完成对订单数据按天、按小时分层聚合,下边根据经营看板的需求进行二次统计,提供查询接口给前端,前端获取数据后在看板界面展示。
需求1:根据时间区间统计
根据时间区间统计以下内容:

- 有效订单数:在统计时间内,订单状态为已完成的订单数。(订单被取消、退款、关闭状态均不属于有效订单)
- 取消订单数:在统计时间内,提交订单后被取消订总量
- 关闭订单数:在统计时间内,提交订单后被关闭订总量
- 有效订单总额:在统计时间内,有效订单的总订单交易总额
- 实付单均价:在统计时间内,平均每单实际支付额(不包含失效订单)
实付单均价=有效订单总额/有效订单数
需求2: 订单趋势图
如果统计时间区间 大于1天,订单趋势显示时间区间内每天的下单总数,查询按天统计表的数据即可。
如果统计时间区间小于等于1天,订单趋势显示当天每小时的下单总数,查询按小时统计表的数据即可。

需求3: 缓存
看板数据需要进行二次统计,为了提高查询性能通常对二次统计的数据结果进行缓存,设置缓存过期时间,通常30分钟以内,根据监控数据变化的实时性去设置,本项目缓存数据为30分钟,当缓存过期重新统计最新的数据在看板展示。
2)阅读代码
- 接口
package com.jzo2o.orders.history.controller.operation;
import com.jzo2o.orders.history.model.dto.response.OperationHomePageResDTO;
import com.jzo2o.orders.history.service.OrdersStatisticsService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiImplicitParam;
import io.swagger.annotations.ApiImplicitParams;
import io.swagger.annotations.ApiOperation;
import org.springframework.format.annotation.DateTimeFormat;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.io.IOException;
import java.time.LocalDateTime;
@Api(tags = "运营端 - 订单统计相关接口")
@RestController("operationOrdersStatisticsController")
@RequestMapping("/operation/orders-statistics")
public class OrdersStatisticsController {
@Resource
private OrdersStatisticsService ordersStatisticsService;
@GetMapping("/homePage")
@ApiOperation("运营端首页数据")
@ApiImplicitParams({
@ApiImplicitParam(name = "minTime", value = "开始时间", required = true, dataTypeClass = LocalDateTime.class),
@ApiImplicitParam(name = "maxTime", value = "结束时间", required = true, dataTypeClass = LocalDateTime.class)
})
public OperationHomePageResDTO homePage(@RequestParam("minTime") @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime minTime,
@RequestParam("maxTime") @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime maxTime) {
return ordersStatisticsService.homePage(minTime, maxTime);
}
- service方法
service方法上使用spring cache注解对看板上展示的数据进行缓存。
package com.jzo2o.orders.history.service.impl;
import cn.hutool.core.bean.BeanUtil;
import cn.hutool.core.date.DatePattern;
import cn.hutool.core.date.LocalDateTimeUtil;
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.util.NumberUtil;
import cn.hutool.core.util.ObjectUtil;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.ExcelWriter;
import com.alibaba.excel.util.MapUtils;
import com.alibaba.excel.write.metadata.WriteSheet;
import com.alibaba.fastjson.JSON;
import com.jzo2o.common.expcetions.ForbiddenOperationException;
import com.jzo2o.common.utils.BeanUtils;
import com.jzo2o.common.utils.ObjectUtils;
import com.jzo2o.mvc.utils.ResponseUtils;
import com.jzo2o.orders.history.model.domain.StatDay;
import com.jzo2o.orders.history.model.domain.StatHour;
import com.jzo2o.orders.history.model.dto.excel.AggregationStatisticsData;
import com.jzo2o.orders.history.model.dto.excel.ExcelMonthData;
import com.jzo2o.orders.history.model.dto.excel.MonthElement;
import com.jzo2o.orders.history.model.dto.excel.StatisticsData;
import com.jzo2o.orders.history.model.dto.response.OperationHomePageResDTO;
import com.jzo2o.orders.history.service.IStatDayService;
