本教程讲解如何将AWS S3中的数据迁移到阿里云对象存储OSS。
如果您需要将AWS S3中的数据通过专线迁移到阿里云对象存储OSS,请参见使用代理迁移。
概述
阿里云在线迁移服务是阿里云提供的存储产品数据通道。使用在线迁移服务,您可以将第三方数据轻松迁移至阿里云对象存储OSS,也可以在对象存储OSS之间进行灵活的数据迁移。
使用在线迁移服务,您只需在控制台填写源数据地址和目的OSS地址信息,并创建迁移任务即可。启动迁移后,您可以通过控制台管理迁移任务,查看迁移进度、流量等信息。
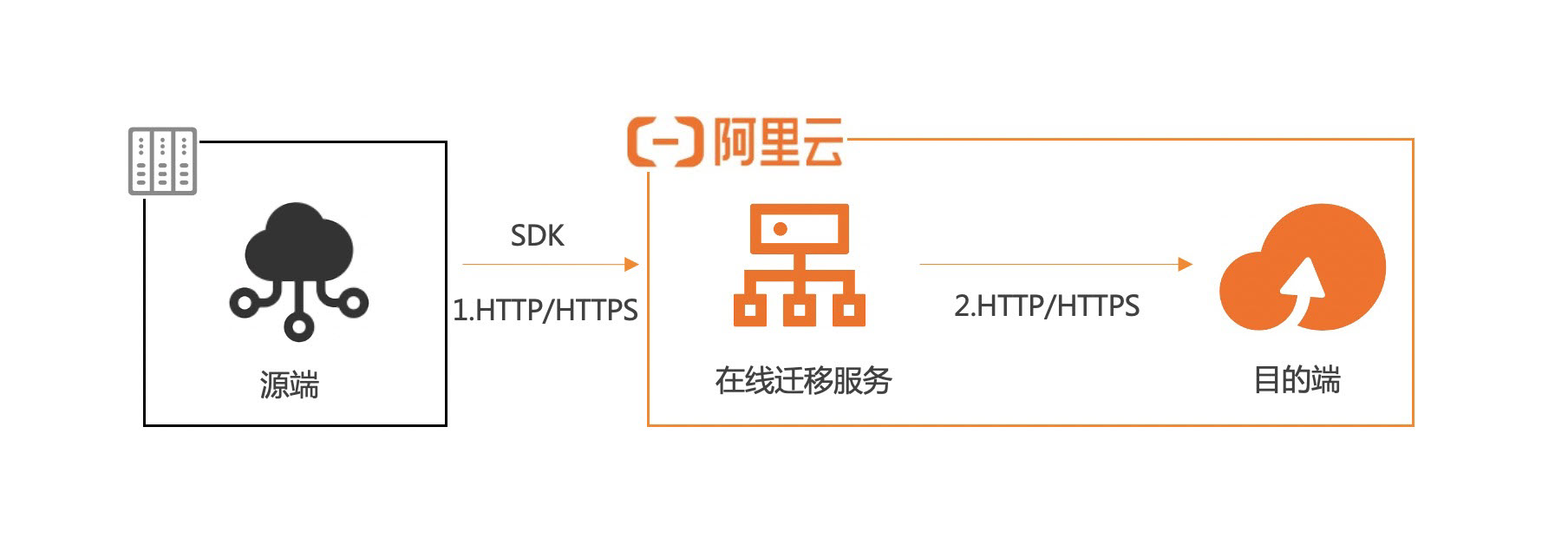
流程图
迁移流程
迁移流程如下图所示:
-
出于数据安全性和一致性考虑,建议您使用HTTPS。
-
在迁移任务完成后,请您务必自行做好源端和目的端数据一致性校验。
更多详情,请参见闪电立方服务协议。
警告
请您务必在迁移任务完成后,校验目的端迁移数据。您在删除源数据前,未校验目的端迁移数据无误,导致数据丢失所引起的一切损失和后果均由您自行承担。
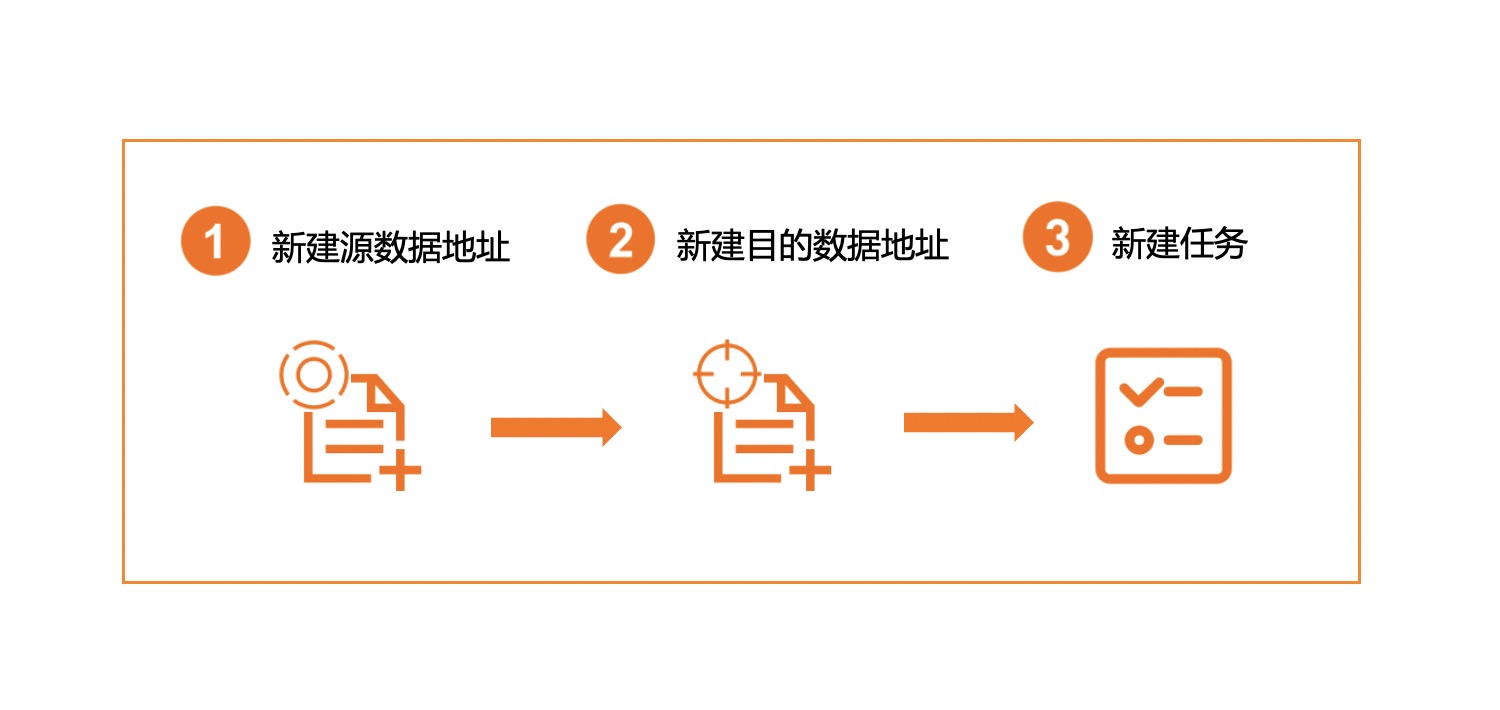
创建迁移任务流程
创建迁移任务流程如下图所示:
重要
执行在线迁移任务过程中,读取源站数据会产生公网流出流量费,该费用由源站的存储服务提供商在源站收取。
准备工作
介绍数据迁移之前的准备工作。
步骤一:解冻源存储空间待迁移数据
当您源端为归档类型的数据,迁移前需要您提前进行解冻操作,待解冻完成后再创建迁移任务,解冻时请注意如下事项:
-
请您务必完成解冻操作后再创建源数据地址和迁移任务。
-
请您根据待迁移的数据总量确保解冻时长,以防迁移期间数据再次变成冻结状态。
-
解冻操作会收取数据取回的费用,部分解冻服务收费较高。具体计费规则可咨询您的源端存储服务提供商。
说明
在线迁移服务并不会对源端数据执行解冻操作。若您源端有未解冻、解冻中的文件,则这些文件都会迁移失败。
AWS S3解冻文件的操作步骤,请参见恢复已归档的对象。
重要
链接文档仅供参考,由于源站变更,文档可能已经过时。
步骤二:创建用于迁移数据的IAM用户
为了保证数据安全,推荐您创建IAM用户并授予其读取源数据的权限,然后创建访问密钥。具体操作,请参见IAM用户。
重要
-
在线迁移服务目前暂不支持AWS S3的白名单访问。如果有白名单配置,请取消白名单。
-
链接文档仅供参考,由于源站变更,文档可能已经过时。
步骤三:创建目标存储空间
创建目标存储空间,用于存放迁移的数据。具体操作,请参见创建存储空间。
步骤四:登录控制台的RAM用户添加权限
在用户页面,单击目标RAM用户操作列的添加权限。
-
系统策略:管理OSS在线迁移服务的权限(AliyunOSSImportFullAccess)。
-
自定义权限策略:该策略必须包含
ram:CreateRole、ram:CreatePolicy、ram:AttachPolicyToRole权限。用于在线迁移控制台创建OSS数据地址 > 授权角色 > 新建角色使用。
步骤五:创建用于迁移数据的RAM角色
为了保证数据安全,推荐您创建RAM角色并按照最小权限原则对该RAM角色进行授权策略后用于迁移数据。
-
登录RAM控制台。
-
在左侧导航栏,选择身份管理 > 角色。
-
在角色页面,单击创建角色。
-
在创建角色页面的选择可信实体类型区域,选择阿里云服务,点击下一步。
-
在已选择可信实体类型区域,选择普通服务角色,输入角色名称和选择受信服务(在线迁移服务)。
