Jmeter基本使用
一、变量
1.用户定义变量
2.用户参数
二、函数
1.计数器${__counter(,)}
2.时间函数
3.加密函数${__digest(,,,,)}
4. 整数相加${__intSum(,,)}
5.属性函数,${__P(,)}、${__property(,,)}、${__setProperty(,,)}
6.V函数
三、获取响应数据
1.json提取器
2.正则提取器
四、DDT数据驱动测试
1.文件名称
2.设置介绍
3.须知内容:
五、逻辑控制器
1.循环控制器、foreach控制器
2.if 条件控制器
六、事务控制器
七、聚合报告\汇总报告
八、临界控制器Critical Section Controller
九、仅一次控制器Once Only Controller
十、DDT驱动数据驱动(二)
1.使用方法: jmeter + sqlite
2.使用步骤
3.操作截图
一、变量
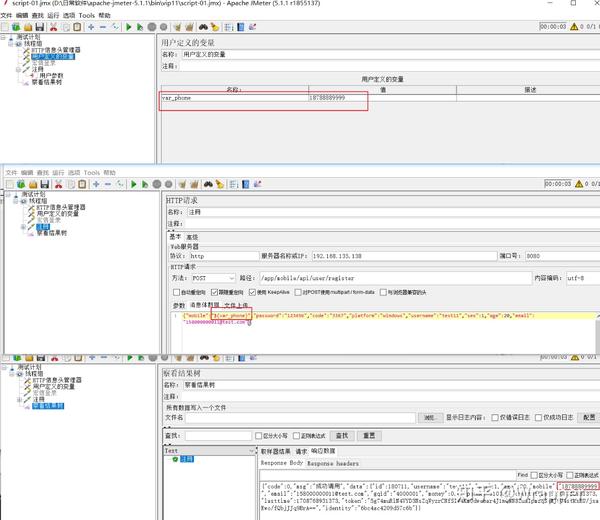
1.用户定义变量
位置:测试计划-->配置元件-->用户定义的变量
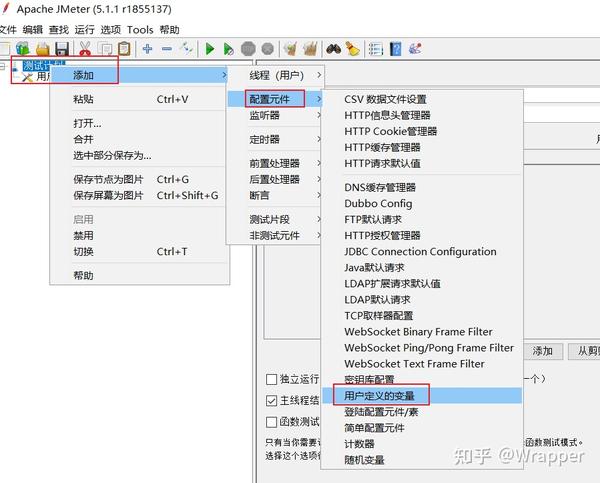
适用范围:全局变量
作用域:作用于整个‘测试计划’
使用情况: 在启动运行时,获取一次值,在运行过程中,不会动态获取值,在运行过程中,值一直都不变在启动运行时,获取一次值,在运行过程中,不会动态获取值,在运行过程中,值一直都不变
使用结果:
2.用户参数
位置:线程组-->前置处理器-->用户参数
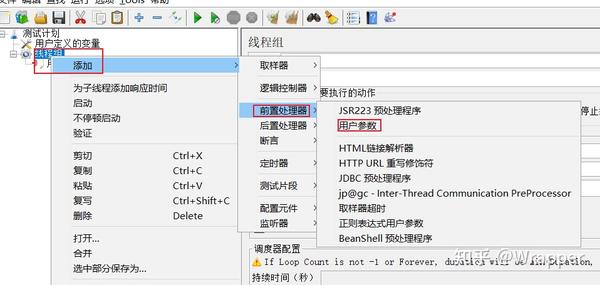
适用范围:局部变量
作用域: 作用于当前线程组或当前的取样器
使用情况: 在启动运行时,获取一次值,在运行过程中,还会动态获取值。在启动运行时,获取一次值,在运行过程中,还会动态获取值。
用户参数,在取样器调用之前被使用。
使用结果:
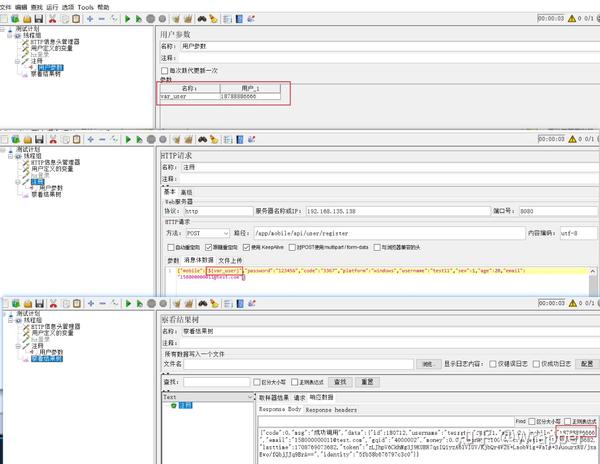
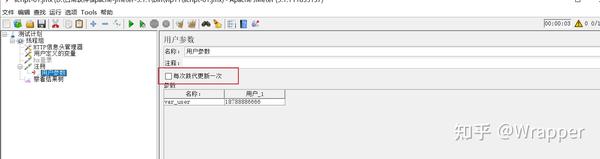
2.1 每次迭代更新一次
