文章目录
- 1. 准备数据文件
- 2. 文件上传到HDFS指定目录
- 2.1 创建HDFS目录
- 2.2 上传文件到HDFS
- 2.3 查看上传的文件
- 3. 运行词频统计程序的jar包
- 3.1 查看Hadoop自带示例jar包
- 3.2 运行示例jar包里的词频统计
- 4. 查看词频统计结果
- 5. 在HDFS集群UI界面查看结果文件
- 6. 在YARN集群UI界面查看程序运行状态
- 7. 失败状态原因分析与解决

1. 准备数据文件
首先,我们需要在Hadoop集群的主节点上准备数据文件,用于词频统计MapReduce作业。
- 在master云主机上创建一个名为
test.txt的文件。
2. 文件上传到HDFS指定目录
接下来,我们将本地文件系统上的数据文件上传到HDFS的指定目录。
2.1 创建HDFS目录
- 执行命令:
hdfs dfs -mkdir -p /wordcount/input来创建HDFS目录。
2.2 上传文件到HDFS
- 执行命令:
hdfs dfs -put test.txt /wordcount/input来上传文件。
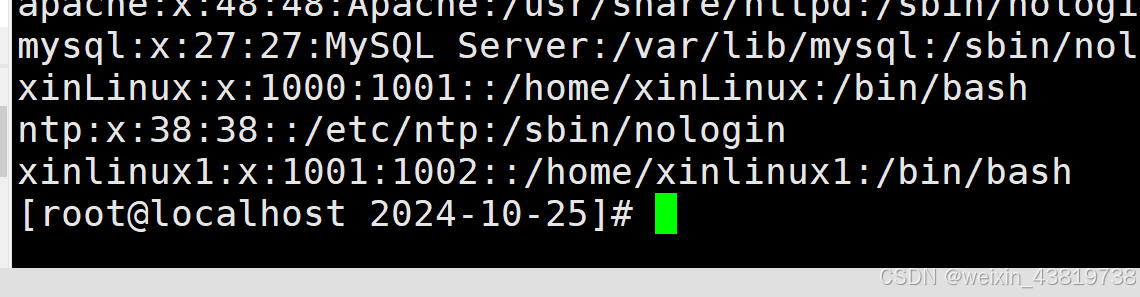
2.3 查看上传的文件
- 执行命令:
hdfs dfs -ls /wordcount/input来查看目录中的文件。 - 执行命令:
hdfs dfs -cat /wordcount/input/test.txt来查看文件内容。 - 也可以通过Hadoop WebUI界面来查看文件。
3. 运行词频统计程序的jar包
我们将使用Hadoop自带的示例jar包来运行词频统计程序。
3.1 查看Hadoop自带示例jar包
- 切换到MR示例目录:执行命令
cd $HADOOP_HOME/share/hadoop/mapreduce。 - 列出目录信息:执行命令
ls。 - 找到示例程序jar包:
hadoop-mapreduce-examples-3.3.4.jar。
3.2 运行示例jar包里的词频统计
- 执行命令:
hadoop jar ./hadoop-mapreduce-examples-3.3.4.jar wordcount /wordcount/input/test.txt /wordcount/output来运行词频统计程序。
4. 查看词频统计结果
- 执行命令:
hdfs dfs -ls /wordcount/output来查看结果文件。 - 执行命令:
hdfs dfs -cat /wordcount/output/*来查看词频统计的结果内容。
5. 在HDFS集群UI界面查看结果文件
- 通过HDFS集群UI界面查看
/wordcount/output目录下的文件。
6. 在YARN集群UI界面查看程序运行状态
- 在浏览器中访问
http://master:8088来查看YARN集群的界面。 - 观察应用程序的运行状态,例如
application_1728606339394_0001。
7. 失败状态原因分析与解决
如果作业失败,可能是因为 mapred-site.xml 文件中没有配置必要的环境变量。
- 配置必要的环境变量:
<configuration> <!-- 配置项 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.4</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.4</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.4</value> </property> </configuration> - 修改配置后,需要将配置分发到所有节点,并重启Hadoop服务。
通过以上步骤,我们完成了一个词频统计的MapReduce作业,从准备数据到运行作业,再到查看结果。这个过程展示了Hadoop MapReduce作业的基本流程和一些常见的配置问题及其解决方法。