步骤六:为RAM角色授权策略
创建RAM角色成功后,在角色页面,单击目标RAM角色操作列的授权策略。根据不同的迁移场景,授予RAM角色相应的权限策略。
同账号迁移(与登录控制台用户为同账号)
同账号迁移时,需要为RAM角色授予以下权限。
-
自定义策略:
-
授予RAM角色对存放迁移后数据的Bucket下所有资源进行列举、读取、中止和写操作的权限。
说明
-
以下权限策略仅供您参考,其中
<mybucket>为存放迁移后数据的Bucket名称,请根据实际值替换。 -
关于OSS权限策略的更多信息,请参见RAM Policy常见示例。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "oss:List*", "oss:Get*", "oss:Put*", "oss:AbortMultipartUpload" ], "Resource": [ "acs:oss:*:*:<mybucket>", "acs:oss:*:*:<mybucket>/*" ] } ] } -
-
跨账号迁移(与登录控制台用户为不同账号)
跨账号迁移时,需要分别为RAM角色授予以下权限。
-
目标阿里云账号给登录控台用户的RAM角色授权
迁移实施
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍将AWS S3中的数据迁移到阿里云对象存储OSS的注意事项、迁移限制说明和操作步骤。
注意事项
使用在线迁移服务迁移数据时需要注意以下事项:
-
在线迁移服务使用源站存储服务提供商公开的标准接口来访问源数据,其行为依赖于源站存储服务提供商的具体实现。
-
在线迁移会占用源地址和目的地址的资源,可能会影响业务正常运行。若您的业务比较重要,请提前做好评估后对迁移任务设置限速,或在空闲时间启动迁移任务。
-
在线迁移前会检查源地址和目的地址的文件,但是若您源和目的地址有相同文件名的文件,且在迁移任务中配置了覆盖方式为覆盖,迁移时会直接覆盖目的地址的文件。若两个文件内容不同,必须更改文件名或做好备份。
-
在线迁移会保留源文件的最后修改时间属性,如果目的Bucket设置了生命周期规则,且迁移后文件处于该生命周期规则生效的时间范围内,则该文件可能会在规则生效时被删除或转为指定的归档类型。
迁移限制说明
-
目前仅支持单次迁移单个Bucket数据,无法将整个账号的数据一次性迁移。
-
AWS S3迁移数据的属性说明如下:
-
支持迁移的属性:x-amz-meta-*、LastModifyTime ,Content-Type,Cache-Control,Content-Encoding,Content-Disposition,Content-Language ,Expires。
-
不支持迁移的属性(包括但不限于):StorageClass、Acl、服务端加密、标签Tagging等。
说明
不支持迁移的属性包括但不限于以上列举的内容,其他未列举的属性行为暂无法确定,以实际迁移完成的内容为准。
-
-
关于如火山引擎(TOS)、网易云等不兼容 S3 接口的数据源,可能会导致迁移失败并产生不可预测的问题,建议可通过HTTP方式进行迁移。
步骤一:选择地域
-
使用创建的RAM用户登录阿里云在线迁移服务管理控制台。
-
在顶部菜单栏左上角处的地域选择代表“迁移服务部署地域”,因此请选择数据源所在地域或距离数据源最近的地域,如下图所示。