勾选后,当前线程组下所有的接口,全部执行,才会更新;
二、函数
- 双下划线开头
- 函数名称,严格区分大小写
- 重要的函数
${__counter(,)} 计数器
${__dateTimeConvert(,,,)} 时间格式转换
${__digest(,,,,)} 加密 简单加密 *****
${__intSum(,,)} 整数相加函数
${__P(,)} 获取属性函数 *****
${__property(,,)} 获取属性函数 *****
${__setProperty(,,)} 设置属性函数 *****
${__Random(,,)} 随机数
${__RandomString(,,)} 随机字符串
${__threadNum} 获取线程号函数
${__time(,)} 获取当前时间戳函数 *****
${__timeShift(,,,,)} 数据格式化
${__V(,)} 拼接函数 *****1.计数器${__counter(,)}
创建计数器函数:

使用计数器函数:
在调式取样器的名称使用计数器函数,循环5次,名称的数字每次加1,起到一个计数器的作用。
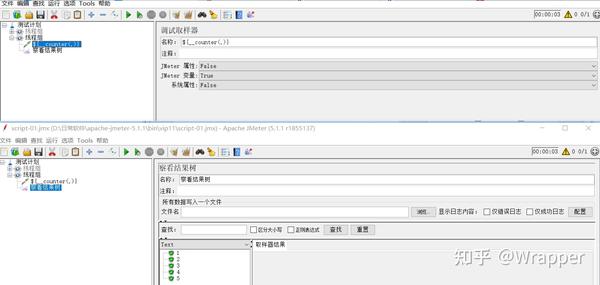
注意:计数器函数每次递增只能加1,若想用递增加2或递增更多的时候,需要使用配置原件中的 “计数器”;
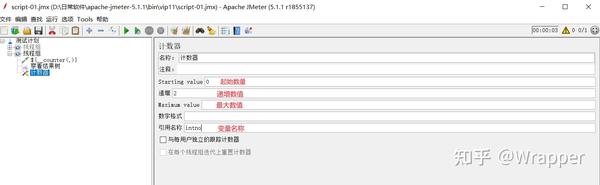
注意截图中的最大数值: 如果运行结果超过最大值时,又会从起始值开始循环;
每个用户独立计数器: 多线程时,每个用户都是从起始值开始计数
2.时间函数
2.1 ${__time(,)}函数
第一种情况:不写参数,就是单独获取当前时间的时间戳
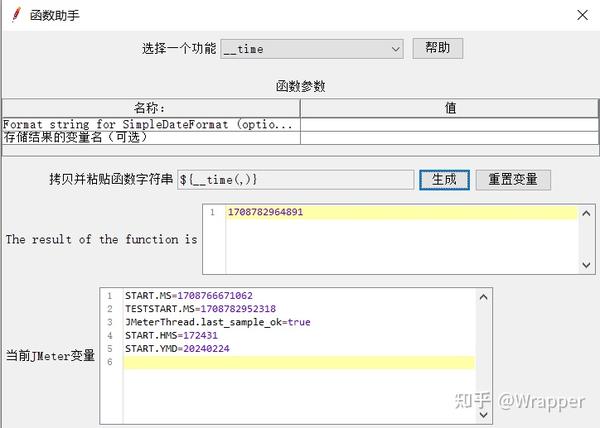
第二种情况,带函数参数时,可以获取到对应格式的时间:
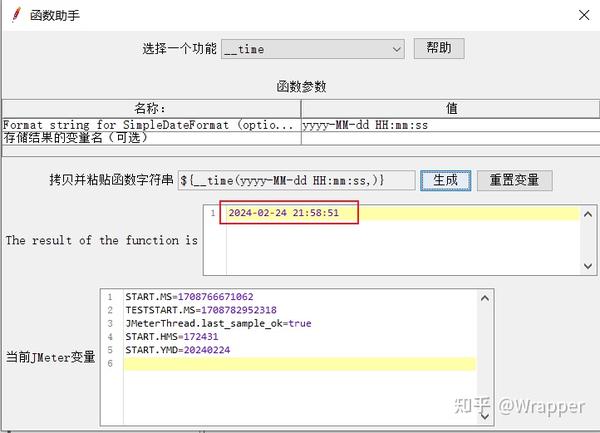
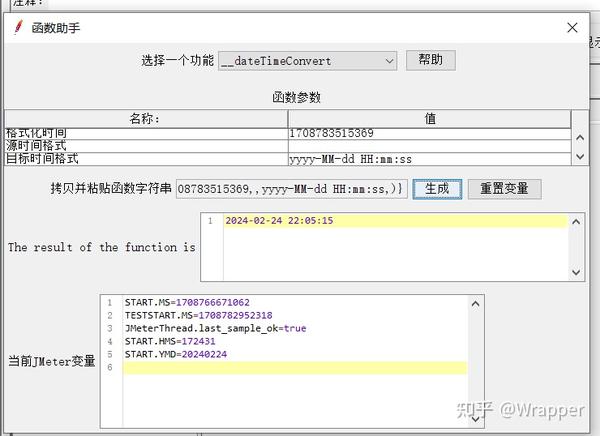
2.2 ${__dateTimeConvert(,,,)} 时间转换
