文章目录
- 前言
- 感知机
- 模型训练
- 模型预测
- 小结
前言

上面是一只猫,人类的大脑可以很轻松地识别出。人脑是如何识别的呢?
人类能够识别出这只猫,是因为这张图片具有猫的典型特征。例如,猫的耳朵、眼睛、猫须、嘴巴等独特的形态特征,可以迅速引起大脑的注意和识别。当我们的大脑看到这些特征时,能够与之前的经验相匹配,从而判断出这是一只猫。
计算机是否可以模拟人脑的方式,判断出这是一只猫呢?
要让计算机模拟人脑的识别过程,首先需要了解人脑的基本工作原理。
一个刚出生的大脑虽然有一定的感知能力,但识别能力尚未完全发育。人类通过视觉、听觉、嗅觉、触觉和味觉等感官获取外界的信息,神经系统将这些信息传递给大脑中的特定区域进行处理。大脑通过分析和整合这些感知信息,逐步学习并记忆不同事物的特征。随着经验的累积,大脑能够更快、更精确地识别出熟悉的事物。
感知机
虽然人脑的识别过程极为复杂,但计算机可以通过一些方式来简单地模仿这一过程。感知机 就是一种可以模仿人脑的方案。
感知机的工作原理是:
- 接收输入的特征值
- 通过训练数据对特征值学习
- 根据之前的学习结果,对新输入的数据进行判断
由于感知机的学习能力较弱,只能处理较为简单的、线性可分的任务,即可以用一条直线将数据划分的任务。
例如,我们可以通过实现一个简单的感知机来识别图片是否为一只猫。
import numpy as np
class Perceptron:
def __init__(self, input_size, lr=0.01):
"""
初始化感知机模型,设置权重和偏置,并定义学习率。
:param input_size: 输入特征的维度大小
:param lr: 学习率
"""
self.weights = np.random.randn(input_size) * 0.01 # 权重随机初始化为小值
self.bias = 0 # 偏置初始化
self.lr = lr # 学习率
def activation(self, z):
"""
阶跃函数,用于二分类任务。
:param z: 输入的加权和
:return: 返回1(正类)或0(负类)
"""
# 使用 NumPy 的向量化方式处理 z
return np.where(z >= 0, 1, 0)
def predict(self, x):
"""
对给定的输入样本进行预测。
:param x: 输入特征
:return: 分类结果(1或0)
"""
z = np.dot(x, self.weights) + self.bias # 计算加权和
return self.activation(z)
def train(self, x_train, y_train, epochs=100):
"""
训练感知机模型。
:param x_train: 训练数据特征
:param y_train: 训练数据标签
:param epochs: 训练的迭代次数
"""
for epoch in range(epochs):
total_error = 0 # 每个 epoch 初始化总误差
for i in range(len(x_train)):
x = x_train[i]
y = y_train[i]
y_pred = self.predict(x)
error = y - y_pred
total_error += np.abs(error) # 计算绝对误差
# 根据误差更新权重和偏置
self.weights += self.lr * error * x
self.bias += self.lr * error
# 每个 epoch 完成后打印总误差
print(f'Epoch {epoch + 1}/{epochs}, Total Error: {total_error}')
模型训练
感知机就如同人类的大脑,通过学习之后会掌握一些能力。为了让这颗人造的“大脑”能够识别猫,我们可以让感知机不断地学习猫的特征。
这里有几个关键点:
- 计算机如何读取猫的特征
- 计算机应该读取哪些特征
计算机并没有眼睛,不能像人类一样用眼睛观察猫。为了解决这个问题,我们可以给猫拍照,然后让计算机通过图片来学习猫的特征。
但是,只依赖少量图片进行学习,感知机可能无法很好地识别猫的特征。类似于我们初次进入动物园时,需要多次观察猴子和狒狒才能区分它们的不同。为了简化这一过程,我们可以采用 CIFAR-10 数据集,这个数据集包含了数千张图片,包括我们需要的猫的图片。
有了数据,我们就可以开始使用感知机进行训练了。感知机不会自动知道哪些特征重要。因此,它只会根据输入的数值化特征进行学习。这个过程称为 特征提取。
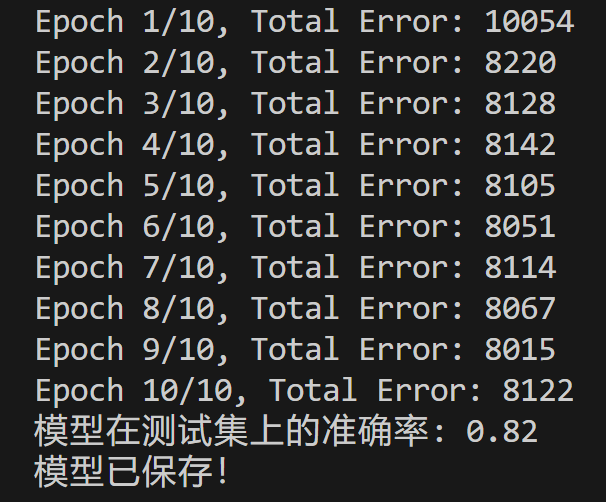
在训练过程中,感知机会尝试调整它的权重来找到一个能够将猫与其他动物区分开的 分类边界。在这个例子中,我们进行了 10 次训练,然后将训练的结果存储起来。不过,由于感知机只适用于线性可分的任务,如果图片中的猫和其他物体的特征无法用线性方式区分,感知机将无法很好地完成识别任务。
import joblib
from tensorflow.keras.datasets import cifar10
from perceptron_model import Perceptron
from sklearn.preprocessing import StandardScaler
import numpy as np
import time
# 第1步:加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 第2步:定义猫的标签
cat_label = 3
# 第3步:预处理数据
x_train_flat = x_train.reshape(x_train.shape[0], -1) # 展平图像
x_test_flat = x_test.reshape(x_test.shape[0], -1)
# 使用 StandardScaler 进行标准化
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train_flat)
x_test_scaled = scaler.transform(x_test_flat)
y_train_cat = (y_train == cat_label).astype(int).flatten()
