leetcode-217
给你一个整数数组
nums。如果任一值在数组中出现 至少两次 ,返回true;如果数组中每个元素互不相同,返回false。示例 1:
输入:nums = [1,2,3,1]
输出:true
解释:
元素 1 在下标 0 和 3 出现。
示例 2:
输入:nums = [1,2,3,4]
输出:false
解释:
所有元素都不同。
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2]
输出:true
思路:直接用map就可以
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
unordered_set<int>us;
for(auto num : nums){
if(us.find(num) == us.end()) {
us.insert(num);
} else {
return true;
}
}
return false;
}
};leetcode-349
给定两个数组
nums1和nums2,返回 它们的交集
。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2] 输出:[2]示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4] 输出:[9,4] 解释:[4,9] 也是可通过的提示:
1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
思路:第一时间想到的是map,但是如果不用map呢,我们是否可以牺牲一点时间复杂度,来换取更少的空间复杂度
没错:使用排序,双指针就可以不用额外空间了
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int>res;
int i=0, j=0;
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
while(i<nums1.size() && j<nums2.size()) {
while(i>0 && i < nums1.size() && nums1[i] == nums1[i-1]) {
++i;
}
if(i >= nums1.size()) {
break;
}
while(j>0 && j < nums2.size() && nums2[j] == nums2[j-1]) {
++j;
}
if(j >= nums2.size()) {
break;
}
if(nums1[i] == nums2[j]) {
res.push_back(nums1[i]);
++i, ++j;
} else if(nums1[i] > nums2[j] ) {
++j;
} else {
++i;
}
}
return res;
}
};leetcode-128
给定一个未排序的整数数组
nums,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。请你设计并实现时间复杂度为
O(n)的算法解决此问题。示例 1:
输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1] 输出:9提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109
思路:先遍历一遍,将所有数放在map里
之后遍历数组,找到一个局部最小数curr(即map里没有cuur-1这个key),逮着这个curr一直向大增长,看他能增长到多少长度,每次保存局部最大长度,选最长的
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int>mp;
int res = 0;
for(auto num : nums) {
mp.insert(num);
}
for(auto num : mp) {
if(!mp.count(num-1)) {
int dis = 1;
int curr = num;
while(mp.count(curr+1)) {
++dis;
++curr;
}
res = max(res, dis);
}
}
return res;
}
};leetcode-290
给定一种规律
pattern和一个字符串s,判断s是否遵循相同的规律。这里的 遵循 指完全匹配,例如,
pattern里的每个字母和字符串s中的每个非空单词之间存在着双向连接的对应规律。示例1:
输入: pattern ="abba", s ="dog cat cat dog"输出: true示例 2:
输入:pattern ="abba", s ="dog cat cat fish"输出: false示例 3:
输入: pattern ="aaaa", s ="dog cat cat dog"输出: false
思路:使用两个map,你映射我,我映射你,证明我们两是一样的,负责就不是
class Solution {
public:
vector<string> Split(string strs) {
vector<string>res;
string str = "";
for(auto s : strs) {
if(s != ' ') {
str += s;
} else {
res.push_back(str);
str = "";
}
}
if(str != "") {
res.push_back(str);
}
return res;
}
bool wordPattern(string pattern, string s) {
auto strs = Split(s);
//cout << pattern.size() << ", " << strs.size() << endl;
if(pattern.size() != strs.size()) {
return false;
}
map<string, char>mp2;
map<char, string>mp1;
for(int i=0; i<pattern.size(); i++) {
if(mp1.find(pattern[i]) == mp1.end()) {
if(mp2.find(strs[i]) != mp2.end()) {
return false;
}
mp2[strs[i]] = pattern[i];
mp1[pattern[i]] = strs[i];
} else {
auto str = mp1[pattern[i]];
if(mp2[strs[i]] != pattern[i]) {
return false;
}
}
}
return true;