使用与可以将时间戳转换成时间:
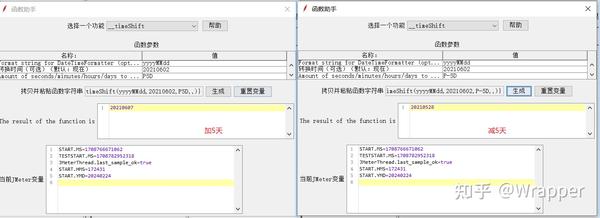
2.3 ${__timeShift(,,,,)} 时间偏移
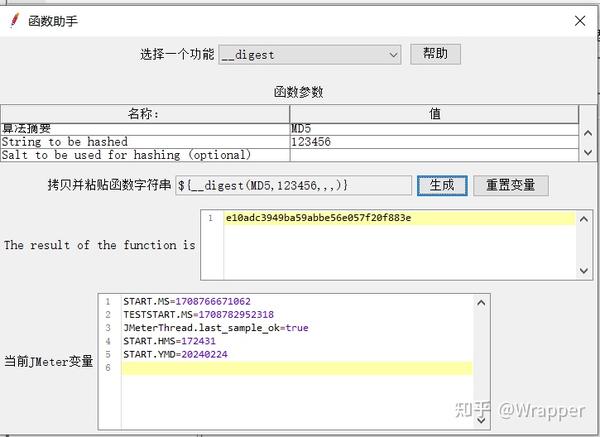
3.加密函数${__digest(,,,,)}
注意:这个加密函数 只能做简单的加密;
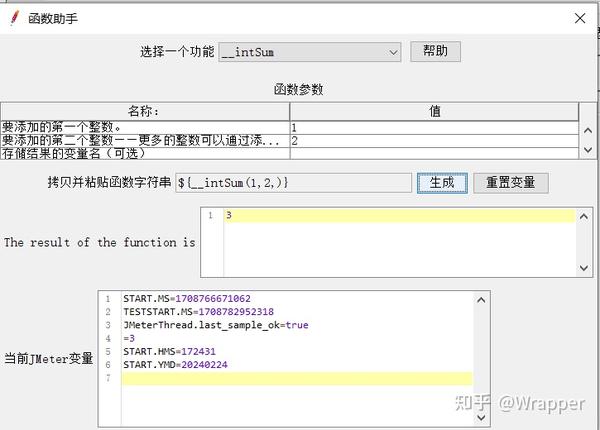
4. 整数相加${__intSum(,,)}
这个函数只能做整数相加
5.属性函数,${__P(,)}、${__property(,,)}、${__setProperty(,,)}
动态属性,是在运行过程中产生的,关闭jmeter,就是自动释放了
属性是jmeter工具具有,jmeter中的线程组要使用属性,都可以使用。可以跨线程组了。
设置jmeter的动态属性,主要是为了跨线程组定义参数;
实际设置属性操作:
1.线程组1,先使用调试取样器,挂一个前置处理的的用户参数,定义一个局部变量:
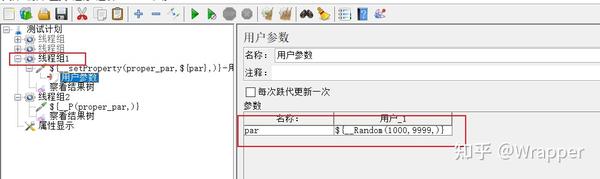
2.将par设置成属性:
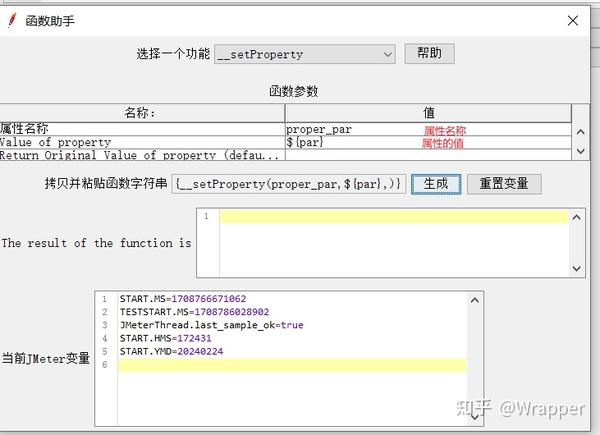
3.在线程组2读取属性proper_par:
读取属性有函数${__P(,)} 、${__property(,,)} 这2个函数意义相同没有区别。
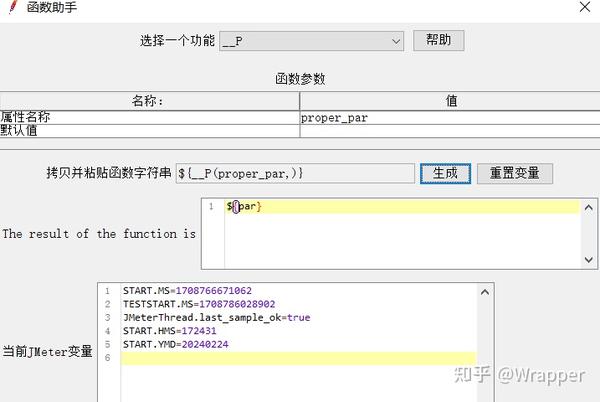
线程组2可以使用调试取样器测试,就可以取到这个属性了:

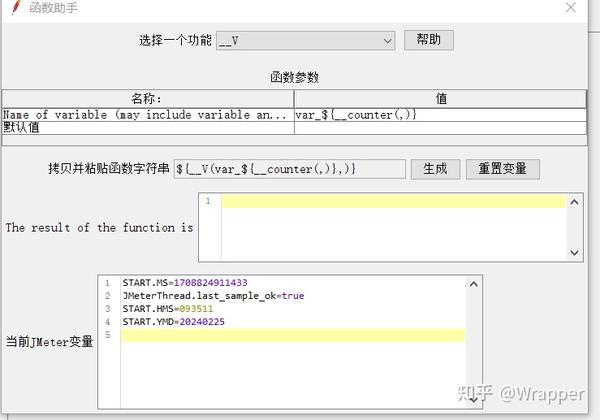
6.V函数
举例说明:
1.取样器下定义了3个用户变量要当做入参的手机号:
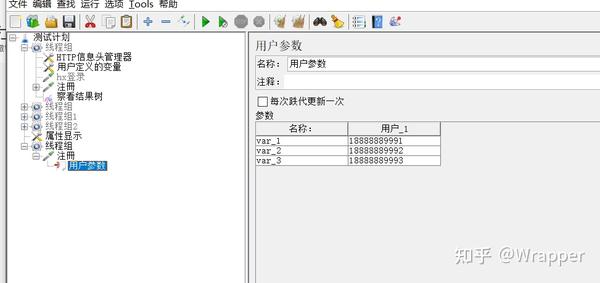
2.此时就可以使用,V函数将var_和计数器函数拼接起来,当做手机号入参的value:
${__V(前缀_可变后缀)} = 得到是这个 “前缀_可变后缀” 变量名值

三、获取响应数据