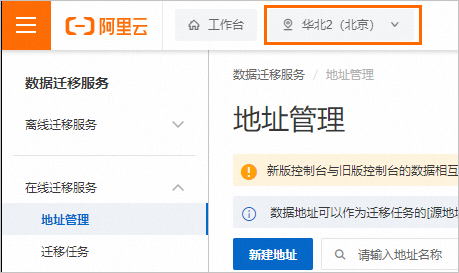
控制台上方所选地域(代表在线迁移服务的部署地域),中国内地地域包含北京、上海、杭州、深圳、乌兰察布,其他地域包含中国香港、新加坡、德国(法兰克福)、美国(弗吉尼亚)。
重要
-
不同地域内的数据地址和迁移任务不通用,请谨慎选择。
-
优先选择源数据所在的地域,如果没有源数据所在地对应的地域,请尽可能选择接近源数据所在的地域创建迁移任务。
-
跨境迁移时,推荐您开启传输加速,提高迁移速度。开启了传输加速的Bucket会收取传输加速费用。关于传输加速的更多信息,请参见传输加速。
-
步骤二:创建源地址
-
在左侧导航栏,选择在线迁移服务 > 地址管理,单击新建地址。
-
在创建数据地址页面,配置如下参数,然后单击确认。
参数
是否必选
说明
名称
是
输入源数据地址名称。名称命名规则如下:
-
名称不能为空,长度为3~63个字符。
-
支持英文小写字母、数字和特殊字符短划线(-)和下划线(_),且区分大小写。
-
UTF-8编码并且不能以短划线(-)和下划线(_)开头。
类型
是
选择AWS S3。
域名
是
输入AWS S3的访问域名。更多信息,请参见Amazon S3终端节点。
重要
链接文档仅供参考,由于源站变更,文档可能已经过时。
AccessKeyId
是
输入创建的IAM用户的访问密钥,用于AWS S3进行身份识别,确认该用户是否有读取源数据的权限。
SecretAccessKey
是
存储桶(Bucket)
是
输入待迁移数据所在的AWS S3存储桶名称。
说明
存储桶名称要求开头和结尾不带空格、换行、制表符等非法字符。
前缀
否
您可以指定数据路径前缀迁移部分数据。
-
指定前缀:迁移指定目录(前缀)下的数据。格式要求不能以正斜线(/)开头,必须以正斜线(/)结尾。
-
不指定前缀:迁移整个Bucket中的数据。
通道
否
选择需要使用的通道名称。
重要
-
仅通过专线或VPN迁移数据上云、自建存储数据迁移上云需要使用该参数。
-
目的数据地址是LOCALFS的以及需要走专线(金融云、专有云等)的场景需要关联代理。
代理
否
选择需要使用的代理名称。
重要
-
仅通过专线或VPN迁移数据上云、自建存储数据迁移上云需要使用该参数。
-
指定通道下,最多可同时选择30个代理。
-
步骤三:创建目的地址
| 参数 | 是否必选 | 说明 |
| 名称 | 是 | 输入目的数据地址名称。名称命名规则如下:
|
| 类型 | 是 | 选择Alibaba OSS。 |
| 自定义域名 | 否 | 支持用户的自定义域名 |
| 地域 | 是 | 选择目的地址所在的地域,例如华东1(杭州)。 |
| 授权角色 | 是 |
|
| 存储桶(Bucket) | 是 | 输入当前控制台所在账号下迁移后数据所在的存储桶(Bucket)名称。 |
| 前缀 | 否 | 您可以指定数据路径前缀将源数据迁移至指定目录下。格式要求不能以正斜线(/)开头,必须以正斜线(/)结尾,例如
|
| 通道 | 否 | 选择需要使用的通道名称。 重要
|
| 代理 | 否 | 选择需要使用的代理名称。 重要
|
-
在左侧导航栏,选择在线迁移服务 > 地址管理,单击新建地址。
-
在新建地址面板,配置如下参数,然后单击确定。
步骤四:创建迁移任务
重要
迁移任务并发数量限制:迁移服务部署地域每个地域最多支持5个任务并发,超出限制后可能导致定时任务调度无法按预期执行。
-
在左侧导航栏,选择在线迁移服务 > 迁移任务,单击新建任务。
