文章目录
- 一、LangChain 简介
- 二、RAG 产生的背景及其局限性
- 三、RAG 工作流程
- 四、 Easysearch 结合 LLM 实现 RAG
- (1)Easysearch 简介
- (2)结合实现RAG
- 五、 Easysearch 结合 LLM 实现 RAG 的优势
- (1)提高检索准确性
- (2)增强知识生成能力
- (3)提升用户体验
LangChain通过提供统一的抽象层和丰富的工具,极大地简化了LLM应用程序的开发过程,使得开发者能够更加专注于业务逻辑。RAG技术则通过索引和检索生成两步流程,利用最新数据或私有数据作为背景信息来增强大模型的推理能力。然而,对于复杂问题,RAG仍存在不足之处,需要进一步探索如GraphRAG等解决方案,以提升其在复杂场景下的表现。
最后讨论Easysearch 作为一种先进的搜索技术,结合强大的语言模型(LLM),为实现检索增强生成(RAG)带来了新的机遇。
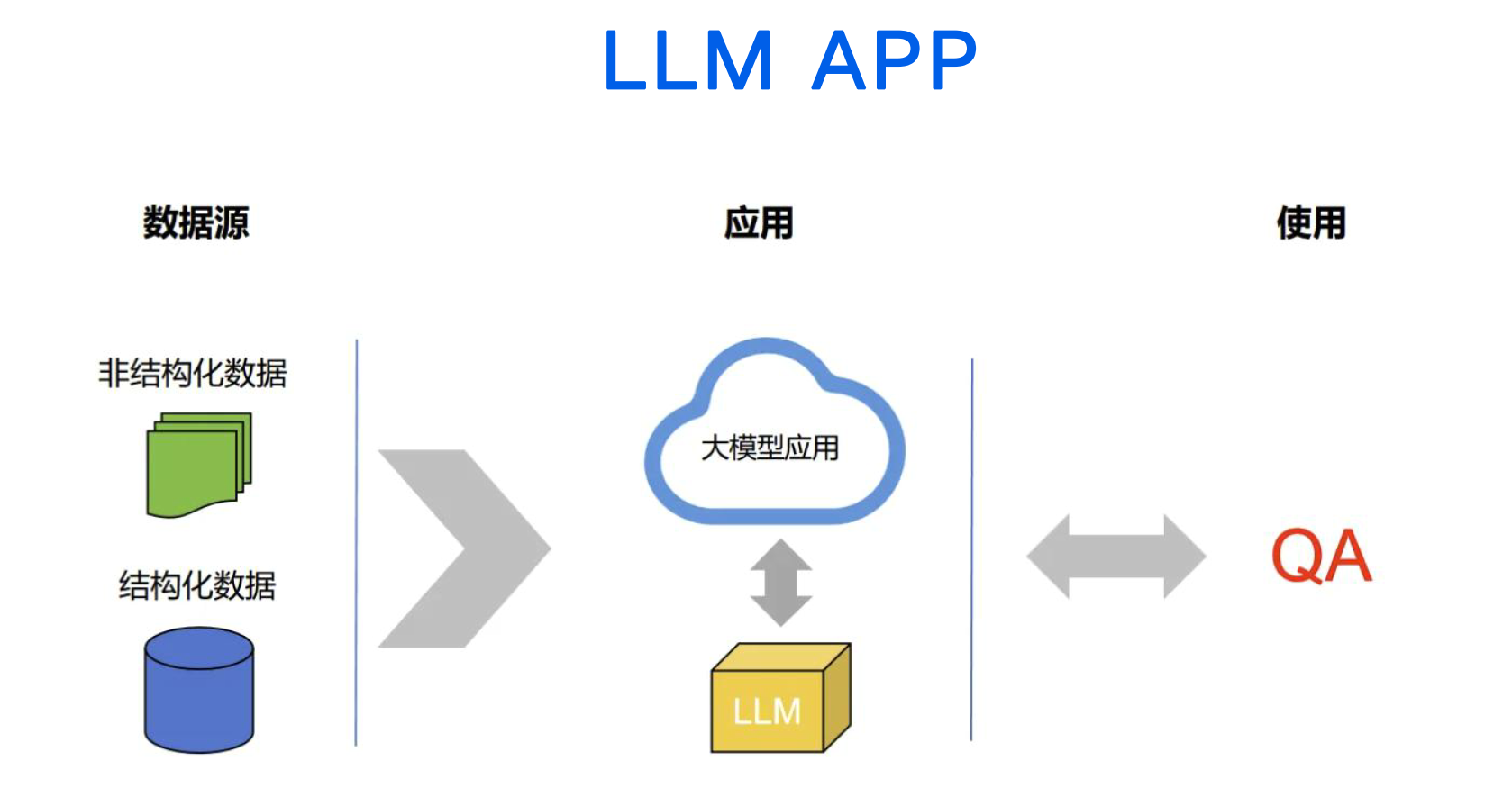
一、LangChain 简介
LangChain是一个基于大语言模型(LLMs)构建应用的开源框架,它为开发者提供了一系列强大的工具和接口,使得创建由LLMs支持的应用程序变得更加简单高效。
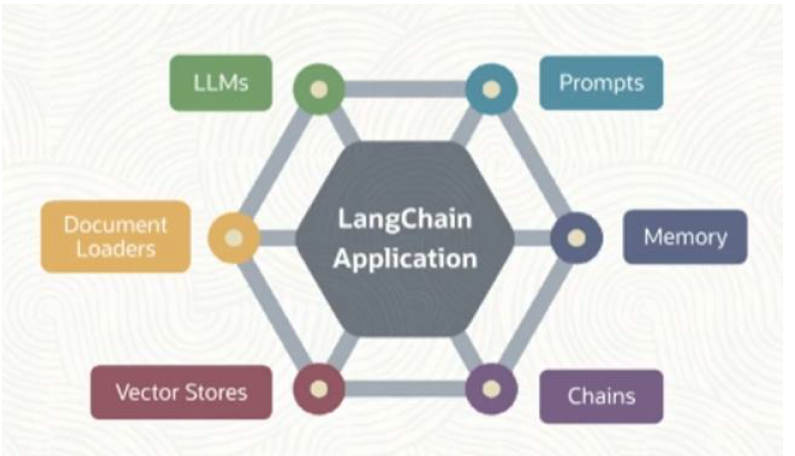
无论是聊天机器人还是图生文、文生图等复杂任务,LangChain都能轻松应对。这一框架通过提供统一的抽象层,让开发者可以将更多精力投入到业务逻辑上,而不是重复造轮子。此外,LangChain还具备通用性,通过API或网站即可与LLM进行交互,这使得它成为AI时代产品升级的重要利器。
