MySQL存储结构
1 什么是表空间⽂件?
解答问题
- 表空间⽂件是⽤来存储表中数据的⽂件,表空间⽂件的⼤⼩由存储的数据多少决定,不同的表空间⽂件存储数据的种类也有所不同,在MySQL中表空间分为五类,包括:系统表空间、独⽴表空间、通⽤表空间、临时表空间和撤销表空间,这些在上⾯的InnoDB架构图中都有体现。
1.1 表空间与表空间⽂件的关系是什么?
- 表空间可以理解为MYSQL为了管理数据⽽设计的⼀种数据结构,主要描述的对结构的定义,表空间⽂件是对定义的具体实现,以⽂件的形式存在于磁盘上
2 ⽤⼾数据在表空间中是怎么存储的?
分析过程
- ⾸先明确⼀点,⽤⼾的数据以数据⾏的⽅式存储在对应的表空间⽂件中,那么表空间中很多个数据⾏就需要进⾏管理,以便后续进⾏⾼效的查询;
- 为了⽅便管理,表空间由段 (segment)、区组(group)、区 (extent)、⻚ (page) 、数据⾏组成,其中⻚是 InnoDB 磁盘管理的最⼩单位;
解答问题
- 可以这么理解,若⼲数据⾏组成了⻚,多个⻚组成了区,多区组成了区组,多个区组组成了段,多个段组成了表空间。
3 为什么要使⽤⻚这个数据管理单元?
分析过程
-
⾸先要明确⼀点,MySQL中的⻚是应⽤层的⼀个概念,是MySQL根据⾃⾝的应⽤场景,定义的⼀种数据结构
-
通常操作系统中的⽂件系统在管理磁盘⽂件时以4KB⼤⼩为⼀个管理单元,称为"数据块",但是在数据库的应⽤场景⾥,查询时数据量都⽐较⼤,如果也使⽤4KB做数据存储的最⼩的单元,就显的有点⼩了,同时会造成频繁的磁盘I/O,导致降低效率;
-
所以MySQL根据⾃⾝情况定义了⼤⼩为16KB的⻚,做为磁盘管理的最⼩单位;
-
每次内存与磁盘的交互⾄少读取⼀⻚,所以在磁盘中每个⻚内部的地址都是连续的,之所以这样做,是因为在使⽤数据的过程中,根据局部性原理,将来要使⽤的数据⼤概率与当前访问的数据在空间上是临近的,所以⼀次从磁盘中读取⼀⻚的数据放⼊内存中,当下次查询的数据还在这个⻚中时就可以从内存中直接读取,从⽽减少磁盘I/O,提⾼性能
解答问题
MySQL根据⾃⾝的应⽤场景使⽤⻚做为数据管理单元,最主要的⽬的就是减少磁盘I/O,提⾼性能。
3.1 什么是局部性原理?
局部性原理是指程序在执⾏时呈现出局部性规律,在⼀段时间内,整个程序的执⾏仅限于程序中的某⼀部分。相应地,执⾏所访问的存储空间也局限于某个内存区域,局部性通常有两种形式:时间局部性和空间局部性。
时间局部性(Temporal Locality):如果⼀个信息项正在被访问,那么在近期它很可能还会被再次访问。
空间局部性(Spatial Locality):将来要⽤到的信息⼤概率与正在使⽤的信息在空间地址上是临近的。
4 数据⻚有哪些基本特性是必须要掌握的? - ⻚
解答问题