-
在选择地址页面,配置如下参数,然后单击下一步。
参数
是否必选
说明
名称
是
输入迁移任务名称。名称命名规则如下:
-
名称不能为空,长度为3~63个字符。
-
支持英文小写字母、数字和特殊字符短划线(-)和下划线(_),且区分大小写。
-
UTF-8编码并且不能以短划线(-)和下划线(_)开头。
源地址
是
选择已创建的源地址。
目的地址
是
选择已创建的目的地址。
-
-
在配置任务页面,配置如下参数。
参数
是否必选
说明
迁移带宽
否
选择迁移带宽。
-
默认:默认最大带宽,实际速度取决于文件大小和文件数量。
-
指定上限:根据控制台提示指定具体的带宽上限。
重要
-
实际迁移带宽与数据源、网络、目的限流、文件大小等因素有关,不一定能达到指定上限。
-
请您评估数据源、迁移目的、业务情况、网络带宽等,并根据实际情况选择合理数值,限流不恰当可能会影响业务的正常运行。
每秒迁移文件数
否
选择每秒迁移文件数。
-
默认:默认每秒迁移文件数。
-
指定上限:根据控制台提示指定具体的每秒迁移文件数。
重要
-
实际迁移带宽与数据源、网络、目的限流、文件大小等因素有关,不一定能达到指定上限。
-
请您评估数据源、迁移目的、业务情况、网络带宽等,并根据实际情况选择合理数值,限流不恰当可能会影响业务的正常运行。
覆盖方式
否
选择同名文件的覆盖方式。
警告
-
根据最后修改时间覆盖无法严格保证一定不会覆盖更新的文件,存在旧文件覆盖新文件的风险。
-
若您选择根据最后修改时间覆盖的覆盖方式,请务必确保源端文件能返回最后修改时间、Size、Content-Type等信息,否则覆盖策略可能失效,产生非预期的迁移结果。
-
选择不覆盖或根据最后修改时间覆盖时,为执行后续覆盖判断,会分别请求源端和目的端meta信息一次,因此会在源端和目的端产生对应的请求费用。
-
不覆盖:不迁移该文件。
-
全部覆盖:源地址中的文件会覆盖目的地址中的文件。
-
根据最后修改时间覆盖:
-
当源地址中的文件最后修改时间晚于目的地址中的文件最后修改时间时,目的地址中的文件会被覆盖。
-
当源地址中的文件最后修改时间与目的地址中的文件最后修改时间相同时,若二者的Size和Content-Type有一项不同,则目的地址中的文件会被覆盖。
-
迁移报告
是
迁移报告推送方式。
-
不推送(默认):不推送迁移报告至目的bucket。
-
推送:将迁移报告推送至目的bucket,详细路径请参考后续操作。
重要
-
迁移报告推送会占用目的端一定的存储空间。
-
迁移报告的推送可能会存在一定的时间延迟,请您耐心等待迁移报告的生成。
-
每个任务执行记录都有一个唯一的ID,请注意,迁移报告只会推送一次,请谨慎删除!
迁移日志
是
迁移日志推送方式。
-
不推送(默认):不推送迁移日志。
-
推送:将迁移日志推送至日志服务SLS,可在SLS上查看迁移日志。
-
仅推送文件错误日志:仅将错误迁移日志推送至日志服务SLS,可在SLS上查看错误迁移日志。
当选择推送或仅推送文件错误日志时,在线迁移服务会在日志服务SLS中创建名称为aliyun-oss-import-log-阿里云账号ID-当前迁移服务部署地域的Project,例如aliyun-oss-import-log-137918634953****-cn-hangzhou。
重要
请务必完成以下操作后,再选择推送或仅推送文件错误日志,否则可能会导致迁移任务异常。
-
已开通SLS服务。
-
已在日志服务授权项授权页面中同意授权。