import com.jzo2o.orders.history.service.IStatHourService;
import com.jzo2o.orders.history.service.OrdersStatisticsService;
import com.jzo2o.orders.history.utils.EasyExcelUtil;
import org.apache.poi.ss.formula.functions.T;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.math.BigDecimal;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import static com.jzo2o.mvc.constants.HeaderConstants.BODY_PROCESSED;
@Service
public class OrdersStatisticsServiceImpl implements OrdersStatisticsService {
/**
* 运营端首页数据
*
* @param minTime 开始时间
* @param maxTime 结束时间
* @return 首页数据
*/
@Override
@Cacheable(value = "JZ_CACHE", cacheManager = "cacheManager30Minutes")
public OperationHomePageResDTO homePage(LocalDateTime minTime, LocalDateTime maxTime) {
//校验查询时间
if (LocalDateTimeUtil.between(minTime, maxTime, ChronoUnit.DAYS) > 365) {
throw new ForbiddenOperationException("查询时间区间不能超过一年");
}
//如果查询日期是同一天,则按小时查询折线图数据
if (LocalDateTimeUtil.beginOfDay(maxTime).equals(minTime)) {
return getHourOrdersStatistics(minTime);
} else {
//如果查询日期不是同一天,则按日查询折线图数据
return getDayOrdersStatistics(minTime, maxTime);
}
}
/**
* 按日统计数据
*
* @param minTime 最小时间
* @param maxTime 最大时间
* @return 统计数据
*/
private OperationHomePageResDTO getDayOrdersStatistics(LocalDateTime minTime, LocalDateTime maxTime) {
//定义要返回的对象
OperationHomePageResDTO operationHomePageResDTO = OperationHomePageResDTO.defaultInstance();
//日期格式化,格式:yyyyMMdd
String minTimeDayStr = LocalDateTimeUtil.format(minTime, DatePattern.PURE_DATE_PATTERN);
String maxTimeDayStr = LocalDateTimeUtil.format(maxTime, DatePattern.PURE_DATE_PATTERN);
//根据日期区间聚合统计数据
StatDay statDay = statDayService.aggregationByIdRange(Long.valueOf(minTimeDayStr), Long.valueOf(maxTimeDayStr));
//将statDay拷贝到operationHomePageResDTO
operationHomePageResDTO = BeanUtils.copyIgnoreNull(BeanUtil.toBean(statDay, OperationHomePageResDTO.class), operationHomePageResDTO, OperationHomePageResDTO.class);
//根据日期区间查询按日统计数据
List<StatDay> statDayList = statDayService.queryListByIdRange(Long.valueOf(minTimeDayStr), Long.valueOf(maxTimeDayStr));
//将statDayList转为map<趋势图横坐标,订单总数>
Map<String, Integer> ordersCountMap = statDayList.stream().collect(Collectors.toMap(s -> dateFormatter(s.getId()), StatDay::getTotalOrderNum));
//趋势图上全部点
List<OperationHomePageResDTO.OrdersCount> ordersCountsDef = OperationHomePageResDTO.defaultDayOrdersTrend(minTime, maxTime);
//遍历ordersCountsDef,将统计出来的ordersCountMap覆盖ordersCountsDef中的数据
ordersCountsDef.stream().forEach(v->{
if (ObjectUtil.isNotEmpty(ordersCountMap.get(v.getDateTime()))) {
v.setCount(ordersCountMap.get(v.getDateTime()));
}
});
//将ordersCountsDef放入operationHomePageResDTO
operationHomePageResDTO.setOrdersTrend(ordersCountsDef);
return operationHomePageResDTO;
}
/**
* 按小时统计数据
*
* @param minTime 开始时间
* @return 统计数据
*/
private OperationHomePageResDTO getHourOrdersStatistics(LocalDateTime minTime) {
//定义要返回的对象
OperationHomePageResDTO operationHomePageResDTO = OperationHomePageResDTO.defaultInstance();
//获取当前日期,格式:yyyyMMdd