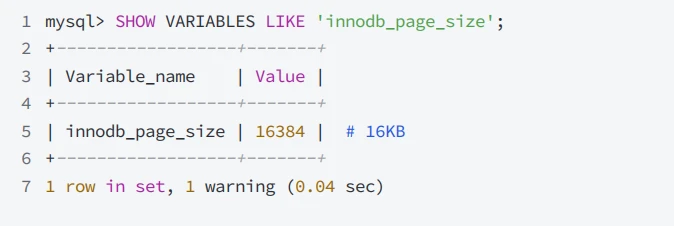
- ⻚的16KB的⼤⼩是MySQL的⼀个默认设置,可以适⽤于⼤多数场景,当然也可以根据⾃⼰的实际业务场景进⾏修改⻚的⼤⼩,通过系统变量 innodb_page_size 进⾏调整与查看,在调整⻚⼤⼩的时候需要保证设置的值是操作系统"数据块" 4KB的整数倍,从⽽保证通过操作系统和磁盘交互时"数据块"的完整性,不被分割或浪费,所以规定了 innodb_page_size 可以设置的值,分别是 4096 、 8192 、 16384 、 32768 、 65536 ,对应 4KB 、 8KB 、 16KB 、 32KB 、64KB ;
- 每⼀个⻚中即使没有数据也会使⽤ 16KB 的存储空间,同时与索引的B+树中的节点对应,后续在索引专题中详细讲解B+树的内容,查看⻚的⼤⼩,可以通过系统变量 innodb_page_size 查看
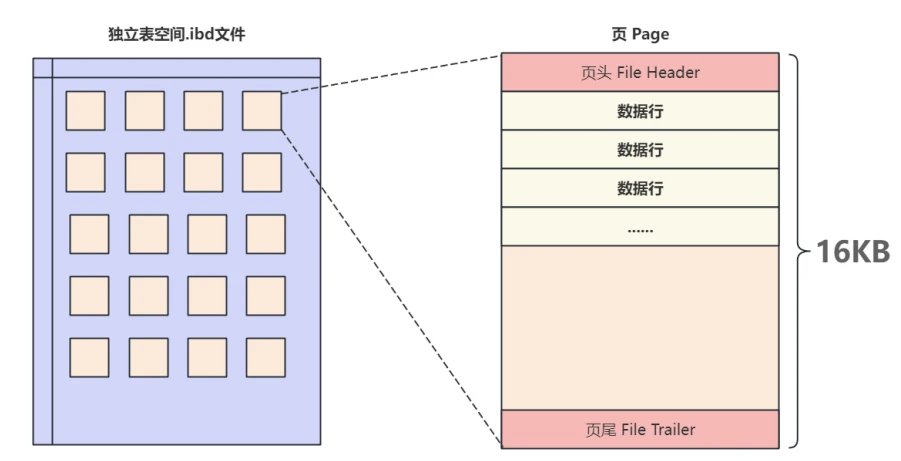
- 在不同的使⽤场景中,⻚的结构也有所不同,在MySQL中有多种不同类型的⻚,但不论哪种类型的⻚都会包含⻚头(File Header)和⻚尾(File Trailer),在这⻚头和⻚尾之间的⻚主体信息根据不同的类型有不同的结构,最常⽤的就是⽤来存储数据和索引的"索引⻚",也叫做"数据⻚",⻚的主体信息使⽤数据"⾏"进⾏填充,⾏的结构我们在下⾯的章节中进⾏详细介绍,⻚的基本结构如下图所⽰:
5 查询的数据超过⼀⻚的⼤⼩,怎么提⾼查询效率 ?区
前置知识
要解答这个问题,我们先要弄明⽩前置的⼏个⼩问题,⾸先通过前⾯的内容,我们了解到磁盘中每个⻚内部的地址都是连续的,那么我们可以继续提问:
-
不同的⻚在磁盘中是不是连续的?
-
如果⻚不连续对访问效率是否有影响?
-
InnoDB如何保证⻚在磁盘中的连续性?
解决以上三个⼩问题之后当前的问题⾃然也就解决了,我们接着往下看。
分析过程
5.1 不同的⻚在磁盘中是不是连续的呢?
- 答案是不⼀定,在不做任何控制的情况下,不同⻚在磁盘中申请的地址⼤概率是不连续的。
- 我们可以很快的分析出来连续的地址对查询效率的影响,如果⻚在磁盘中可以被连续读取,那么查询效率就⾼,否则果询效率就低。
5.2 为什么不连续的地址会降低查询的效率?
- 当存储介质是机械硬盘时,访问不连续的地址会带来磁盘寻址的开销,也就是磁头在不同盘⾯、磁道和扇区的机械转动,这个过程称为磁盘随机访问,⾮常影响效率,磁盘结构如下图所⽰:
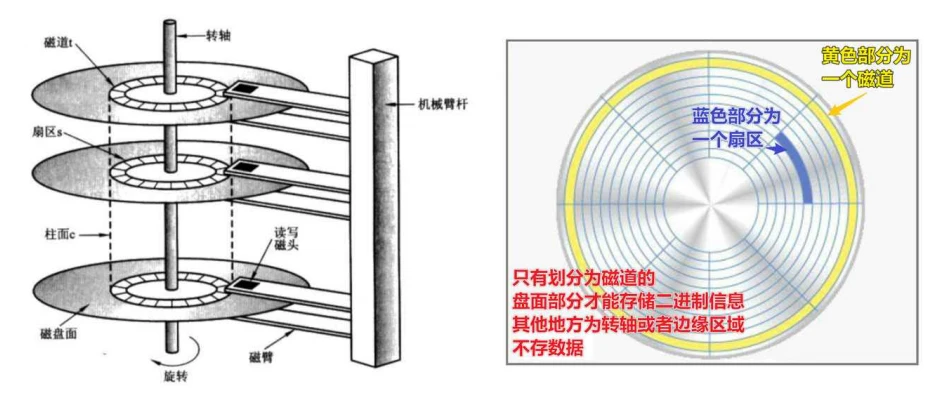
- 经过以上的分析,当查询的数据⼤于⼀⻚时不加任何控制会产⽣磁盘随机访问,这个是影响查询效率的主要因素,那么现在怎么提⾼查询效率的问题就变成了,⻚在磁盘中是否连续的问题,我们换个问法。