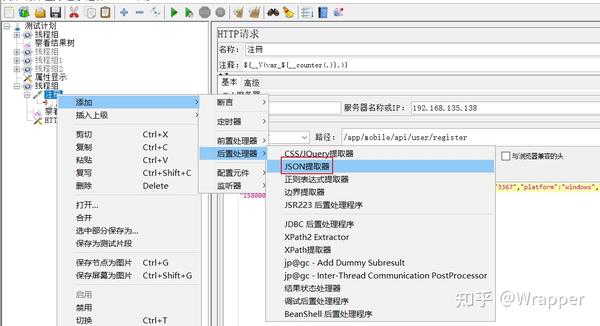
1.json提取器
1.1添加json提取器的位置:在取样器上右键 > 后置处理器 > json提取器
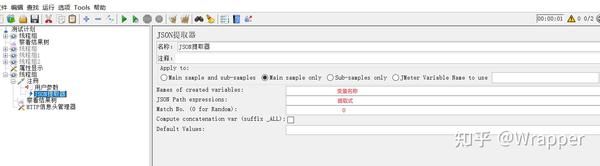
注意:Match.No是获取第几个该字段的值,如果是0就是随机一个,如果要获取的所有该字段的值写-1,如果获取具体某一个只需写具体数值。
1.2举例说明:
{
"msg": "成功调用",
"code": 0,
"data": {
"pmoney": 100.0,
"createtime": 1708827844213,
"sex": 1,
"mobile": "18888889992",
"token": "tRUcARYUf+yYdsXjtAhuBTSMHlUaqTkMv0CA7HxezU\/hqZpq7g9fDZ\/n96CFBLtNxRU\/jxaEwo\/fQbjJJq9BrA==",
"lasttime": 1708827844213,
"money": 0.0,
"gqid": "4000001",
"identity": "1d65cb3e94ac22ae",
"id": 180714,
"age": 20,
"email": "158000000011@test.com",
"username": "test11"
}
}提取上方数据中的gqid字段:(两种写法)
- $.根路径.二级路径 json提取式 ----绝对路径写法
- $..末梢节点名称 -----相对路径写法, 推荐
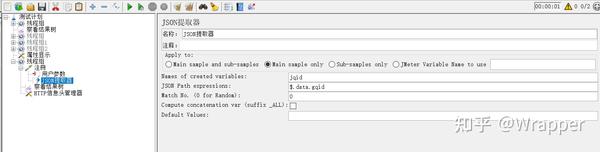
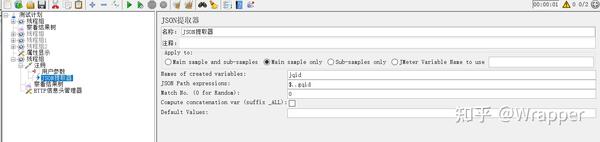
1.3 json获取多个值
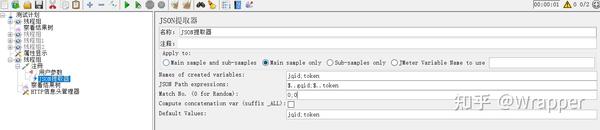
变量名、提取式 要用英文的;号分隔。
注意:Default Values要写上默认值。
2.正则提取器
2.添加正则提取器的位置:在取样器上右键 > 后置处理器 > 正则提取器
正则提取式: 左边界(正则式)右边界, 万能正则式: .*?
