两年前自己在实习公司做过superpoint相关的工作,当时是负责利用superpoint代替slam前端的特征点部分,来达到把特征点相关的处理放到推理计算平台上减轻CPU压力并且精度无损的目的,最终也是成功完成了这部分工作。但是当时没有留下任何的记录,这次在工作中要再次接触superpoint和superglue时,还花了不少时间去回顾,所以为了方便自己,也希望能帮到一些有需要的人去理解它,打算以自己的理解的角度在业余时间写几篇博客。暂时是想分为几篇,superpoint完整解读包括源码(本篇)、superGlue完整解读包括源码、superglue中superpoint的再实现与原版superpoint的不同之处、两个模型利用tenssort加速与cpp部署的经验分享,以及两个模型的训练。不过想法是美好的,碍于工作太忙,自己不知道能实现几篇。(另外自己虽然是本硕科班计,但是一直对network知之甚少,望有错时能被纠正)
知识所属:MagicLeap
论文地址:https://arxiv.org/abs/1712.07629
作者讲解PPT:https://github.com/magicleap/SuperPointPretrainedNetwork/blob/master/assets/DL4VSLAM_talk.pdf
作者讲解视频:https://www.bilibili.com/video/BV14V4y1T7pW/?spm_id_from=333.337.search-card.all.click&vd_source=d85bf57f8523cf0ac2f69db86f6b6bfd(搬运自B站,因为源视频需要科学上网)
