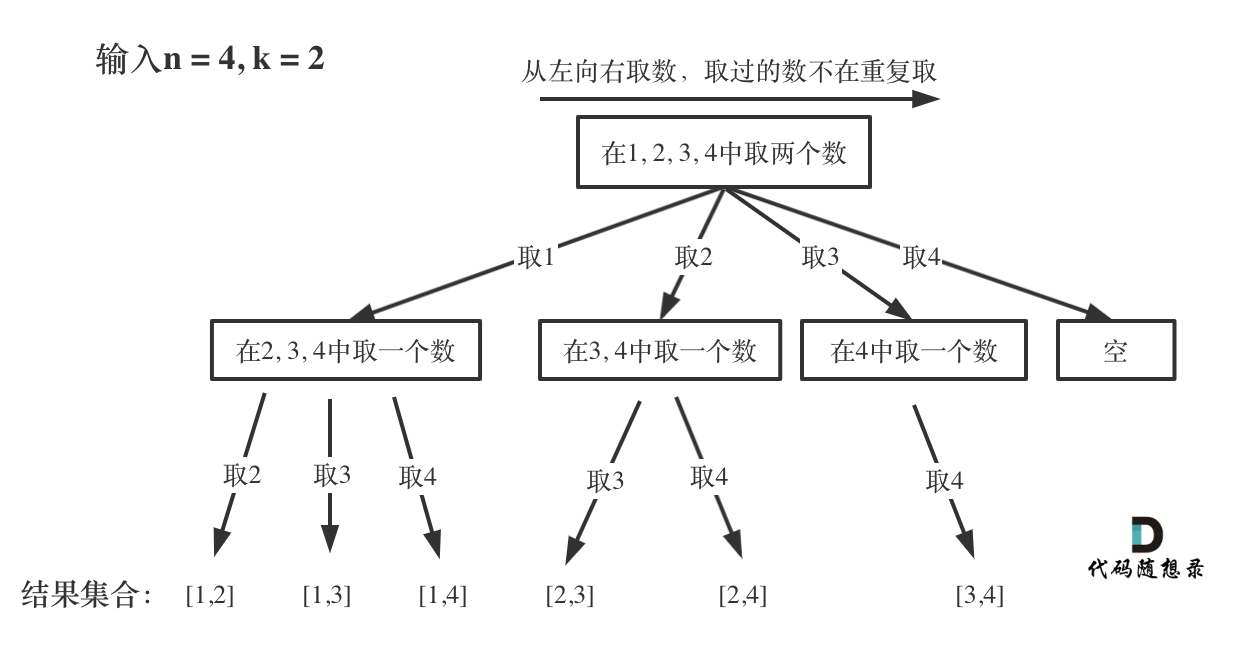
决策树
1. 什么是决策树?
决策树是一种基于树结构的监督学习算法,适用于分类和回归任务。
根据数据集构建一棵树(二叉树或多叉树)。
先选哪个属性作为向下分裂的依据(越接近根节点越关键)?
使用信息熵作为依据(即这个属性所包含的信息的多少)
2. 决策树构建的过程
决策树的构建过程包括以下几个步骤:
- 选择最优特征进行分裂:基于某些标准选择能够最好划分数据的特征(常见标准如信息增益、基尼系数)。
- 划分数据:按照选定的特征划分数据集。
- 递归构建子树:对每个子集重复1和2,直到满足停止条件(如树达到最大深度或叶子节点中的样本属于同一类)。
3. 如何选择分裂特征?