日志服务授权
否
当迁移日志选择推送或仅推送文件错误日志时出现该选项。
单击授权进入云资源访问授权页面,页面会对应创建AliyunOSSImportSlsAuditRole角色,并对角色做授权,请单击同意授权完成授权。
文件名
否
文件名过滤器。
支持包含和排除两种过滤规则,请参见RE2库的正则表达式语法(仅支持部分表达式语法)。例如:
-
.*\.jpg$表示以.jpg结尾的所有文件。
-
^file.*默认表示根目录下以file开头的所有文件。
如果源数据地址设置了前缀,例如源数据地址前缀为data/to/oss/,则需要使用^data/to/oss/file.*来匹配指定前缀下以file开头的所有文件。
-
.*/picture/.*表示匹配某一级为picture的子目录。
重要
-
当过滤规则为包含时,符合规则的文件都会被迁移,如果有多条规则,符合任意一个条件的文件都会被迁移。
例如2个文件picture.jpg和picture.png,设置一条包含规则过滤.*\.jpg$,此时只会迁移picture.jpg文件,如果同时也设置了包含规则过滤.*\.png$,则2个文件都会被迁移。
-
当过滤规则为排除时,符合规则的文件都不会被迁移,如果有多条规则,符合任意一个条件的文件都不会被迁移。
例如2个文件picture.jpg和picture.png,设置一条排除规则过滤.*\.jpg$,此时只会迁移picture.png,如果同时也设置了排除规则过滤.*\.png$,则2个文件都不会被迁移。
-
排除规则优先。当一个文件既在排除规则中又在包含规则中,则文件不会被迁移。
例如文件file.txt,设置排除规则过滤.*\.txt$文件,并同时设置包含规则过滤file.*,则此时file.txt文件不会被迁移。
文件修改时间
否
文件最后一次修改时间过滤器。
可指定文件最后一次修改时间作为过滤规则。如果指定了时间范围,则只迁移文件最后一次修改时间在指定时间范围内的文件,具体规则如下。
-
当仅指定开始时间为2019年01月01日,不指定结束时间时,则只迁移文件最后一次修改时间晚于等于2019年01月01日的文件。
-
当仅指定结束时间为2022年01月01日,不指定开始时间时,则只迁移文件最后一次修改时间早于等于2022年01月01日的文件。
-
当指定开始时间为2019年01月01日,结束时间为2022年01月01日,则迁移文件最后一次修改时间范围在晚于等于2019年01月01日,且早于等于2022年01月01日的文件。
执行时间
否
重要
-
正在迁移中的任务,在下一个指定时间前仍未结束本轮迁移,则会在本轮迁移结束后,自动顺延至下一个指定时间启动任务,直至完成指定次数的迁移。
-
迁移任务并发数量限制:迁移服务部署地域选择中国香港或中国内地时最多支持10个任务并发,选择海外地域时最多支持5个,超出限制后可能导致定时任务调度无法按预期执行。
确定迁移任务的执行时间。
-
立即执行:立即执行当前任务。
-
指定执行时间:指定任务执行期间每天的执行时间段。默认情况下,任务将在指定的起始时间启动,在指定的停止时间暂停。
-
周期调度:通过调整执行频率和执行次数来启动任务。
-
执行频率:支持以每小时、每天、每周、一周中某些天、自定义等5种频率,具体请查看执行频率参考。
-
执行次数:指定任务的执行次数,如不设置则默认执行一次,最大执行次数请参考控制台提示。
-
重要
可随时手动启动和暂停任务,不受自定义执行时间的影响。