y_test_cat = (y_test == cat_label).astype(int).flatten()
# 第4步:初始化感知机并训练模型
input_size = x_train_scaled.shape[1] # 输入特征维度
perceptron = Perceptron(input_size, lr=0.01)
perceptron.train(x_train_scaled, y_train_cat, epochs=10)
# 第5步:模型评估(使用批处理提高效率)
predictions = perceptron.predict(x_test_scaled)
accuracy = np.mean(predictions == y_test_cat)
print(f"模型在测试集上的准确率: {accuracy:.2f}")
# 第6步:保存模型
model_data = {
'weights': perceptron.weights,
'bias': perceptron.bias,
'scaler': scaler,
'version': '1.0',
'train_time': time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime()),
'test_accuracy': accuracy,
'hyperparameters': {'learning_rate': 0.01, 'epochs': 10}
}
try:
joblib.dump(model_data, 'perceptron_cat_model_v1.pkl')
print("模型已保存!")
except Exception as e:
print(f"模型保存失败: {e}")
模型训练结果:
模型预测
我们创建的大脑——感知机,已经学习了猫的特征。现在,我们可以使用它所学习的结果来识别一张新的猫的图片。
首先,我们从 CIFAR-10 数据集中取出一张猫的图片。因为感知机只能处理数值化的特征,我们需要先将这张图片转化为感知机可以理解的形式,例如将图像的像素值展平成一维数组。接下来,启动感知机并加载之前保存的训练结果。
感知机通过已经学到的权重和线性分类器,对输入的图像数据进行计算。它将判断这张图片是否符合之前所学习到的“猫”的特征。如果符合,它会将这张图片判断为猫,否则会判断为其他类别。
import numpy as np
import joblib
from tensorflow.keras.datasets import cifar10
from perceptron_model import Perceptron
import logging
logging.basicConfig(level=logging.INFO)
def preprocess_image(image, scaler):
image_flat = image.reshape(1, -1)
image_scaled = scaler.transform(image_flat)
return image_scaled
def is_cat(image, model, scaler):
image_scaled = preprocess_image(image, scaler)
prediction = model.predict(image_scaled[0])
logging.info(f"模型预测输出: {prediction}")
return prediction == 1
def load_model(filepath='perceptron_cat_model_v1.pkl'):
try:
model_data = joblib.load(filepath)
return model_data
except FileNotFoundError:
logging.error("模型文件未找到,请检查路径。")
return None
except Exception as e:
logging.error(f"模型加载失败: {e}")
return None
def evaluate_model(model, scaler, images, labels):
predictions = [is_cat(img, model, scaler) for img in images]
accuracy = np.mean(predictions == (labels == 3))
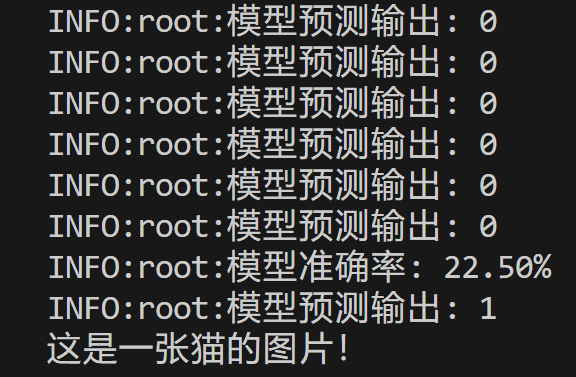
logging.info(f"模型准确率: {accuracy * 100:.2f}%")
return accuracy
# 加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# CIFAR-10 类别索引
cat_class_index = 3
cat_images = x_test[y_test.flatten() == cat_class_index]
# 加载保存的模型
model_data = load_model('perceptron_cat_model_v1.pkl')
if model_data is None:
raise Exception("模型加载失败")
# 恢复模型和预处理器
perceptron = Perceptron(input_size=3072)
perceptron.weights = model_data['weights']
perceptron.bias = model_data['bias']
scaler = model_data['scaler']
# 评估模型
evaluate_model(perceptron, scaler, cat_images, y_test[y_test.flatten() == cat_class_index])
# 选择一张图片进行预测
test_image = cat_images[0]
if is_cat(test_image, perceptron, scaler):
print("这是一张猫的图片!")
else:
print("这不是猫的图片。")
模型识别结果:
小结
感知机是一种早期模拟大脑工作机制的模型,尽管它为人工智能带来了重要的启示,但也存在明显的局限性。比如,它的模拟能力不够准确,无法有效处理复杂问题。然而,感知机依然为我们探索更复杂的人工智能模型奠定了基础。