分裂特征的选择是决策树的核心。常用的特征选择标准包括:
-
信息增益(Information Gain):基于熵(Entropy)的变化来衡量特征的划分能力。信息增益越大,特征越优。

- 熵公式:

- 熵公式:
-
基尼不纯度(Gini Impurity):用于CART(分类和回归树)算法。它衡量了从数据集中随机抽取一个样本后,错误分类的概率。基尼不纯度越低,特征越优。

4. 决策树的优缺点
优点:
- 易于理解和解释:可解释性强。
- 无需特征缩放:不需要对数据进行标准化或归一化。
- 适用于分类和回归任务:既可以处理分类问题,也可以处理回归问题。
- 处理不平衡数据:对不平衡的数据具有较好的适应能力。
缺点:
- 容易过拟合:决策树如果不进行修剪,可能会过度拟合训练数据。
- 对噪声敏感:对数据中的噪声(异常值)敏感,可能导致树结构不稳定。
- 局限于轴对齐的分裂:决策树每次分裂仅基于单个特征,无法处理更加复杂的非线性边界。
5. 如何防止决策树的过拟合?
为了解决决策树过拟合的问题,常用的技术包括:
-
树剪枝(Pruning):
- 预剪枝(Pre-Pruning):在构建决策树时,限制树的最大深度、节点最小样本数、叶子节点的最小样本数等,从而避免树结构过于复杂。
- 后剪枝(Post-Pruning):先构建完整的决策树,然后通过删除一些分支来简化树的结构。
-
设置最大深度(Max Depth):限制树的最大深度,避免过拟合。
-
最小样本数(Min Samples Split/Leaf):控制每个节点最少需要包含的样本数,减少树的深度。
-
随机森林和集成学习:通过多个决策树的组合,如随机森林、梯度提升树等,可以有效降低单棵树的过拟合风险。
6. 常见的决策树算法
- ID3:基于信息增益选择分裂特征。
- C4.5:ID3的改进版,使用信息增益比(Information Gain Ratio)来选择特征。
- CART(Classification and Regression Tree):使用基尼系数选择特征,能够处理分类和回归问题。
7. 随机森林与决策树的区别
- 决策树:单棵树,容易过拟合,且对噪声敏感。
- 随机森林(Random Forest):随机森林的核心思想是通过构建多个决策树并让它们集体做出预测。对数据集进行划分成多个独立数据集,对划分的数据集单独训练成决策树,获得多个决策树。
8. 常见面试问题
-
什么是决策树?它是如何工作的?
- 回答要点:解释决策树的基本构建过程,如何通过划分数据集进行预测。
-
决策树如何选择分裂点?
- 回答要点:详细说明信息增益、基尼系数等标准。
-
如何防止决策树的过拟合?
- 回答要点:介绍预剪枝、后剪枝、设置最大深度等方法。
-
什么是随机森林?它与决策树的区别是什么?
- 回答要点:随机森林通过多棵树的集成减少单棵树的过拟合问题。
-
决策树可以用于回归吗?如果可以,它是如何处理的?
- 回答要点:决策树可以用于回归问题,回归树使用均方误差作为划分标准。
-
什么是CART算法?
- 回答要点:CART(分类和回归树)使用基尼系数进行分类,或者均方误差进行回归。
随机森林
(Random Forest) 是一种基于集成学习(Ensemble Learning)的监督学习算法,可以用于分类和回归任务。它通过构建多个决策树(通常是大量的决策树)并结合这些树的预测结果来提高模型的准确性和鲁棒性。随机森林可以通过投票(分类任务)或平均值(回归任务)来生成最终预测,从而减少单棵树可能带来的过拟合问题。
1. 随机森林的核心思想
随机森林的核心思想是通过构建多个决策树并让它们集体做出预测。每棵树都是在随机选取的样本和特征上独立训练的,最后通过对所有树的输出进行汇总来获得最终的预测结果。这个集成方法能够有效地提高模型的泛化能力,减少单棵决策树过拟合的风险。
2. 随机森林的构建步骤
(1) 随机样本选择(Bootstrap Sampling)
- 对于每棵树,从原始训练数据集中进行有放回的采样,构建不同的子数据集。这意味着每棵树可能会看到不同的训练数据,增强了模型的多样性。
- 未被采样到的数据称为“袋外数据”(Out-of-Bag Data, OOB),可以用来评估模型的性能。
(2) 随机特征选择(Random Feature Selection)