-
-
阅读在线迁移服务协议,选中我已理解并确认,合规承诺声明且当迁移任务完成时,我有确认迁移数据一致性的义务和责任,然后单击下一步。
-
检查配置信息,确认无误后,单击确定,等待迁移任务执行。
执行频率参考
| 执行频率 | 说明 | 示例 |
| 每小时 | 选择以每小时为频率,可搭配执行次数一起使用。 | 当前时间为8:05分,指定每小时为频率,执行3次任务,则会在下一个整点9点钟开始第一次任务。
|
| 每天 | 选择以每天为频率时,需设置0~23小时中任意整点时间启动任务,可搭配执行次数一起使用。 | 当前时间为8:05分,指定每天10点,执行5次,会在当天10点开始第一次任务。
|
| 每周 | 选择每周时,需指定周内任意一天,并设置0~23小时中任意整点时间启动任务,可搭配执行次数一起使用。 | 当前时间为周一8:05分,指定每周一的10点,执行10次,则会在当天10点时开始第一次任务。
|
| 一周中某些天 | 选择一周中某些天时,支持选择周内任意几天,并设置0~23小时中任意整点时间启动任务。 | 当前为周三8:05,指定每周一、三、五的10点,则会在当天的10点时开始第一次任务。
|
| 自定义 | 使用Corn表达式自定义设置任务启动时间。 | 说明 Corn表达式由5个字段组成,每个字段之间使用空格分隔,依次表示任务的执行时间规则:分钟 小时 日 月 星期。 以下是一些示例Cron表达式:
|
步骤五:校验数据
迁移服务仅负责数据的迁移,无法保证数据的一致性和完整性。迁移任务完成后,请您全量校验迁移的数据,务必自行做好源端和目的端数据一致性校验。
警告
请您务必在迁移任务完成后,校验目的端迁移数据。您在删除源数据前,未校验目的端迁移数据无误,导致数据丢失所引起的一切损失和后果均由您自行承担。
查看迁移任务状态
迁移任务创建后,有以下多种状态:
-
已创建:迁移任务已创建。用户可手动点启动或者等待到达指定的起始时间,系统启动任务。
-
启动:任务创建成功且已启动,等待调度。
-
准备:数据预处理中。
-
迁移:数据正在迁移中,请您耐心等待。
-
删除中:迁移任务正在删除中,待删除完成后,已删除的迁移任务将从任务列表中移除。
-
暂停:迁移任务已暂停。
-
关闭:迁移任务正在关闭中,待关闭完成后,迁移任务将会转为结束状态。
-
结束:迁移任务已结束。
-
中断:迁移任务异常中断。
查看迁移报告
-
登录数据在线迁移控制台。
-
在左侧导航栏,选择在线迁移服务 > 迁移任务。
-
在迁移任务列表中,单击对应任务的管理,进入任务的详情页面。
-
若创建任务时选择不推送报告,在任务详情页 > 历史,单击生成迁移报告。待迁移报告生成完成后,可单击下载迁移报告到本地。
-
若创建任务时选择推送报告,在任务详情页 > 历史,待报告生成完成,可点击下载迁移报告到本地。
-
重要
-
在数据迁移任务完成之前,生成的迁移报告内容可能不完整。如需获取完整的迁移报告,请在任务迁移完成后点击下载。
-
迁移报告仅供参考,以实际迁移完成的内容为准。
迁移报告生成后将被存储在指定的对象存储(OSS)Bucket中。根据任务执行情况,文件夹目录层级的前缀格式如下所示:
OSS://<bucket>/<prefix>/aliyun_import_report/<uid>/<jobid>/<runtimeid>/total_list/
OSS://<bucket>/<prefix>/aliyun_import_report/<uid>/<jobid>/<runtimeid>/failed_list/