5.3 InnoDB如何保证⻚在磁盘中的连续性?
- 为了解决磁盘随机访问⾮常低效的问题,需要尽可能在磁道上读取连续的数据,减少磁头的移动,从⽽提升效率,MySQL使⽤ Extent(区) 这个结构来管理⻚,规定每个区固定⼤⼩为 1MB ,可以存放 64 个⻚,这时如果跨⻚读数据时,⼤概率都在附近的地址,可以⼤幅减少碰头移动;
提⽰:我们学习的主要是解决问题的思路,⼤家要搞懂为什么要有区以及区解决了什么问题,⾄于区的固定⼤⼩不⽤刻意去记,现阶段是1MB,以后的版本会不会改变也说不好。
- 同时,如果频繁的读取某个区中的⻚,可以把整个区都读取出来放⼊内存中,减少后续查询对磁盘的访问次数,进⼀步提升效率,如图所⽰
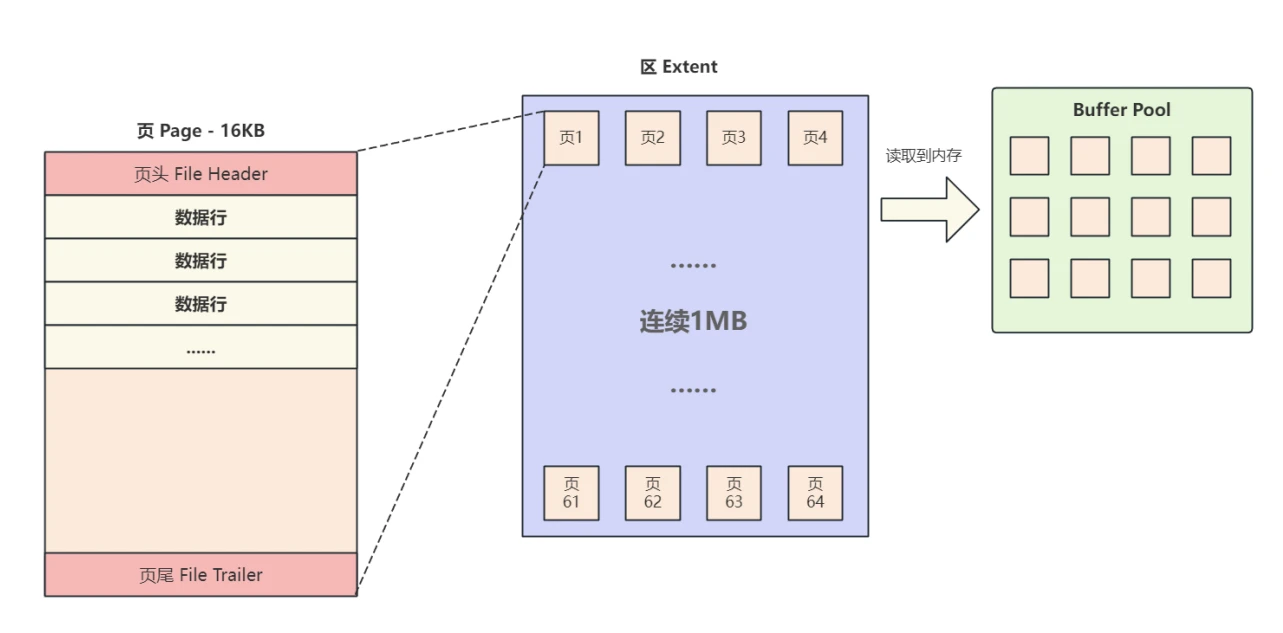
解答问题
- 通过对问题的分析,我们了解到InnoDB中⽤来组织⻚的数据结构–区,并且每个区固定⼤⼩为1MB ,可以包含64个连续的⻚,查询的数据超过⼀⻚⼤⼩时,可能会有以下⼏种情况:
a. ⻚在区内是相邻的:磁盘顺序I/O,可以⼤幅提升效率
b. ⻚在区内但不是相邻的:可以⼤幅减少碰头移动,可以提升效率
c. ⻚在不同的区:还是要发⽣随机I/O,不能提升效率
衍⽣问题
- 那么⼜有⼀个问题来了,新创建表时没有数据,或者说有的表只有很少的数据,1MB的空间⽤不完,那不是就存在空间浪费的问题吗?
