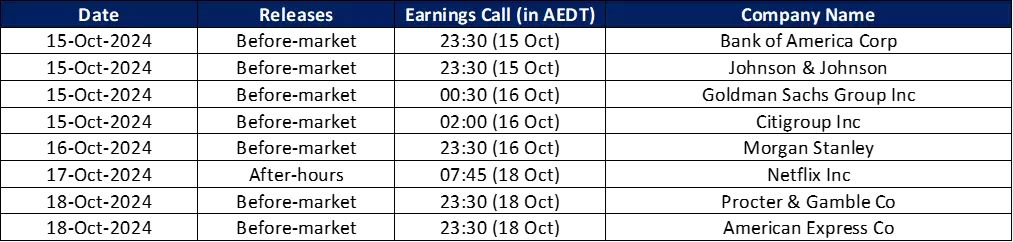
在上一篇文章中,我们介绍了如何使用Python进行基本的人脸识别。本文将深入探讨人脸识别技术的高级应用,包括如何优化识别性能、处理复杂环境下的识别挑战以及如何利用深度学习模型来提高识别准确性等话题。

人脸识别的原理回顾
人脸识别流程
人脸识别涉及以下关键步骤:
- 人脸检测:从图像或视频帧中定位人脸的位置。
- 特征提取:提取人脸的关键特征点,并将其转换为向量形式。
- 特征匹配:将提取的特征与已知的人脸数据库进行比较,找到最接近的匹配项。
常见方法
- 传统方法:基于特征的手动设计,如Eigenfaces、LBP(局部二值模式)、Haar特征等。
- 深度学习方法:利用卷积神经网络(CNN)自动学习特征,如FaceNet、ArcFace等。
提高识别性能
1. 优化特征提取算法
特征提取是人脸识别的核心部分之一。深度学习模型如卷积神经网络(CNN)能够自动学习到更复杂的特征表示。
使用预训练模型
使用预训练的深度学习模型可以显著提高识别准确率。例如,可以使用Dlib库中的预训练模型,或者使用FaceNet等先进的模型来进行特征提取。
import face_recognition
# 加载图片
image = face_recognition.load_image_file("example.jpg")
# 提取特征
face_encoding = face_recognition.face_encodings(image)[0]
模型微调
如果预训练模型在特定的应用场景下表现不佳,可以考虑对模型进行微调。微调涉及到使用新的数据集来更新模型权重。
import torch
import torchvision.transforms as transforms
from torchvision.models import resnet50
# 加载预训练模型
model = resnet50(pretrained=True)
# 微调最后一层
num_features = model.fc.in_features
model.fc = torch.nn.Linear(num_features, num_classes)
# 微调训练
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
2. 并行处理
对于实时视频流来说,处理每一帧都需要一定的时间。为了提高处理速度,可以使用多线程或多进程技术来并行处理多个帧。
from concurrent.futures import ThreadPoolExecutor
def process_frame(frame):
# 处理单个帧
face_locations = face_recognition.face_locations(frame)
face_encodings = face_recognition.face_encodings(frame, face_locations)
return face_encodings
frames = [...] # 假设这是一个包含多个帧的列表
with ThreadPoolExecutor(max_workers=4) as executor:
results = [executor.submit(process_frame, frame) for frame in frames]
face_encodings_list = [future.result() for future in results]
应对复杂环境
1. 光照变化
光照条件的变化会影响识别效果。可以使用光照补偿算法来减少光照变化的影响。一种简单的方法是使用直方图均衡化。
import cv2
def histogram_equalization(image):
# 转换为灰度图像
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用直方图均衡化
eq_image = cv2.equalizeHist(gray_image)
return eq_image
# 示例
image = cv2.imread("example.jpg")
eq_image = histogram_equalization(image)
cv2.imshow("Equalized Image", eq_image)
cv2.waitKey(0)
2. 旋转和倾斜
人脸的旋转和倾斜也会降低识别率。可以通过对齐人脸来校正姿态。
import cv2
import numpy as np
from scipy.spatial import distance
# 获取关键点
keypoints = face_recognition.face_landmarks(image)
# 对齐人脸
def align_face(image, keypoints):
# 假设双眼位置
left_eye = keypoints[0]['left_eye']
right_eye = keypoints[0]['right_eye']
# 计算两眼之间的距离和角度
dx = right_eye[0][0] - left_eye[0][0]
dy = right_eye[0][1] - left_eye[0][1]