二、RAG 产生的背景及其局限性

在传统的数据查询方式中,我们通常依赖于数据库、搜索服务或向量数据库等手段。然而,这些方法在面对动态变化的数据环境时显得力不从心。尤其是在预训练阶段,大模型往往缺乏最新的数据以及企业或个人专属的数据,这就导致了可解释性差和幻觉问题频发。此外,大模型决策过程的不透明性也让人难以信服。而RAG技术正是在这样的背景下应运而生,通过传递最新数据或私有数据作为背景信息,不涉及直接利用大模型推理能力,从而减少幻觉发生。然而,对于一些宏观且复杂的问题,RAG仍然显得捉襟见肘,需要借助GraphRAG等更高级别的方法来弥补这些不足。
三、RAG 工作流程
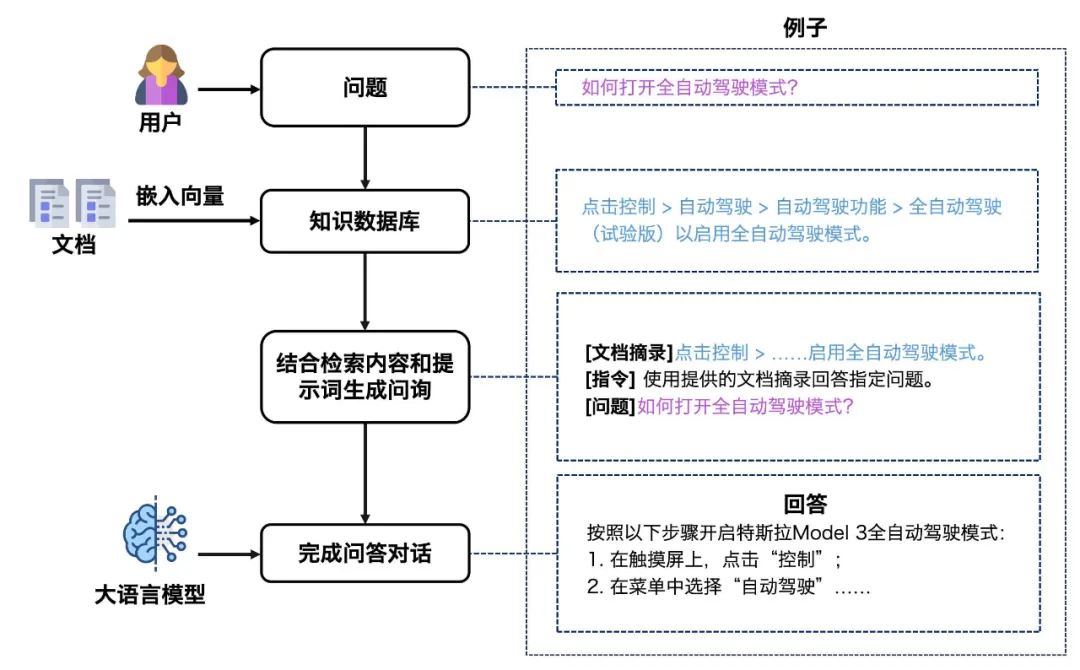
典型的RAG工作流程分为两个步骤:索引和检索生成。
在索引阶段,从源获取数据并进行索引处理;而在检索生成阶段,则接受用户查询,从索引中检索相关数据,并将其传递给大模型以生成回答。
为了实现这一过程,LangChain提供了多种加载器,可以从各种数据源加载Document对象,并通过文本分割器将内容拆分成更小块,以便于存储和检索。同时,通过embedding模型创建文本向量表示,并定义检索接口来包装这些操作,使整个流程更加流畅高效。
四、 Easysearch 结合 LLM 实现 RAG
(1)Easysearch 简介
Easysearch 是一种高效的搜索工具,具有以下特点:
- 快速准确:能够在海量数据中快速定位所需信息,提供准确的搜索结果。