.*?的正则式除换行符之外,都可以匹配
举例说明:
{
"msg": "成功调用",
"code": 0,
"data": {
"pmoney": 100.0,
"createtime": 1708827844213,
"sex": 1,
"mobile": "18888889992",
"token": "tRUcARYUf+yYdsXjtAhuBTSMHlUaqTkMv0CA7HxezU\/hqZpq7g9fDZ\/n96CFBLtNxRU\/jxaEwo\/fQbjJJq9BrA==",
"lasttime": 1708827844213,
"money": 0.0,
"gqid": "4000001",
"identity": "1d65cb3e94ac22ae",
"id": 180714,
"age": 20,
"email": "158000000011@test.com",
"username": "test11"
}
}获取以上响应的token:
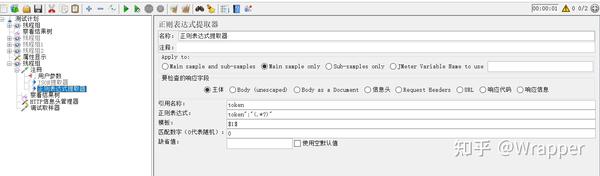
四、DDT数据驱动测试
位置:线程组-->配置元件-->CSV数据文件设置
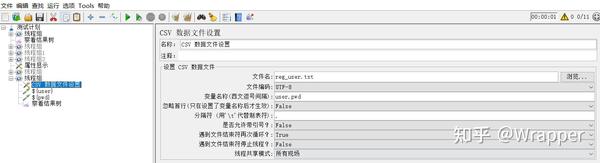
1.文件名称
可以是txt、csv等文本文件,都可以,但是,我们推荐使用txt,能不用csv,就不用csv。
- 获取速度 txt相对要快
- 编码:txt文件,默认编码,utf8; csv文件,默认编码,不是utf8
- 遇到jmeter读取csv文件内容,乱码问题:
- 原因:csv的编码不是utf8,而csv数据文件设置中,选择了utf8,导致编码不一致。
- 解决:把csv文件,用记事本打开,选择编码为utf8保存
2.设置介绍
变量名称: 可以写多个,多个之间用“,” 固定使用逗号;
是否允许带引号: 一对英文双引号;
遇到文件结束符再次循环:
- rue: 运行次数超过总数量行数时,会从头开始取值
- False:运行次数超过总数量行数时,还会继续运行,但是取不到值
- 管理取值的情况
遇到文件结束符停止线程:管理运行状态;
分隔符:文档内的分隔符号,建议使用英文的逗号;
3.须知内容:
使用csv数据文件设置,默认配置的情况下,当多用并发时:
-
- 第1thead,第一次取值,取第1行;
- 第2thead,第一次取值,取第2行;
- 第3thead,第一次取值,取第3行;
五、逻辑控制器
性能测试脚本中,会使用逻辑控制器,但是,使用了逻辑控制器,并不是混合场景。
1.循环控制器、foreach控制器
循环控制器:常用在 重复运行多次
foreach控制器:常用于,使用 带有 _ 下滑线变量引用
2.if 条件控制器
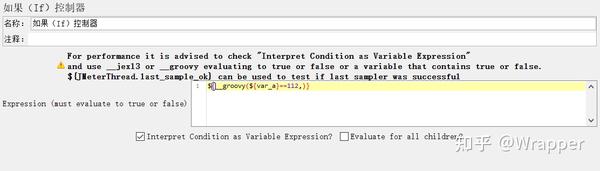
默认的情况下, 勾选了条件框中,要使用 __jexl3 or __groovy 函数的计算结果为true,false;
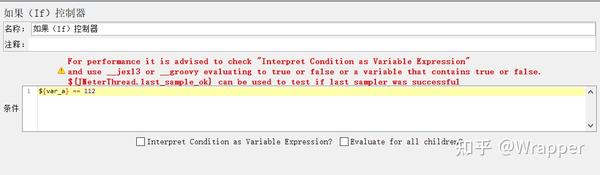
如果不勾选 Interpret condition as variable express 是把 条件框中的 表达式 当做js脚本,进行计算,计算的结果为真,则执行下面请求
六、事务控制器
- 在jmeter中,默认一个取样器,就是一个事务;
- 事务控制器,控制其子集取样器(n),合并为一个事务
- 事务: TPS 服务器每秒处理的事务数
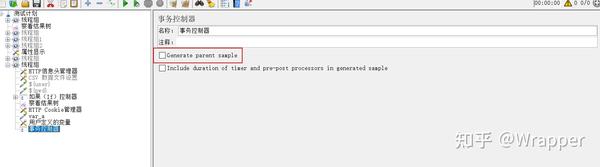
- 在事务控制器下,挂载多个取样器,想要把多个取样器合并为1个事务,必须勾选“Generate parent sample”
七、聚合报告\汇总报告
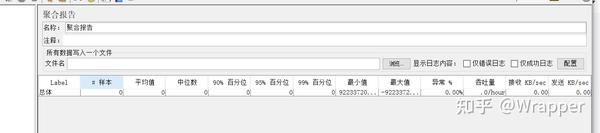
在性能测试中,看聚合报告,有前提条件:
- 1、没有网络瓶颈
- 在很多时候,我们在看聚合报告时,会把 吞吐量的值 等价为 TPS的值,其实是不对的。
- 怎么判断有没有网络瓶颈?