是的,的确是这样,InnoDB在设计时也考虑到了这个问题,我们继续提出问题,然后再来解决。

6 当表中的数据很少时如何避免空间浪费?
分析过程
- 当创建表时,并不知道当前表的数据量级
- 为了节省空间,最初只创建7个初始⻚(在MySQL5.7中创建6个初始⻚),⽽不是⼀个完整的区,可以通过以下SQL查看:

- 这些零散⻚会放在表空间中⼀个叫碎⽚区的区域,随着数据量的增加,会申请新的⻚来存储数据,当碎⽚区达到32个⻚的时候,后续每次都会申请⼀个完整的区来存储更多的数据;
解答问题
- 通过零散⻚和碎⽚区避免空间浪费的问题
7 如果访问的数据跨区了怎么办?区组
分析过程
- 不同的区在磁盘上⼤概率是不连续的,那么这个问题其实是InnoDB如何⾼效的的管理区?
- 当表中的数据越来越多,为了有效的管理区,定义了区组的结构,每个区组固定管理256个区即256MB ,通过区组可以在物理结构层⾯⾮常⾼效的管理和定位到每个区
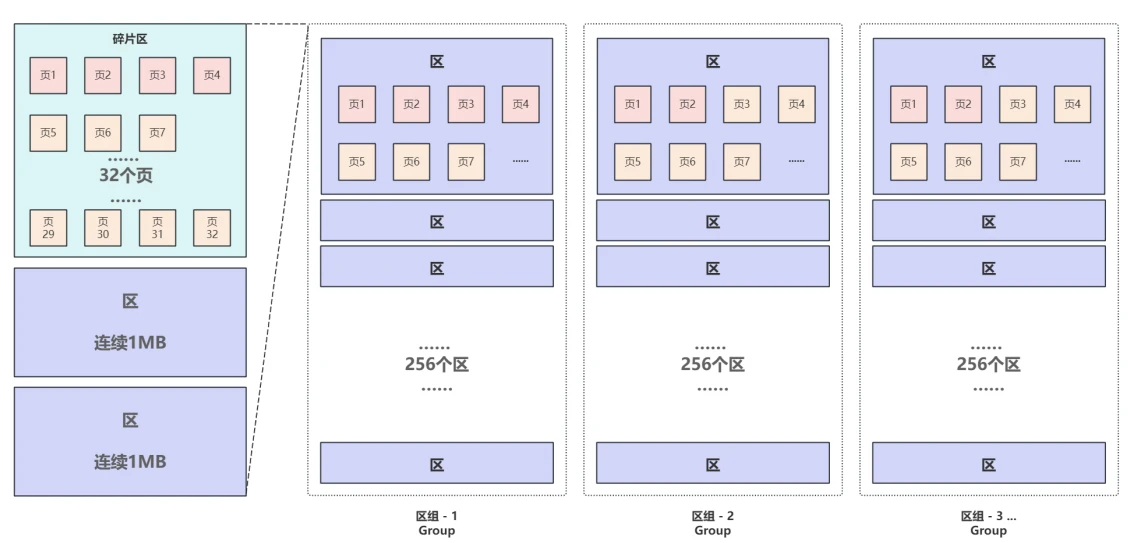
- 第⼀个区组中的⾸个区的前四⻚⽐特殊,也就是初始⻚中的前4⻚,分别是:
- File Space Header: 表空间和区组中条⽬信息
- Insert Buffer Bitmap:Change Buffer相关信息
- File Segment inode: 段信息
- B-tree Node:索引根信息
- 其他为空闲⻚⽤来存储真实的数据
- 其他区组中⾸个区的结构都⼀样,前两个⻚分别是:
- Extent Descriptor(XDES):区组条⽬信息
- Insert Buffer Bitmap:Change Buffer相关信息
解答问题
使⽤区组结构有效的管理区,每个区组固定管理256个区即 256MB ,区组条⽬信息中会记录每个区的偏移并⽤双向链表连接。
