目录
连接(JOIN)
语法:
不同的 SQL JOIN
INNER JOIN 关键字
LEFT JOIN 关键字
SQL LEFT JOIN 语法
RIGHT JOIN 关键字
SQL RIGHT JOIN 语法
FULL OUTER JOIN 关键字
SQL FULL OUTER JOIN 语法
UNION 操作符
SQL UNION 语法
SQL UNION ALL 语法
SELECT INTO 语句
INSERT INTO SELECT 语句
CREATE TABLE 语句
SQL CREATE TABLE 语法
约束(Constraints)
SQL CREATE TABLE + CONSTRAINT 语法
1. NOT NULL
实例
2. UNIQUE
使用场景
实例
3. PRIMARY KEY
实例
4. FOREIGN KEY
实例
5. CHECK
确保列中的值满足特定的条件。
实例
6. DEFAULT
实例
7. INDEX
用于快速访问数据库表中的数据。
例子
PRIMARY KEY 约束
FOREIGN KEY 约束
CHECK 约束
DEFAULT 约束
CREATE INDEX 语法
SQL CREATE UNIQUE INDEX 语法
DROP INDEX 语句
DROP TABLE 语句
语法格式:
DATABASE 语句
语法格式:
TRUNCATE TABLE 语句
ALTER TABLE 语句
SQL ALTER TABLE 语法
AUTO INCREMENT 字段
上篇链接:数据库SQL基础教程 (一)_数据库sql使用1-CSDN博客
下篇链接:
连接(JOIN)
SQL join 用于把来自两个或多个表的行结合起来。
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。

SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN)。 SQL INNER JOIN 从多个表中返回满足 JOIN 条件的所有行。
语法:
SELECT column1, column2, ... FROM table1 JOIN table2 ON condition;
参数说明:
- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table1:要连接的第一个表。
- table2:要连接的第二个表。
- condition:连接条件,用于指定连接方式。
不同的 SQL JOIN
- INNER JOIN:如果表中有至少一个匹配,则返回行
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN:只要其中一个表中存在匹配,则返回行
INNER JOIN 关键字
INNER JOIN 关键字在表中存在至少一个匹配时返回行。
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
或:
SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column_name=table2.column_name;
参数说明:
- columns:要显示的列名。
- table1:表1的名称。
- table2:表2的名称。
- column_name:表中用于连接的列名。
LEFT JOIN 关键字
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
或:
SELECT column_name(s)
FROM table1
LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name;
注释:在某些数据库中,LEFT JOIN 称为 LEFT OUTER JOIN。

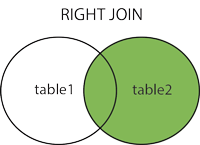
RIGHT JOIN 关键字
RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;
或:
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;
注释:在某些数据库中,RIGHT JOIN 称为 RIGHT OUTER JOIN。
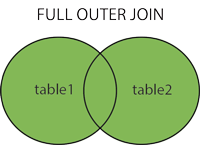
FULL OUTER JOIN 关键字
FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行.
FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
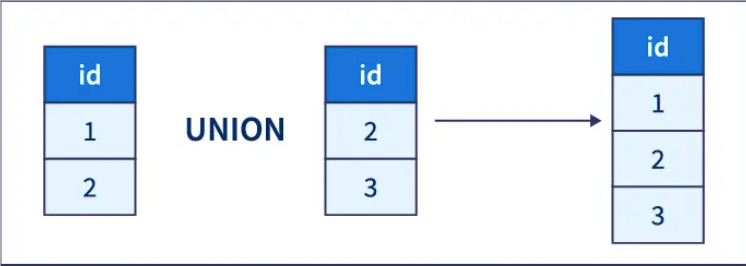
UNION 操作符
SQL UNION 操作符合并两个或多个 SELECT 语句的结果。
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。它可以从多个表中选择数据,并将结果集组合成一个结果集。使用 UNION 时,每个 SELECT 语句必须具有相同数量的列,且对应列的数据类型必须相似。
UNION 语法
SELECT column1, column2, ... FROM table1 UNION SELECT column1, column2, ... FROM table2;
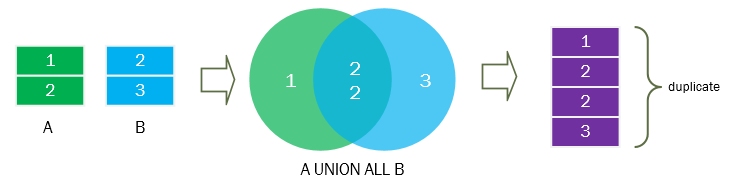
UNION 操作符默认会去除重复的记录,如果需要保留所有重复记录,可以使用 UNION ALL 操作符。
UNION ALL 语法
SELECT column1, column2, ...