OSS://<bucket>/<prefix>/aliyun_import_report/<uid>/<jobid>/<runtimeid>/skipped_list/| 字段名称 | 字段含义 |
| bucket | 目的端bucket。 |
| prefix | 目的数据地址指定的迁移目录前缀。 |
| uid | 用户主账号ID。 |
| jobid | 任务ID(任务详情页 > 详情获取)。 |
| runtimeid | 任务执行记录ID(任务详情页 > 历史获取)。 |
-
在对象存储OSS控制台,找到目的bucket下迁移报告文件,您可以下载这些文件并查看详细的文件列表,推荐使用ossbrowser或ossutil工具查看。
根据任务执行情况,生成的迁移报告文件分为总迁移文件列表、迁移失败文件列表和迁移跳过文件列表三种。
说明
迁移报告文件命名规则
-
uid@jobid@runtimeid_total_list_n,代表总迁移文件列表,可能会有多个,其中 n 是一个大于等于 0 的正整数。
-
uid@jobid@runtimeid_failed_list_n,代表迁移失败文件列表,可能会有多个,其中 n 是一个大于等于 0 的正整数。
-
uid@jobid@runtimeid_skipped_list_n,代表迁移跳过文件列表,可能会有多个,其中 n 是一个大于等于 0 的正整数。
迁移报告文件所含字段内容描述了文件(对象)从源到目的地迁移过程中的各种属性,具体包括:
| 字段名称 | 字段含义 |
| 源文件名 | 表示源文件的名称 |
| 目的文件名 | 表示目标文件的名称 |
| 源文件大小 | 表示源文件的大小 |
| 目的文件大小 | 表示目标文件的大小 |
| 源文件MD5 | 提供源文件的MD5哈希值,用于一致性验证 |
| 目的文件MD5 | 提供目标文件的MD5哈希值,用于一致性验证 |
| 源文件CRC64 | 提供源文件的CRC64值,用于一致性检查 |
| 目的文件CRC64 | 提供目标文件的CRC64值,用于一致性检查 |
| 源文件最后修改时间 | 表示源文件的最后修改时间 |
| 目的文件最后修改时间 | 表示目标文件的最后修改时间 |
| 源对象版本ID(只有多版本迁移涉及) | 仅在多版本迁移中使用,用于指示源对象的版本ID |
| 目的对象版本ID(只有多版本迁移涉及) | 仅在多版本迁移中使用,用于指示目标对象的版本ID |
| 迁移开始时间 | 记录文件迁移的开始时间 |
| 迁移结束时间 | 记录文件迁移的结束时间 |
| 是否异常迁移(false:正常,true:异常) | 一个布尔标志,指示迁移是否异常(false表示正常,true表示异常) |
| 异常原因 | 提供异常情况的原因说明 |
查看迁移日志
迁移任务结束后,可以通过日志服务SLS查看迁移任务的日志。您可以使用任务名、任务ID、UID、文件名等作为过滤条件,精准定位迁移日志。
重要
-
仅对创建迁移任务时,参数迁移日志选择推送或仅推送错误日志的任务有效。如果创建迁移任务时,参数迁移日志选择不推送,则不会推送迁移任务的日志到日志服务SLS上。
-
数据迁移未完成前SLS中迁移日志内容可能不完整,如需获取完整的迁移日志,请在任务迁移结束后再查看SLS中的迁移日志。
-
迁移日志仅供您参考,请以实际迁移完成的内容为准。