}
};leetcode-523
给你一个整数数组
nums和一个整数k,请你在数组中找出 不同的 k-diff 数对,并返回不同的 k-diff 数对 的数目。k-diff 数对定义为一个整数对
(nums[i], nums[j]),并满足下述全部条件:
0 <= i, j < nums.lengthi != j|nums[i] - nums[j]| == k注意,
|val|表示val的绝对值。示例 1:
输入:nums = [3, 1, 4, 1, 5], k = 2 输出:2 解释:数组中有两个 2-diff 数对, (1, 3) 和 (3, 5)。 尽管数组中有两个 1 ,但我们只应返回不同的数对的数量。示例 2:
输入:nums = [1, 2, 3, 4, 5], k = 1 输出:4 解释:数组中有四个 1-diff 数对, (1, 2), (2, 3), (3, 4) 和 (4, 5) 。示例 3:
输入:nums = [1, 3, 1, 5, 4], k = 0 输出:1 解释:数组中只有一个 0-diff 数对,(1, 1) 。提示:
1 <= nums.length <= 104-107 <= nums[i] <= 1070 <= k <= 107
思路:将所有的数放在map里,接着遍历这些数,如果一个数curr满足,curr和curr+k都在该map里,则将该数放入结果中,最终看该结果数组多大
class Solution {
public:
int findPairs(vector<int>& nums, int k) {
unordered_set<int>visit;
unordered_set<int>res;
for(auto num : nums) {
if(visit.count(num-k)) {
res.insert(num-k);
}
if(visit.count(num+k)) {
res.insert(num);
}
visit.insert(num);
}
return res.size();
}
};leetcode-205
给定两个字符串
s和t,判断它们是否是同构的。如果
s中的字符可以按某种映射关系替换得到t,那么这两个字符串是同构的。每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
示例 1:
输入:s ="egg", t ="add"输出:true示例 2:
输入:s ="foo", t ="bar"输出:false示例 3:
输入:s ="paper", t ="title"输出:true提示:
1 <= s.length <= 5 * 104t.length == s.lengths和t由任意有效的 ASCII 字符组成
思路:和前面290题目差不多,两个map互相映射
class Solution {
public:
bool isIsomorphic(string s, string t) {
if(s.size() != t.size()) {
return false;
}
unordered_map<char, char>mp1;
unordered_map<char, char>mp2;
for(int i=0; i<s.size(); i++) {
if(mp1.find(s[i]) == mp1.end() && mp2.find(t[i]) == mp2.end()) {
mp1[s[i]] = t[i];
mp2[t[i]] = s[i];
} else if(mp1.find(s[i]) != mp1.end() && mp2.find(t[i]) != mp2.end()) {
if(mp1[s[i]] != t[i] || mp2[t[i]] != s[i]) {
return false;
}
} else {
return false;
}
}
return true;
}
};leetcode-138
给你一个长度为
n的链表,每个节点包含一个额外增加的随机指针random,该指针可以指向链表中的任何节点或空节点。构造这个链表的 深拷贝。 深拷贝应该正好由
n个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的next指针和random指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。例如,如果原链表中有
X和Y两个节点,其中X.random --> Y。那么在复制链表中对应的两个节点x和y,同样有x.random --> y。返回复制链表的头节点。
用一个由
n个节点组成的链表来表示输入/输出中的链表。每个节点用一个[val, random_index]表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。你的代码 只 接受原链表的头节点
head作为传入参数。示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:
输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]示例 3:
输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]提示:
0 <= n <= 1000-104 <= Node.val <= 104Node.random为null或指向链表中的节点。
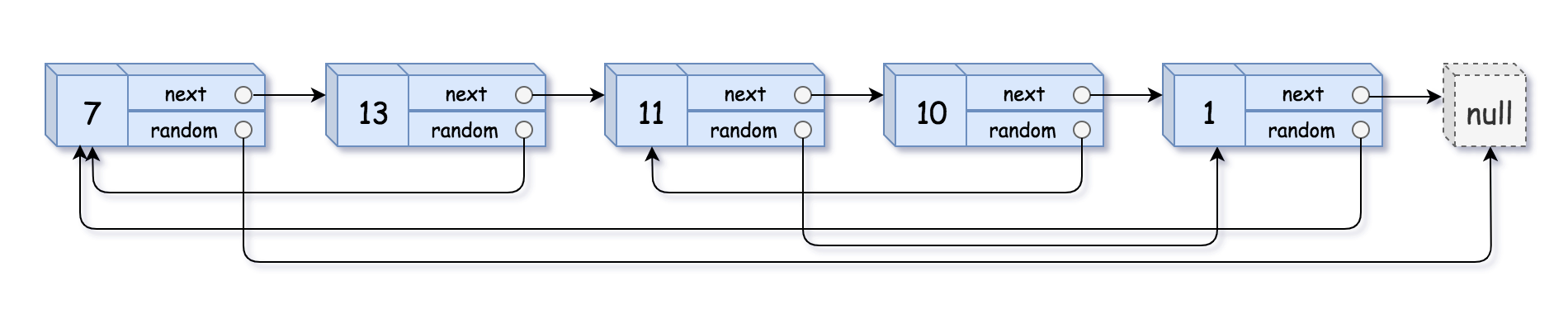


思路:这个题目感觉用递归好做些。唯一需要注意的是,需要先复制所有节点本身,再复制随机节点,不然直接复制随机节点,随机节点还没被创建
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
unordered_map<Node*, Node*> mp;
Node* copyRandomList(Node* head) {
if (!head) {
return nullptr;
}
if (!mp.count(head)) {
auto newNode = new Node(head->val);
mp[head] = newNode;
newNode->next = copyRandomList(head->next);
newNode->random = copyRandomList(head->random);
}
return mp[head];
}
};

![[uni-app]小兔鲜-08云开发](https://img-blog.csdnimg.cn/img_convert/b4ff268fe3ba3342a876cd8f4faf1043.png)