String minTimeDayStr = LocalDateTimeUtil.format(minTime, DatePattern.PURE_DATE_PATTERN);
//查询该日期的统计数据
StatDay statDay = statDayService.getById(Long.valueOf(minTimeDayStr));
//趋势图上全部点
List<OperationHomePageResDTO.OrdersCount> ordersCountsDef = OperationHomePageResDTO.defaultHourOrdersTrend();
if (null == statDay) {
operationHomePageResDTO.setOrdersTrend(ordersCountsDef);
return operationHomePageResDTO;
}
//如果统计数据不为空,拷贝数据
operationHomePageResDTO = BeanUtil.toBean(statDay, OperationHomePageResDTO.class);
//根据时间区间查询小时统计数据,并转换为map结构,key为小时,value为订单数量
List<StatHour> statHourList = statHourService.queryListByIdRange(Long.valueOf(minTimeDayStr + MIN_HOUR), Long.valueOf(minTimeDayStr + MAX_HOUR));
//将statHourList转map
Map<String, Integer> ordersCountMap = statHourList.stream().collect(Collectors.toMap(s -> String.format("%02d",s.getId() % 100), StatHour::getTotalOrderNum));
//遍历ordersCountsDef,将统计出来的ordersCountMap覆盖ordersCountsDef中的数据
ordersCountsDef.stream().forEach(v->{
if (ObjectUtil.isNotEmpty(ordersCountMap.get(v.getDateTime()))) {
v.setCount(ordersCountMap.get(v.getDateTime()));
}
});
//组装订单数趋势,返回结果
operationHomePageResDTO.setOrdersTrend(ordersCountsDef);
return operationHomePageResDTO;
}
...
3)测试
首先完成订单按天、按小时统计测试。
然后进入运营端
通过工作台查看统计数据

3.9 统计结果导出
3.9.1 EasyExcel入门
1)需求分析
在经营看板界面可将订单趋势图的数据导出Excel
点击“导出明细”,导出Excel。

示例:
2023-10-20~2023-11-20 全国经营分析统计.xlsx

示例2:

2)EasyExcel入门
根据需求,目标是将订单趋势图的中的数据导出Excel,数据来源于按天统计表和按小时统计表,现在关键问题是使用java语言生成Excel文档。
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
Easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便。
EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具。他能让你在不用考虑性能、内存的等因素的情况下,快速完成Excel的读、写等功能。
- 官方网站:https://easyexcel.opensource.alibaba.com/
- github地址:https://github.com/alibaba/easyexcel
- gitee地址:https://gitee.com/easyexcel/easyexcel
参考官方的例子
- 读Excel
DEMO代码地址:https://github.com/alibaba/easyexcel/blob/master/easyexcel-test/src/test/java/com/alibaba/easyexcel/test/demo/read/ReadTest.java
package com.jzo2o.orders.history.easyexcel.read;
import java.io.File;
import java.io.InputStream;
import java.util.List;
import java.util.Map;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.ExcelReader;
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.annotation.format.DateTimeFormat;
import com.alibaba.excel.annotation.format.NumberFormat;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.converters.DefaultConverterLoader;
import com.alibaba.excel.enums.CellExtraTypeEnum;
import com.alibaba.excel.read.listener.PageReadListener;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.excel.read.metadata.ReadSheet;
import com.alibaba.excel.util.ListUtils;
import com.alibaba.fastjson.JSON;
import com.jzo2o.orders.history.easyexcel.util.TestFileUtil;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
@Slf4j
public class ReadTest {
/**
* 最简单的读
* <p>1. 创建excel对应的实体对象 参照{@link DemoData}
* <p>2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link DemoDataListener}
* <p>3. 直接读即可
*/
@Test
public void simpleRead() {
String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}
...