在线迁移服务会在日志服务SLS中创建名称为aliyun-oss-import-log-阿里云账号ID-当前控制台地域的Project,例如aliyun-oss-import-log-137918634953****-cn-hangzhou。在此Project中可以查看迁移任务的日志,其中包含如下两种日志:
-
drs_import_success_log:迁移成功日志。
-
drs_import_fail_log:迁移失败日志。
迁移日志中的主要字段说明如下表所示。
| 字段 | 说明 |
| JobName | 迁移任务的名称。 |
| JobId | 迁移任务ID。 |
| Region | 当前控制台所在地域。 |
| Status | 迁移文件的状态。包括如下三种状态:
|
| UserId | 用户的UID。 |
| ExecuteId | 执行记录ID。 |
| StartTime | 迁移开始的时间。 |
| EndTime | 迁移结束的时间。 |
| ListTime | 该文件被扫描到的时间。 |
| Time | 当前的时间。 |
| SrcObjectName | 源端文件名称。以Src开头的是源端相关字段。 说明 文件名为URL编码处理后的格式,例如docs%2Fmy.docir%2Fexample.log。 |
| SrcObjectSize | 源端文件大小。 |
| DestObjectName | 目的端文件名称。以Dest开头的是目的端相关字段。 说明 文件名为URL编码处理后的格式,例如docs%2Fmy.docir%2Fexample.log。 |
| DestObjectSize | 目的端文件大小。 |
修改限流
数据迁移过程中,您可以根据您的实际情况随时修改限流参数,修改限流后需要一定的生效时间。
-
登录数据在线迁移控制台。
-
在顶部菜单栏,选择任务所在的地域。
-
在左侧导航栏,选择在线迁移服务 > 迁移任务。
-
在迁移任务列表中,单击对应任务的管理,进入任务详情页面。
-
在配置区域,单击迁移带宽上限后的重置。
-
在弹出的对话框中配置迁移带宽上限。
-
默认:默认最大带宽,实际速度取决于文件大小和文件数量。
-
指定上限:根据控制台提示指定具体的带宽上限。
-
-
单击确定,即可完成修改。
修改每秒迁移文件数上限
数据迁移过程中,您可以根据您的实际情况随时修改每秒迁移文件数上限参数,修改每秒迁移文件数上限后需要一定的生效时间。
-
登录数据在线迁移控制台。
-
在顶部菜单栏,选择任务所在的地域。
-
在左侧导航栏,选择在线迁移服务 > 迁移任务。
-
在迁移任务列表中,单击对应任务的管理,进入任务详情页面。
-
在配置区域,单击每秒迁移文件数上限后的重置。
-
在弹出的对话框中配置每秒迁移文件数上限。
-
默认:默认每秒迁移文件数,实际速度取决于文件大小和文件数量。
-
指定上限:根据控制台提示指定具体的每秒迁移文件数。
-
-
单击确定,即可完成修改。
迁移失败后重试
如果迁移任务有部分文件迁移失败,可选择重新迁移失败的文件。
-
登录数据在线迁移控制台。
-
在顶部菜单栏,选择任务所在的地域。
-
在左侧导航栏,选择在线迁移服务 > 迁移任务。
-
在迁移任务列表中,单击对应任务操作列的管理,进入任务详情页面。
-
在历史区域下单击对应任务操作列的重试。
-
修改子任务名称,单击下一步。
-
确认迁移带宽、每秒迁移文件数、覆盖方式等参数无误后,单击下一步。
-
单击确定,子任务会启动并且重新迁移失败的文件。