FROM table1
UNION ALL
SELECT column1, column2, ...
FROM table2;
注释:UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名
SELECT INTO 语句
SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中。
注意:
MySQL 数据库不支持 SELECT ... INTO 语句,但支持 INSERT INTO ... SELECT 。
当然你可以使用以下语句来拷贝表结构及数据:
CREATE TABLE 新表 AS SELECT * FROM 旧表
表结构:
SELECT INTO会创建一个新表,并且新表的结构将基于选择的列和数据类型。- 如果新表已经存在,
SELECT INTO语句将失败。在这种情况下,可以使用INSERT INTO ... SELECT语句。
数据库支持:
SELECT INTO语句在 SQL Server 中非常常用,但在 MySQL 和 PostgreSQL 中通常使用CREATE TABLE ... AS SELECT语句。
INSERT INTO SELECT 语句
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响。
CREATE TABLE 语句
CREATE TABLE 语句用于创建数据库中的表。
表由行和列组成,每个表都必须有个表名。
CREATE TABLE 语法
CREATE TABLE table_name
(
column_name1 data_type(size),
column_name2 data_type(size),
column_name3 data_type(size),
....
);
column_name 参数规定表中列的名称。
data_type 参数规定列的数据类型(例如 varchar、integer、decimal、date 等等)。
size 参数规定表中列的最大长度。

约束(Constraints)
SQL 约束用于规定表中的数据规则。
如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
CREATE TABLE + CONSTRAINT 语法
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
在 SQL 中,我们有如下约束:
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。
- DEFAULT - 规定没有给列赋值时的默认值。
- INDEX - 用于快速访问数据库表中的数据。
1. NOT NULL
确保列不能有 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录
例子
CREATE TABLE Students (
StudentID INT NOT NULL,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50),
Age INT
);
2. UNIQUE
确保列中的所有值都是唯一的。
UNIQUE 类似于主键 (PRIMARY KEY) 约束,但 UNIQUE 约束允许列中的值为 NULL,而主键不允许。
PRIMARY KEY 约束自带唯一性(UNIQUE)约束功能。
使用场景
- 确保唯一性:例如,确保电子邮件地址、用户名等字段在整个表中是唯一的。
- 在多列上应用:可以在多列上创建
UNIQUE约束,以确保组合值的唯一性。
实例
CREATE TABLE Employees (
EmployeeID INT NOT NULL UNIQUE,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50),
Email VARCHAR(100) UNIQUE
);
3. PRIMARY KEY
唯一标识表中的每一行记录。PRIMARY KEY 约束是 NOT NULL 和 UNIQUE 的结合。
实例
CREATE TABLE Orders (
OrderID INT NOT NULL PRIMARY KEY,
OrderNumber INT NOT NULL,
OrderDate DATE NOT NULL
);
4. FOREIGN KEY
确保一个表中的值匹配另一个表中的值,从而建立两表之间的关系。
实例
CREATE TABLE Orders (
OrderID INT NOT NULL PRIMARY KEY,
OrderNumber INT NOT NULL,
CustomerID INT,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
5. CHECK
确保列中的值满足特定的条件。
实例
CREATE TABLE Products (
ProductID INT NOT NULL PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Price DECIMAL(10, 2) CHECK (Price >= 0)
);