运行上边的测试方法,跟踪DemoDataListener类invoke方法,观察控制台输出了从Excel中读取到的数据。
- 写Excel
DEMO代码地址:https://github.com/alibaba/easyexcel/blob/master/easyexcel-test/src/test/java/com/alibaba/easyexcel/test/demo/write/WriteTest.java
package com.jzo2o.orders.history.easyexcel.write;
import java.io.File;
import java.io.InputStream;
import java.net.URL;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Date;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.ExcelWriter;
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.annotation.format.DateTimeFormat;
import com.alibaba.excel.annotation.format.NumberFormat;
import com.alibaba.excel.annotation.write.style.ColumnWidth;
import com.alibaba.excel.annotation.write.style.ContentRowHeight;
import com.alibaba.excel.annotation.write.style.HeadRowHeight;
import com.alibaba.excel.enums.CellDataTypeEnum;
import com.alibaba.excel.metadata.data.CommentData;
import com.alibaba.excel.metadata.data.FormulaData;
import com.alibaba.excel.metadata.data.HyperlinkData;
import com.alibaba.excel.metadata.data.HyperlinkData.HyperlinkType;
import com.alibaba.excel.metadata.data.ImageData;
import com.alibaba.excel.metadata.data.ImageData.ImageType;
import com.alibaba.excel.metadata.data.RichTextStringData;
import com.alibaba.excel.metadata.data.WriteCellData;
import com.alibaba.excel.util.BooleanUtils;
import com.alibaba.excel.util.FileUtils;
import com.alibaba.excel.util.ListUtils;
import com.alibaba.excel.write.handler.CellWriteHandler;
import com.alibaba.excel.write.handler.context.CellWriteHandlerContext;
import com.alibaba.excel.write.merge.LoopMergeStrategy;
import com.alibaba.excel.write.metadata.WriteSheet;
import com.alibaba.excel.write.metadata.WriteTable;
import com.alibaba.excel.write.metadata.style.WriteCellStyle;
import com.alibaba.excel.write.metadata.style.WriteFont;
import com.alibaba.excel.write.style.HorizontalCellStyleStrategy;
import com.alibaba.excel.write.style.column.LongestMatchColumnWidthStyleStrategy;
import com.jzo2o.orders.history.easyexcel.util.TestFileUtil;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellStyle;
import org.apache.poi.ss.usermodel.FillPatternType;
import org.apache.poi.ss.usermodel.IndexedColors;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.streaming.SXSSFSheet;
import org.junit.jupiter.api.Test;
public class WriteTest {
/**
* 最简单的写
* <p>1. 创建excel对应的实体对象 参照{@link com.alibaba.easyexcel.test.demo.write.DemoData}
* <p>2. 直接写即可
*/
@Test
public void simpleWrite() {
String fileName = TestFileUtil.getPath() + "write" + System.currentTimeMillis() + ".xlsx";
// 这里 需要指定写用哪个class去读,然后写到第一个sheet,名字为模板 然后文件流会自动关闭
// 如果这里想使用03 则 传入excelType参数即可
EasyExcel.write(fileName, DemoData.class).sheet("模板").doWrite(data());
}
...
运行上边的测试方法,跟踪写到磁盘的excel文件(fileName ),查看文件内容是否是data()方法返回的数据。
- web上传、下载
DEMO代码地址:https://github.com/alibaba/easyexcel/blob/master/easyexcel-test/src/test/java/com/alibaba/easyexcel/test/demo/web/WebTest.java
package com.jzo2o.orders.history.controller.test;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.util.ListUtils;
import com.jzo2o.orders.history.model.dto.request.HistoryOrdersListQueryReqDTO;
import com.jzo2o.orders.history.model.dto.response.HistoryOrdersDetailResDTO;
import com.jzo2o.orders.history.model.dto.response.HistoryOrdersListResDTO;
import com.jzo2o.orders.history.service.IHistoryOrdersService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiImplicitParam;