- 在每个节点分裂时,随机选择特征子集,而不是使用全部特征。然后在这个子集中选择最佳特征进行分裂。这一步进一步增加了树之间的差异,防止所有树在训练过程中做出相同的决策。
(3) 构建决策树
- 每棵决策树都使用不同的训练样本和不同的特征子集进行训练。训练过程是独立的,且没有任何剪枝(即决策树不进行复杂度控制)。
(4) 投票与平均
- 分类问题:每棵决策树独立对样本进行分类,随机森林则通过所有树的多数投票来决定最终分类结果。
- 回归问题:每棵树给出一个预测值,随机森林则取所有树预测值的平均作为最终结果。
3. 随机森林的优缺点
优点
- 抗过拟合:通过集成多棵树,随机森林能够有效降低单棵决策树的过拟合风险,从而提高泛化性能。
- 处理高维数据:随机森林可以处理包含大量特征的数据,并且能够自动进行特征选择。
- 处理缺失数据:随机森林能够处理数据中的缺失值,不需要对缺失值进行特殊处理。
- 高效性:通过并行训练多棵树,随机森林可以很好地扩展到大数据集。
- 稳健性:对噪声和异常值具有鲁棒性,因为多数树的投票或平均结果会减少单棵树对噪声的敏感性。
缺点
- 计算复杂度高:虽然可以并行处理,但随机森林模型包含大量的决策树,训练时间和预测时间较长。
- 模型解释性差:相比单棵决策树,随机森林的结果不易解释,无法像决策树那样直观地看到每个特征对结果的影响。
4. 随机森林的常用参数
- n_estimators:树的数量,即随机森林中包含多少棵决策树。通常,树的数量越多,模型的性能越好,但计算时间也会增加。
- max_depth:树的最大深度。限制树的深度可以防止模型过拟合。
- min_samples_split:节点分裂所需的最小样本数。增大此值可以防止过拟合。
- max_features:每次分裂时考虑的最大特征数,可以是
auto(等于总特征数的平方根)、sqrt(平方根)或log2(以2为底的对数)。 - bootstrap:是否使用有放回的采样,默认为
True,即每棵树都从训练集中有放回地抽样。
5. 袋外估计(Out-of-Bag Estimate, OOB)
- 袋外样本:在训练每棵树时,由于采样是有放回的,约有1/3的样本没有被用于训练这些树,这些未被使用的样本被称为袋外样本。
- OOB误差:使用袋外样本来评估模型性能,即通过未被采样到的样本来预测并评估准确性。OOB误差是衡量随机森林模型泛化能力的有效方法,类似于交叉验证。
6. 随机森林的常见应用
- 分类任务:用于文本分类、图片分类、疾病诊断等领域的分类问题。
- 回归任务:用于预测房价、股票市场波动、能源消耗等连续值的任务。
- 特征重要性评估:通过计算每个特征在所有树中的分裂贡献,评估各个特征的重要性。
- 异常检测:使用随机森林可以检测数据中的异常样本。
7. 随机森林的实践示例(使用Python的scikit-learn库)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 定义随机森林分类器
rf_clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_clf.fit(X_train, y_train)
# 进行预测
y_pred = rf_clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Random Forest Model Accuracy: {accuracy * 100:.2f}%')
8. 常见的面试问题
-
什么是随机森林?它与决策树的区别是什么?
- 回答要点:随机森林由多棵决策树组成,通过集成决策树的结果来减少过拟合,而单棵决策树容易过拟合。
-
随机森林如何防止过拟合?
- 回答要点:通过随机采样和随机选择特征子集,使每棵树的差异性增加,并结合多棵树的投票结果,减少单棵树的过拟合风险。
-
什么是OOB估计?它有什么用途?
- 回答要点:OOB估计是使用未被用来训练某棵树的样本来评估模型性能,类似于交叉验证,用于评估随机森林模型的泛化能力。
-
随机森林可以用于回归任务吗?如果可以,怎么实现?
- 回答要点:随机森林可以用于回归问题,通过在每棵树的基础上输出预测值的平均值来进行回归预测。