6. DEFAULT
为列设置默认值。
实例
CREATE TABLE Customers (
CustomerID INT NOT NULL PRIMARY KEY,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50),
JoinDate DATE DEFAULT GETDATE()
);
7. INDEX
用于快速访问数据库表中的数据。
CREATE INDEX idx_lastname ON Employees (LastName);
例子
CREATE TABLE Students (
StudentID INT NOT NULL PRIMARY KEY,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50) NOT NULL,
Age INT CHECK (Age >= 18),
Email VARCHAR(100) UNIQUE,
EnrollmentDate DATE DEFAULT GETDATE()
);
通过这些约束,数据库管理系统能够确保数据的一致性、完整性和准确性。
PRIMARY KEY 约束
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
PRIMARY KEY 必须包含唯一的值,且不能包含 NULL 值。
每个表只能有一个 PRIMARY KEY,该主键可以由单个列或多个列组成。
FOREIGN KEY 约束
一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。
CHECK 约束
CHECK 约束用于限制列中的值的范围。
如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
如果对一个表定义 CHECK 约束,那么此约束会基于行中其他列的值在特定的列中对值进行限制。
DEFAULT 约束
DEFAULT 约束用于向列中插入默认值。
如果没有规定其他的值,那么会将默认值添加到所有的新记录。
CREATE INDEX 语法
在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name
ON table_name (column_name)
CREATE UNIQUE INDEX
在表上创建一个唯一的索引。不允许使用重复的值:唯一的索引意味着两个行不能拥有相同的索引值。Creates a unique index on a table. Duplicate values are not allowed:
CREATE UNIQUE INDEX index_name
ON table_name (column_name)
注释:用于创建索引的语法在不同的数据库中不一样。因此,检查您的数据库中创建索引的语法。
DROP INDEX 语句
索引是一种优化数据库查询性能的结构,但有时候可能需要删除某个索引,例如当索引不再需要或需要替换为新的索引时。
DROP INDEX 语句用于删除表中的索引。
DROP INDEX [IF EXISTS] index_name
ON TABLE_NAME;
参数说明:
DROP INDEX:表示要删除索引的操作。IF EXISTS:是一个可选的子句,用于检查索引是否存在。如果存在,就执行删除操作;如果不存在,不会报错。index_name:要删除的索引的名称。ON table_name:指定包含要删除索引的表的名称。
DROP TABLE 语句
DROP TABLE 语句用于删除表。
删除表将同时删除表的结构以及存储在其中的所有数据。因此,在执行DROP TABLE语句之前,请确保您真的希望永久删除表及其所有数据,因为此操作是不可逆的。
DROP TABLE [IF EXISTS] TABLE_NAME;
参数说明:
DROP TABLE:表示删除表的操作。IF EXISTS:是一个可选的子句,用于检查表是否存在。如果存在,执行删除操作;如果不存在,不会报错。table_name:要删除的表的名称。
DATABASE 语句
DROP DATABASE 语句用于删除数据库,包括其中的所有表、视图、存储过程等数据库对象。
DROP DATABASE 是一个非常强大和危险的操作,因为它会永久删除整个数据库及其所有相关数据,因此在执行之前务必要慎重考虑并确保你真的希望执行此操作。
DROP DATABASE [IF EXISTS] database_name;
TRUNCATE TABLE 语句
TRUNCATE TABLE语句用于快速删除表中的所有数据,但保留表的结构(列、约束等)
ALTER TABLE 语句
ALTER TABLE 语句用于在已有的表中添加、删除或修改列。
如需在表中添加列,请使用下面的语法:
ALTER TABLE table_name
ADD column_name datatype
如需删除表中的列,请使用下面的语法(请注意,某些数据库系统不允许这种在数据库表中删除列的方式):
ALTER TABLE table_name
DROP COLUMN column_name
AUTO INCREMENT 字段
Auto-increment 会在新记录插入表中时生成一个唯一的数字。



