8 以上这些数据结构还有优化的空间吗?段
分析过程
-
以上讲到的区、区组还有⻚这种都是物理结构
-
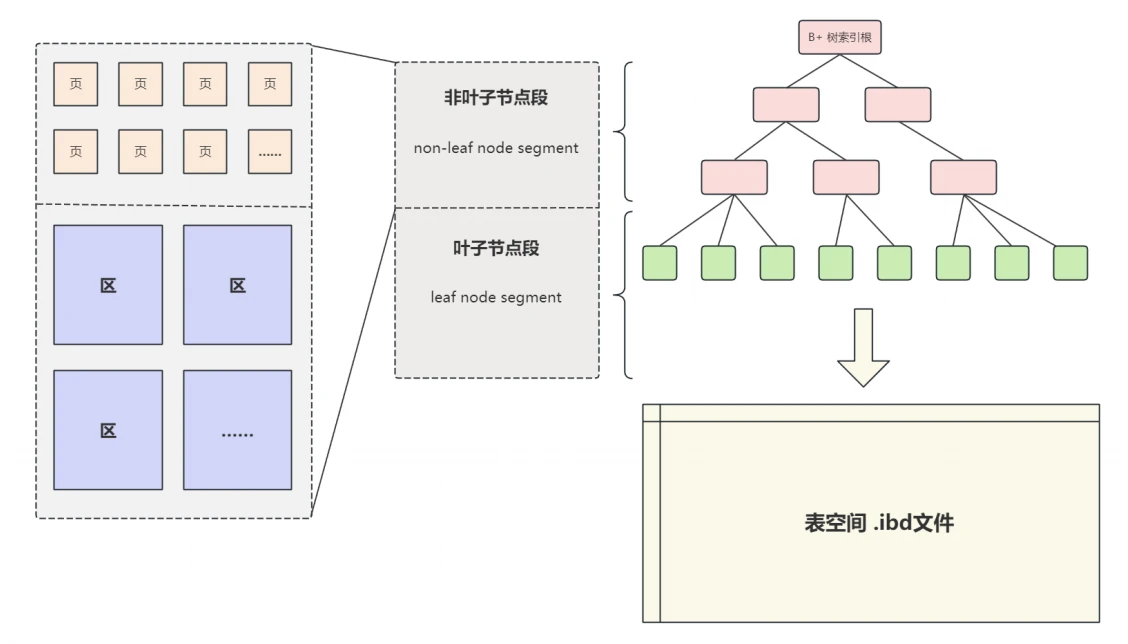
在物理结构的基础上,定义了⼀个逻辑上的概念,也就是"段";
- “段"并不对应表空间中的连续的物理区域,可以看做是 “区” 和 “⻚” 的⼀个附加标注信息,段的主要作⽤是区分不同功能的区和在碎⽚区中的⻚,主要分为"叶⼦节点段"和"⾮叶⼦节点段"等,这两个段和我们常说的B+树索引中的叶⼦、⾮叶⼦节点对应,可以简单的理解为"⾮叶⼦节点段” 存储和管理索引树,"叶⼦节点段"存储和管理实际数据,从逻辑上讲,最终由 “叶⼦节点段” 和 “⾮叶⼦节点段” 等段构成了表空间 .ibd ⽂件,如下图所⽰:
解答问题
- 当然是有的,InnoDB使⽤"段"这个逻辑结构区分不同功能的区和在碎⽚区中的⻚,并按功能分为"叶⼦节点段"和"⾮叶⼦节点段",做为B+树索引中的叶⼦、⾮叶⼦节点,从⽽进⼀步提升查询效率。
8.1 上⾯讲的所有操作是在哪⾥进⾏的?
- 所有的数据库操作都是在内存中进⾏的,最终会把修改结果刷回磁盘中对应的⻚中。
8.2 查询数据时MySQL会⼀次把表空间中的数据全部加载到内存吗?
- 当然不是,使⽤InnoDB存储引擎创建表,在查询数据时会根据表空间内部定义的数据结构(⼀般为索引),定位到⽬标数据⾏所在的⻚,只把符合查询要求的⻚加载到内存。
8.3 每查询⼀条数据都要进⾏⼀次磁盘I/O吗?
- 不⼀定,每次查询都会把磁盘中数据⾏对应的数据⻚加载到内存中,如果当前查询的数据⾏已经在内存中,则直接从内存中返回结果,从⽽提⾼查询效率

可以看到⻚这个结构在MySQL运⾏的过程中起到了⾮常重要的作⽤.