- 1.聚合报告最后两列,是 吞吐率,每秒传输多少KB的数据。
- 2.吞吐率 与我们的带宽是有关系, 吞吐率,是可以看出是否存在网络带宽问题?
- 带宽:100Mb = 100 * 1024kb = 102400kb /8 = 12800KB (b 和 B 是8倍的关系)
- 理论上百兆带宽,每秒不超12800KB传输的数据 就没有网络瓶颈。
- 2、并发用户数不变
- 负载测试时,并发用户数会随着时间变化,而变化,就不能看聚合报告。
- 因为吞吐量是个平均值,用户变化时,在用平均值就不行了,得到的结果无法看到当时并发量的TPS。
聚合报告含义:
每一行数据:都是一种事务;
样本:在请求的过程中,所有的并发用户数,在一段时间中的总请求量;
- 单独看样本,是无法知道并发用户数、执行时长 ;
- 例如样本 = 472 , 10个并发数, 10人 * 60秒 * 频率 = 472 频率= 0.78 ,也就是每个用户每秒钟发送0.78个吞吐量
- 平均值、中位数、90%百分位...........最小值、最大值: 这些都是响应时间, 它们单位是 毫秒ms
- 90%百分位:所有的样本中,有90%的样本时间是小于等于这个时间的。 这个具有参考价值。
八、临界控制器Critical Section Controller

- 严格控制请求顺序
- 锁名称: 默认是一个固定锁名称
- 相当于把性能测试中的并行执行,强制转换为 串行