论文源码:https://github.com/magicleap/SuperPointPretrainedNetwork?tab=readme-ov-file
1. 前言
superpoint从发布到现在已经六年了,其优秀的“履历”感觉在这里也不需要过多赘述。本篇博客我会直接讲解网络模型的过程、算法思路以及对应的源码,如果之前对superpoint没有了解的建议先了解一下。
2. 网络结构
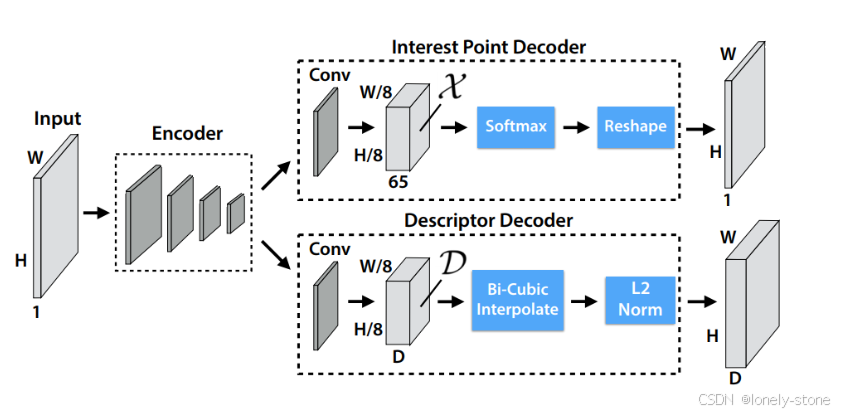
如上图所示,superpoint是Encoder-Decoder结构。特征点检测器与描述子网络共享的是一个前向encoder,encoder结束后,二者根据任务的不同学习不同的网络参数,再通过不同的处理得到最终的结果。其中特征点位置解码器会进行softmax、reshape和nms步骤得到最终的特征点及其置信度。描述子解码器则会进行双线性插值和标准化来得到最终的结果。接下来会对各个部分进行仔细讲解,并且会附上对应代码。
2.0 源码结构解析
文件结构
主要代码都在demo_superpoint.py,superpoint_v1.pth是模型参数,assets⾥⾯是⼀些样本图⽚。

代码结构
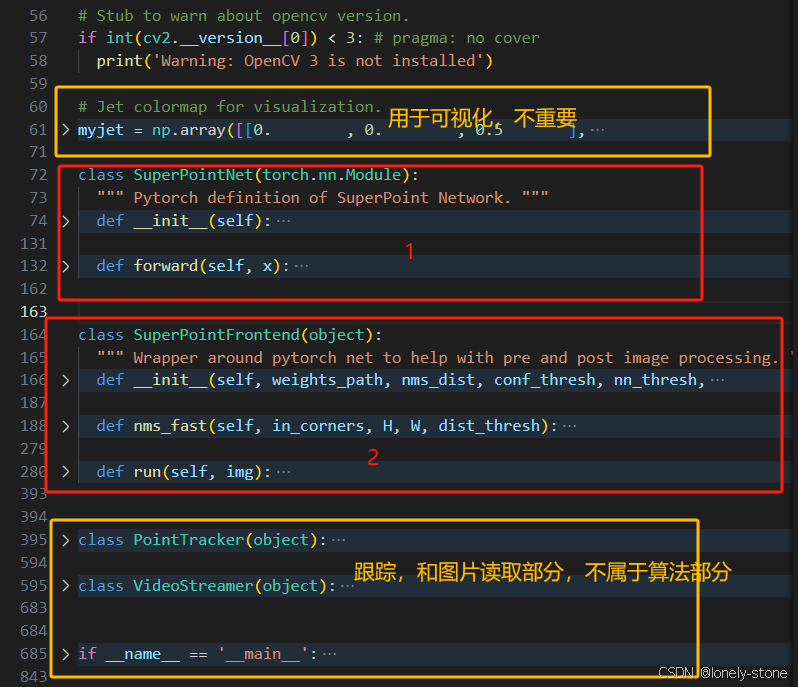
代码里面重要的也就两个class,一个是SuperPointNet,对应卷积网络部分。另一个
SuperPointFrontend里面实现了网络的调用和两个解码器的后处理。
2.1 Shared Encoder 共享的编码网络
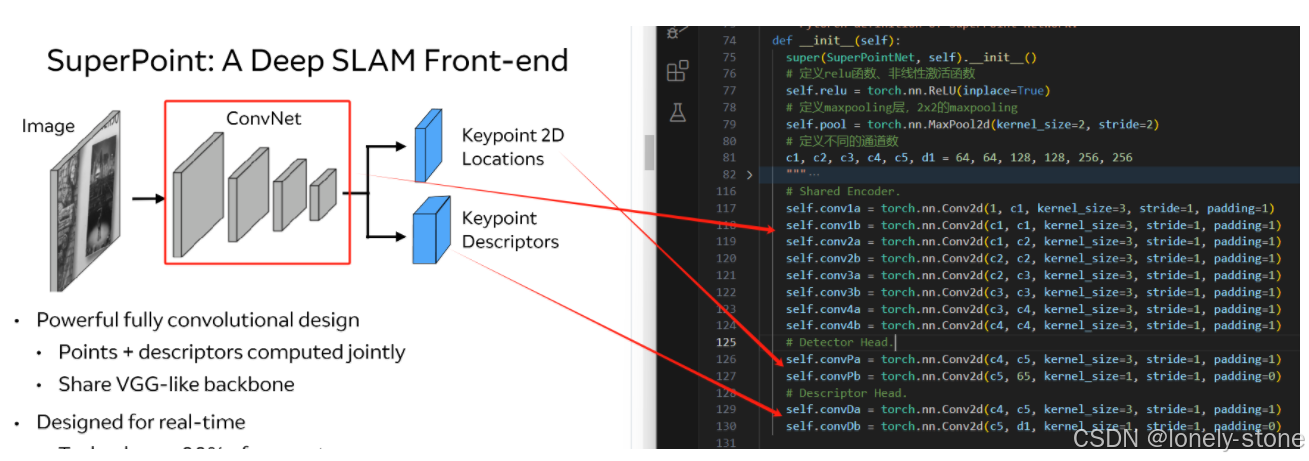
如上图所示,网络的卷积过程与代码一一对应。其中,还会涉及到维度和通道数的变化,具体如下:
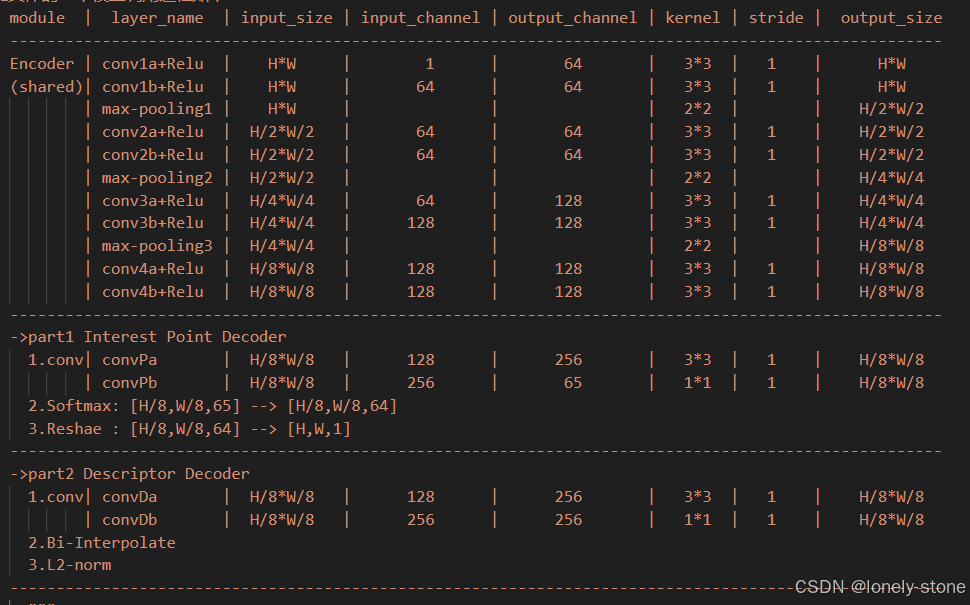
2.2 Interest Point Decoder
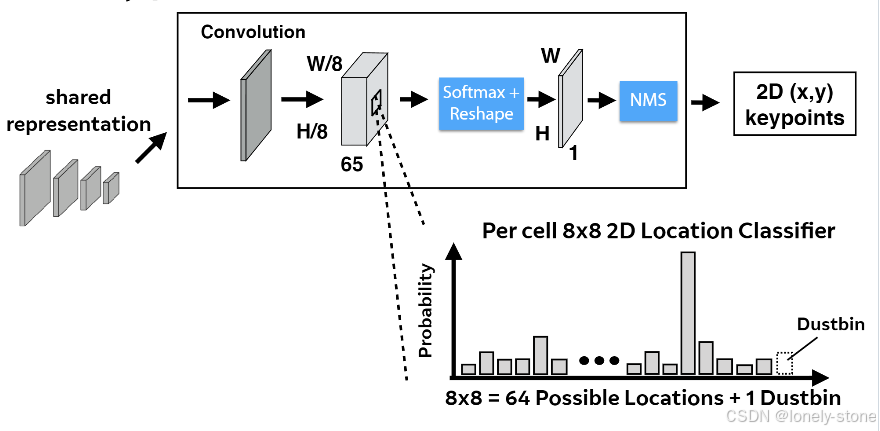
输入图片经过上面的共享编码网络之后,就会得到一个张量
[65,H/8,W/8],这个张量中,每个像素有65个通道,放大后如上图中的坐标图。其中64个通道的值就是对应图像中8x8区域中各个位置成为特征点的概率值,第65位为dutbin位(如果没有dustbin通道,在没有特征点时,每个cell在做完softmax后某些原本响应特别小的响应被 softmax“放大”,在后续就会被错误地选为特征点;如果有dustbin通道,在没有特征点时,dustbin的值会很大,即使经过了softmax也不会将其余的64个数字“放大”。所以dustbin是为了应对没有特征的情况)
Softmax+去dustbin+reshape+confidence限制
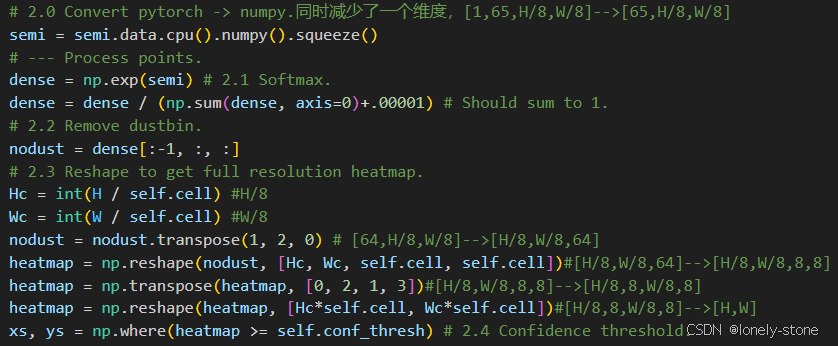
首先会进行softmax,即沿着每个像素的通道维度把各个数值通过经过运算后加和为1(针对概率分布的处理)。随后去掉dustbin通道,并对维度进行处理,得到[H,W]。然后根据confidence筛选。
NMS+remove border point
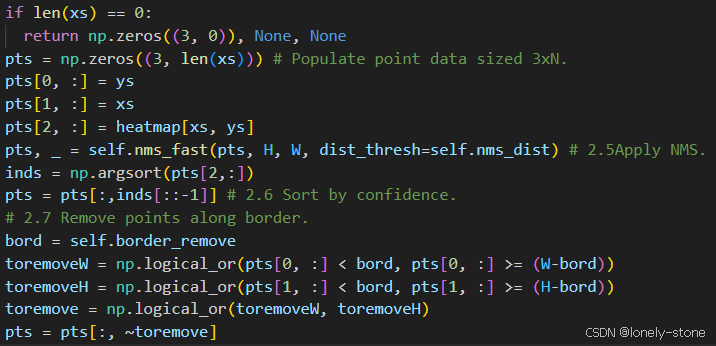
在经过上面步骤得到初步的特征点后,此时还要进行NMS(非极大抑制),其作用就是把一个区域内最大值周边的值都设置为不成为特征点,原因是因为那些点的confidence大可能不是它本身的质量高,而是被那个最大值特征点带起来的,第二个原因就是NMS也能很好的让特征点均匀分布,有利于后续的匹配。在经过NMS后,去掉处于图像边界的特征点,最后根据confidence排序得到最终结果。