# 计算旋转角度
angle = np.degrees(np.arctan2(dy, dx))
# 创建旋转矩阵
center = tuple(np.array(image.shape[1::-1]) / 2)
rot_mat = cv2.getRotationMatrix2D(center, angle, 1.0)
# 应用仿射变换
aligned_face = cv2.warpAffine(image, rot_mat, image.shape[1::-1], flags=cv2.INTER_LINEAR)
return aligned_face
aligned_face = align_face(image, keypoints)
3. 复杂背景
在复杂背景下,人脸可能会被其他物体遮挡。可以使用背景减除技术来减少干扰。
import cv2
def background_subtraction(frame):
fgmask = fgbg.apply(frame)
return fgmask
fgbg = cv2.createBackgroundSubtractorMOG2()
frame = cv2.imread("example.jpg")
masked_frame = background_subtraction(frame)
cv2.imshow("Masked Frame", masked_frame)
cv2.waitKey(0)
利用深度学习提升性能
1. 自定义训练
除了使用预训练模型之外,还可以通过自定义训练来进一步提升模型的性能。这需要收集大量带标签的数据集,并使用深度学习框架(如TensorFlow或PyTorch)来训练模型。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 构建模型
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(train_images, train_labels, epochs=10)
2. 数据增强
数据增强可以增加训练数据的多样性,帮助模型更好地泛化。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# 使用数据增强生成器
train_generator = datagen.flow_from_directory(train_dir, target_size=(224, 224), batch_size=32)
3. 模型融合
使用多个模型进行融合可以提高识别准确性。例如,可以使用多个不同的模型进行投票决策。
from sklearn.ensemble import VotingClassifier
# 定义多个模型
model1 = ... # 第一个模型
model2 = ... # 第二个模型
model3 = ... # 第三个模型
# 创建融合模型
ensemble_model = VotingClassifier(estimators=[('m1', model1), ('m2', model2), ('m3', model3)], voting='hard')
# 训练融合模型
ensemble_model.fit(X_train, y_train)
# 预测
predictions = ensemble_model.predict(X_test)

高级应用场景
1. 实时监控系统
在安全监控场景中,实时的人脸识别尤为重要。可以使用多线程技术来处理视频流,同时保持较低的延迟。
import threading
def capture_video():
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
# 处理帧
process_frame(frame)
capture_thread = threading.Thread(target=capture_video)
capture_thread.start()
2. 多人识别
在多人环境中,需要同时识别多个人的脸部。可以使用人脸聚类技术来区分不同的人。
from sklearn.cluster import DBSCAN
# 聚类人脸编码
clusterer = DBSCAN(eps=0.6, min_samples=1)
clusters = clusterer.fit_predict(face_encodings)
# 显示聚类结果
for i, encoding in enumerate(face_encodings):
label = clusters[i]
print(f"Face {i} is in cluster {label}")
3. 人脸识别与情感分析结合
结合情感分析可以让人脸识别系统更具智能。例如,在零售环境中,可以根据顾客的表情提供个性化的服务。
from fer import FER
# 初始化情感分析器
emotion_detector = FER()
# 分析表情
emotions = emotion_detector.top_emotion(face)
print(emotions)
总结
本文深入探讨了Python人脸识别技术的高级应用,包括优化特征提取算法、并行处理、应对复杂环境以及利用深度学习来提升性能。通过这些方法,我们可以构建更加智能、高效的人脸识别系统。