九、仅一次控制器Once Only Controller
仅一次控制器: 意思是,一个线程用户只执行一次
- 并发用户是10,不管你设置循环多少次,其下挂载的取样器,每个都只会执行10次
- 并发用户是10,不管你运行多长时间,其下挂载的取样器,每个都只会执行10次
十、DDT驱动数据驱动(二)
1.使用方法: jmeter + sqlite
jmeter的lib目录安装sqlite-jdbc-3.31.1.jar 包
2.使用步骤
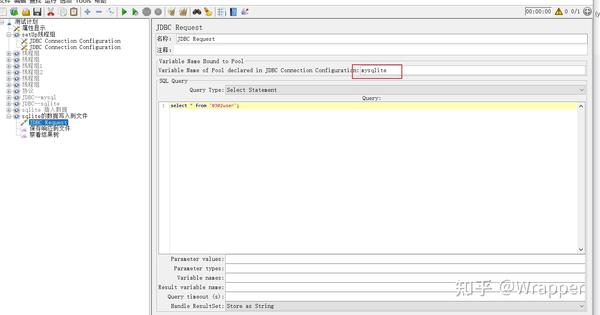
- 2.1 首先使用jmeter的jdbc request 查询mysql数据库的数据;
- 2.2 查询数据结果定义成变量;
- 2.3 使用jmeter的jdbc request 创建sqlite的文件;
- 2.4 使用jmeter的jdbc request 对sqlite数据库文件创建一个表;
- 2.5 使用jmeter的jdbc request 将myslq的查询结果变量,通过循环控制器逐条插入到sqlite的表中;
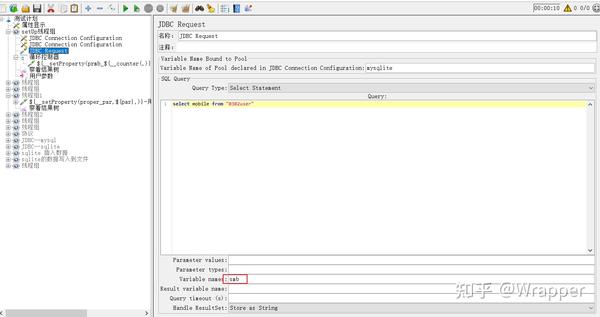
- 2.6 再次查询sqlite的表中 ,将数据写入到用户属性内,后续取参数直接取属性了
3.操作截图
1.链接mysql配置
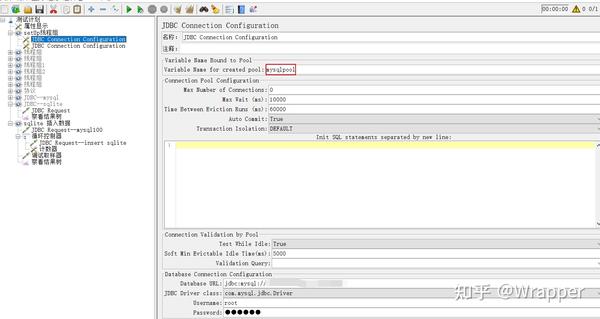