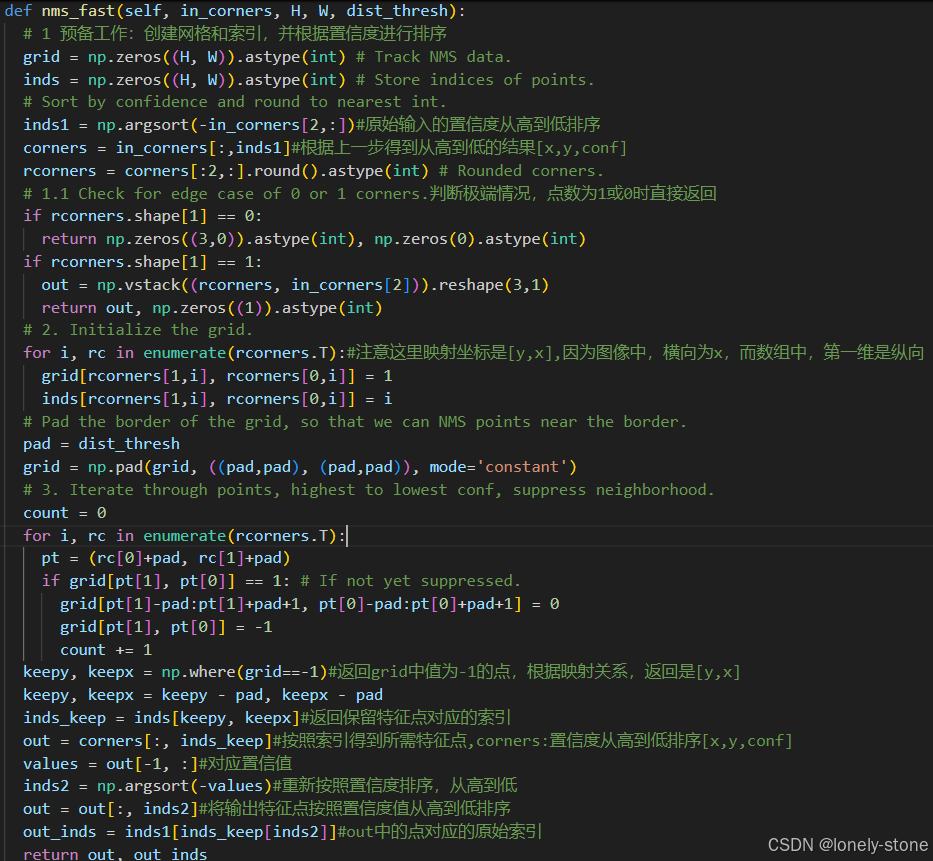
接下来对NMS的具体处理过程进行介绍:
算法的整体思路为:创建一个大小为HxW的网格上(image大小), 让每个特征点所在位置的值为1,其他的为0。遍历所有为1的位置(从confidence值大到小的顺序),将它变成-1,将其周围区域内的所有为1的值变为0( -1表示保留, 0表示抑制)。本质上: 将置信值最大的附近的特征点变味0来抑制。
具体的代码过程如下:
2.2 Descriptor Decoder
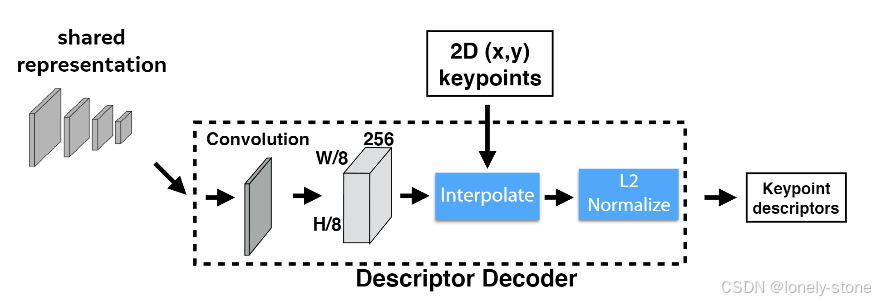
主要经过两个步骤,首先会结合拿到的特征图和特征点位置进行双线性插值,得到对应的描述子矩阵后再进行L2范数计算得到最终的描述子结果。
双线性插值
这部分采用了pytorch中的函数torch.nn.functional.grid_sample(关于这个函数的理解可以参考https://blog.csdn.net/weixin_42392454/article/details/141608192)。grid_sample 是 PyTorch 中的一个函数,它用于根据给定的采样网格(grid)对输入张量进行采样。具体流程是首先将 grid 中的归一化坐标转换为输入张量的实际坐标。然后双线性插值对每个采样点,根据其在输入张量中的实际坐标,找到周围的四个像素点,计算插值权重。使用这些权重,对周围的像素值进行加权平均,以获得采样点的值。从而得到新的输出张量。