- 智能排序:根据相关性、热度等因素对搜索结果进行智能排序,提高用户获取有用信息的效率。
- 个性化推荐:根据用户的历史搜索记录和偏好,为用户提供个性化的搜索推荐。
(2)结合实现RAG

- 检索阶段
Easysearch 利用其高效的搜索算法,在大规模数据集中快速检索与用户查询相关的文档。这些文档作为输入提供给 LLM,以便进行进一步的分析和处理。
- 分析阶段
LLM 对检索到的文档进行深入分析,理解其内容和含义。通过提取关键信息、总结主要观点等方式,为后续的知识生成提供基础。
- 知识生成阶段
基于对文档的分析,LLM 利用其知识生成能力,生成与用户查询相关的新的知识内容。这些生成的内容可以是回答问题、提供解释、生成报告等形式。
- 反馈阶段
用户对生成的知识内容进行反馈,帮助系统不断优化和改进。
Easysearch 和 LLM 可以根据用户反馈调整搜索策略和知识生成方式,提高准确性和实用性。
五、 Easysearch 结合 LLM 实现 RAG 的优势
(1)提高检索准确性
LLM 的语言理解能力可以帮助更好地理解用户查询的意图,从而提高检索的准确性。结合 Easysearch 的智能排序和个性化推荐功能,为用户提供更符合需求的搜索结果。
(2)增强知识生成能力
LLM 的知识生成能力可以为用户提供更丰富、更深入的知识内容。
与 Easysearch 的检索功能相结合,可以快速获取相关的文档作为知识生成的基础,提高生成内容的质量和可靠性。
(3)提升用户体验
通过提供准确的搜索结果和有用的知识生成内容,Easysearch 结合 LLM 可以大大提升用户的体验。用户可以更快速地获取所需信息,解决问题,提高工作效率和学习效果。