import io.swagger.annotations.ApiOperation;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.net.URLEncoder;
import java.util.Date;
import java.util.List;
@Controller
@RequestMapping("/excel/test")
public class ExcelController {
/**
* 文件下载(失败了会返回一个有部分数据的Excel)
* <p>
* 1. 创建excel对应的实体对象 参照{@link DownloadData}
* <p>
* 2. 设置返回的 参数
* <p>
* 3. 直接写,这里注意,finish的时候会自动关闭OutputStream
*/
@GetMapping("download")
public void download(HttpServletResponse response) throws IOException {
// 这里注意 有同学反应使用swagger 会导致各种问题,请直接用浏览器或者用postman
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止中文乱码 当然和easyexcel没有关系
String fileName = URLEncoder.encode("测试", "UTF-8").replaceAll("\\+", "%20");
response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + fileName + ".xlsx");
EasyExcel.write(response.getOutputStream(), DemoData.class).sheet("模板").doWrite(data());
//设置返回body无需包装标识
response.setHeader(BODY_PROCESSED, "1");
}
/**
* 文件上传
* <p>1. 创建excel对应的实体对象 参照{@link UploadData}
* <p>2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link UploadDataListener}
* <p>3. 直接读即可
*/
@PostMapping("upload")
@ResponseBody
public String upload(MultipartFile file) throws IOException {
EasyExcel.read(file.getInputStream(), DemoData.class, new DemoDataListener()).sheet().doRead();
return "success";
}
测试上边的download方法。
3)小结
基于java的excel导入导出工具很多,这里推荐使用EashExcel,它性能更好。
使用方法:
读excel:
针对excel中的数据设计模型类。
编写监听类,实现ReadListener,在invoke方法中读取excel每一行的数据。
通过EasyExcel.read 方法读取excel。
写excel:
准备好要写入的数据。
针对要写入的数据编写模型类。
通过EasyExcel.write方法向excel写入数据。
3.9.2 统计结果导出
有了EasyExcel基础,下边阅读并测试订单导出的代码
1)阅读代码
- 接口
package com.jzo2o.orders.history.controller.operation;
import com.jzo2o.orders.history.model.dto.response.OperationHomePageResDTO;
import com.jzo2o.orders.history.service.OrdersStatisticsService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiImplicitParam;
import io.swagger.annotations.ApiImplicitParams;
import io.swagger.annotations.ApiOperation;
import org.springframework.format.annotation.DateTimeFormat;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.io.IOException;
import java.time.LocalDateTime;
@Api(tags = "运营端 - 订单统计相关接口")
@RestController("operationOrdersStatisticsController")
@RequestMapping("/operation/orders-statistics")
public class OrdersStatisticsController {
@Resource
private OrdersStatisticsService ordersStatisticsService;
/**
* 文件下载并且失败的时候返回json(默认失败了会返回一个有部分数据的Excel)
*
* @since 2.1.1
*/
@GetMapping("downloadStatistics")
@ApiOperation("导出统计数据")
@ApiImplicitParams({
@ApiImplicitParam(name = "minTime", value = "开始时间", required = true, dataTypeClass = LocalDateTime.class),
@ApiImplicitParam(name = "maxTime", value = "结束时间", required = true, dataTypeClass = LocalDateTime.class)
})
public void downloadStatistics(@RequestParam("minTime") @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime minTime,
@RequestParam("maxTime") @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime maxTime) throws IOException {
ordersStatisticsService.downloadStatistics(minTime, maxTime);
}
}
- service方法
/**
* 导出统计数据
*
* @param minTime 开始时间
* @param maxTime 结束时间
*/
@Override
public void downloadStatistics(LocalDateTime minTime, LocalDateTime maxTime) throws IOException {
//校验查询时间
if (LocalDateTimeUtil.between(minTime, maxTime, ChronoUnit.DAYS) > 365) {
throw new ForbiddenOperationException("查询时间区间不能超过一年");
}
HttpServletResponse response = ResponseUtils.getResponse();
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
//设置返回body无需包装标识
response.setHeader(BODY_PROCESSED, "1");