2.链接sqlite配置
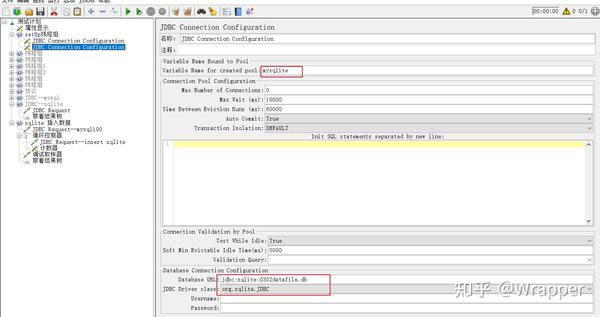
3.sqlite数据库创建表0302user
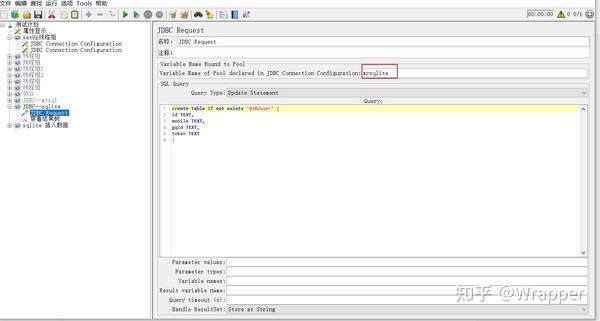
4.查询mysql数据的结果定义成变量
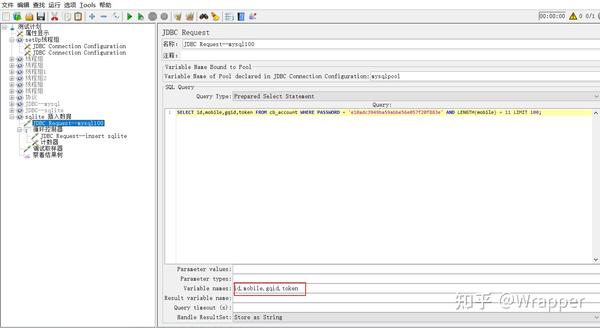
5.通过循环控制器+计数器 对sqlite表插入数据
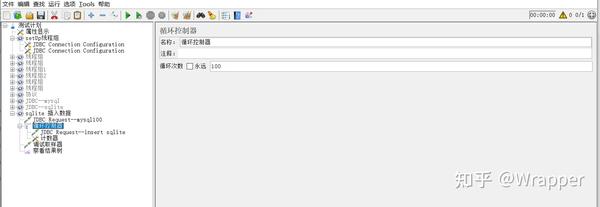
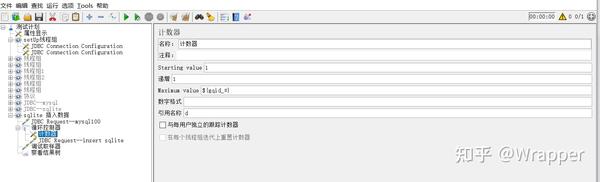
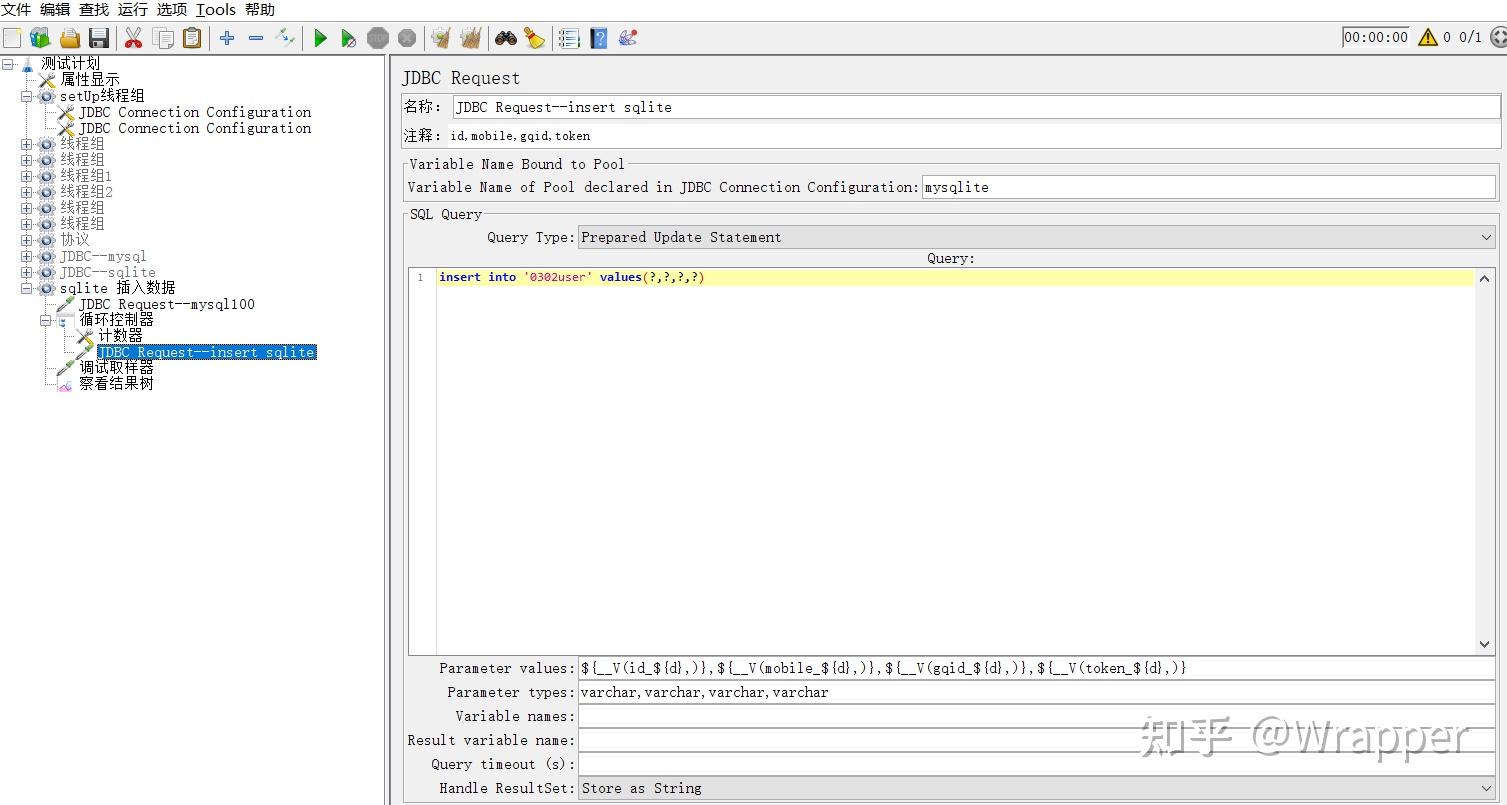
6.再次查询sqlit内的数据,将数据写入到用户属性内
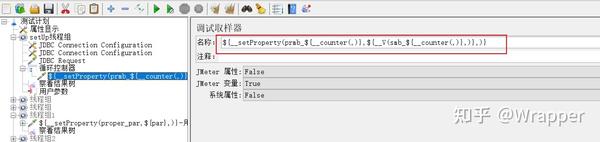
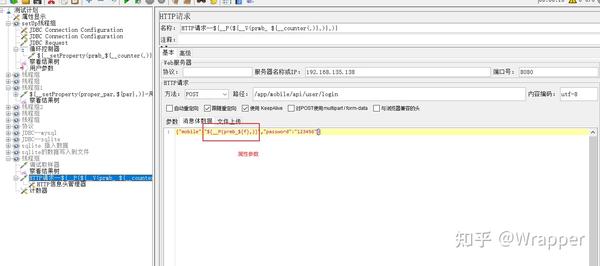
7.小功能:可以将插入到sqlite中的数据保存到txt文件
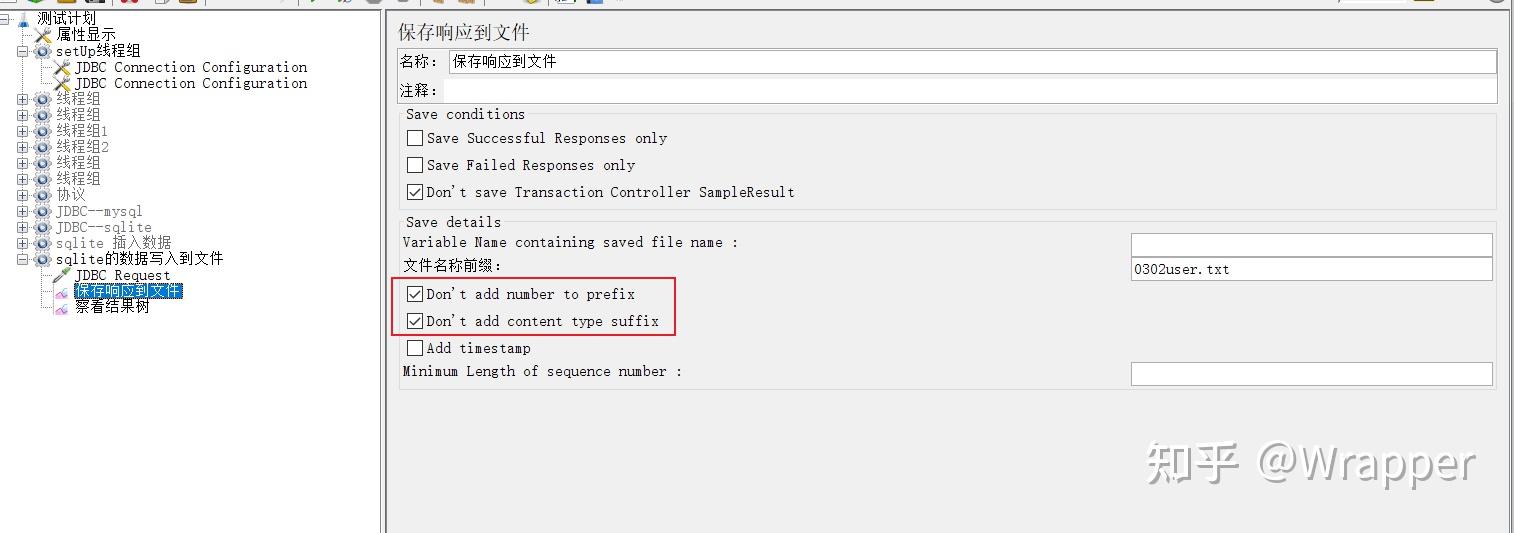
加一个 保存详情到问文件的监听器
- 填写文件名称前缀
- 勾选: Don't add number to prefix
- 勾选: Don't add content type suffix