try {
//如果查询日期是同一天,则按小时导出数据
if (LocalDateTimeUtil.beginOfDay(maxTime).equals(minTime)) {
downloadHourStatisticsData(response, minTime);
} else {
//如果查询日期不是同一天,则按日导出数据
downloadDayStatisticsData(response, minTime, maxTime);
}
} catch (Exception e) {
// 重置response,默认失败了会返回一个有部分数据的Excel
response.reset();
response.setContentType("application/json");
Map<String, String> map = MapUtils.newHashMap();
map.put("status", "failure");
map.put("message", "下载文件失败" + e.getMessage());
response.getWriter().println(JSON.toJSONString(map));
}
}
private void downloadDayStatisticsData(HttpServletResponse response, LocalDateTime minTime, LocalDateTime maxTime) throws IOException {
//模板文件路径
String templateFileName = "static/day_statistics_template.xlsx";
//转换时间格式,拼接下载文件名称
String fileNameMinTimeStr = LocalDateTimeUtil.format(minTime, DatePattern.NORM_DATE_PATTERN);
String fileNameMaxTimeStr = LocalDateTimeUtil.format(maxTime, DatePattern.NORM_DATE_PATTERN);
String fileName = fileNameMinTimeStr + "~" + fileNameMaxTimeStr + " 全国经营分析统计.xlsx";
// 这里URLEncoder.encode可以防止中文乱码
fileName = URLEncoder.encode(fileName, StandardCharsets.UTF_8).replaceAll("\\+", "%20");
response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + fileName);
String currentTime = LocalDateTimeUtil.format(LocalDateTime.now(), "yyyy/MM/dd HH:mm:ss");
//根据id区间查询按天统计数据,并转为map,key为日期,value为日期对应统计数据
String minTimeDayStr = LocalDateTimeUtil.format(minTime, DatePattern.PURE_DATE_PATTERN);
String maxTimeDayStr = LocalDateTimeUtil.format(maxTime, DatePattern.PURE_DATE_PATTERN);
//查询按天统计表
List<StatDay> statDayList = statDayService.queryListByIdRange(Long.valueOf(minTimeDayStr), Long.valueOf(maxTimeDayStr));
//转成List<StatisticsData>
List<StatisticsData> statisticsDataList = BeanUtils.copyToList(statDayList, StatisticsData.class);
//按月份切分统计数据, 有几个月list中就有几条记录
List<ExcelMonthData> excelMonthDataList = cutDataListByMonth(statisticsDataList);
// 生成CellWriteHandler对象,在向单元格写数据时会调用它的afterCellDispose方法
// getSpecialHandleDataInfo()方法找到需要格式化处理的行索引,返回CellWriteHandler对象
EasyExcelUtil easyExcelUtil = getSpecialHandleDataInfo(excelMonthDataList);
try (ExcelWriter excelWriter = EasyExcel
//注意,服务器上以jar包运行,只能使用下面第2种方式,第1种方式只能在本地运行成功
// .write(fileName, StatisticsData.class)
.write(response.getOutputStream(), StatisticsData.class)
//注意,服务器上以jar包运行,只能使用下面第3种方式,前2种方式只能在本地运行成功
// .withTemplate(templateFileName)
// .withTemplate(FileUtil.getInputStream(templateFileName))
.withTemplate(FileUtil.class.getClassLoader().getResourceAsStream(templateFileName))
.autoCloseStream(Boolean.FALSE)
.registerWriteHandler(easyExcelUtil).build()) {
// 按天统计,选择第1个sheet,把sheet设置为不需要头
WriteSheet writeSheet = EasyExcel.writerSheet(0).needHead(Boolean.FALSE).build();
//构建填充数据,map的key对应模板文件中的{}中的名称
Map<String, Object> map = MapUtils.newHashMap();
map.put("startTime", fileNameMinTimeStr);
map.put("endTime", fileNameMaxTimeStr);
map.put("currentTime", currentTime);
//写入填充数据
excelWriter.fill(map, writeSheet);
//向单元格式依次写入数据
for (ExcelMonthData excelMonthData : excelMonthDataList) {
MonthElement monthElement = new MonthElement(excelMonthData.getMonth());
excelWriter.write(List.of(monthElement), writeSheet);//月份
excelWriter.write(excelMonthData.getStatisticsDataList(), writeSheet);//每天的数据
excelWriter.write(List.of(excelMonthData.getMonthAggregation()), writeSheet);//该天的汇总数据
}
excelWriter.finish();
}
}
通过阅读代码,这里通过EasyExcelUtil更改excel的样式。
2)测试
首先完成订单按天、按小时统计测试。
然后进入运营端
通过工作台查看统计数据,点击“导出明细”